
异常值。检测和去除异常值的方法
异常值
这篇文章是关于什么是数据集中的异常值,什么是异常值类型,如何检测和处理异常值用 Pandas 和 Python。
什么是异常值?

异常值,作者绘制
异常值是与其他观察结果显着不同的数据点。异常值会扭曲特征分布,ML 会显着发挥作用,因此我们需要观察并形成处理它们的策略。
异常值如何弹出?
出现此类观察的原因可能是:
-
测量方法的差异,例如传感器的灵敏度发生了变化;
-
实验错误,异常值可能是数据收集过程中的错误结果;
-
新工艺引进;
-
数据收集阶段或数据处理期间出错;
-
或观察方差的指标。
根据异常值的性质,您可以保留或排除它们,例如如果出现实验错误,您希望删除它们。
异常值的类型有哪些? 异常值有 3 种类型:
- 全局: 也称为点异常值。这种观察远远超出了整个数据集。例如:一个班级,所有学生年龄相同,但有一个学生年龄500岁的记录。
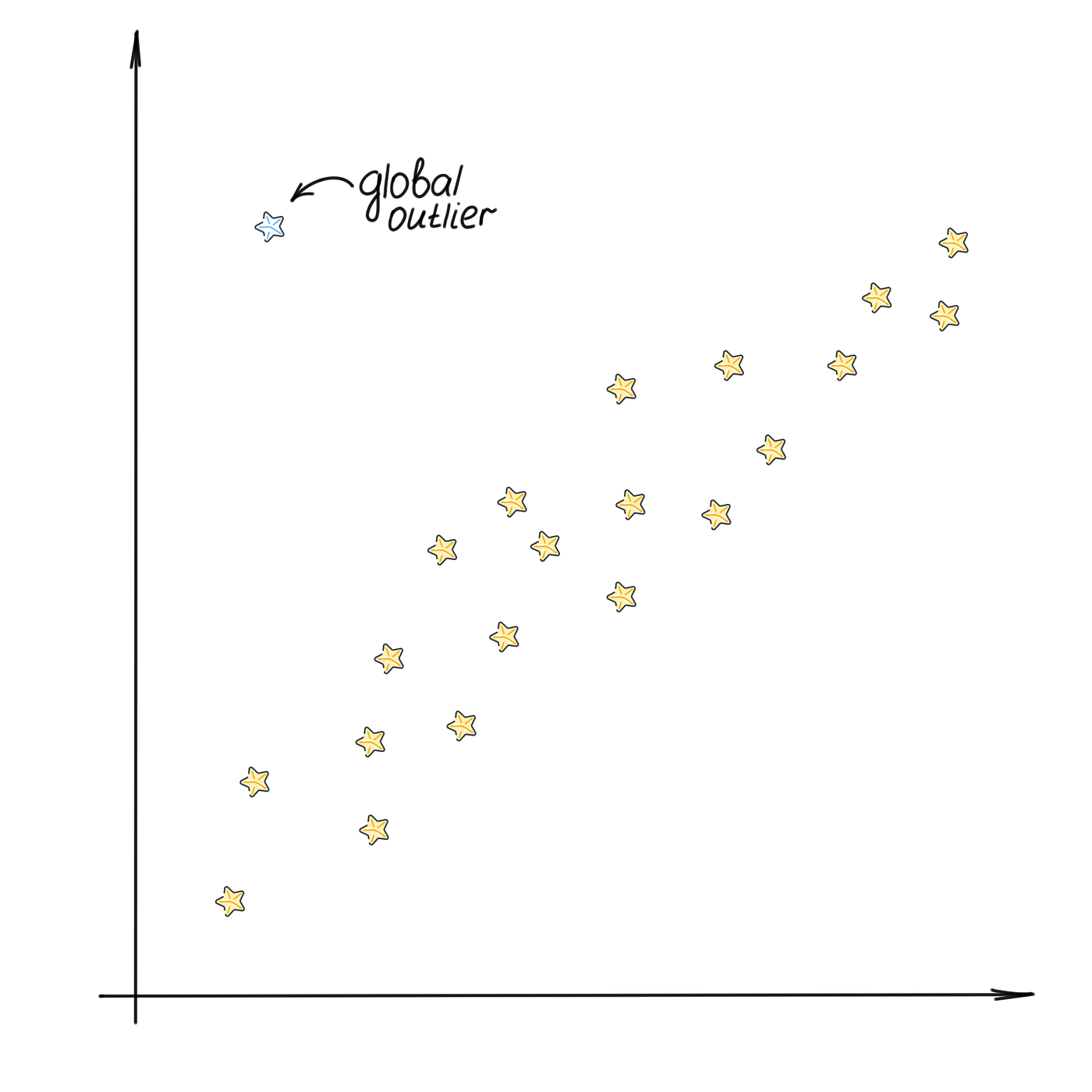
全局异常值,作者绘制
