
迈向可靠的设备管理平台
作者Benson Ma,Alok Ahuja
简介
在 Netflix,从流媒体棒到智能电视的数百种不同设备类型每天都通过自动化进行测试,以确保新软件版本继续提供我们客户所享受的 Netflix 体验质量。此外,Netflix 不断与其合作伙伴(如 Roku、三星、LG、亚马逊)合作,将 Netflix SDK 移植到他们的新设备和即将推出的设备(电视、智能盒子等),以确保在允许之前达到质量标准。设备上的 Netflix 应用程序可以走向世界。 Netflix 的合作伙伴基础架构团队通过启用大规模设备管理来提供支持这两项重大工作的解决方案。
背景
为了规范 Netflix 和合作伙伴网络中网络环境的多样性,并创建一致且可控的计算环境,用户可以在该环境上运行回归和 Netflix 应用程序设备认证测试,合作伙伴基础架构团队提供了一个定制的嵌入式计算机,称为参考自动化环境 (RAE)。与硬件相辅相成的是RAE和云端的软件,两端的软件桥接是双向控制平面。它们共同构成了设备管理平台,这是Netflix 测试工作室(NTS) 的基础设施。然后,用户通过以即插即用的方式将他们的设备连接到 RAE 来有效地运行测试。
该平台允许大规模有效的设备管理,其功能集大致分为两个领域:
-
为控制设备及其环境(硬件和软件拓扑)提供服务级抽象。
-
收集和汇总连接到队列中 RAE 的所有设备的信息和状态更新。在这篇博文中,我们将重点关注后一个功能集。
在连接到 RAE 的设备的整个生命周期中,设备可以随时更改属性。例如,在运行测试时,设备的状态会从“可测试”变为“测试中”。此外,由于这些设备中有许多是预生产设备,因此会经常更改固件,因此生产设备中通常是静态的属性有时也会发生变化,例如分配给的 MAC 地址和电子序列号 (ESN)设备上的 Netflix 安装。因此,能够使设备信息保持最新以使设备测试正常工作非常重要。在设备管理平台中,这是通过将设备更新从事件源通过控制平面传输到云来实现的,这样 NTS 将始终拥有有关可用于测试的设备的最新信息。因此,挑战在于能够以可扩展的方式摄取和处理这些事件,即随着设备数量的增加而扩展,这将是这篇博文的重点。
系统设置
架构
下图总结了架构描述:
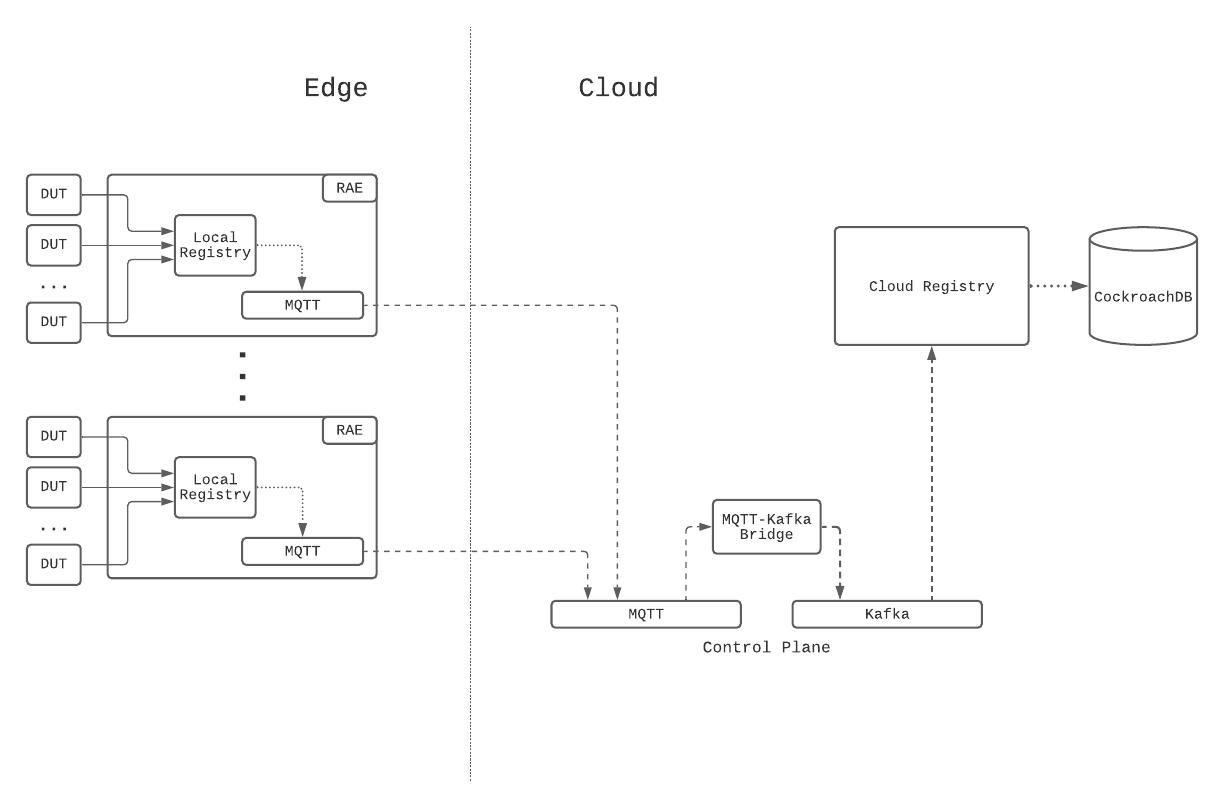
图 1:设备管理平台的事件溯源架构。
