
深度学习中的训练测试拆分
机器学习的黄金法则之一是将数据集拆分为训练集、验证集和测试集。了解如何绕过最常见的警告!
我们这样做的原因很简单。如果我们不将数据拆分为不同的集合,则模型将根据它在训练期间看到的相同数据进行评估。因此,我们可能会在不知不觉中遇到过拟合等问题。
在使用深度学习模型之前,我们经常使用三个不同的集合。
-
A train set 用于训练模型
-
一个验证集,用于在训练过程中评估模型
-
一个测试集,用于在部署前评估最终模型的准确性
我们如何使用训练集、验证集和测试集?
通常,我们使用不同的集合如下:
-
我们将数据集随机分成三个子集,称为train、validation 和test set。拆分可以是 60/20/20 或 70/20/10 或您想要的任何其他比率。
-
我们使用训练集训练模型。
-
在训练过程中,我们在验证集上评估模型。
-
如果我们对结果不满意,我们可以更改超参数或选择另一个模型并_再次进入第 2 步_
-
最后,一旦我们对验证集上的结果感到满意,我们就可以在测试集上评估我们的模型。
-
如果我们对结果感到满意,我们现在可以再次使用我们导出的超参数在 train 和 validation set 上训练我们的模型。
-
我们可以再次评估测试集上的模型准确性,如果我们乐意部署模型。
大多数 ML 框架为数据集的随机训练/测试拆分提供内置方法。最著名的例子是 scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html)的[train_test_split 函数。
使用非常小的数据集有什么问题吗?
是的,这可能是个问题。对于非常小的数据集,测试集会很小,因此一个错误的预测会对测试的准确性产生很大的影响。幸运的是,有一种方法可以解决这个问题。
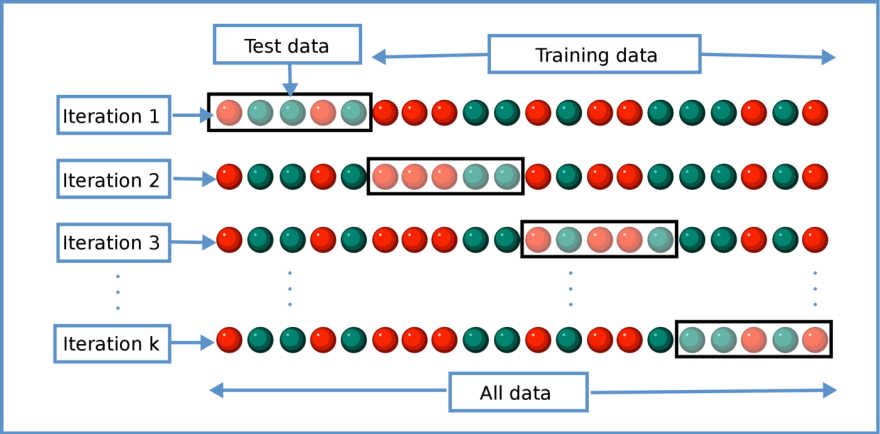
这个问题的解决方案称为交叉验证。我们基本上创建了数据集的分区,如下图所示。我们总是拿出一组进行测试,并使用所有其他数据进行训练。最后,我们收集并平均来自测试集的所有结果。我们基本上训练了 k 个模型,并使用这个技巧设法获得了在完整数据集上评估模型的统计数据(因为每个样本都是 k 个测试集之一的一部分)。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--uYY_cKoF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads.s3.amazonaws .com/uploads/articles/9agmdxw2iycf2igvld1m.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--uYY_cKoF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads.s3.amazonaws .com/uploads/articles/9agmdxw2iycf2igvld1m.png)
这种方法在最近的深度学习方法中几乎没有使用,因为训练一个模型 k 次非常昂贵。
随着深度学习的兴起和数据集大小的大量增加,对交叉验证或单独验证集等技术的需求已经减少。造成这种情况的一个原因是实验非常昂贵并且需要很长时间。另一个原因是由于大多数深度学习方法的大型数据集和性质,模型受过度拟合的影响较小。
过拟合仍然是深度学习中的一个问题。但是对 50 个具有 10 个特征的样本进行过拟合比对具有数百万像素的 100k 图像进行过拟合更快
有人可能会争辩说,研究人员和从业者变得懒惰/草率。看到任何最近的论文再次调查这种影响将会很有趣。例如,可能是过去几年研究人员严重过度拟合他们的模型到 ImageNet 的测试集,因为一直在努力改进它并成为最先进的。
我应该如何选择我的训练集、验证集和测试集?