2\。有条件的:在给定上下文的情况下,观察被认为是异常的。例如,由于全球经济危机,一个国家的经济表现急剧下降,一段时间内较低的利率成为常态。
**3\。集体:**一组彼此接近且具有接近异常值的观察值。如果这些值作为一个聚合值显着偏离整个数据集,则认为点的子集是异常的,但单个数据点的值本身在上下文或全局意义上都不是异常的:
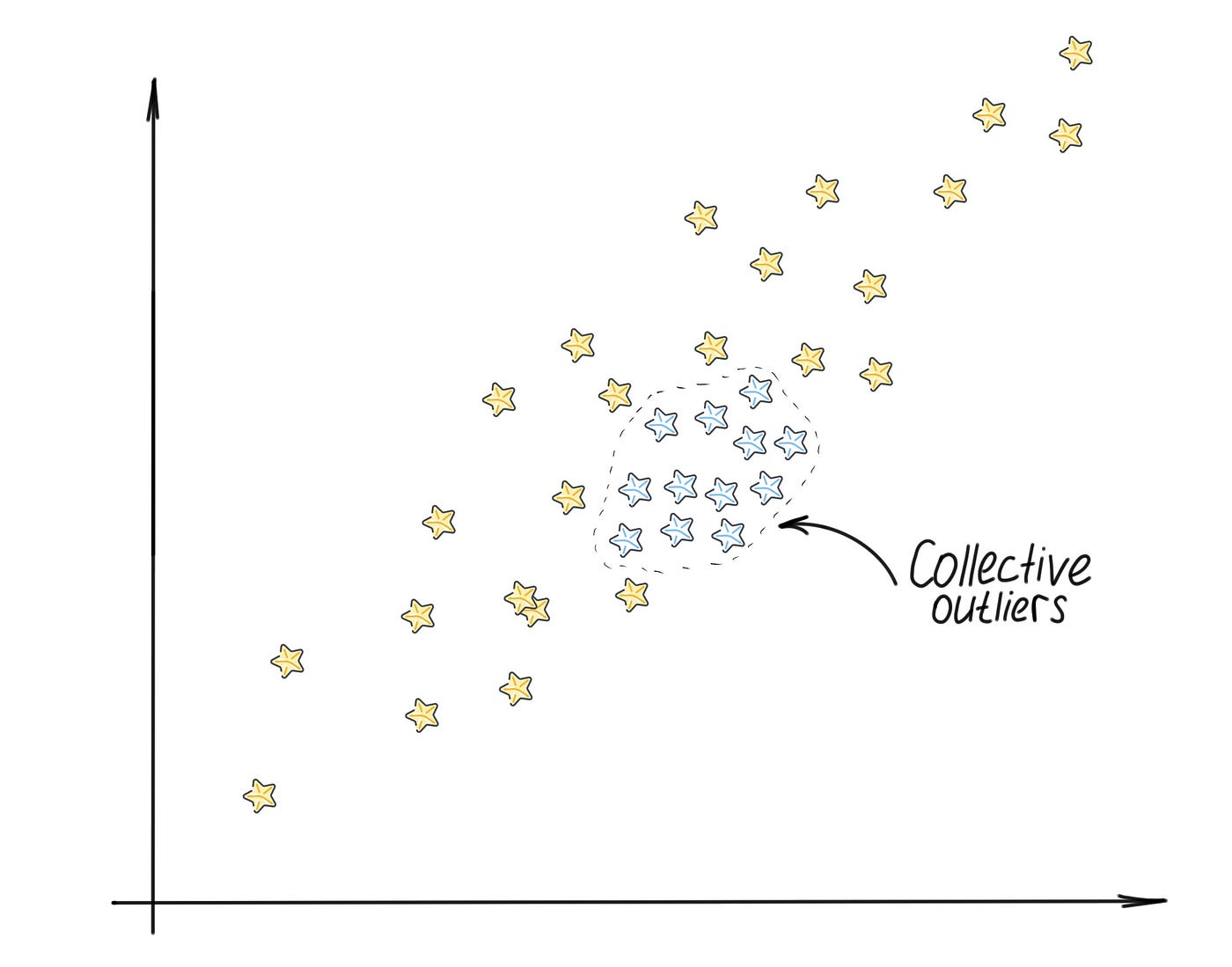
集体异常值,作者绘制
为什么识别异常值很重要? 机器学习算法对值的范围和分布很敏感。异常值会误导 ML 模型,导致训练时间更长、准确性更低,最终结果更差。但是,并非所有 ML 工作都受到异常值的影响,对于某些算法,您可以放心地忽略它们。
-
异常值敏感算法:线性回归、逻辑回归、支持向量机
-
Outliers Immune Algorithms:所有基于树的或复杂的算法
在业务方面,您应该旨在了解为什么存在异常值,并且您可以将其删除。例如,如果您有一个表示一个人身高的特征,并且其中一个观测值包含一个具有奇怪值(例如 u003d“abc cm”)而不是数字的字符串,并且由于高度不能包含这样的值,放下它是安全的。
如何检测异常值?
