
Python 模糊匹配的最佳库
字符串匹配变得简单
数据科学家在日常任务中必须处理各种数据。数据处理的最大挑战之一是非结构化数据。当数据不能以表格(结构化)方式表示时,称为非结构化数据。非结构化数据包括文本、音频、视频文件等。
文本数据通过使用特殊技术进行处理。一种这样的技术是模糊匹配。模糊匹配是指寻找字符串之间的相似性,这些相似性度量可以用于多种目的。模糊匹配可以通过多种算法完成,每种算法都有其优缺点。让我们在下面讨论这些算法。
常见的模糊匹配算法
模糊匹配用于检查两个字符串是否相同或不同,在后者的情况下,它们不同的因素是什么。模糊匹配通常被称为 edit-distance, 即字符串 A 需要编辑多少才能匹配字符串 B?有多种计算相似度度量的方法。让我们讨论三个最常见的。
- 列文斯坦距离
Levenshtein 距离于 1965 年由 Vladimir Levenshtein 首次使用。它通过计算将第一个字符串转换为第二个字符串所需的最小单字符编辑次数来确定两个字符串之间的相似性。 Levenshtein 将以下操作视为编辑:
1.加法
- 删除
3、换人
号越小。所需的编辑是,两个字符串越接近。
- ** Damerau–Levenshtein 距离**
Damerau-Levenshtein 的工作方式与传统的 Levenshtein 算法完全相同,但略有改进。除了上面提到的三个编辑之外,Damerau-Levenshtein 还考虑了转置。换位对应于交换两个相邻的字符,被认为是一个单一的操作。 Damerau 表示,这 4 种操作占所有人类拼写错误的 80%。
- 雅罗-温克勒距离
Jaro-Winkler 距离算法于 1990 年提出。它建立在 Jaro 相似度算法的基础上,该算法使用以下等式计算相似度。

Jaro相似方程
-
m u003d 匹配字符数
-
t 是换位次数的一半
-
|s1|和 |s2|分别是每个字符串的长度。
Jaro 相似度返回一个介于 0 和 1 之间的分数,其中 0 表示不匹配,1 表示字符串完全相似。 Jaro-Winkler 通过对第一个 i 匹配字符应用更多权重来修改公式。我不会详细介绍,但最终形式由下面的等式表示。

在继续之前,如果您发现此内容有帮助,请考虑在Ko-Fi上支持我。

在 ko-Fi 上支持我
python中的模糊匹配库
Python有很多模糊匹配算法的实现。我编制了一些可供开源使用的最佳库的小列表。
- FuzzyWuzzy
FuzzyWuzzy 使用 Levenshtein 距离实现的模糊匹配来为您提供所提供句子之间的比率分数。
使用以下命令安装库。

