计算机视觉工程师业务场景题:智能推荐视频封面
SSIM(Structural Similarity Index Measure,结构相似性指数)是一种用于衡量两幅图像感知相似度的全参考图像质量评价指标,由王舟等人于2004年提出。相较于传统的MSE(均方误差)、PSNR(峰值信噪比),SSIM 更符合人类视觉系统(HVS)特性,能更好地反映图像内容的结构信息损失。核心思想SSIM 认为人眼主要感知图像中的结构信息(如边缘、纹理),而非绝对像素
题目
(百度)给定一个视频,如何智能推荐视频中的其中一帧作为封面?给出详细的方案。
解答
这是一个典型的计算机视觉应用问题,核心在于 从视频中自动选取最具代表性和吸引力的帧。
(1)详细步骤与核心技术
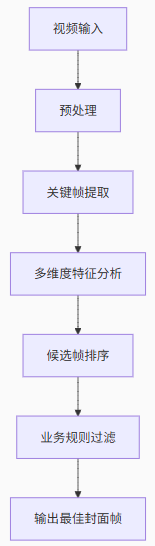
1. 预处理阶段
抽帧策略:
-
非均匀采样:优先在镜头切换(Shot Boundary)前后增加采样率(如每0.5秒一帧),镜头中间减少采样(如每秒1帧),避免冗余。
-
动态调整:长视频(>10分钟)可降低采样率,短视频(<1分钟)提高采样率。
分辨率处理:对4K视频降采样至720p,减少计算量。
异常帧过滤:检测纯黑/纯白帧(像素值方差<阈值)、模糊帧(Laplacian梯度方差<100)、花屏帧(FFT高频能量异常)。
2. 关键帧提取
镜头边界检测:
-
算法:
Histogram Difference+SIFT特征匹配,结合帧间差异阈值(e.g., 直方图差异 > 0.3)。 -
输出:每个镜头的起止时间点。
关键帧选择:
-
方案1:取镜头中间帧(避免转场动画)。
-
方案2:聚类镜头内所有帧,取聚类中心帧(使用K-means + HSV特征)。
3. 多维度特征分析(核心)
对每个候选帧计算以下特征并打分(0~1分):
(1) 视觉质量
-
清晰度:
Tenengrad梯度函数(Sobel算子计算梯度能量)gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) score = cv2.Sobel(gray, cv2.CV_64F, 1, 1).var() -
亮度均衡:避免过曝/欠曝(像素值在[30, 220]的比例 > 80%)
-
色彩丰富度:HSV空间统计饱和度高(S>0.5)的像素占比。
(2) 内容重要性
-
主体检测:
-
使用目标检测模型(YOLOv8或Faster R-CNN)检测人/脸/商品等关键物体。
-
得分公式:
score = 1 + 0.5*人脸数 + 0.3*重要物体数(可配置权重)
-
-
显著性区域:使用
U2-Net生成显著图,计算显著区域占比(>20%为佳)。 -
文本信息:OCR识别(PaddleOCR)标题/字幕,存在有效文本加分(e.g., 视频标题关键词匹配)。
(3) 情感吸引力
人脸分析:
-
人脸表情:微笑(+0.2分)、惊讶(+0.1分) vs 愤怒/悲伤(-0.3分)。
-
人脸占比:单人脸占画面15%~50%为最佳区间。
美学构图:使用Aesthetic评分模型(预训练ResNet),预测美感得分。
(4) 运动信息(针对动态场景)
光流分析:计算帧间稀疏光流(LK算法),运动幅度过大的帧扣分(可能模糊)。
4. 候选帧排序
加权综合评分:
Total_Score = w1*质量分 + w2*内容分 + w3*情感分 - w4*运动模糊分权重调整:通过A/B测试确定(如w1=0.4, w2=0.3, w3=0.2, w4=0.1)。
多样性保护:若前N帧相似度高(SSIM>0.8),只保留最高分帧,避免重复推荐。
5. 业务规则过滤
黑名单规则:
-
规避水印区域(检测固定位置/颜色的Logo)。
-
规避字幕区域(底部20%像素检测高对比度文本)。
-
规避马赛克/模糊处理区域(通过边缘检测识别)。
白名单规则:
-
优先包含主播人脸(短视频场景)。
-
优先包含品牌商品(电商场景)。
尺寸适配:选择宽高比与目标封面(如16:9)最接近的帧。
6. 工程优化
计算效率:
-
并行化处理:使用Spark或Ray并行处理不同视频段。
-
模型加速:关键模型(目标检测、美学评分)部署为TensorRT推理。
缓存机制:热门视频预生成封面帧,存入Redis。
降级策略:超时则退回第一帧或中间帧。
(2)算法选型对比