您可以利用不同类型的视觉效果轻松发现异常值:
1.箱线图
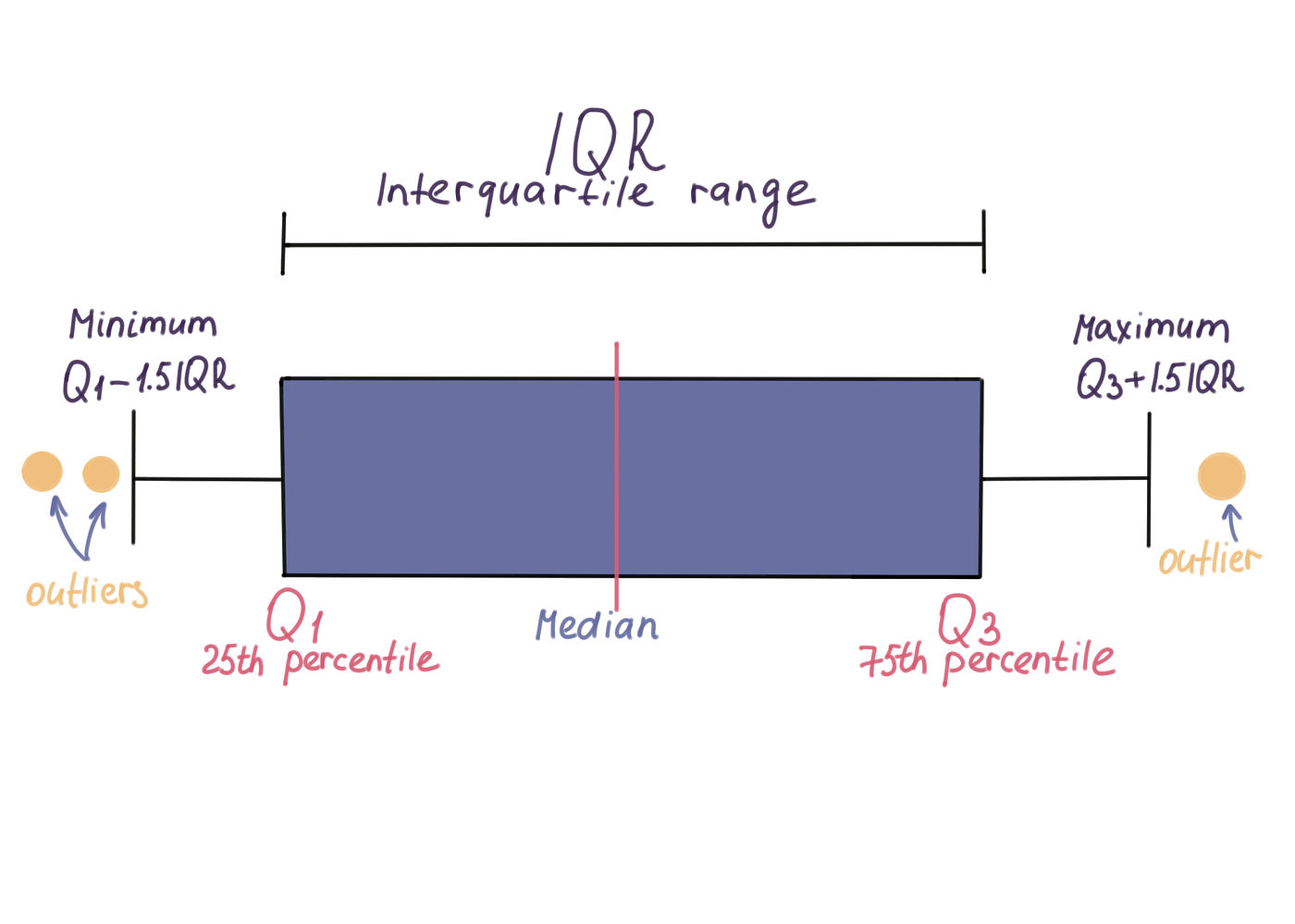
箱线图,作者绘制
这是箱线图显示的内容:
-
中位数是排序序列中心元素的值。请注意,中位数受异常值的影响较小,因此显示在中心的是中位数,而不是算术平均值。
-
前四分位数(Q3 或 75%)是只有 25% 的值高于该分数的分数。下四分位数(Q1 或 25%)是只有 25% 的值低于该值的值。
-
四分位距 (IQR) 是 75% 和 25% 四分位数之间的差。在这个范围内是 50% 的值。例如,如果范围很窄,则子组的成员在他们的评估中是一致的。如果它是广泛的,那么就没有同质的意见。
基于上述情况,您通常可以检测到高于“25% 百分位数 - 1.5 x IQR”或低于“75% 百分位数 + 1.5 x IQR”的异常值,如上图所示。
