
Fast RCNN vs YOLO
读者好,在本文中,我将解释两种最广泛使用的对象检测算法及其实现。我还将提到我个人对这两种算法的体验,它们的易用性、便利性和局限性。希望这篇文章能对fast RCNN和YOLO的对比研究和实现有所启发。 首先,对象检测是识别图像中某些特定对象并使用边界框注释对象的过程。这是定位有用对象以供进一步使用(如分割)的过程。在计算机视觉行业中广泛使用的目标检测算法有很多,如 Fast RCNN(循环神经网
读者好,在本文中,我将解释两种最广泛使用的对象检测算法及其实现。我还将提到我个人对这两种算法的体验,它们的易用性、便利性和局限性。希望这篇文章能对fast RCNN和YOLO的对比研究和实现有所启发。
首先,对象检测是识别图像中某些特定对象并使用边界框注释对象的过程。这是定位有用对象以供进一步使用(如分割)的过程。在计算机视觉行业中广泛使用的目标检测算法有很多,如 Fast RCNN(循环神经网络)、SSD(单次检测器)、YOLO(你只看一次)、SPP(空间金字塔池化)等。但是在这里我将根据我的经验详细说明快速 RCNN 和 YOLO。
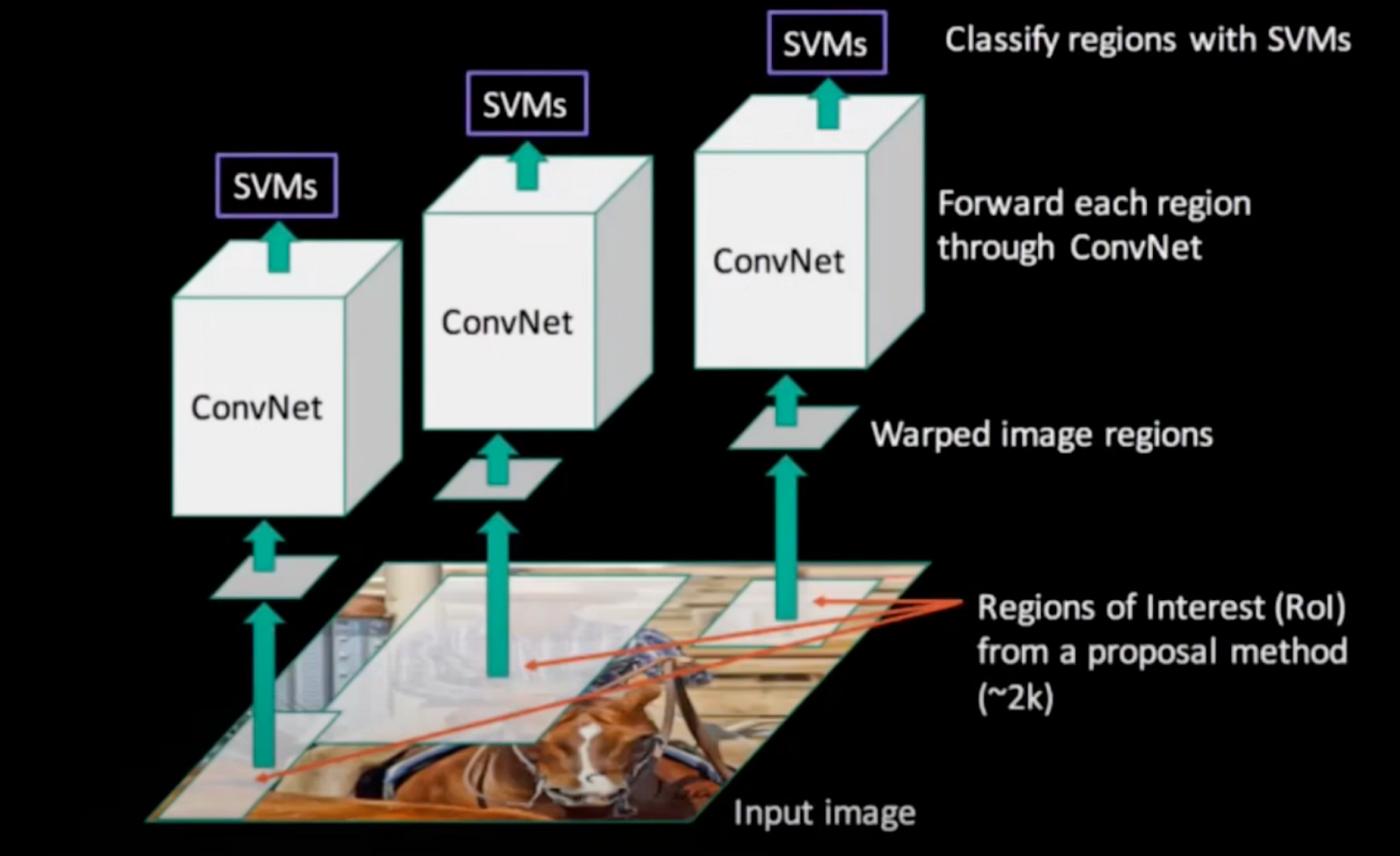
- Fast RCNN:在 RCNN 中,我们提供了一张包含多个对象的图像。然后选择性搜索算法将获取图像并从中创建大约 2000 个区域建议(边界框)。这些是扭曲的图像部分/边界框区域。然后它们被传递到 CNN 层。