RAE 被配置为有效地连接被测设备 (DUT) 的路由器。在 RAE 上,有一个名为 Local Registry 的服务,它负责检测、载入和维护有关连接到 RAE 的 LAN 端的所有设备的信息。当一个新的硬件设备连接上时,Local Registry 会检测并收集一组关于它的信息,例如网络信息和 ESN。本地注册表会定期探测设备以检查其连接状态。随着设备属性和属性随时间变化,这些更改会保存到本地注册表中,并同时向上游发布到设备管理平台的控制平面。除了属性更改之外,本地注册表会定期在上游发布设备记录的完整快照,作为状态协调的一种形式。这些检查点事件使数据馈送的消费者能够更快地重建状态,同时防止错过更新。
在云端,一个名为 Cloud Registry 的服务会摄取 Local Registry 实例发布的设备信息更新,对其进行处理,然后将物化数据推送到由CockroachDB支持的数据存储中。 CockroachDB 被选为支持数据存储,因为它提供了 SQL 功能,并且我们的设备记录数据模型已标准化。此外,与其他 SQL 存储不同,CockroachDB 从一开始就设计为可水平扩展,这解决了我们对 Cloud Registry 能够随着设备管理平台上的设备数量进行扩展的担忧。
控制平面
MQTT构成了设备管理平台控制平面的基础。 MQTT 是物联网 (IoT) 的 OASIS 标准消息传递协议,被设计为高度轻量级但可靠的发布/订阅消息传输传输,非常适合连接具有小代码足迹和最小网络带宽的远程设备。 MQTT 客户端连接到 MQTT 代理并发送带有主题前缀的消息。相反,代理负责接收所有消息,过滤它们,确定谁订阅了哪个主题,并相应地将消息发送给订阅的客户端。使 MQTT 对我们非常有吸引力的关键特性是它对分层主题、客户端身份验证和授权、每个主题 ACL 和双向请求/响应消息模式的支持,所有这些对于我们拥有的业务用例来说都是至关重要的控制平面。
在控制平面内,设备命令和设备信息更新以一个主题字符串为前缀,该主题字符串包括 RAE 序列号和device_session_id,这是一个与设备会话对应的 UUID。将这两个信息嵌入到每条消息的主题中,使我们能够应用主题 ACL 并有效地控制用户可以看到和交互的 RAE 和 DUT,同时与其他用户的设备安全隔离。
由于Kafka是 Netflix 支持的消息传递平台,因此在两种协议之间建立了一座桥梁,以允许云端服务与控制平面进行通信。通过桥接器,MQTT 消息直接转换为 Kafka 记录,其中记录键设置为消息分配到的 MQTT 主题。由于 MQTT 上发布的设备信息更新包含主题中的device_session_id,这意味着给定设备会话的所有设备信息更新将有效地出现在同一个 Kafka 分区上,从而为我们提供了一个明确定义的消息消费顺序。