2.直方图
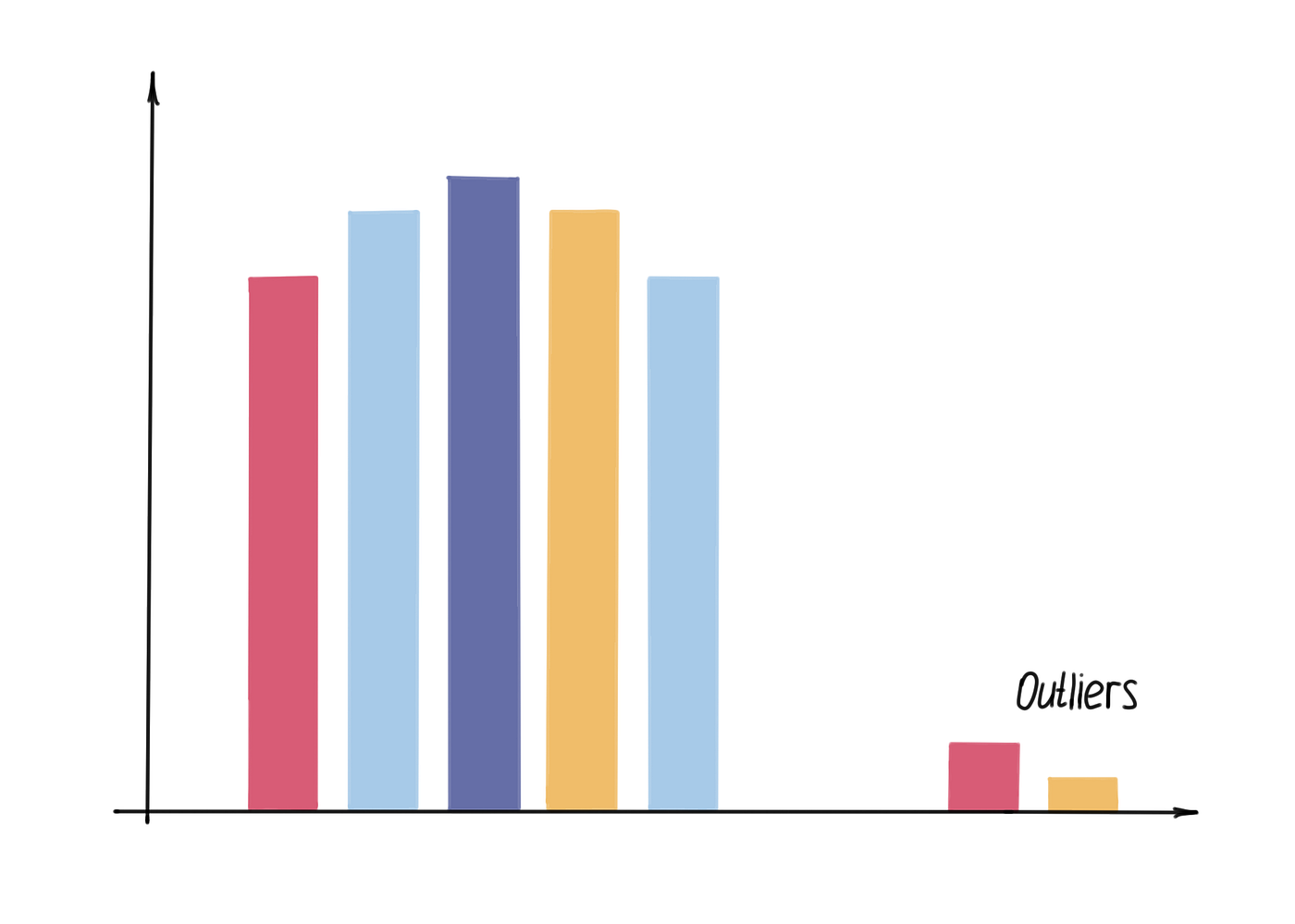
直方图,作者绘制
直方图将数值数据聚合到称为 bin 的均匀分布的组中,并显示每个 bin 中值的出现频率。使用数字字段或百分比/比率字段创建条形图。直方图有助于回答以下问题:值的分布是什么?它们在数据集中出现的频率如何?
通过增加和减少 bin 的数量,您可以影响数据的分析方式。虽然数据本身没有改变,但它的外观可能会改变。选择正确的 bin 数量对于正确解释数据中的模式很重要。太少的 bin 会隐藏一些模式,而太多的 bin 会夸大可接受的小数据变化的价值。正确数量的 bin 将显示使用大 bin 时不可见的模式。
3\。散点图
