
使用 PySpark 和 Dataproc Serverless 处理从 Hive 到 GCS 的大型数据表

Dataproc 模板允许我们使用 Java 和 Python 在 Dataproc Serverless 上运行常见用例,而无需自己开发。这些模板实现了常见的 Spark 工作负载,让我们可以轻松地自定义和运行它们。
如果您是 Dataproc Serverless 的新手,或者您正在寻找 PySpark 模板以使用 Dataproc Serverless 将数据从 GCS 迁移到 BigQuery,则可以使用这篇博文。
另外,您可以参考我的另一篇博文将数据从 BigQuery 移动到 GCS。
在这篇博文中,我们将讨论如何使用 Dataproc Serverless 处理从 Hive 到 GCP 的大量数据。
先决条件
为了运行这些模板,我们需要:
-
谷歌云SDK安装并认证
-
Python 3.7+ 已安装
-
启用了私有 Google 访问权限的 VPC 子网。只要启用了私人 Google 访问权限,默认子网就适用。您可以在此处查看所有 Dataproc 无服务器网络要求。
主要优点
-
使用 Dataproc Serverless 运行 Spark 批处理工作负载,无需预置和管理您自己的集群。
-
HiveToGCS模板是开源的,完全可定制,可用于简单的工作。
-
您可以以 Parquet、AVRO、CSV 和 JSON 格式将数据从 Hive 摄取到 GCS。
配置参数
此模板包含以下参数来配置执行:
-
spark.hadoop.hive.metastore.uris:Hive 元存储 URI 的 spark 属性 -
hive.gcs.input.database:输入表的 Hive 数据库 -
hive.gcs.input.table:Hive 输入表名 -
hive.gcs.output.location:输出文件的 GCS 位置(格式:gs://BUCKET/...) -
hive.gcs.output.format:输出文件格式。之一:avro、parquet、csv、json。默认为镶木地板 -
hive.gcs.output.mode:输出写入模式。之一:附加、覆盖、忽略、errorifexists。默认为追加。您可以在此处了解每种保存模式的行为。
用法
- 创建一个 GCS 存储桶以用作 Dataproc 的暂存位置。 Dataproc 将使用此存储桶来存储运行我们的无服务器集群所需的依赖项。
导出暂存_BUCKETu003d”我的暂存桶”
gsutil mb gs://$STAGING_BUCKET
2\。克隆 Dataproc 模板存储库并导航到 Python 模板的目录
git clonehttps://github.com/GoogleCloudPlatform/dataproc-templates.git
cd dataproc-模板/python
3\。配置 Dataproc 无服务器作业
要将作业提交到 Dataproc Serverless,我们将使用提供的bin/start.sh脚本。该脚本要求我们使用环境变量配置 Dataproc Serverless 集群。
强制配置是:
-
GCP_PROJECT:运行 Dataproc Serverless 的 GCP 项目。 -
REGION:运行 Dataproc Serverless 的区域。 -
SUBNET:Hive Metastore 所在的子网 -
GCS_STAGING_LOCATION:Dataproc 将存储暂存资产的 GCS 位置。应该在我们之前创建的存储桶中。
