

What makes Kafka very fast? What makes it special? we shall respond to that in this blog post. Let’s agree that the term fast is very fuzzy, I mean, what does fat even imply? Are you saying low latency? high throughput? And specifically, compared to what?

Come to an agreement!
Kafka is optimized for High throughput, it is optimized to move large amounts of records in a short period of time, you can think of the water pipe as an analogy, the larger the water pipe, the more enormous amount of liquid it can hold and move! Now, we have come to an agreement, when someone says that Kafka is fast, he means that it’s high throughput and can move a very large amount of data, that’s it.

Fine, but why?!
We have agreed that Kafka is fast but, why? what design decisions helped it be that fast? Mmmm, well, there are many design decisions that helped in this, two of them seem to have the most impact on it, Sequential I/O and Zero Copy Principle. We will dive into both of them now.
Don’t forget to hit the Clap and Follow buttons to help me write more articles like this.
Sequential I/O
Before diving deep into this, we must resolve a popular misconception that disks aren’t slower than memories in general and that depends on the access pattern itself.
There are two main access patterns:
- Random access: in this access pattern, the arm takes a lot of time to jump to different locations, this, makes random access very slow on the disks, about hundreds of kilobytes per second.
- Sequential access: the arm has no need to jump to different locations, so it is much faster, about hundreds of megabytes per second.
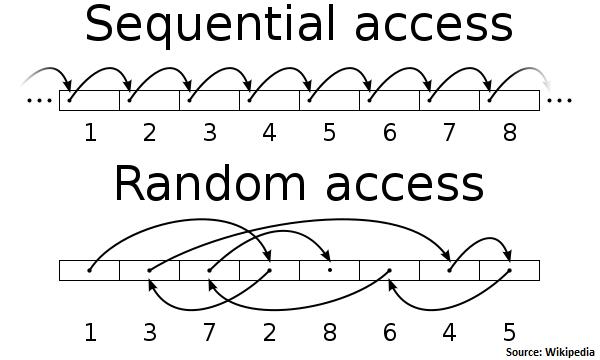
Kafka takes advantage of this and uses an append-only log as its primary data structure. It adds new data to the end of the file thus sequential.
