
【智能体记忆】Why?What? How?
目录
2.智能体(Agent)中的记忆(Memory)是什么意思?

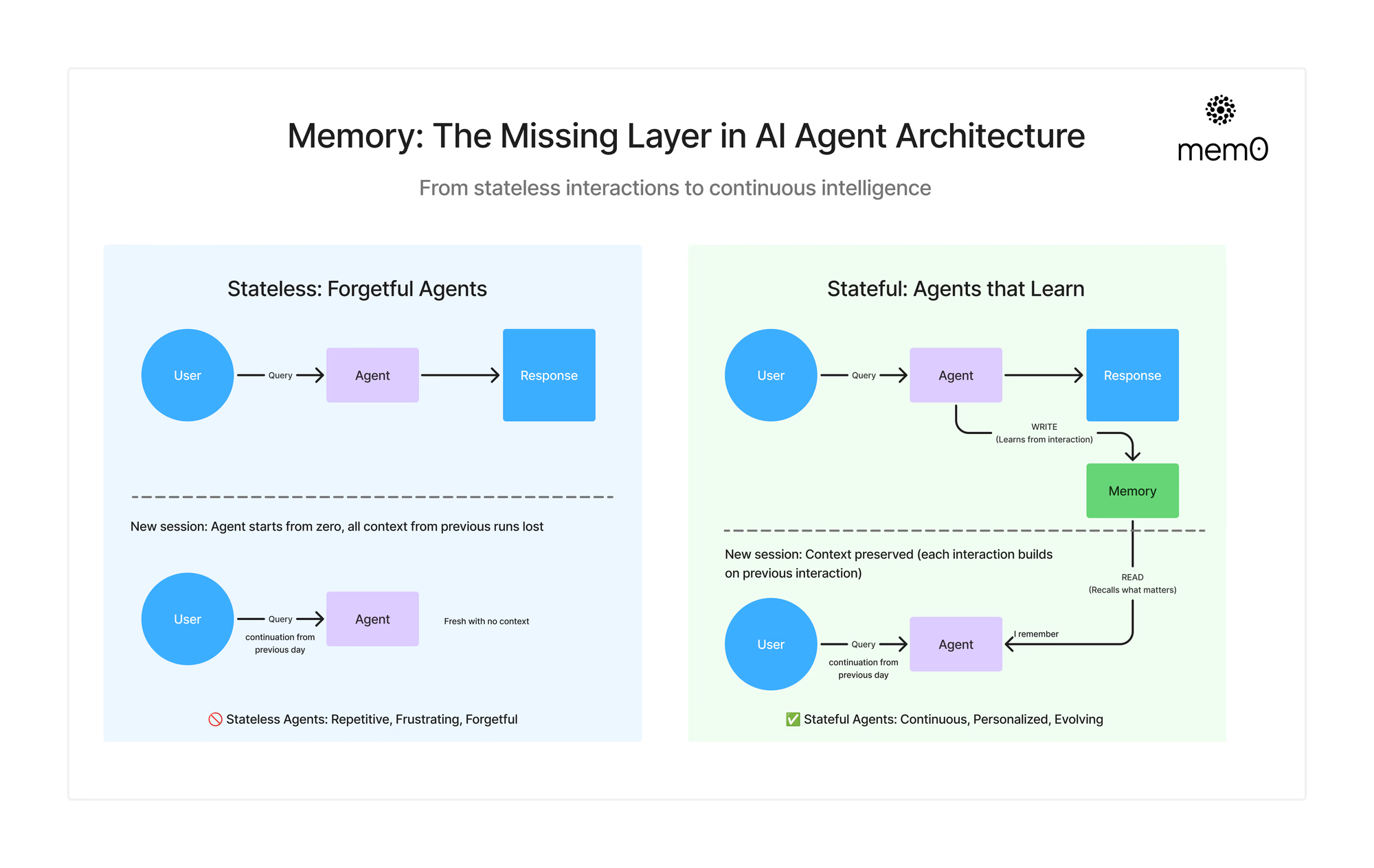
想象一下,你和一个朋友聊天,他竟然忘记了你说过的所有话。每一次对话都从零开始。没有记忆,没有背景,没有进展。这会让人感到尴尬、疲惫,而且缺乏人情味。不幸的是,如今大多数人工智能系统就是这样运作的。它们确实很聪明,但缺少一个至关重要的东西:记忆。
让我们首先讨论一下记忆在人工智能中的真正含义以及它为何重要。
1.引言:当今人工智能中的记忆幻觉
像 ChatGPT 或 Cocoding Copilots 这样的工具乍一看很有帮助,但你发现自己不得不一遍又一遍地重复指令或偏好。为了构建能够学习、进化和协作的智能体,真实记忆不仅有益,而且至关重要。
这种由上下文窗口和巧妙的提示设计所创造的记忆错觉,让许多人相信代理已经“记住”了。但实际上,如今大多数代理都是无状态的,无法从过去的交互中学习,也无法随着时间的推移进行调整。
为了从无状态工具转变为真正智能、自主(有状态)的代理,我们需要赋予它们记忆,而不仅仅是更大的提示或更好的检索。
2.智能体(Agent)中的记忆(Memory)是什么意思?