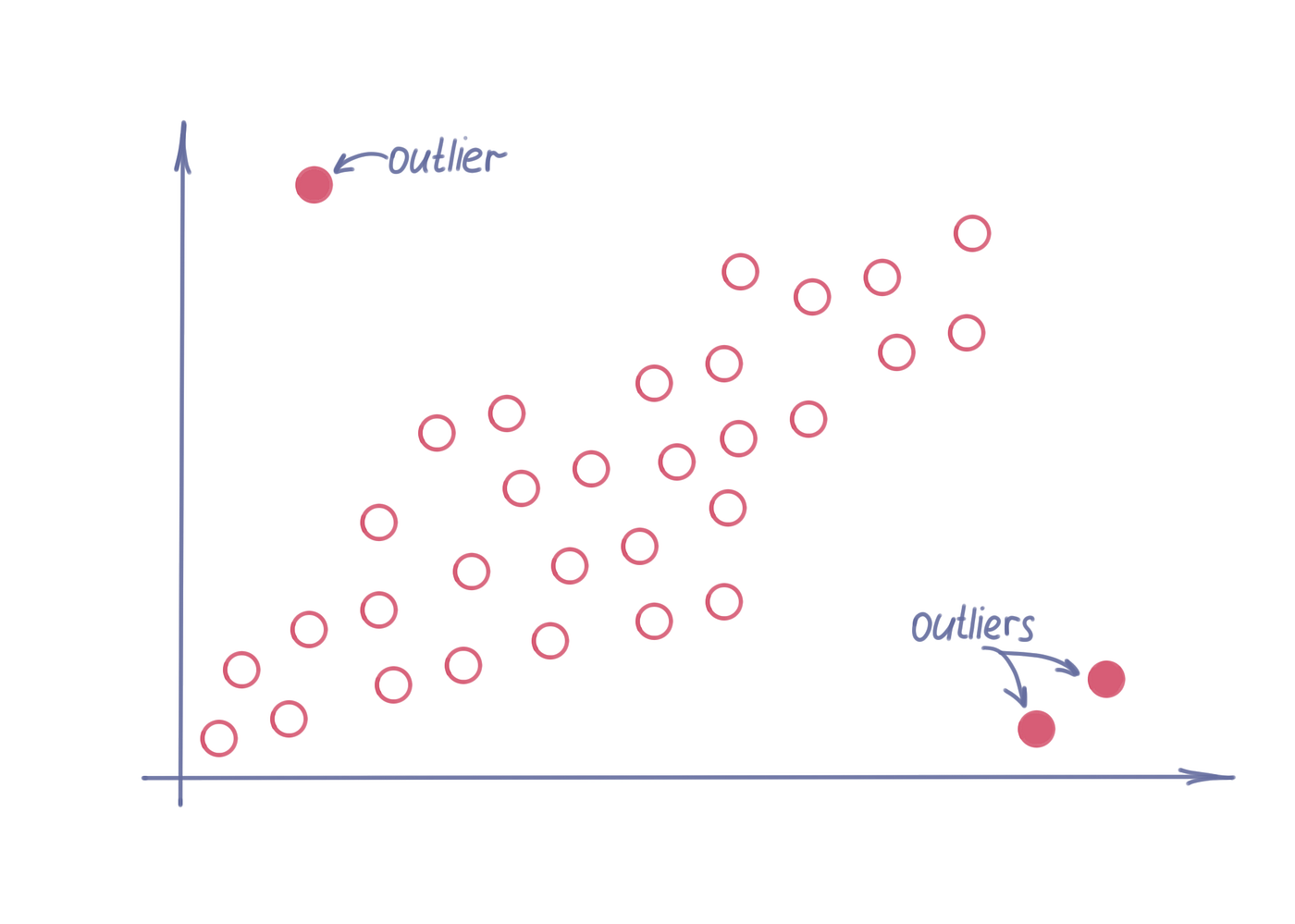
散点图,作者绘制
散点图显示了两个变量之间集合元素的分布。一个独立参数的值沿 X 轴绘制,第二个相关参数的值沿 Y 轴绘制。
散点图上显示的模式允许您查看不同类型的相关性。从点的一般聚类/相关线显着移除的点称为异常值。
4\。Z 分数
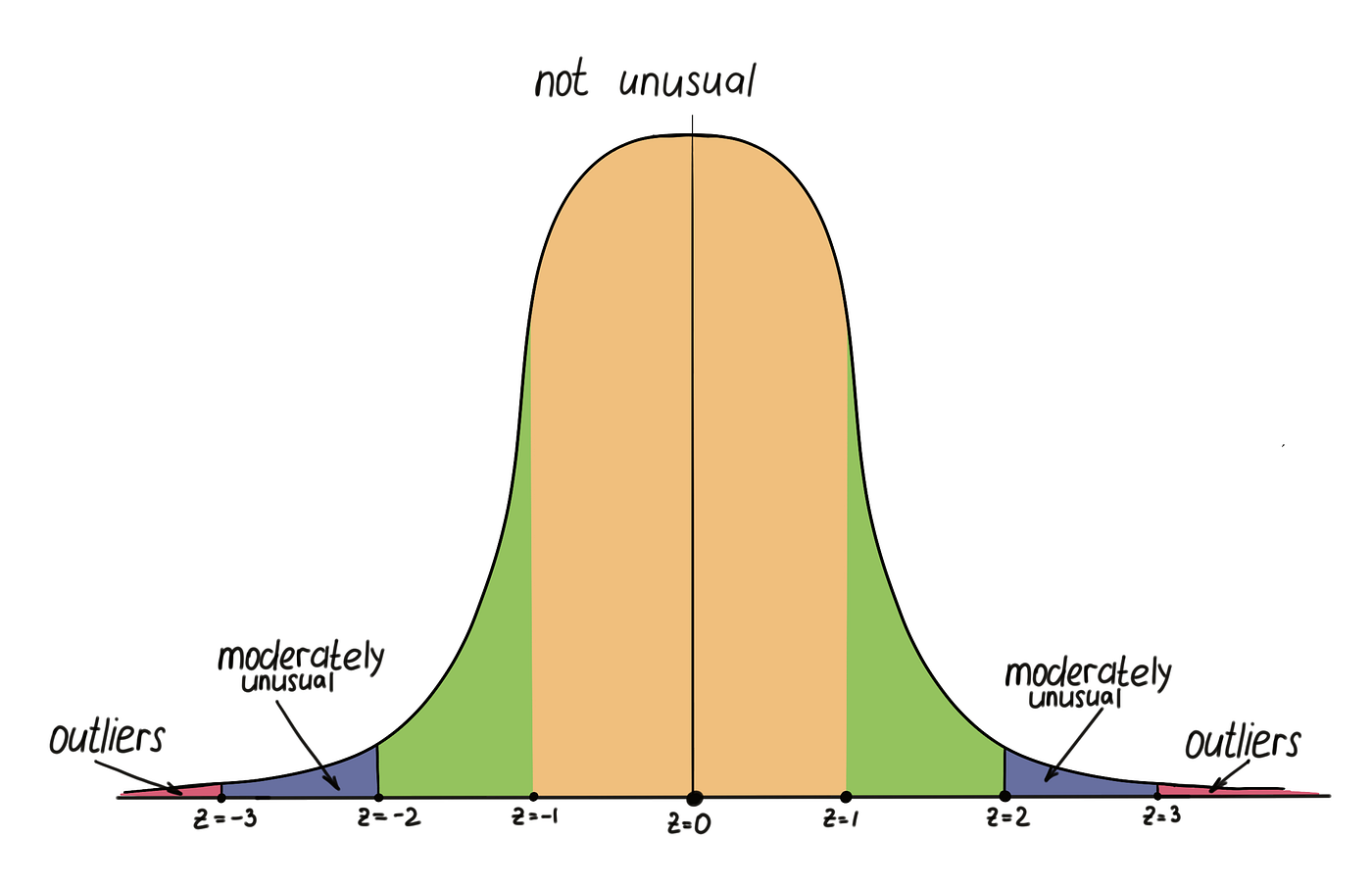
Z-score,作者绘制
z 分数也可以称为标准分数,表示数据相对于平均值的分布。该分数表示低于或高于给定总体的标准差。
z的值可以在钟形曲线上看到。其中 Z 分数范围从 -3 个标准差(正态分布曲线的最左角)到 +3 个标准差(正态分布曲线的最右角)。在大多数情况下,大于或小于 -+3 的值被识别为异常值。
如何处理异常值?