This technique has its cost advantage, as now we can use HDD efficiently instead of other disk types like SSD. As HDD costs about one-third the price of an SSD with three times the capacity!! Henceforth, giving Kafka a large pool of cheap disk space without any performance penalty, means that it can cost-effectively retain messages for a long period of time, which is a feature that was uncommon to messaging systems before.
Zero Copy Principle
Kafka moves an enormous amount of data from the network to the disk and vice versa. That means, eliminating any excess copy is very critical and will have a great impact on the system as a whole.
First, let's see how data is moved in the system without the Zero Copy Principle:
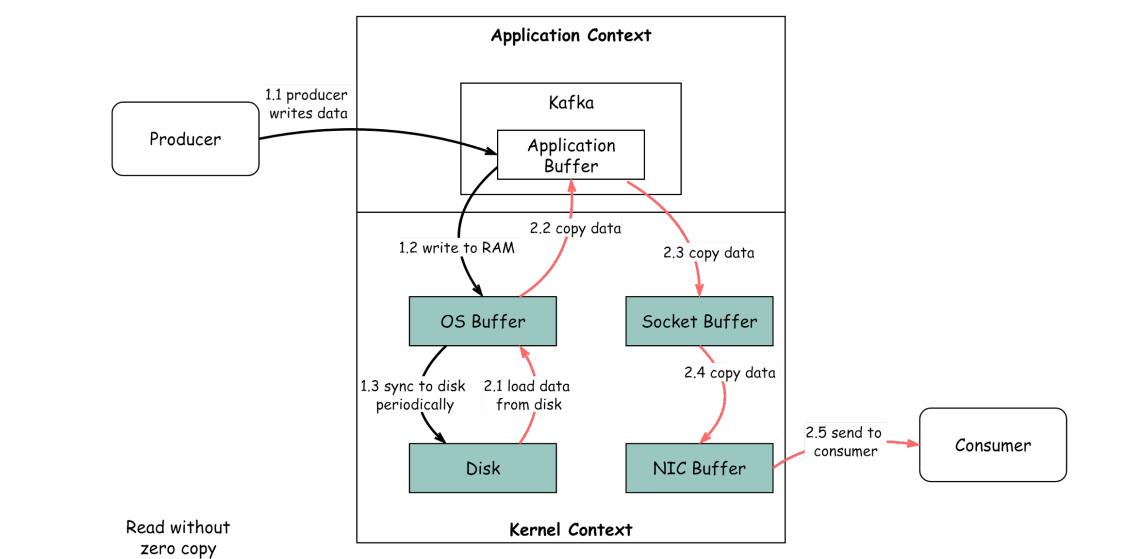
- The data is loaded from the disk to the OS cache.
- The data is copied from the OS cache to the Kafka application.
- Kafka application copies the data into the socket buffer.
- The data is copied from the socket buffer to the network card.
- The network card sends data out to the consumer.
Second, with the Zero Copy Principle:
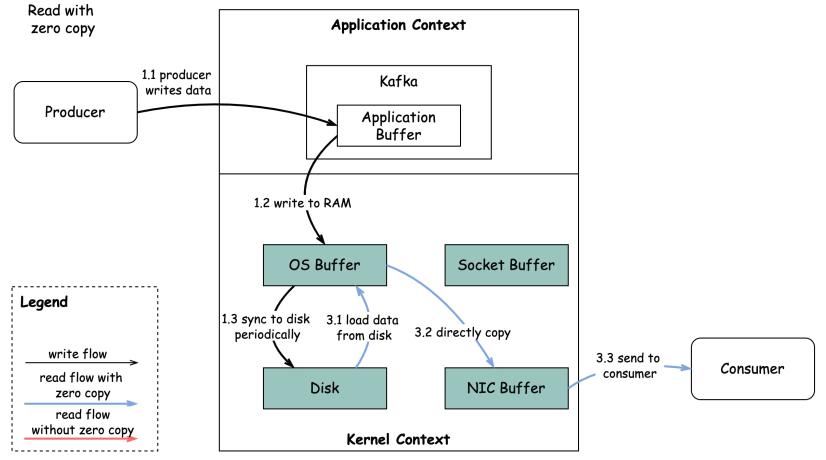
- The data is loaded from the disk to the OS cache.
- OS cache directly copies the data to the network card via
sendfile()command. - The network card sends data out to the consumer.
This copy is done with DMA(direct memory access) which means that the CPU is not involved and that makes the process away more efficient.
Zero copy is a shortcut to save the multiple data copies between application context and kernel context. This approach brings down the time by approximately 65%.
Don’t forget to hit the Clap and Follow buttons to help me write more articles like this.
Finally,
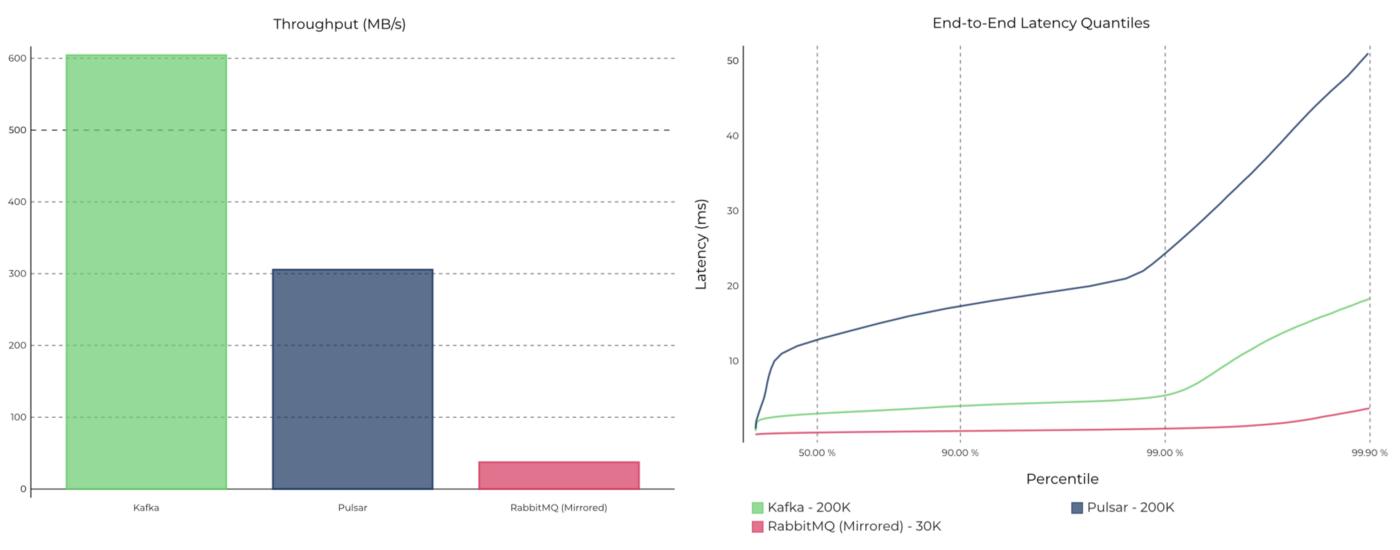
Kafka uses other techniques to increase performance and squeeze every ounce of performance of modern hardware! Check the following graphs for a proper comparison.
References
Why is Kafka fast?
Why is Kafka fast? Kafka achieves low latency message delivery through Sequential I/O and Zero Copy Principle. The same…
blog.bytebytego.com





 已为社区贡献13070条内容
已为社区贡献13070条内容

所有评论(0)