在智能体的语境中,记忆是指跨时间、跨任务、跨用户交互保留和回忆相关信息的能力。它使智能体能够记住过去发生的事情,并利用这些信息来改进未来的行为。
记忆不仅仅是存储聊天记录或向提示中注入更多令牌。它还在于构建一个持久的内部状态,该状态会不断发展,并告知代理的每次交互,即使交互间隔数周或数月。
代理中的内存由三大支柱定义:
-
状态:了解当前正在发生的事情
-
持久性:跨会话保留知识
-
选择:决定什么值得记住
这些共同实现了我们以前从未有过的东西:连续性。
3.记忆模块如何定位和融入到整体架构中
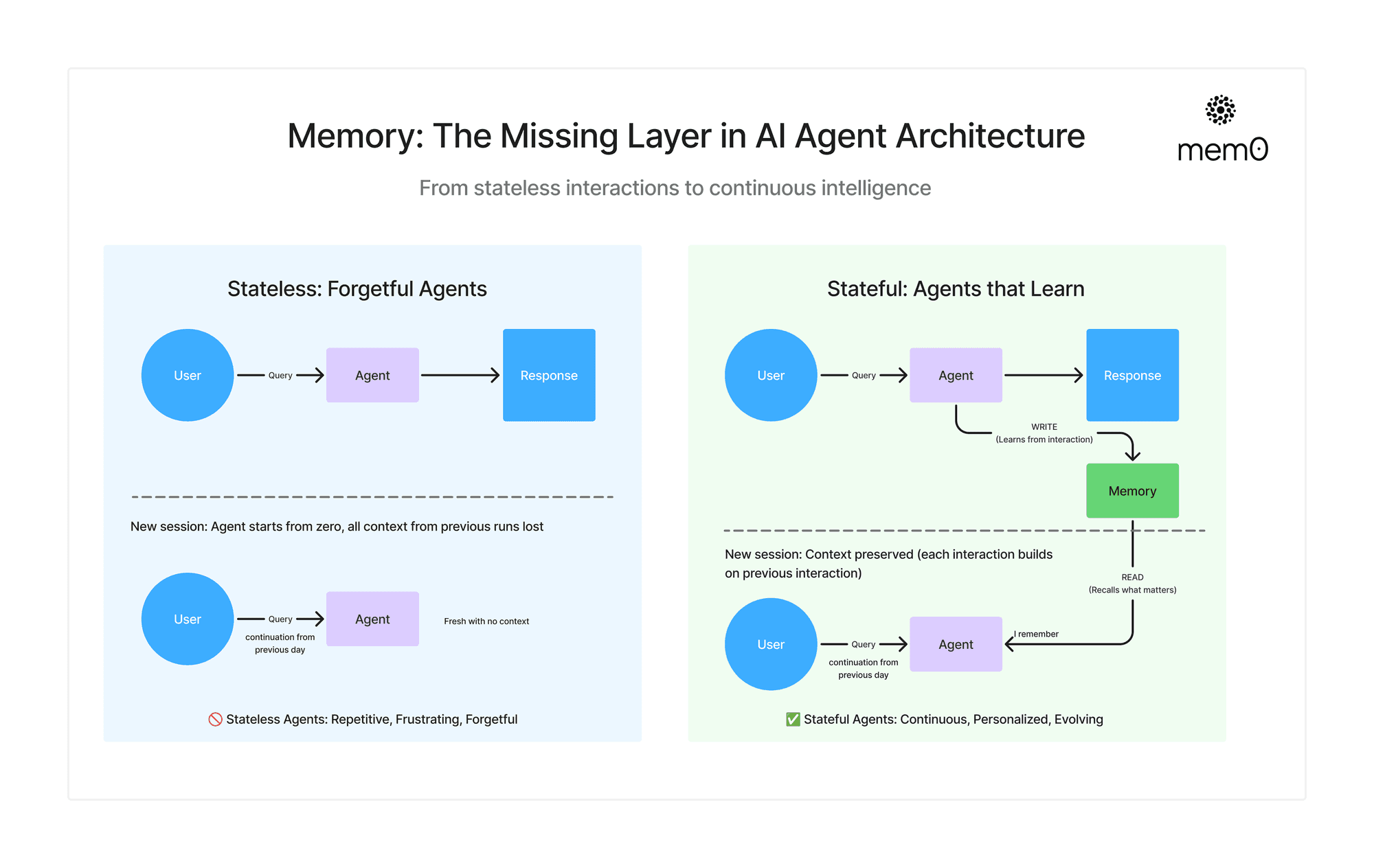
无状态代理(无记忆) vs 有状态代理(有记忆)
让我们将记忆放入智能体的架构中。典型的组件包括:
-
LLM推理和答案生成
-
策略或规划器(例如 ReAct、AutoGPT)
-
访问工具/API
-
用于获取文档或过去数据的检索器
问题在于:这些组件都不记得昨天发生了什么。没有内部状态。没有不断发展的理解。没有记忆。
4.记忆 in the loop
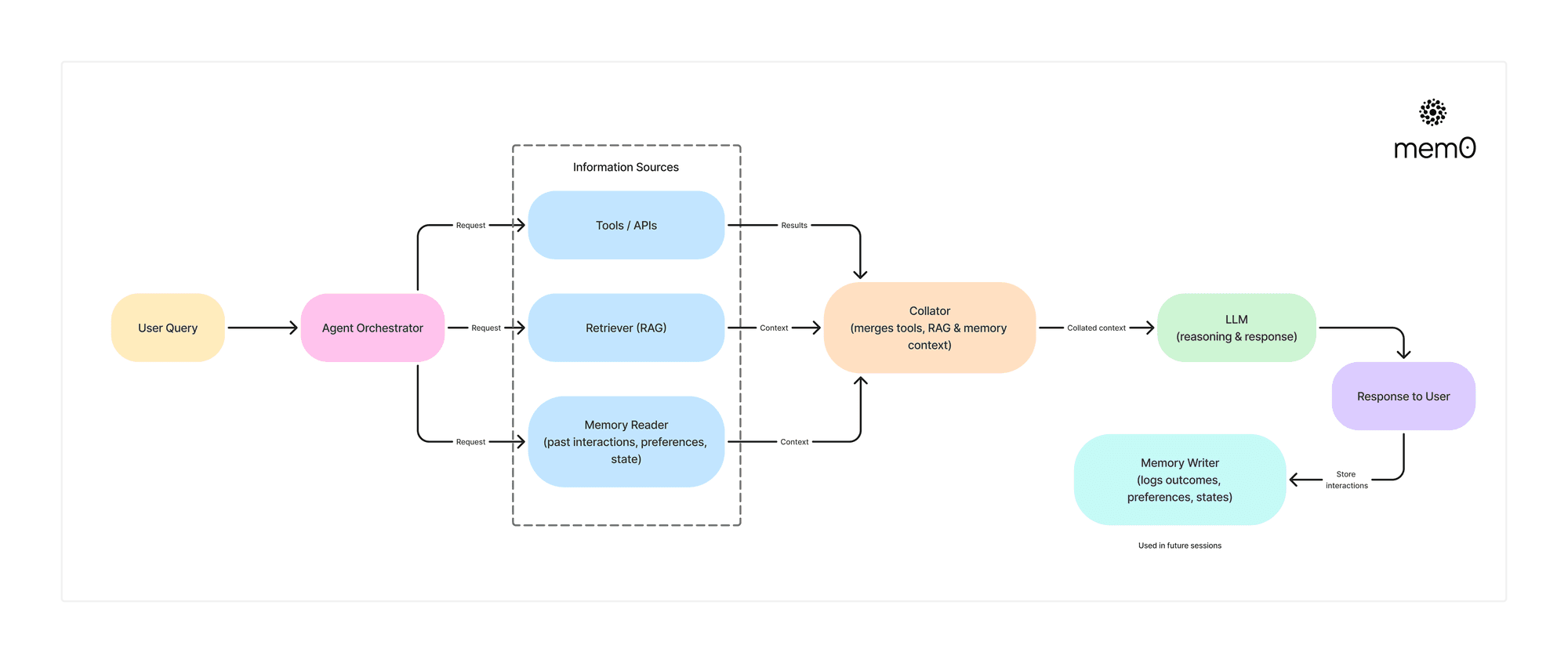
Agent架构中的内存层,这将Agent从一次性助手转变为不断发展的协作伙伴。