一旦检测到数据集中的异常值,您将执行以下 3 个操作:
-
去除异常值。通常,如果您非常清楚数据应该落在什么范围内(例如人们的年龄),则可以删除异常值,您可以安全地删除该范围之外的值。
-
更改异常值(例如用平均值或最大上限值替换该值,例如 90% 百分位)
-
保留它。您不应该以删除异常值为目标,例如,如果您的数据中有 20%-40% 是异常值,那么它不一定被视为异常值,相反,您应该进一步研究它。
入门
在我们开始动手之前,一些准备工作:
1.我使用Kaggle环境运行代码,如果你以前没有使用过Kaggle,建议你阅读这篇文章。
-
我们将使用All Lending Club 贷款数据来查找和处理异常值。
-
你可以在这里找到 Kaggle 笔记本。
异常值 Python 动手实践
让我们加载数据集并导入所有必需的包:
#加载包并设置 pd 格式 %matplotlib inline
from matplotlib import pyplot as plt pd.set_option('display.float_format', lambda x: '%.0f' % x) #load dataset loan u003d pd.read_csv('../ input/lending-club/accepted_2007_to_2018Q4.csv.gz', compressionu003d'gzip', low_memoryu003dTrue) #仅考虑关键业务 特征贷款 u003d 贷款[['贷款_amnt','term','int_rate','sub_grade','emp_length','home_ownership','annual_inc','loan_status','addr_state', 'dti','mths_since_recent_inq','revol_util','bc_open_to_buy','bc_util','num_op_rev_tl']] * #remove 缺失值* loan u003d loan.dropna()
请注意,如果您是初学者数据科学家,我建议您阅读我在同一数据集此处上编写的缺失值处理文章。
查看特征分布的最简单方法是绘制直方图。它会立即让我们了解极端异常值。 Pandas .hist 帮助我们完成这项任务:
贷款.hist(bins u003d 10, figsize u003d (20,10), color u003d 'black')
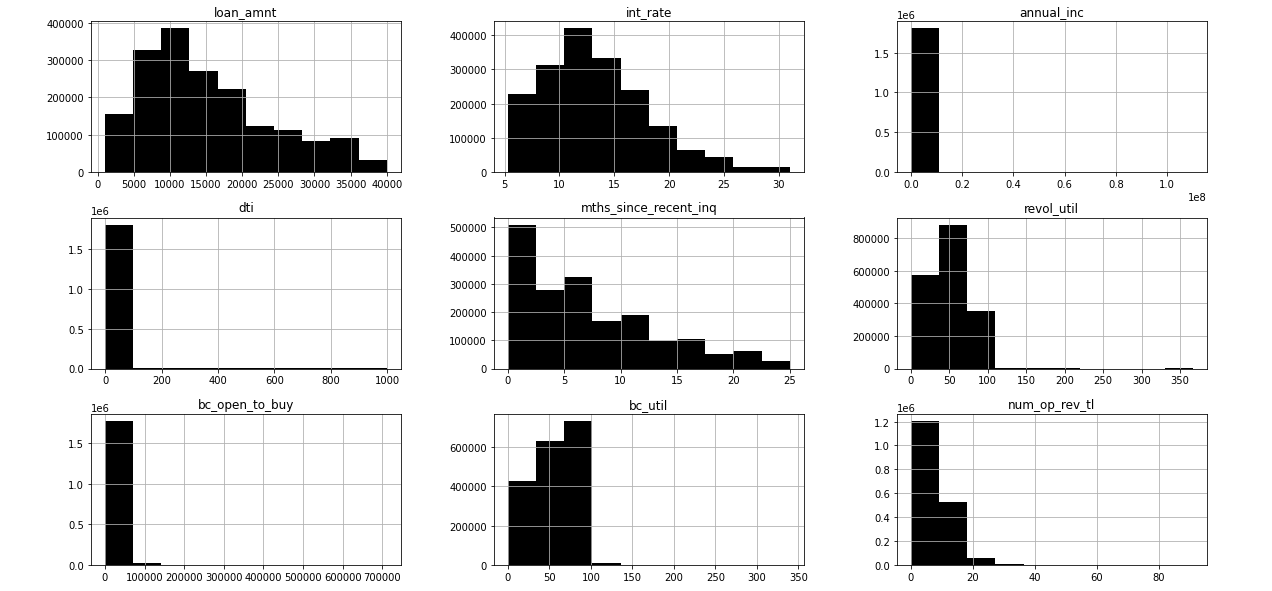
代码输出截图
我们可以看到annual_inc, dti, revol_util, bc_open_to_buy, bc_util, num_op_rev_ti特征有明显的异常值,这些异常值远远超出了大多数正常的观察值。例如,我们可以看到,在 year_inc 特征中,大多数观察值都远低于每年 200K 美元,而有少数申请人的收入高达 1 MM 美元,为什么有这样收入的申请人会寻找3万美元贷款?