Canary 测试工作负载
除了为用户和 DUT 之间的常规消息流量提供服务外,控制平面本身还以大约 3 小时的间隔进行压力测试,其中创建了近 3000 个临时 MQTT 客户端来连接并在 MQTT 代理上生成闪存流量。这是一个金丝雀测试,以验证代理是否在线并且能够处理突然涌入的客户端连接和高消息负载。因此,我们可以看到设备管理平台控制平面上的流量负载随着时间的推移是非常动态的。
遵守铺装路径
在 Netflix,我们强调构建尽可能多地使用铺砌路径工具的解决方案(参见帖子此处和此处)。特别是由 Runtime 团队维护的Spring Boot Native的风格是 Netflix 内部开发的许多 Web 服务(包括 Cloud Registry)的基础。 Netflix Spring 包附带了应用程序在 Netflix 生态系统中无缝工作所需的所有集成。特别是,Kafka 集成与这篇博文最相关。
翻译成系统需求
鉴于我们描述的系统设置,我们提出了 Cloud Registry 的基于 Kafka 的设备更新处理解决方案必须解决的基本业务需求列表。
背压支架
由于处理工作负载随时间显着变化,因此解决方案首先必须通过提供Reactive Streams规范中定义的背压支持来扩展消息负载 - 换句话说,解决方案应该能够在推送之间切换和基于拉动的背压模型,取决于下游是否能够应对消息生产速率。
订单处理
正确的设备信息更新摄取的语义要求消息按照生成的顺序被使用。由于每个 Kafka 分区都保证了消息顺序,并且给定设备会话的所有更新都分配到同一个分区,这意味着只要每个分区只分配一个线程,就可以强制执行每个设备的更新处理顺序。同时,到达不同分区的事件应该并行处理以获得最大吞吐量。
容错
如果底层KafkaConsumer因临时系统或网络事件而崩溃,应自动重启。如果在消息消费过程中抛出异常,异常应该被优雅地捕获,并且在有问题的消息被丢弃后消息消费应该无缝地继续。
优雅关机
当重新部署服务或调整其实例组的大小时,应用程序关闭是必要且不可避免的。因此,处理器关闭应该可以从 Kafka 消费上下文之外调用,以促进优雅的应用程序终止。另外,由于Kafka消息通常是被KafkaConsumer批量拉下的,所以实现的方案应该在收到关闭信号后,在关闭前消耗并清空内部队列中剩余的所有已经取到的消息。
铺装路径集成
