25年8月份最新文章—爬取某无忧网的岗位信息
本文介绍了一个基于Python和Playwright的爬虫程序,用于采集前程无忧网站上19个热门城市的1000条岗位信息。程序通过处理URL参数和验证码滑块,获取岗位名称、薪资、公司信息等关键字段,并使用pandas保存为CSV文件。代码包含详细的注释,实现了自动翻页、数据解析和异常重试机制,支持自定义搜索岗位名称。该爬虫可有效收集全国主要城市的招聘数据,为就业市场分析提供数据支持。
·
前言
我们这里就爬全国较为热门的19个城市的最新发布的1000家岗位信息,一些关键字段有岗位名称、城市、薪资待遇,公司名称,发布时间、工作地址、等等,还可以通过岗位和公司的详情链接获取更加详细的信息。
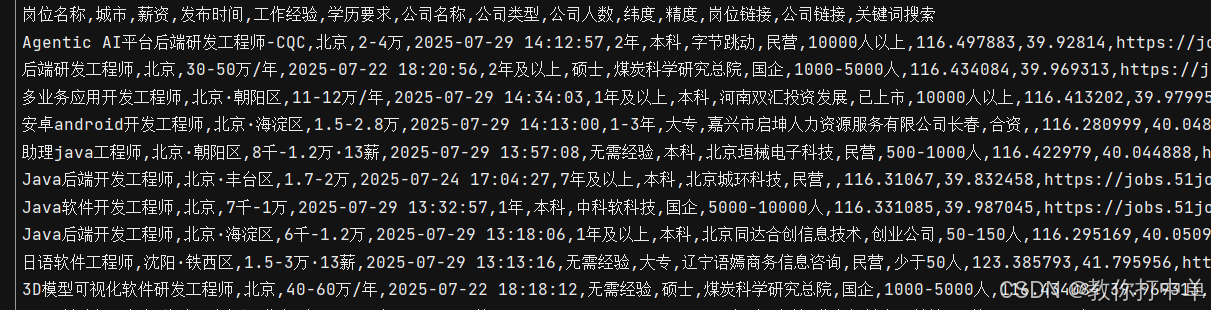
1、直接分析处理好相关url的参数值,其中
keyword是岗位名称,city是城市,page是页码
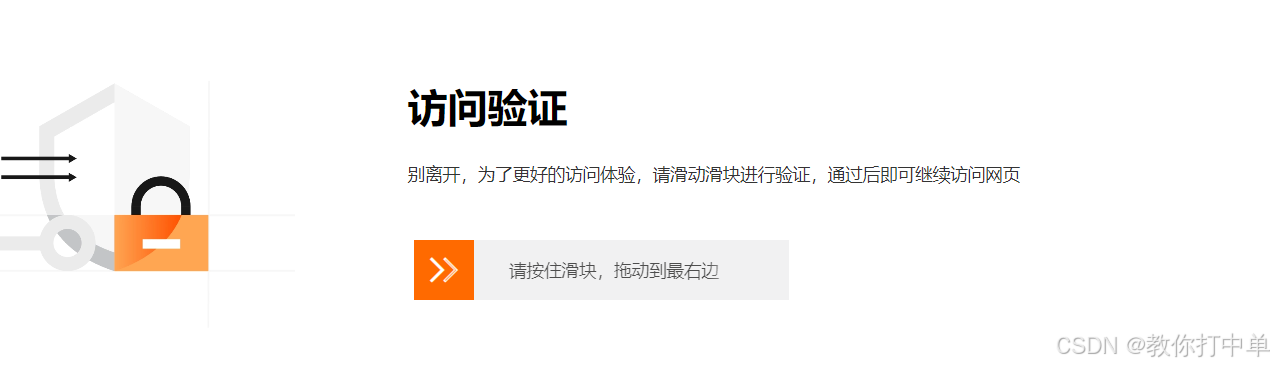
2、过掉这个验证码就好了
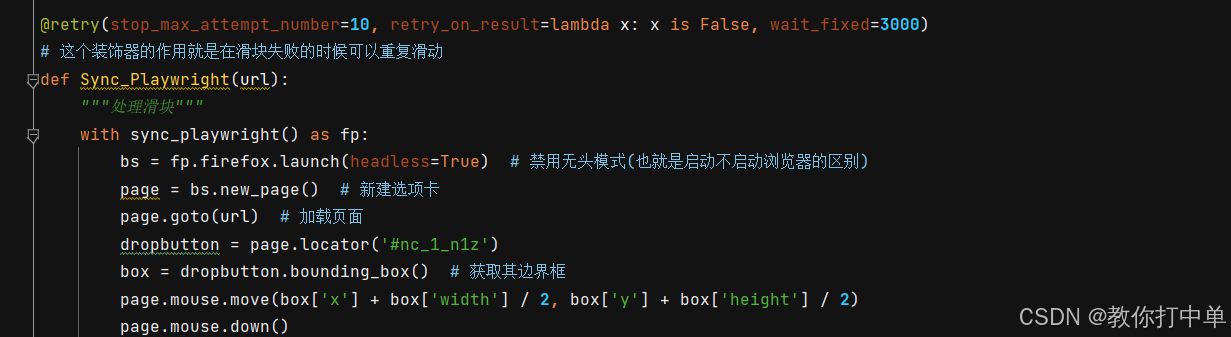
3、因为过这个验证码经常可能出现一次过不掉的情况,所有这里加了个装饰器(作用是失败了可以重复反复滑动)
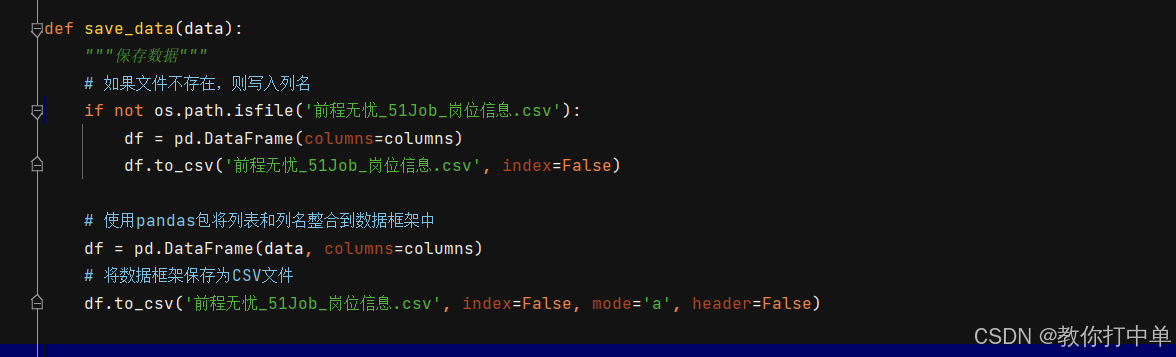
4、数据就保存在当前目录,名称可以随便改的,
5、使用下面命令先安装一下模块
pip install playwright -i Simple Index
playwright install
6、开始去采集自己需要的数据吧,代码注释的非常详细了喔。
完整代码如下
import json
import os
import random
import time
import pandas as pd
from playwright.sync_api import sync_playwright # 同步模式
from retrying import retry
@retry(stop_max_attempt_number=10, retry_on_result=lambda x: x is False, wait_fixed=3000)
# 这个装饰器的作用就是在滑块失败的时候可以重复滑动
def Sync_Playwright(url):
"""处理滑块"""
with sync_playwright() as fp:
bs = fp.firefox.launch(headless=True) # 禁用无头模式(也就是启动不启动浏览器的区别)
page = bs.new_page() # 新建选项卡
page.goto(url) # 加载页面
dropbutton = page.locator('#nc_1_n1z')
box = dropbutton.bounding_box() # 获取其边界框
page.mouse.move(box['x'] + box['width'] / 2, box['y'] + box['height'] / 2)
page.mouse.down()
# 模拟人类的鼠标移动轨迹
steps = 30 # 可以根据需要调整步数
for step in range(1, steps + 1):
progress = step / steps