模糊的安装
安装后,只需一行即可使用该库,如下所示。
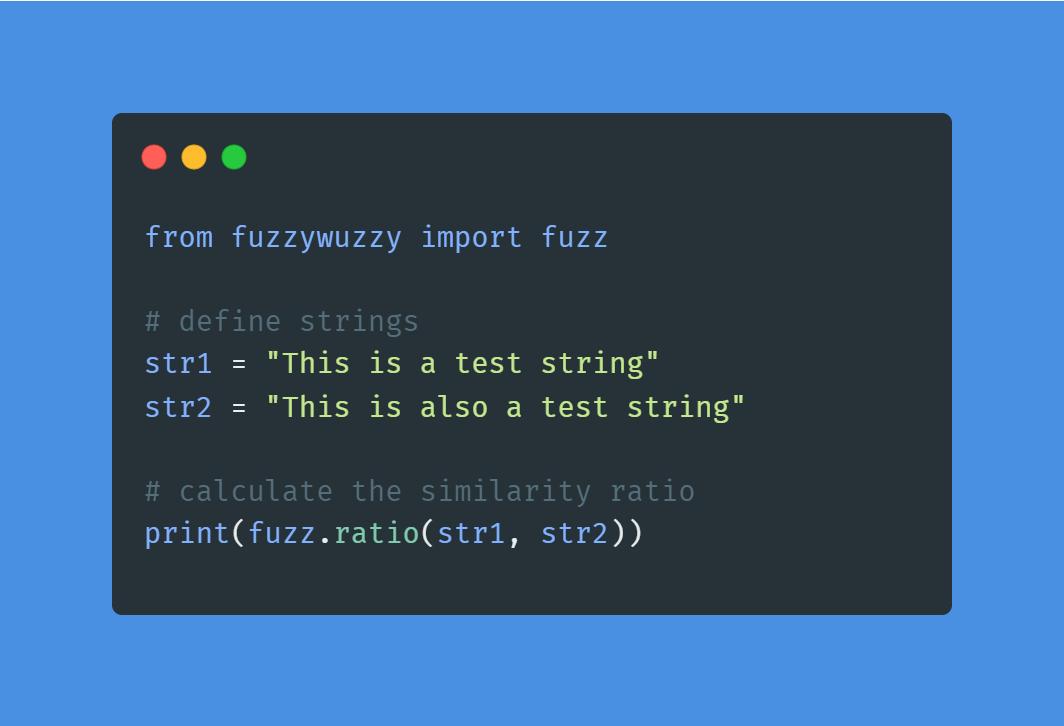
测试fuzzywuzzy
结果比率为 90,这意味着 2 个句子的相似度为 90%。
该库还附带一个附加包,可将计算速度提高 10 倍。从他们的文档中了解有关 FuzzyWuzzy 的更多信息。
- 快速模糊
RapidFuzz 与 FuzzyWuzzy 的实现完全相同,但主要是用 C++ 编写的,并提供了额外的算法改进。它的 C++ 实现使这个库非常快,并且它提供了一些优于 FuzzyWuzzy 的额外好处。
-
它是 MIT 许可证,所以您可以自由选择项目的许可证。
-
它包括其他实现,例如 Jaro-Winkler,这些实现在 FuzzyWuzzy 中不存在
您可以使用以下命令安装此库。

安装 RapidFuzz
它的功能与 FuzzyWuzzy 完全相同,但具有额外的速度优势。

该比率为80.7%
RapidFuzz 还提供了更多功能,类似于 FuzzyWuzzy。在官方文档中阅读更多关于它们的信息。
3\。 Jar-Winkle 的
Jaro-Winkler 距离在 python 中也有多种实现,但显然,其中许多是不正确的。根据StackOverflow上的一位用户的说法,pyjarowinkler(一个非常古老且流行的 Python 库)产生的结果似乎不正确。我用jaro-winkler库测试了同样的问题,并得到了与其他正确实现相匹配的结果。
使用以下命令安装库。

安装 jaro-winkler
使用“jaro_winkler_metric”函数计算距离。请参阅下面的应用程序。

测试 jaro-winkler 库
相似度为 78.3 %
在计算比率或百分比时,Jaro-Winkler 距离比 Levenshtein 或 Damerau-Levenshtein 具有非常重要的优势。后面提到的算法为较小的字符串提供了误导性的结果。让我们看一个下面的例子。