如前所述,在 Netflix 中,Spring 被大量用作开发服务的铺路解决方案,而 Cloud Registry 是 Spring Boot Native 应用程序。因此,实施的解决方案必须至少与 Netflix Spring 设施集成以提供身份验证和指标支持——前者用于访问 Kafka 集群,后者用于服务监控和警报。此外,实现的解决方案的生命周期管理也必须集成到 Spring 的生命周期管理中。
长期可维护性
实施的解决方案必须对长期维护支持足够友好。这意味着它必须至少是单元和功能可测试的,以便快速和迭代反馈驱动的开发,并且代码必须符合人体工程学,以降低新维护者的学习曲线。
采用流处理框架
There are many frameworks available for reliable stream processing for integration into web services (for example, Kafka Streams, Springzwz100072 KafkaListener zwz100073 zwz100071, Project Reactor, Flink, Alpakka-Kafka, to name一些)。我们选择 Alpakka-Kafka 作为 Kafka 处理方案的基础,原因如下。
-
事实证明,Alpakka-Kafka 满足了我们提出的所有系统要求,包括对 Netflix Spring 集成的需求。它进一步提供了对流处理的高级和细粒度的控制,包括自动背压支持和流监督。
-
与其他可能满足我们所有系统需求的解决方案相比,Akka 是一个轻量级的框架,它与 Spring Boot 应用程序的集成相对较短和简洁。此外,Akka 和 Alpakka-Kafka 代码比其他解决方案简洁得多,这降低了维护人员的学习曲线。
-
基于 Alpakka-Kafka 的解决方案的维护成本远低于其他解决方案,因为 Akka 和 Alpakka-Kafka 在文档和社区支持方面都是成熟的生态系统,至少存在 12 年和 6 年。
基于Alpakka的Kafka处理流水线的搭建可以用下图来概括:
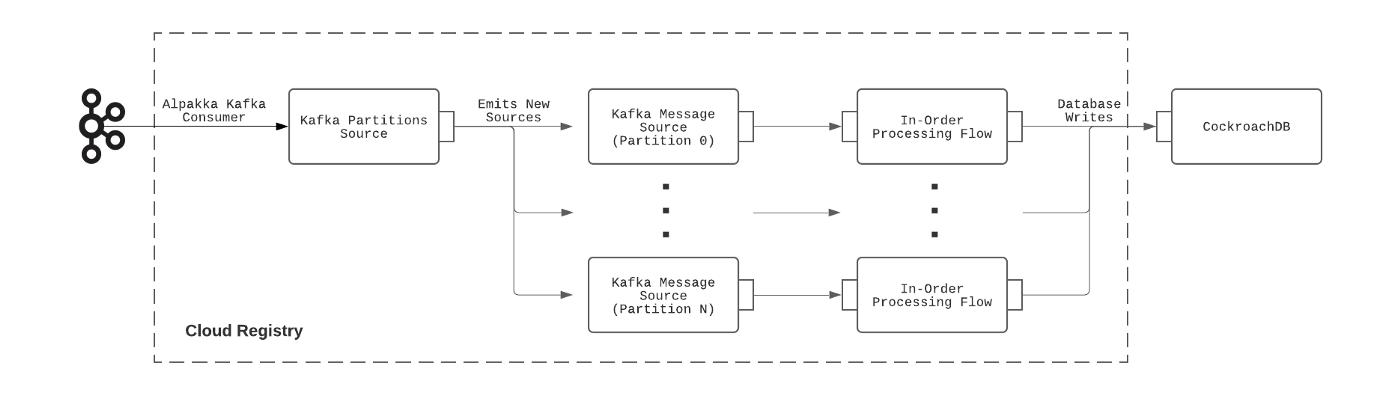
图 2:Cloud Registry 使用的 Kafka 处理管道。
实现
Alpakka-Kafka 流与 Netflix Spring 应用程序上下文的集成非常简单,实现如下:
1.在build.gradle中导入Alpakka-Kafka库,但是****排除自带的kafka-client传递依赖,以便使用Netflix内部增强的变体。
-
构建一个 Spring