mov_x = box['x'] + box['width'] / 2 + 300 * progress + random.uniform(-5, 5)
mov_y = box['y'] + box['height'] / 2 + random.uniform(-5, 5)
page.mouse.move(mov_x, mov_y)
time.sleep(random.uniform(0.02, 0.1)) # 模拟人的自然反应时间
page.mouse.up()
ttt = random.uniform(5, 8)
time.sleep(ttt)
html = page.locator('xpath=/html/body/pre')
qwer = html.inner_text()
if 'resultbody' in qwer:
a = json.loads(qwer)
return a
else:
return False
# 定义列名为全局变量
columns = ['岗位名称', '城市', "薪资", "发布时间", "工作经验", '学历要求', '公司名称', '公司类型', '公司人数', '纬度',
'精度',
'岗位链接', '公司链接', '关键词搜索']
def save_data(data):
"""保存数据"""
# 如果文件不存在,则写入列名
if not os.path.isfile('前程无忧_51Job_岗位信息.csv'):
df = pd.DataFrame(columns=columns)
df.to_csv('前程无忧_51Job_岗位信息.csv', index=False)
# 使用pandas包将列表和列名整合到数据框架中
df = pd.DataFrame(data, columns=columns)
# 将数据框架保存为CSV文件
df.to_csv('前程无忧_51Job_岗位信息.csv', index=False, mode='a', header=False)
def parseDataFields(i, keyword, page):
"""解析数据"""
jobName = i['jobName'] # 岗位名称
cityString = i['jobAreaString'] # 城市
provideSalaryString = i['provideSalaryString'] # 薪资
issueDateString = i['issueDateString'] # 发布时间
workYearString = i['workYearString'] # 需要工作经验
degreeString = i['degreeString'] # 学历
companyName = i['companyName'] # 公司名称
companyTypeString = i['companyTypeString'] # 企业类型
companySizeString = i['companySizeString'] # 公司人数
lon = i['lon'] # 纬度
lat = i['lat'] # 精度
jobHref = i['jobHref'] # 岗位链接
companyHref = i['companyHref'] # 公司链接
s = [jobName, cityString, provideSalaryString, issueDateString, workYearString, degreeString, companyName,