来源:文章
考虑到上面的例子,图像内部识别出 3 个对象。每个对象的每个区域提案都经过卷积网络,然后 SVM 算法对图像进行分类。这就是基本 RCNN 的功能。创建感兴趣区域的算法,它们不是自己学习的,它们是随机选择的,这样可以创建 2000 个区域建议。因此,为了克服这一限制,引入了快速 RCNN。
来源:文章
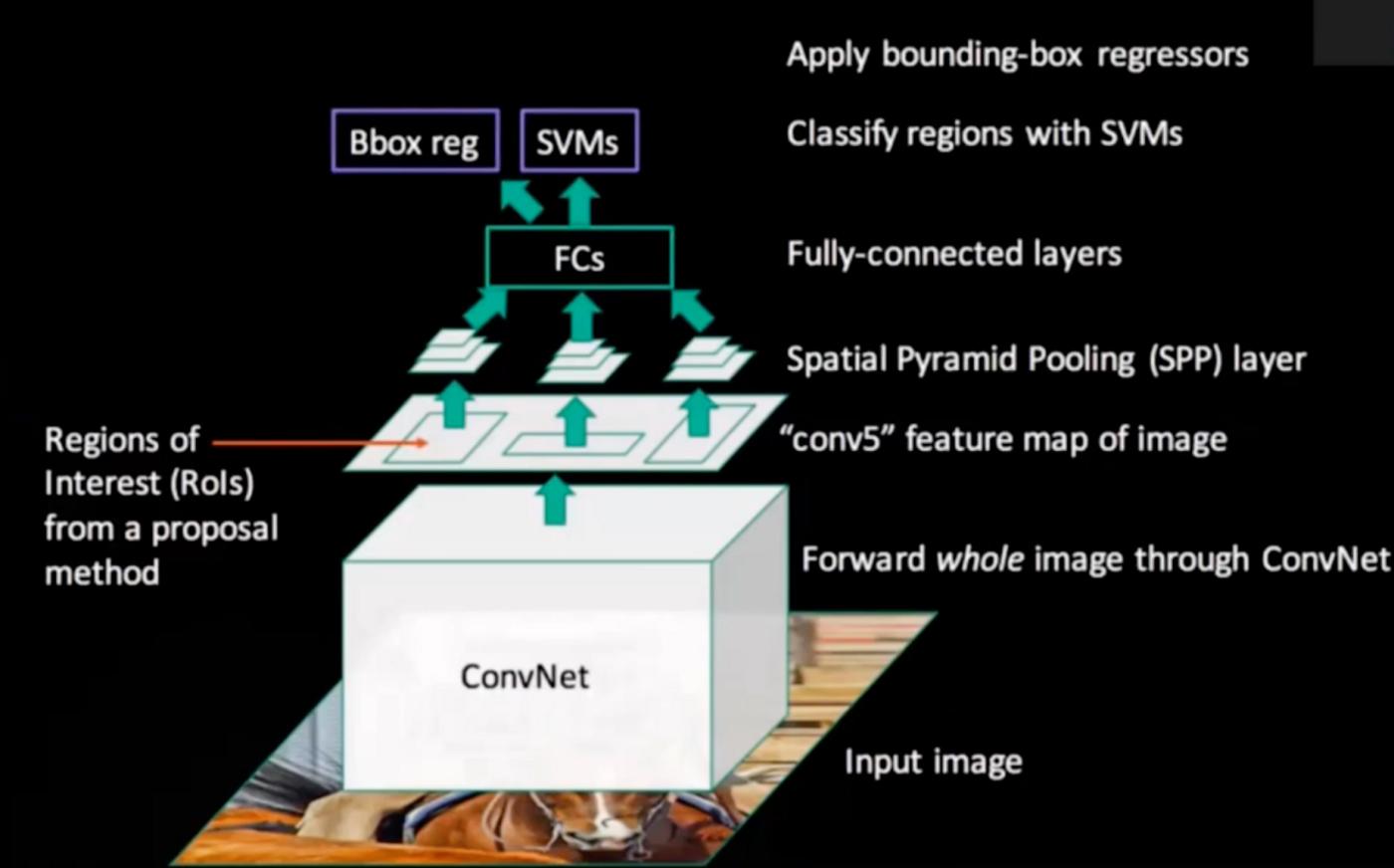
没有考虑 2000 个区域建议,而是将所有子图像/边界框作为完整图像。然后它们被传递到 CNN 层。一旦我们得到一个特征图作为卷积层的输出,它就会被传递到 CNN 的 ROI 池化层。 ROI pooling 层确保正在创建的所有特征图具有相同的图像大小。然后,将输出转发到 FC 层,它在激活函数(Softmax)的帮助下完成图像分类任务并给我们边界框。但是,这种方法没有任何算法可以为图像选择感兴趣的区域。
来源:文章
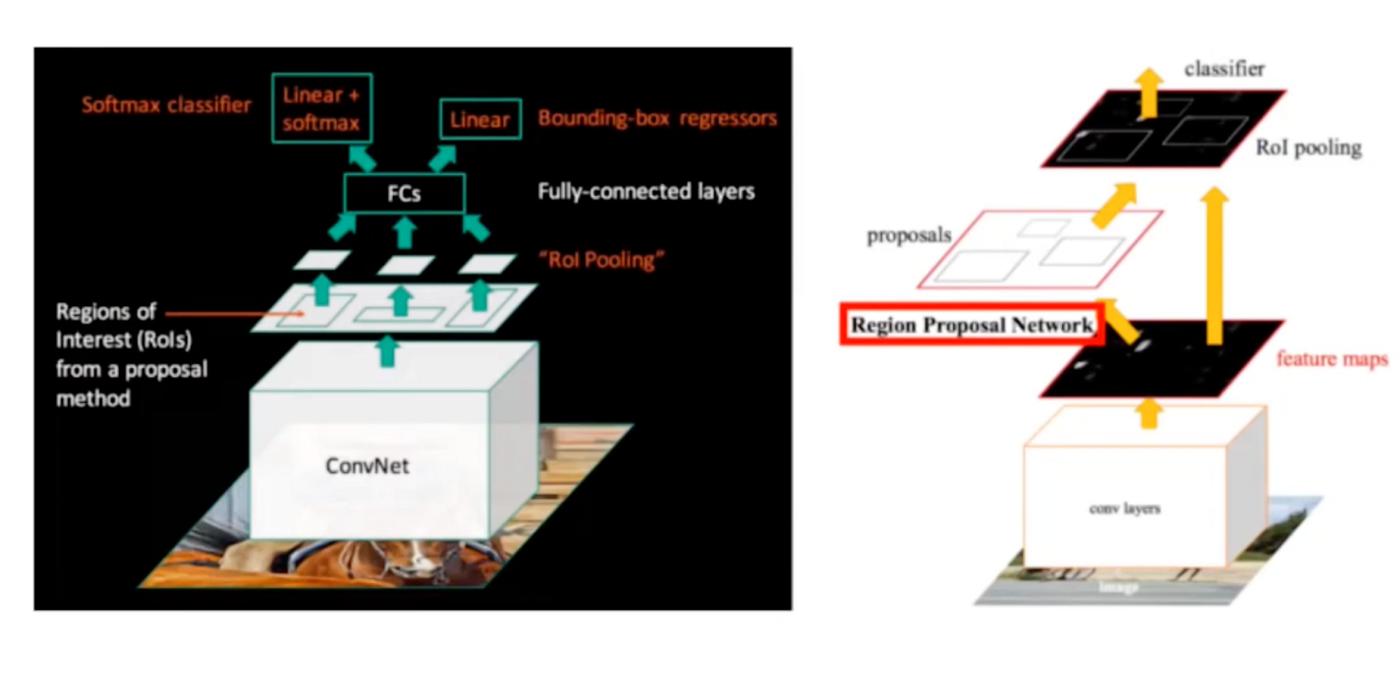
因此,引入了更快的 RCNN。它通过添加一个额外的神经网络层消除了 RCNN 和快速 RCNN 的限制。与快速 RCNN 类似,整个图像被传递到 CNN 层。第一个神经网络称为区域提议网络,其中选择感兴趣的区域。区域提议用于给出适当的边界框。该输出将再次传递到第二个神经网络层,该层使用 SVM 对图像进行分类并找出边界框。