@Configuration类,该类autowire是由 Netflix Spring 运行时注入的KafkaPropertiesbean,并使用该 bean 中可用的 Kafka 设置,构建一个 Alpakka-KafkaConsumerSettingsbean。 -
使用
ConsumerSettingsbean 作为输入构造一个 Alpakka-Kafka 处理图。
由于此集成明确使用了 Netflix 增强的KafkaConsumer和 Netflix Spring 注入的 Kafka 设置,因此基于 Alpakka-Kafka 的解决方案立即享受了铺设路径 SpringKafkaListener附带的身份验证和指标记录工具。
测试
使用EmbeddedKafka库对 Alpakka-Kafka 消费者进行功能测试非常简单,该库提供了一个内存中的 Kafka 实例来运行测试。为了根据 Kafka 消息处理管道的复杂性扩大测试规模,将消息处理代码与 Alpakka-Kafka 图代码分开。这允许使用功能测试单独测试消息处理代码,同时最大限度地减少基于 EmbeddedKafka 的 Kafka 集成测试所需测试的表面积。
结果
在 Alpakka-Kafka 之前
Cloud Registry 中实现的原始 Kafka 处理解决方案是基于 SpringKafkaListener构建的,主要是因为它作为 Netflix Spring 提供的铺路解决方案可以立即使用。这里展示了从 SpringKafkaListener到 Alpakka-Kafka 的过渡时间表,以便更好地了解过渡的动机。
内存和 GC 问题
基于 SpringKafkaListener\ 的解决方案在今年早些时候部署,在此期间关于 Kafka 主题的消息很稀疏,因为当时 Local Registry 尚未完全投入生产。在2021–07–15 15:00 PST左右,生产者端完全启用了上游事件溯源。到第二天早上,收到关于高内存消耗和 GC 延迟的警报,以至于服务对 HTTP 请求没有响应。对 JVM 内存转储的调查显示了一个内部 Kafka 消息并发队列,其大小已不受控制地增长到超过 130 万个元素。
造成这种异常队列增长的原因是由于 SpringKafkaListener缺乏原生的背压支持。使用KafkaListener,Kafka 消息获取率在应用程序启动时是固定的。但是,可以通过调整max-poll-interval-ms和max-poll-records配置值来调整它,这需要事先以某种方式根据经验确定以获得最佳性能。这种设置既不是最佳的也不是防崩溃的,因为 Kafka 消息处理速率将根据环境因素而变化,例如我们系统设置中的数据库延迟。结果,随着时间的推移,KafkaListener最终会有效地过度消耗消息,这体现在其内部消息队列的增长中。