companyTypeString,
companySizeString, lon, lat, jobHref, companyHref, keyword]
print(page, companyName, cityString, jobName)
return s
if __name__ == '__main__':
# 获取当前时间的时间戳(秒)
timestamp = int(time.time())
# 将时间戳转换为指定格式的字符串
formatted_timestamp = "{:06d}".format(timestamp)
keyword = input("请输入岗位:")
city_names = {
'010000': '北京',
'020000': '上海',
'030000': '广州',
'040000': '深圳',
'180200': '武汉',
'200200': '西安',
'080200': '杭州',
'070200': '南京',
'090200': '成都',
'060000': '重庆',
'070300': '苏州',
'190200': '长沙',
'050000': '天津',
'170200': '郑州',
'030800': '东莞',
'070400': '无锡',
'080300': '宁波',
'120300': '青岛',
'150200': '合肥'
}
all_data = []
# 只爬取4个一线城市和15个新一线城市的最新发布的1000条招聘信息(岗位自输)
for city in city_names:
for page in range(1, 51):
url = (
f'https://we.51job.com/api/job/search-pc?api_key=51job×tamp={formatted_timestamp}&keyword={keyword}'
f'&searchType=2&function=&industry=&jobArea={city}&jobArea2=&landmark=&metro=&salary=&workYear=°ree=&'
f'companyType=&companySize=&jobType=&issueDate=&sortType=1&pageNum={page}&requestId=7e9414e33dca12ec81455c05a6963a8a'
f'&keywordType=&userLonLat=&pageSize=20&source=1&accountId=&pageCode=sou%7Csou%7Csoulb&scene=7')
html = Sync_Playwright(url)
bba = html['resultbody']['job']['items']
for i in bba:
pardate = parseDataFields(i, keyword, page)
all_data.append(pardate)
save_data(all_data)
all_data.clear()
print("已经爬了", city_names.get(city))
print("全部爬取完成")

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)