| 任务 | 推荐算法 | 备选方案 | 适用场景 |
|---|---|---|---|
| 镜头分割 | OpenCV HistDiff | PySceneDetect | 通用 |
| 目标检测 | YOLOv8s | Faster R-CNN | 需实时性场景 |
| 显著性检测 | U2-Net | DeepGaze II | 无明确主体时 |
| 美学评分 | NIMA (ResNet50) | AVA数据集预训练 | 时尚/艺术类视频 |
(3)评估指标
-
人工评估:随机抽样视频,人工评分封面相关性(1~5分)。
-
业务指标:封面点击率(CTR)、视频完播率。
-
自动化指标:关键物体覆盖率(检测框IoU>0.5)、模糊帧误选率。
(4)迭代方向
-
个性化封面:根据用户历史行为推荐(如游戏用户偏好角色特写)。
-
动态封面:生成3秒GIF封面(需平衡加载速度)。
-
多模态融合:结合音频分析(掌声/笑声高峰帧)和字幕关键词。
注:实际工业场景中,需通过A/B测试持续优化权重和算法组合,同时平衡计算成本与效果。大厂通常会构建专用封面服务,与视频理解平台联动。
附1:SSIM(结构相似性指数)介绍
SSIM(Structural Similarity Index Measure,结构相似性指数)是一种用于衡量两幅图像感知相似度的全参考图像质量评价指标,由王舟等人于2004年提出。相较于传统的MSE(均方误差)、PSNR(峰值信噪比),SSIM 更符合人类视觉系统(HVS)特性,能更好地反映图像内容的结构信息损失。
核心思想
SSIM 认为人眼主要感知图像中的结构信息(如边缘、纹理),而非绝对像素差异。它从三个维度比较图像:
-
亮度(Luminance):比较平均亮度
-
对比度(Contrast):比较标准差(对比度)
-
结构(Structure):比较去均值归一化后的相关性
数学公式
给定两幅图像 x 和 y,在局部窗口(通常为 8×8 或 11×11)内计算:
1. 亮度比较(Luminance)
-
:窗口内像素均值
-
:避免分母为0的常数(L 为像素值范围,如255;
,通常取0.01)
2. 对比度比较(Contrast)
-
:窗口内像素标准差
-
3. 结构比较(Structure)
-
:协方差
-
(通常简化设置
4. 综合SSIM指数
关键特性
| 特性 | 说明 |
|---|---|
| 值域 | [-1, 1],值越大表示越相似(1表示完全相同) |
| 局部性 | 通过滑动窗口计算,最终取所有窗口的平均值(Mean SSIM) |
| 感知一致性 | 对亮度/对比度变化不敏感,聚焦结构信息 |
| 计算效率 | 可快速实现(OpenCV 等库已优化) |
| 非对称性 | SSIM(x,y) = SSIM(y,x) |
在视频封面推荐中的应用
在方案中,SSIM 用于 候选帧去重 :
import cv2
def calc_ssim(frame1, frame2):
# 转换为灰度图(SSIM通常用于单通道)
gray1 = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# OpenCV 实现(需确保图像尺寸相同)
ssim_score = cv2.SSIM(gray1, gray2)
return ssim_score
# 示例:过滤相似帧
candidate_frames = [...] # 候选帧列表
filtered_frames = []
threshold = 0.8 # 经验阈值:>0.8认为高度相似
for frame in candidate_frames:
if not filtered_frames:
filtered_frames.append(frame)
else:
# 与已选帧中最高分帧比较
max_similarity = max(calc_ssim(frame, f) for f in filtered_frames)
if max_similarity < threshold:
filtered_frames.append(frame)与其他指标对比
| 指标 | 敏感对象 | 人眼一致性 | 计算复杂度 | 适用场景 |
|---|---|---|---|---|
| SSIM | 结构信息 | 高 | 中 | 图像/视频质量评估 |