在将服务实例数量增加一倍并增加实例大小但仅取得了平庸的成功后,决定研究具有完整背压管理功能的替代 Kafka 处理解决方案。
Kafka 主题指标
从本地注册表启用事件溯源显着增加了设备管理平台的控制平面流量,Kafka 主题消息发布频率从每秒 100 条消息/90 kB 传入到每秒 900 条消息/840 kB 传入的频率增长了 9 倍就证明了这一点(图3)。
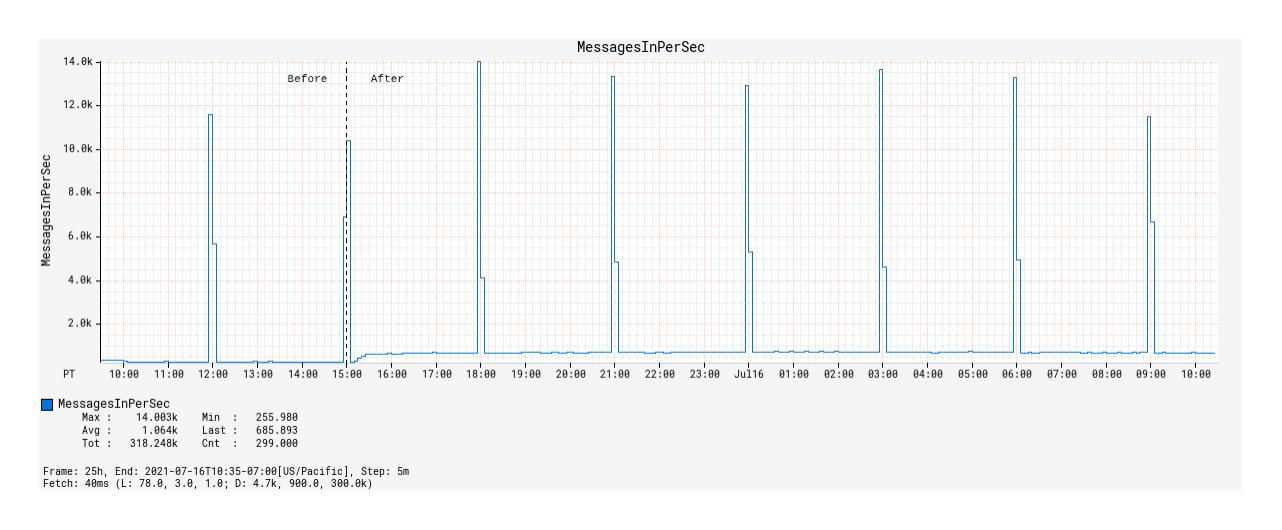
图 3:启用事件溯源前后随时间变化的消息流量。
此处显示的每隔 3 小时出现的峰值对应于前面提到的金丝雀运行,这些运行有效地使用大量新记录对 Kafka 主题进行负载测试。此后,它们将被称为突发事件。虽然与每秒产生数十万甚至数百万事件的数据系统相比,平均消息发布率较低,但它确实突出了即使在消息的低端进行背压管理的重要性载荷谱。
使用 Alpakka-Kafka 改进 Kafka 消费
我们现在比较基于 SpringKafkaListener的 Kafka 处理方案和基于 Alpakka-Kafka 的方案之间的 Kafka 消耗,后者在2021–07–23 18:00 PST上部署到生产。具体来说,我们将查看 Kafka 消费性能的三个指标:消息获取率、最大消费者延迟和提交率。
获取请求指标
在部署基于 Alpakka-Kafka 的处理器后,我们进行了一些观察:
-
在部署之前,随着时间的推移,获取调用的数量在突发事件中通常保持不变,但实际上随着时间的推移非常不稳定(图 4)。
-
部署后,随着时间的推移,fetch 调用与 Kafka 主题的消息发布率 1:1 对应,包括间隔突发事件(图 4)。在突发事件窗口之外,随着时间的推移,获取调用的数量非常稳定。
-
令人惊讶的是,与基于 Spring
KafkaListener\ 的处理器相比,在突发事件窗口期间每个提取请求提取的平均记录数减少了(图 5)。
我们可以从这些观察中推断出,在本地背压支持的情况下,基于 Alpakka-Kafka 的处理器能够动态扩展其 Kafka 消耗量,从而不会过度消耗或过度消耗 Kafka 消息。这种行为使处理器保持足够的忙碌,但不会因为从 Kafka 拉出的消息队列不断增加而使处理器过载,最终导致 JVM 的内存和 GC 容量溢出。