直方图让我们能够立即了解分布和极端异常值,同样,我们可以使用箱线图:
%matplotlib inline from matplotlib import pyplot as plt num_cols u003d ['loan_amnt', 'term','int_rate', 'sub_grade', 'emp_length','home_ownership', '年度_inc','loan_status','addr_state','dti','mths_since_recent_inq','revol_util','bc_open_to_buy','bc\ _util', 'num_op_rev_tl' ] plt.figure(figsizeu003d(18,9))
贷款[num_cols].boxplot()
plt.title("借贷俱乐部数据集", fontsizeu003d20)
plt.show()
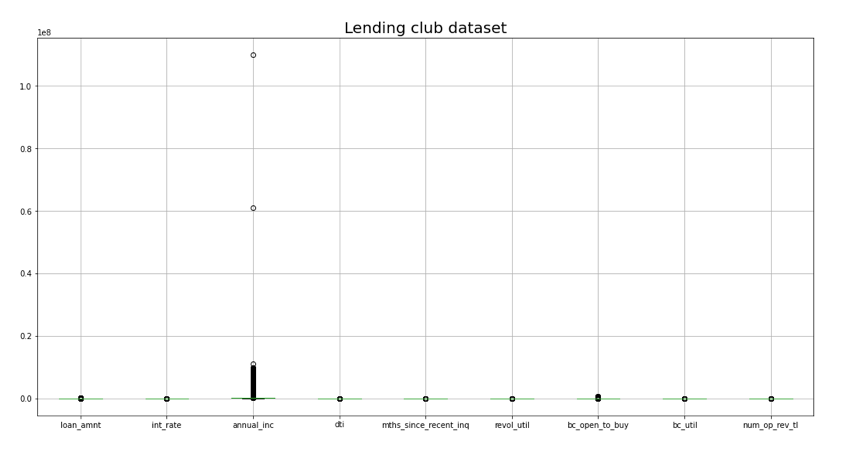
代码输出截图
让我们以“annual_inc”特征为例,以更好地了解内部的观测范围。 Pandas .describe 函数可以快速返回给我们统计见解:
贷款.年度_inc.describe()
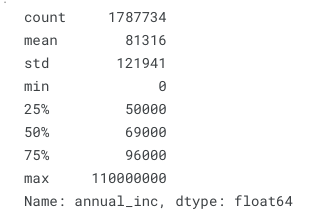
代码输出截图
我们看到annual_inc中观察的最大值是 11 MM 美元,这可能无法描述我们申请贷款的人群。在业务方面,我们可能不需要预测这种情况,这种逻辑让我们有信心放弃这些类型的异常值。
第一种方法——极端异常值修剪
最简单的方法是对极端异常值进行微调或修剪。例如,98% 的缩尾法突出显示所有大于 99 个百分位的观测值和所有小于 1 个百分位的观测值。在 Winsorization 中,您只需分配相同的百分位高于或低于您检测到异常值,而不是删除观察值。
但是,这两个收入为 11 MM USD 的极端申请人的特征可能无法很好地描述剩余人口,因此我们最好将这些申请人完全删除。这就是我们使用修剪的地方。
q_low u003d 贷款[“年度_inc”].quantile(0.01)
q_hi u003d 贷款["annual_inc"].quantile(0.99) 贷款_extreme u003d 贷款[(loans["annual_inc"] < q_hi) & (loans["annual\ _inc"] > q_low)] num_cols u003d ['annual_inc']
plt.figure(figsizeu003d(18,9))
贷款_extreme[num_cols].boxplot()
plt.title("数值变量", fontsizeu003d20)
plt.show()
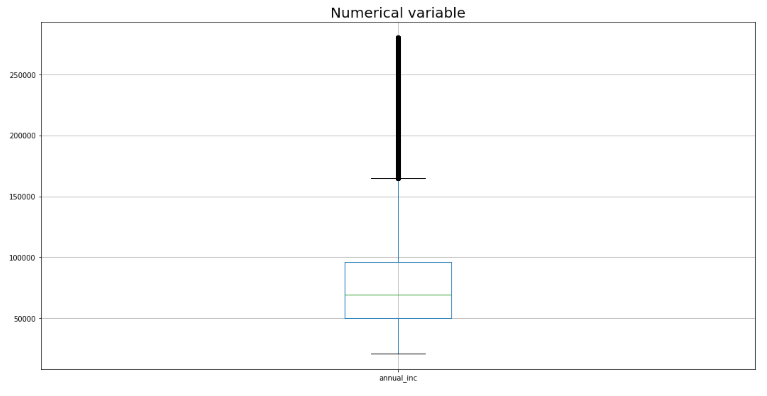
代码输出截图
在这种方法中,我们可以通过手动调整所需的百分位数来快速去除极端异常值。
第二种方法——基于 IQR 范围的异常值
另一种方法是检测高于“25% 百分位数减去 1.5 x IQR”和低于“75% 百分位数加上 1.5 x IQR”的异常值。
Q1 u003d 贷款[“年度_inc”].quantile(0.25)
Q3 u003d 贷款[“年度_inc”].quantile(0.75)