使用额外一层神经网络的目的是让神经网络自行学习并理解带注释的图像(带有边界框的图像)的模式。这就是更快的 RCNN 在 CNN 的双层上工作的方式,从而简化了任务。
我使用更快的 RCNN 来检测货架图中的间隙。我还使用 Detecto 包来完成基于 Pytorch 构建的任务。它使用更快的 RCNN Resnet50。它是一种深度学习网络架构。
您将需要的数据:图像、XML 标签文件
在用 10 个 epoch 训练模型后,这是我得到的结果:


2\。 YOLO(You Only Look Once):第二个最广泛使用的方法是 YOLO。它是一种广泛应用于计算机视觉的目标检测算法。 YOLO 共有三个版本:YOLOV1、YOLOV2、YOLOV3。另外两个版本(YOLOV4、YOLOV5)是YOLOV1的升级版。 YOLO 中的对象检测是作为回归问题完成的,具有检测到的对象的可能概率。 YOLO 因其高速度、准确性和学习能力而广受欢迎。它涉及三种方法:
2.1 Residual blocks:在这种方法中,图像被分成多个网格。每个网格具有相同的尺寸(S x S)。每个网格单元都有助于检测其中存在的对象。
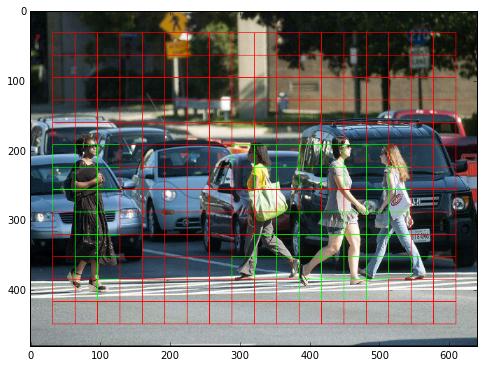