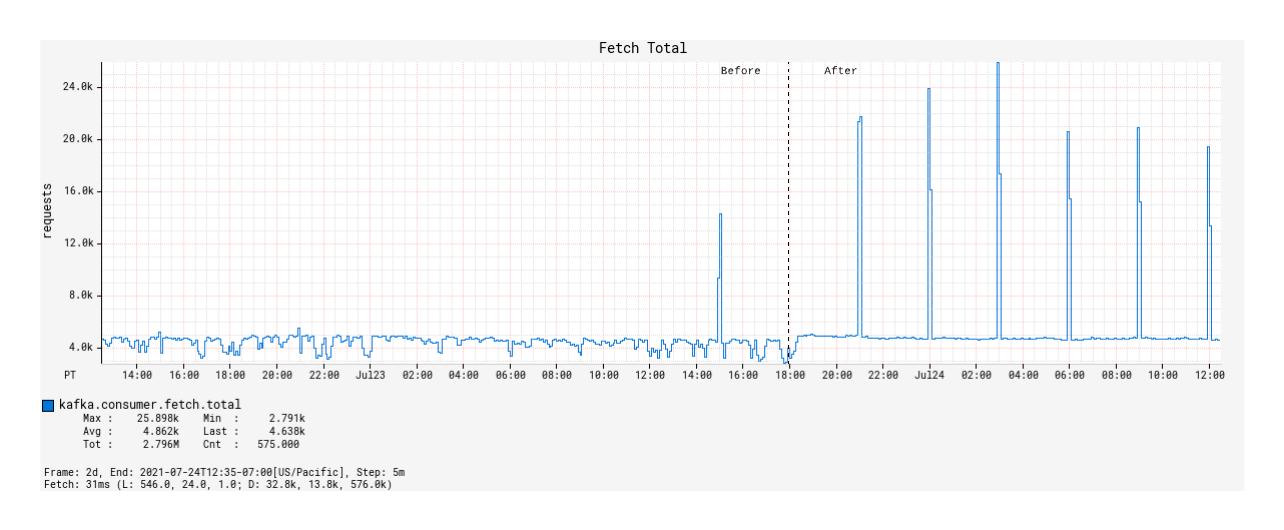
图 4:记录KafkaConsumer在部署基于 Alpakka-Kafka 的处理器之前和之后随时间进行的 fetch 调用。
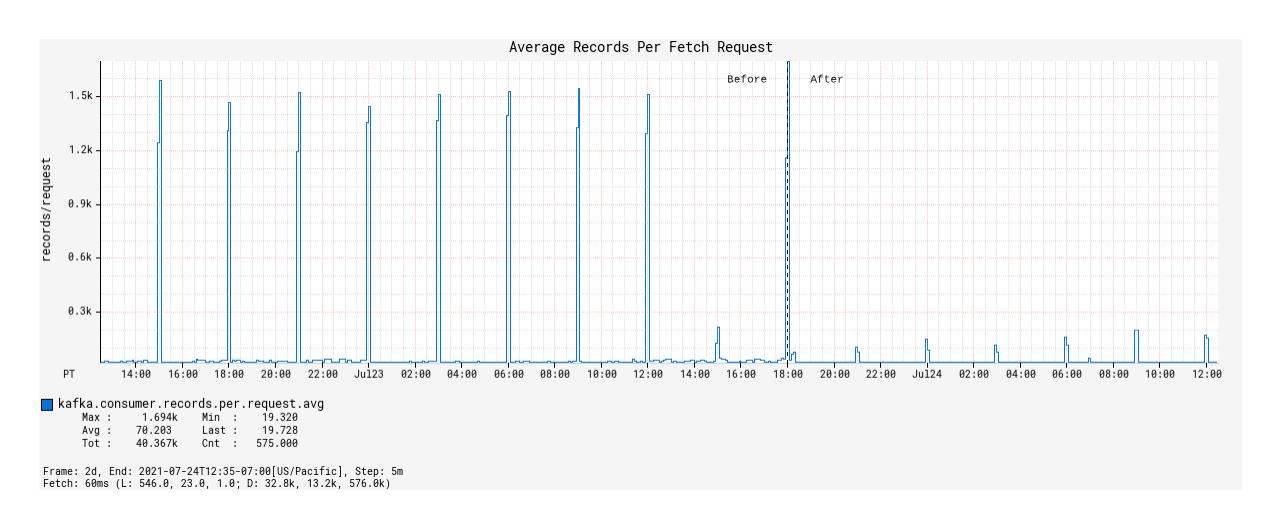
图 5:部署前后随时间推移,每个获取请求获取的平均记录数。
最大消费者滞后
除了 JVM 和服务正常运行时间之外,基于 Alpakka-Kafka 的处理器的最显着改进体现在 Kafka 消费者滞后指标上。虽然部署了 SpringKafkaListener,但最大消费者延迟通常长期浮动在大约 60,000 条记录,不包括突发事件时间窗口(由于绘制值的数量级差异,这在图表中无法直观辨别)。从功能的角度来看,这是不可接受的,因为如此大的恒定滞后值意味着设备信息更新将需要足够长的时间才能传播到服务中,这样我们的用户才会注意到它。这种情况在突发事件窗口期间加剧,其中最大消费者延迟将增加到超过 1 亿条记录的值(图 6)。
自从部署基于 Alpakka-Kafka 的处理器以来,随着时间的推移,最大消费者延迟在突发事件窗口之外平均为零。在突发事件窗口内,最大消费者延迟会短暂增加到大约 20,000 条记录,自部署以来的 48 小时内只有一个异常值(图 7)。这些指标向我们表明,Alpakka-Kafka 采用的 Kafka 消费模式和 Akka 的流媒体功能通常在规模上表现得非常好,从安静的用例到突然出现大量消息负载。
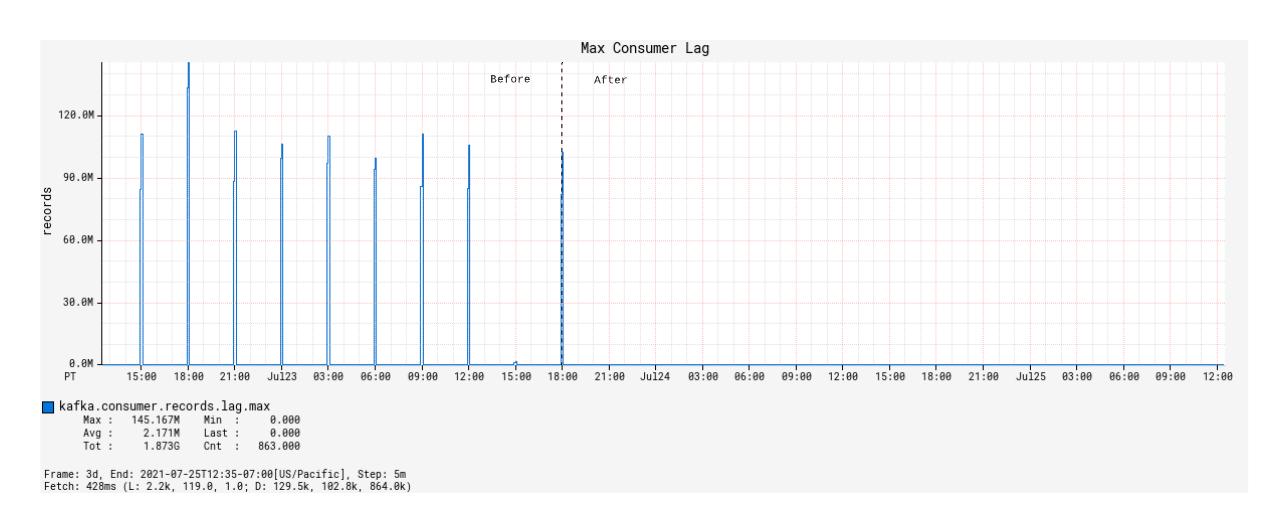
图 6:KafkaConsumer在部署前后随时间变化的最大消费者延迟。
! swz 100102 swz 100103 swz 100101
图 7:KafkaConsumer随时间的最大消费者延迟,在部署后的一段时间内放大到时间窗口。
提交率和平均提交延迟
当 Kafka 消费者获取记录时,它可以执行手动或自动偏移提交——这可以通过enable.auto.commit进行配置。与名称相反,手动与自动提交的语义不一定指_如何_执行偏移提交,而是_何时_与记录获取过程周期有关。使用自动提交,消息一旦被获取就被确认已收到并且与处理无关,而使用手动提交,消费者只能在消息被正确处理后决定确认。