天真地,可以手动将数据集分成三个块。这种方法的问题是我们人类非常有偏见,这种偏见会被引入这三个集合中。
在学术界,我们知道我们应该随机挑选它们。随机分成三组可确保所有三组都遵循相同的统计分布。这就是我们想要的,因为 ML 都是关于统计的。
从完全不同的分布中推导出这三个集合会产生一些不需要的结果。如果我们想用它来分类花朵,那么在猫的图片上训练一个模型并没有太大的价值。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--9ujq7jcB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads.s3.amazonaws .com/uploads/articles/7z6e8urmeke9bc9j9jbt.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--9ujq7jcB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads.s3.amazonaws .com/uploads/articles/7z6e8urmeke9bc9j9jbt.png)
然而,随机分割的基本假设是初始数据集已经与我们要解决的问题的统计分布相匹配。这意味着对于自动驾驶等问题,假设我们的数据集涵盖了各种城市、天气条件、车辆、一年中的季节、特殊情况等。
正如您可能认为的那样,这个假设实际上对于大多数实际的深度学习应用程序都是无效的。每当我们在不受控制的环境中使用传感器收集数据时,我们可能无法获得所需的数据分布。
但这很糟糕。如果我无法收集我试图解决的问题的代表性数据集,我该怎么办?
您正在寻找的是围绕发现和处理领域差距、分布变化或数据漂移的研究领域。所有这些术语都有自己的特定定义。我在这里列出它们,以便您可以轻松搜索相关问题。
使用 domain,我们将数据域称为我们使用的数据的来源和类型。前进的方式有以下三种:
-
通过收集更具代表性的数据来解决数据缺口
-
使用数据整理方法,使已收集的数据更具代表性
-
专注于构建足够强大的模型来处理此类领域差距
后一种方法侧重于为分布式任务构建模型。
为分布式任务选择一个火车测试拆分
在机器学习中,当我们的模型必须在新输入数据来自与训练数据不同的分布的情况下表现良好时,我们指的是分布外。回到我们之前的自动驾驶示例,我们可以说,对于一个只在加州阳光明媚的天气下训练过的模型,在欧洲进行预测是不合时宜的。
现在,我们应该如何为这样的任务拆分数据集?
由于我们使用不同的传感器收集数据,我们还可能有关于每个样本来源的附加信息(样本可以是图像、激光雷达帧、视频等)。
我们可以通过以下方式拆分数据集来解决这个问题:
-
我们对来自列表 A 中城市的一组数据进行训练
-
并根据列表 B 中城市的一组数据评估模型
Yandex 研究中有一篇很棒的文章关于他们的新数据集,以解决数据集中的分布变化。
可能出错的事情
验证集和测试集准确率相差很大
您很可能将模型过度拟合到验证集,或者验证集和测试集非常不同。但是怎么做?
您可能进行了多次调整参数的迭代,以挤出您的模型可以在验证集上产生的最后一点准确性。验证集不再实现其目的。此时,您应该放松一些超参数或引入正则化方法。
在得出最终的超参数后,我想在发货前在完整数据集(训练 + 验证 + 测试)上重新训练我的模型
不,不要这样做。超参数已针对训练集(或者可能是训练集 + 验证集)进行了调整,并且在用于完整数据集时可能会产生不同的结果。
此外,由于测试集不再存在,您将无法再回答模型的实际性能如何。
我有一个视频数据集,想将帧随机分成训练集、验证集和测试集
由于视频帧很可能是高度相关的(例如,相邻的两个帧看起来几乎相同),这是一个坏主意。这几乎就像我们在训练数据上评估模型一样。相反,您应该跨视频拆分数据集(例如,视频 1、3、5 用于训练,视频 2、4 用于验证)。您可以再次使用随机训练测试拆分,但这次是在视频级别而不是帧级别。
伊戈尔,联合创始人
Lightly.ai
这篇博文最初发表在这里:https://www.lightly.ai/post/train-test-split-in-deep-learning
u200d

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)