# 运行 Dataproc 无服务器作业的项目 ID
export GCP_PROJECTu003d<project_id># 应提交作业的 GCP 区域
export REGIONu003d<region># 存在 Hive 元存储的子网,因此可以在同一子网中启动作业
export SUBNETu003d<region># Dataproc 的暂存位置
导出 GCP\STAGING\LOCATIONu003dgs://$STAGING\BUCKET/staging
4\。执行 Hive To GCS Dataproc 模板
配置作业后,我们就可以触发它了。我们将运行 bin/start.sh 脚本,指定我们要运行的模板和执行的参数值。
./bin/start.sh \
— propertiesu003dspark.hadoop.hive.metastore.urisu003dthrift://<hostname-or-ip>:9083 \
— — 模板u003dHIVETOGCS \
— hive.gcs.input.databaseu003d”<数据库>” \
— hive.gcs.input.tableu003d”<table>” \
— hive.gcs.output.locationu003d”gs://bucket/path”\
— hive.gcs.output.formatu003d”<csv|parquet|avro|json>”\
— hive.gcs.output.modeu003d”<append|overwrite|ignore|errorifexists>”
注意:提交作业会要求您启用 Dataproc API(如果尚未启用)。
5\。监控 Spark 批处理作业
提交作业后,我们将能够在Dataproc Batches UI中看到。从那里,我们可以查看作业的指标和日志。
定时执行
除了通过 start.sh 脚本提交作业,您还可以选择设置作业的计划执行。当您想要在白天有新数据时定期从 Hive 移动到 GCS 时,此设置很有用。
需要考虑的重要一点是修改 HiveToGCS 模板以允许指定分区,因此您的计划作业以增量加载方式从最近的分区中读取数据。目前,模板可以支持全表的定时导出,输出模式为覆盖
在下面的示例中,我们将使用 Cloud Scheduler 来计划执行 dataproc 模板。 Cloud scheduler 是 cron 作业调度程序的 GCP 服务。
- 克隆 Dataproc 模板存储库并导航到 Python 模板的目录
git clonehttps://github.com/GoogleCloudPlatform/dataproc-templates.git
cd dataproc-模板/python
2\。运行以下命令创建 egg 文件并使用 gsutil 命令将文件上传到 GCS 存储桶,供 Cloud Scheduler 使用。还将 main.py 文件上传到同一个 GCS 存储桶
python setup.py bdist_egg — outputu003ddataproc_templates_distribution.egggsutil mb gs://{DEPENDENCY_BUCKET}gsutil cp dataproc_templates_distribution.egg gs://{DEPENDENCY_BUCKET}gsutil cp main.py gs://{依赖_BUCKET}
3\。让我们创建云调度程序作业:
- 打开Cloud Scheduler并点击 CREATE JOB

- 填写作业名称的详细信息。支持 HTTPS cron 作业的区域。对于这个博客,我们将使用 us-central1。还要填写Cron频率和时区您希望此作业运行,然后单击继续
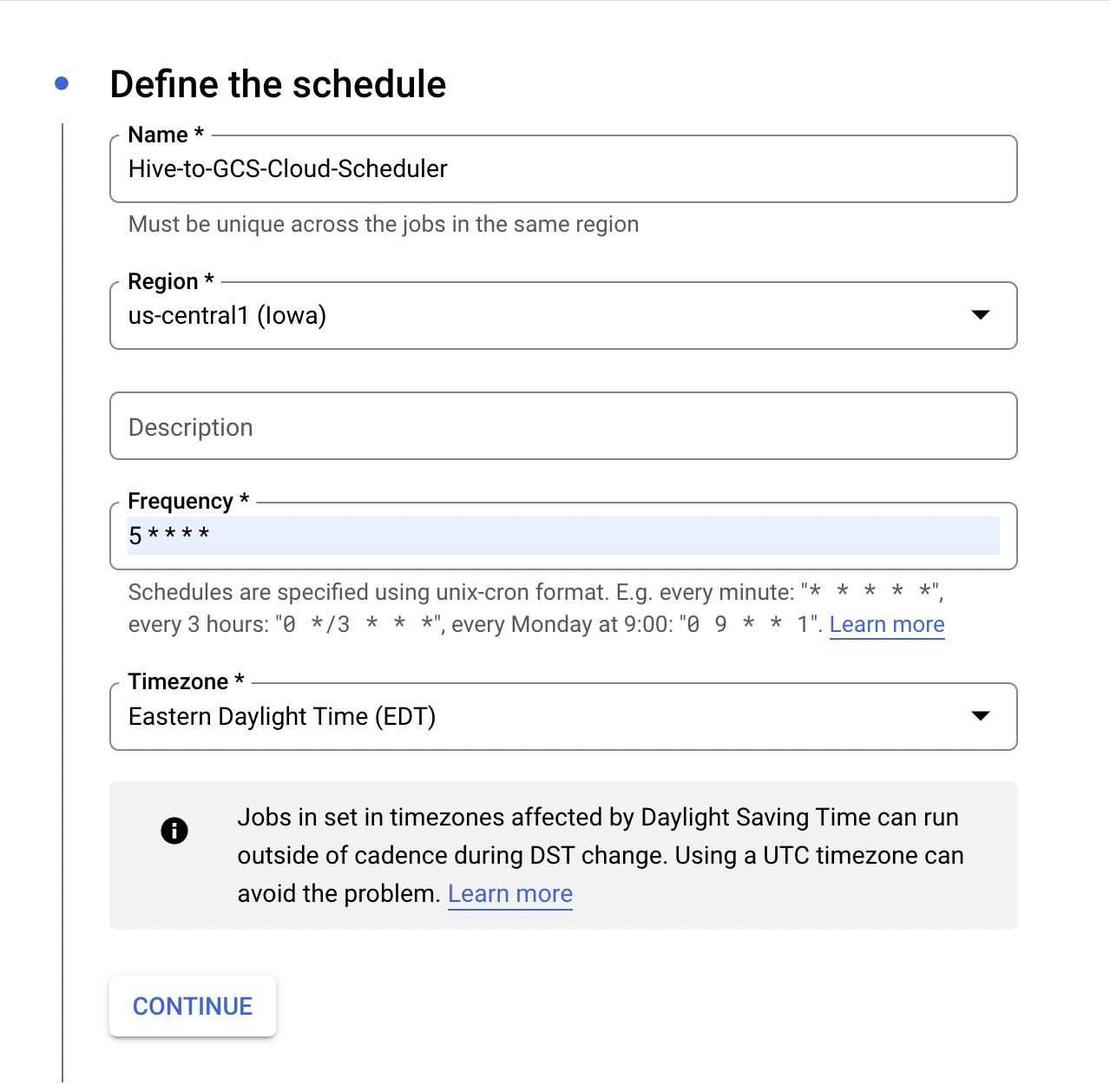
- 以下是发出 POST 请求以提交 dataproc 无服务器作业所需的 URL
https://dataproc.googleapis.com/v1/projects/{PROJECT_ID}/locations/{REGION}/batches
- 创建作业时需要提供的示例 JSON 正文。根据您的值编辑 JSON 正文
{“标签”:{“job_type”:“dataproc_template”},“runtimeConfig”:{“properties”:{“spark.hadoop.hive.metastore.uris”:“thrift://{hostname-or -ip}:9083”}},“environmentConfig”:{“executionConfig”:{“subnetworkUri”:“projects/{PROJECT_ID}/regions/{REGION}/subnetworks/{SUBNET}”}},“pysparkBatch” :{“mainPythonFileUri”:“gs://{DEPENDENCY_BUCKET}/main.py”,“args”:[“—templateu003dHIVETOGCS”,“—hive.gcs.input.databaseu003d{databaseName}”, “——hive.gcs.input.tableu003d{tableName}”,“——hive.gcs.output.locationu003d{gs://bucket/path}”,“——hive.gcs.output.formatu003d{csv|parquet |avro|json}”,“ — hive.gcs.output.modeu003d{append|overwrite|ignore|errorifexists}”],“pythonFileUris”: [“gs://{DEPENDENCY_BUCKET}/dataproc_templates _distribution.egg”],“jarFileUris”: [“file:///usr/lib/spark/external/spark-avro.jar”,“gs://spark-lib/bigquery/spark-bigquery-最新的_2.12.jar”]}}
- 填写详细信息后,页面如下所示。最后点击创建完成创建作业。
! zoz100076](https://devpress-image.s3.cn-north-1.jdcloud-oss.com/a/1e26bbb234_0*0UM7iLDQniNVf-Xh.jpg)
-
确保选择正确的身份验证标头/具有提交 Dataproc Serverless 作业的权限的服务帐户
-
一旦我们的工作被创建,它将按照定义的频率运行。我们也可以手动触发 Cloud Scheduler 作业(Force a job run)进行测试,然后在Dataproc Batches UI中监控执行的 dataproc 作业
参考文献
-
Dataproc 无服务
-
Dataproc 模板存储库

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)