默认情况下,当enable.auto.commit设置为false时,SpringKafkaListener会在每处理一条记录时执行一次偏移提交,即确认方式设置为AckMode.RECORD。这是极其低效的,并且是已知来降低消费者的消息消费吞吐量。使用基于 Alpakka-Kafka 的处理器,我们选择批量提交记录(默认设置为1000),提交之间允许的最大间隔为 1 秒。此行为类似于 SpringKafkaListener中的AckMode.COUNT_TIME确认模式,但具有在 Kafka 消费失败或终止时自动尝试完成未完成的提交请求的额外好处。
在手动偏移提交方案下,总是可以在失败的情况下重新处理 Kafka 消息。为了保留由自动偏移提交方案保证的(主要)一次性处理,Kafka 处理器进行了更新以使用幂等 upsert 存储设备更新,即,以数据库中记录的时间戳为条件执行 upsert 早于要更新的时间戳。这有效地确保了对每个事件的精确一次处理。
随着基于 Alpakka-Kafka 的处理器的部署,提交率从大约 7 KB/秒显着降低到 50 字节/秒(图 8),但平均提交延迟从平均 1 毫秒增加到 12 毫秒(图9)。尽管如此,这大大减少了提交偏移所花费的网络开销,并且对提高 Kafka 处理的吞吐量做出了重大贡献。
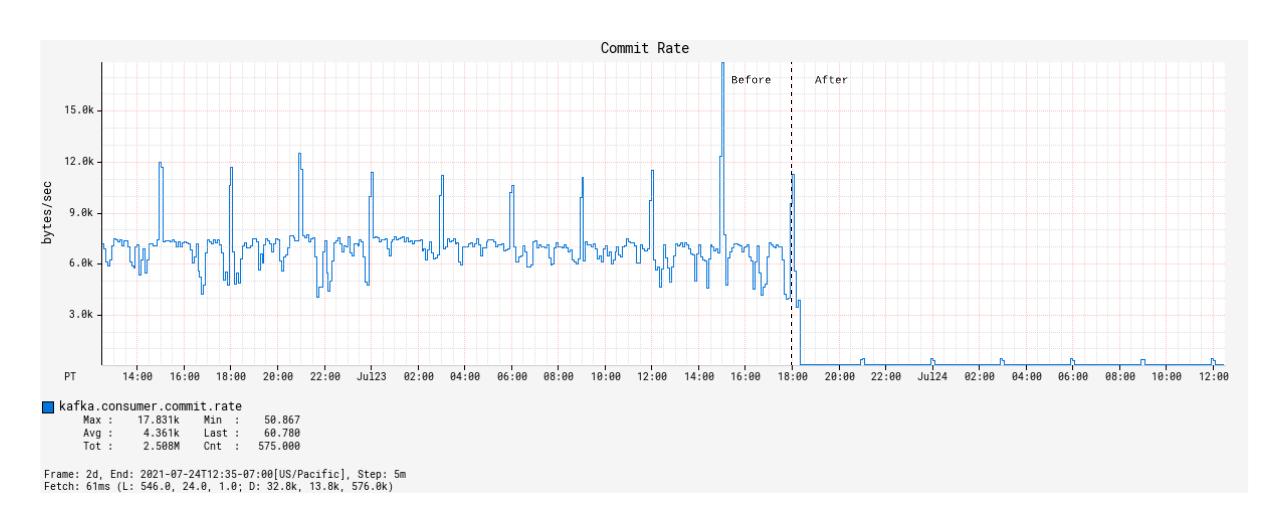
图 8:KafkaConsumer在部署前后随时间的偏移提交率。
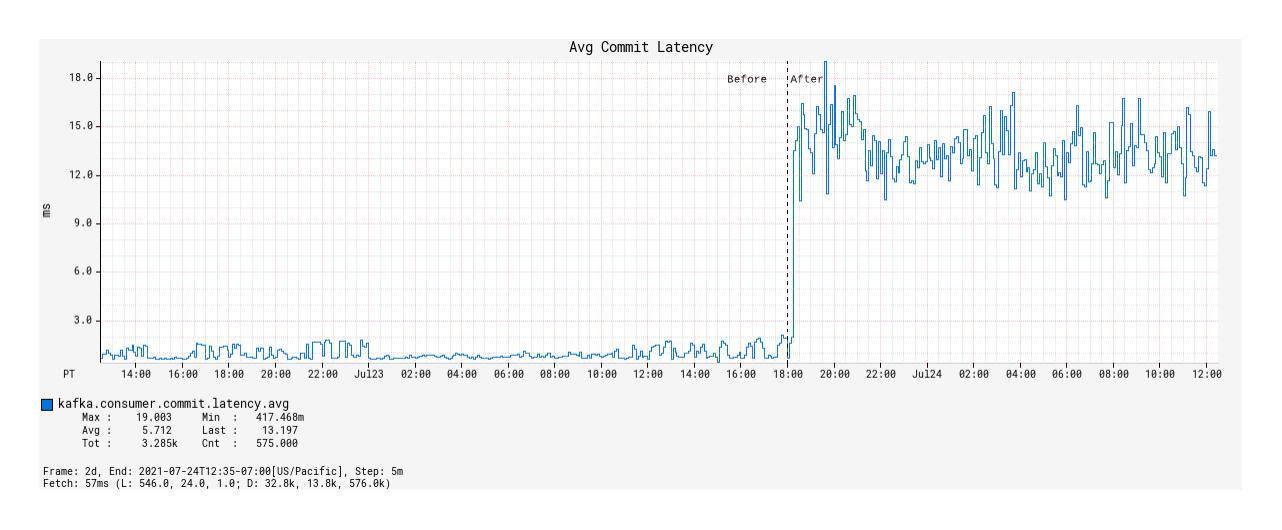
图 9:部署前后每次偏移提交的平均延迟。
结论
Kafka 流处理可能很难正确处理。需要根据业务需求考虑许多系统实现细节。幸运的是,Akka 流和 Alpakka-Kafka 提供的原语使我们能够通过允许我们构建与我们拥有的业务工作流相匹配的流解决方案来实现这一点,同时在构建和维护这些解决方案时提高开发人员的生产力。借助云注册表中基于 Alpakka-Kafka 的处理器,我们确保了控制平面消费者端的容错性,这是在设备管理平台内实现准确可靠的设备状态聚合的关键。
虽然我们实现了消息消费容错,但这只是设备管理平台设计和实现的一个方面。该平台及其控制平面的可靠性取决于在多个领域所做的重要工作,包括 MQTT 传输、身份验证和授权以及系统监控,我们计划在未来的博客文章中详细讨论所有这些。同时,作为这项工作的结果,随着我们将越来越多的设备加入我们的系统,我们可以预期设备管理平台将随着时间的推移继续扩展以适应不断增加的工作负载。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20425条内容
已为社区贡献20425条内容

所有评论(0)