2.2 边界框:边界框强调图像中存在的对象。它定位对象并在其周围绘制一个具有特定高度和宽度的边界框。每个边界框都有与之关联的类。边界框具有以下坐标:x u003d (pc, ax, ay, aw, ah,
在哪里
ax : 起点的x坐标
ay : 起点的y坐标
aw : 宽度
啊:高度
pc : 盒子的中心
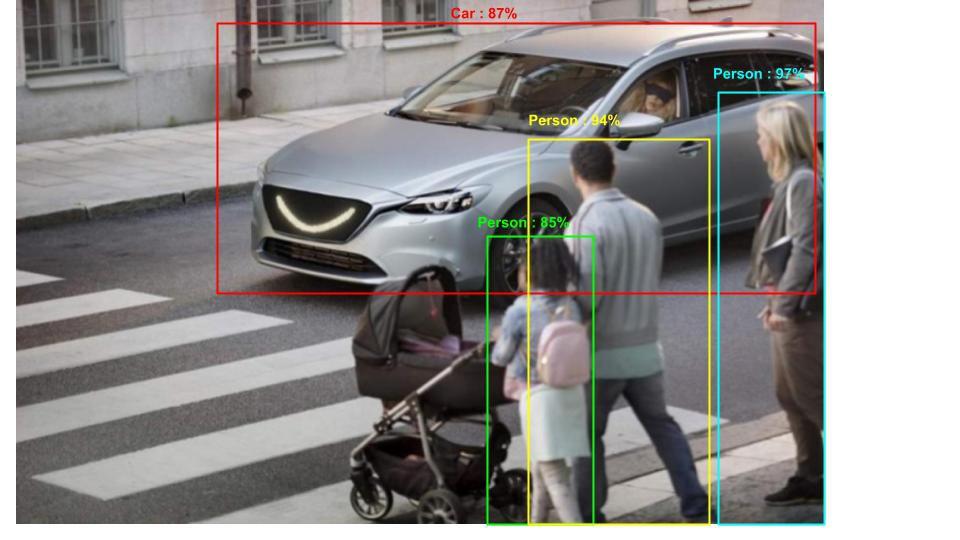
2.3 Intersection over union (IOU):IOU 是一种详细说明边界框如何重叠的技术。 YOLO 使用 IOU 来找出哪些边界框完美地放置在对象周围。如上所述,每个网格负责预测其中的对象。如果预测的边界框与真实的边界框完全匹配,则 IOU 等于 1。此技术还消除了与真实框不匹配的边界框。

我在同一个数据集上使用 YOLOV5 来完成相同的任务来比较结果。
您将需要的数据:图像、XML 标签文件、data.yaml(它将包括您的火车的路径、测试目录和有关课程的信息)
用 10 个 epoch 训练模型后,这是我的模型的结果:


因此,我个人认为 YOLOv5 是完成这项任务的更好模型。
而已 !我真的希望您发现这些信息很有用,并且通过实施,您可以简要了解快速 RCNN 和 YOLO 的比较见解。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 1
1 0
0- 0



 已为社区贡献20434条内容
已为社区贡献20434条内容

所有评论(0)