| PSNR | 像素绝对误差 | 低 | 低 | 编码失真评估 |
| MSE | 像素平方误差 | 极低 | 极低 | 算法优化(梯度友好) |
| LPIPS | 深度学习特征差异 | 极高 | 高 | 生成图像质量评估(GAN) |
改进版本
-
MS-SSIM (Multi-scale SSIM):在多个分辨率下计算SSIM,更适合人类多尺度视觉感知。
-
CW-SSIM (Complex Wavelet SSIM):使用复小波变换应对平移/旋转不变性。
工程注意事项
-
颜色空间:通常使用 YCbCr 的亮度通道(Y)计算,避免颜色干扰。
-
滑动窗口大小:过小会噪声敏感,过大会丢失细节(推荐 11×11 高斯加权窗口)。
-
阈值选择:
- SSIM > 0.8:视觉上几乎相同
- SSIM > 0.6:内容可辨认但质量下降
- SSIM < 0.2:显著不同
附2:A/B测试介绍
A/B测试(也称为分流测试或桶测试)是一种通过随机分组对比不同方案效果的科学实验方法,广泛应用于互联网产品优化、算法迭代和业务决策。其核心逻辑是:控制单一变量,通过统计学验证因果性。
核心概念
| 术语 | 说明 |
|---|---|
| 对照组 (Control) | 使用原始方案(如旧版封面推荐算法)的用户群 |
| 实验组 (Variant) | 使用新方案(如新版封面算法)的用户群 |
| 流量分割 | 随机将用户分为多组(如50%用A方案,50%用B方案) |
| 实验指标 | 衡量效果的核心业务指标(如封面点击率、视频完播率) |
| 显著性检验 | 判断指标差异是否由方案导致(而非随机波动) |
在视频封面推荐中的实施步骤
1. 明确目标
-
主指标:封面点击率(CTR = 封面点击量 / 视频曝光量)
-
辅助指标:视频平均播放时长、点赞/分享率、用户流失率
-
护栏指标:服务延迟(确保新算法不影响用户体验)
2. 设计实验方案
-
变量控制:
-
实验组:使用智能封面推荐算法
-
对照组:使用原方案(如视频第一帧/人工指定帧)
-
-
流量分割:
-
按 UserID 哈希分桶(确保同一用户每次看到相同方案)
-
比例:通常实验组 vs 对照组 = 50% : 50%(大流量可缩小实验组比例)
-
3. 技术实现
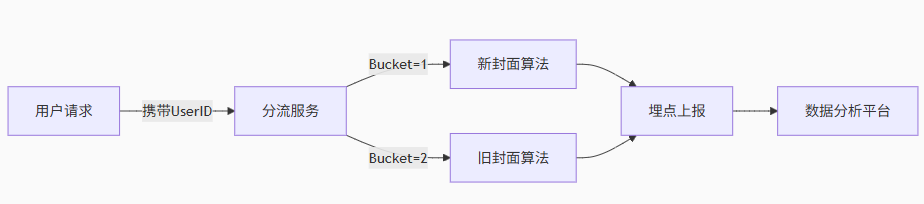
关键组件:
-
分流服务:根据UserID分配实验策略(可基于Redis缓存)
-
埋点日志:记录用户行为(曝光、点击、播放进度)
-
数据管道:实时计算指标(Flink/Kafka+Spark)
4. 数据收集与监控
数据去噪:
-
排除机器人流量(UA过滤)
-
排除极端用户(播放时长<2秒的无效曝光)
实时看板:监控核心指标波动(如CTR突然下降10%需熔断实验)
5. 统计分析与结论
假设检验:
-
原假设 H0:实验组与对照组CTR无差异
-
备择假设 H1:实验组CTR更高
检验方法:T检验(正态分布指标)或 Mann-Whitney U检验(非正态分布)
决策规则:若 p-value < 0.05(95%置信水平)且 CTR提升>1% ,认为新方案显著有效
关键注意事项
1.样本量计算
需预先估算最小样本量,避免统计功效不足(公式):
- σ:指标标准差(通过历史数据预估)
- δ:预期提升幅度(如CTR提升0.5%)
:显著性水平(α=0.05时取1.96)
:统计功效(通常取0.84对应80%功效)
2.实验时长
-
至少覆盖 1个完整用户周期(如短视频用户周期为7天)
-
避免周期干扰(如周末/工作日流量差异)
3.辛普森悖论
需分层分析(Stratification),避免分组偏差:
-
按用户画像分层(新用户/老用户)
-
按视频类型分层(娱乐/教育类视频)
4.多变量测试 (MVT):同时测试多个变量(如封面算法+UI布局),需正交实验设计。
与A/B测试互补的方法
-
Interleaving Testing:在同一用户页面交错展示A/B方案结果(适合排序类算法)。
-
Bandit算法:动态分配流量(如90%给效果更好的方案),减少机会成本。
经典工具:Google Optimize、Airbnb ERF、内部AB平台
核心价值:用数据驱动决策替代主观判断,降低业务风险。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)