测试较短的字符串

结果
即使字符串仅相差一个字符,该比率也是 67%,这是一个非常重要的数字。现在让我们将其与 Jaro-Winkler 距离进行比较。
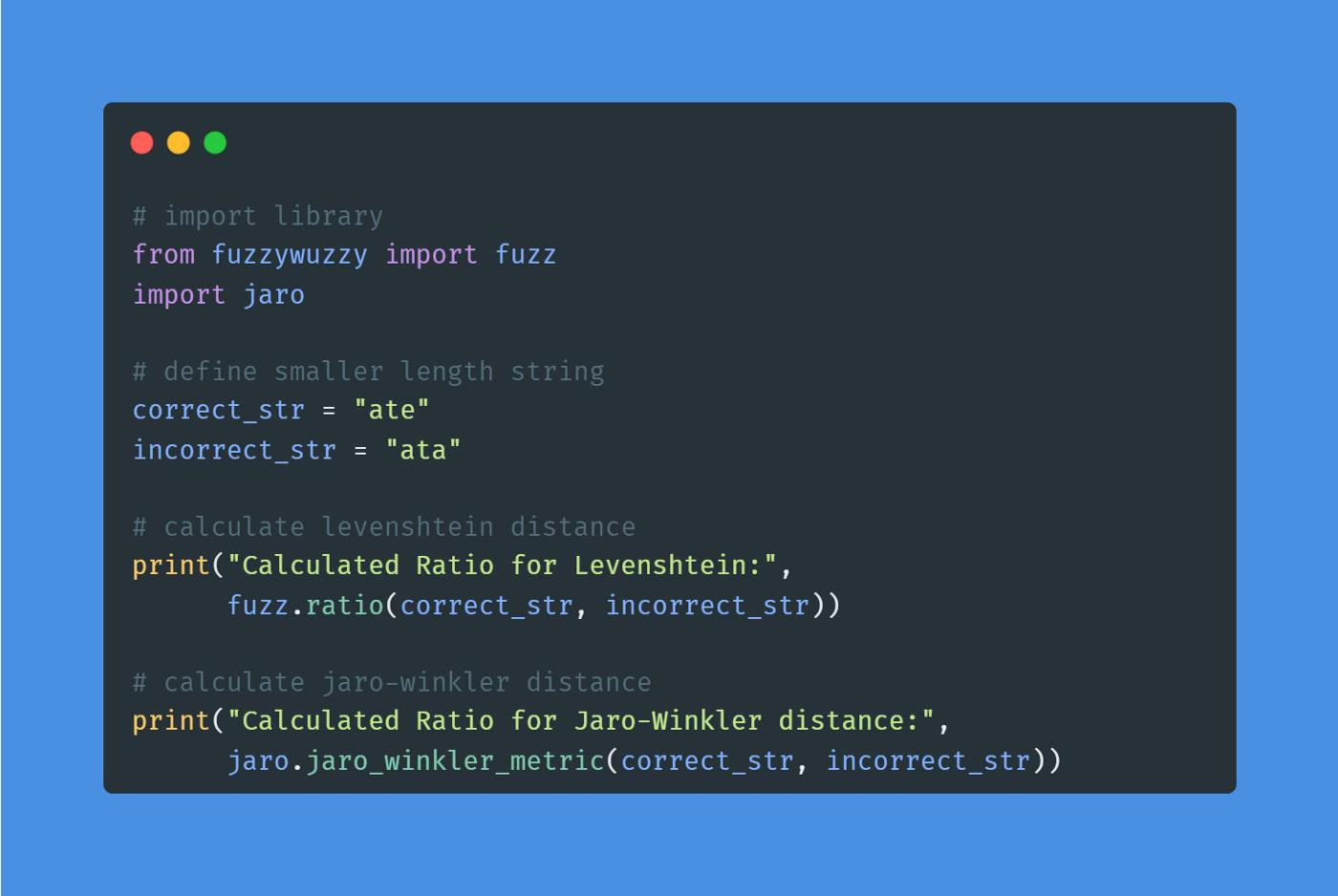

两种算法的结果
Jaro-Winkler 算法返回的相似性百分比为 82.2% , 这是一个更合理的数字。
模糊匹配的应用
字符串匹配在日常应用中扮演着重要的角色。当您在 google 上搜索某些内容时,它会使用著名的 “包括以下结果:...”来纠正您的错字。

谷歌字符串匹配
在后台,Google 实际上通过编辑距离算法运行您的查询,并将其与预定义字典中的每个单词进行匹配。相同功能的另一个示例是手机上的自动更正功能。
它还用于许多搜索算法,这些算法会弹出类似于实际查询的术语建议。这使得搜索功能更加先进,因为即使您没有输入确切的术语,您也可以找到正确的匹配项。
模糊匹配的更多应用是数据库中记录的重复数据删除。很多时候我们的记录包含类似的数据,所以像“groupby”这样的技巧不起作用。模糊匹配有助于挑选出定义阈值内的所有记录。
结束语
模糊匹配是一种简单但非常有用的数据处理技术。它在不同方面用于 Web 应用程序,也包含在许多数据处理管道中。 Python 提供了一些很棒的库来实现某种形式的模糊匹配。这些库提供了简单的 API 来计算字符串匹配分数,并且可以在您的应用程序中使用。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20424条内容
已为社区贡献20424条内容

所有评论(0)