IQR u003d Q3 - Q1 贷款_iqr u003d 贷款[((loans["annual_inc"] >u003d (Q1 - 1.5 * IQR)) & (loans["annual_inc"] <u003d ( Q3 + 1.5 * IQR)))] num_cols u003d ['annual_inc']
plt.figure(figsizeu003d(18,9))
贷款_iqr[num_cols].boxplot()
plt.title("数值变量", fontsizeu003d20)
plt.show()
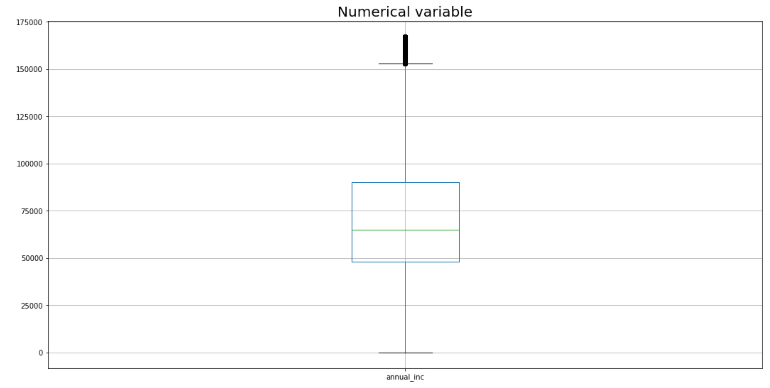
代码输出截图
在这种方法中,大量观察被标记为异常值 (~5%),例如,年收入为 200,000 美元的申请人也被标记为异常值。此外,这一人群保留了自己的特点,例如,薪水较高的申请人往往具有较低的债务收入比,这将导致较低的利率和较低的风险。
第三种方法——基于 z-score 的异常值
贷款_zscore u003d贷款[“年度_inc”]
z u003d np.abs(stats.zscore(loans_zscore))
贷款_zscore u003d pd.concat([loans_zscore, z], axisu003d1) 贷款_zscore.columns u003d ['annual_inc', 'z_score'] 贷款_zscore u003d 贷款_zscore [(loans_zscore.z_score < 3) & (loans_zscore.z_score > -3)] num_cols u003d ['annual_inc'] plt.figure(figsizeu003d(18, 9))
贷款_zscore[num_cols].boxplot()
plt.title("数值变量", fontsizeu003d20)
plt.show()
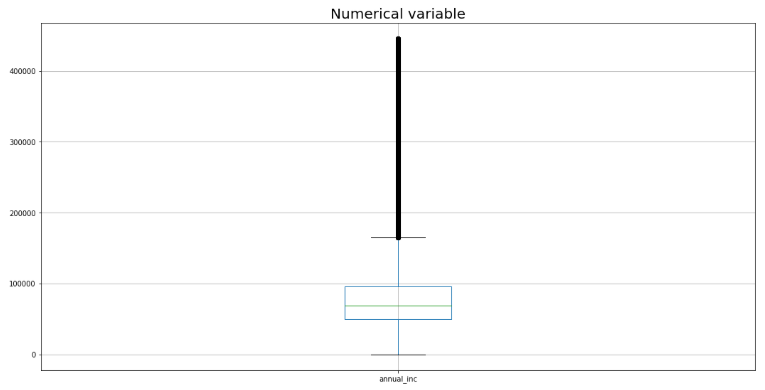
代码输出截图
根据您的业务逻辑,您可以决定什么是正确的方法,或者什么是正确的削减百分比,以保留您的模型将要针对的正确人群。选择正确的方法并在数据集中应用剩余的特征!
笔记本参考:
[
检测并去除异常值
使用 Kaggle Notebooks 探索和运行机器学习代码 |使用来自 All Lending Club 贷款数据的数据
www.kaggle.com
](https://www.kaggle.com/code/mariiagusarova/detect-and-remove-the-outliers/notebook)
感谢您的阅读。我写适合初学者的文章。你想尝尝成为数据科学家的感觉吗?我正在为那些以前从未体验过数据科学的人创建一个端到端的数据科学项目。通过完成这个项目:1)您将亲自体验整个数据科学周期,并且您将能够理解您是否想成为一名数据科学家,2)您将开发一个可以用于面试的项目,或者您自己的自由职业者作为投资组合工作,并且 3)如果您决定从事数据科学家的职业,您将回答最流行的面试问题。
在您的早期旅程中,您遇到了什么困难?在这里与我分享,我很乐意提供帮助!我仔细聆听您的故事,并希望制作能够帮助您度过这段旅程的内容。
更多类似的内容,注册我的时事通讯。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20425条内容
已为社区贡献20425条内容

所有评论(0)