5.上下文窗口≠记忆
一个常见的误解是,较大的上下文窗口将消除对记忆的需求。但由于某些限制,这种方法并不理想。调用包含更多上下文的 LLM 的主要缺点之一是成本高昂:更多 token = 更高的成本和延迟
|
功能特性 |
上下文窗口(Context Window) |
记忆(Memory) |
|---|---|---|
|
保留方式(Retention) |
临时的 —— 每个会话都会重置 |
持久的 —— 跨会话保留 |
|
作用范围(Scope) |
扁平且线性 —— 把所有 token 一视同仁,没有优先级概念 |
分层且结构化 —— 优先保留重要细节 |
|
扩展成本(Scaling Cost) |
高 —— 输入规模越大成本越高 |
低 —— 只存储相关信息 |
|
延迟(Latency) |
较慢 —— 提示词越大延迟越高 |
较快 —— 优化且一致 |
|
回忆方式(Recall) |
基于距离 —— 越早的内容越容易被遗忘 |
基于意图或相关性 |
|
行为特征(Behavior) |
被动反应 —— 缺乏连续性 |
自适应 —— 每次交互都会进化 |
|
个性化(Personalization) |
无 —— 每个会话都是无状态的 |
深度个性化 —— 记住偏好与历史 |
上下文窗口(Context Window)有助于Agent在会话中保持一致性。记忆(Memory)使Agent能够跨会话保持智能。由于较长的上下文容易让Agent迷失在大量的信息中而失去焦点, 即使上下文(Context)长度达到 10 万Token,由于缺乏持久性、优先级和显著性,Agent仍然不足以实现真正的智能。
6.为什么 RAG 与记忆(Memory)不同
虽然RAG(检索增强生成)和记忆(Memory)系统都检索信息来支持 LLM,但它们解决的问题却截然不同。
-
RAG在推理时将外部知识引入到提示中。它有助于将文档中的事实作为答案的基础。
-
但 RAG 从根本上来说是无状态的——它无法了解之前的交互、用户身份或当前查询与过去对话的关系。
而记忆(Memory)则带来了连续性。它会记录用户的偏好、过去的查询、做出的决策以及遇到的失败,并在未来的交互中将这些信息提供出来。
可以这样想:
RAG 帮助Agent更好地回答问题。记忆(Memory)则帮助Agent表现得更聪明。
系统层面的关键差异:
|
维度(Aspect) |
RAG:检索增强生成(Retrieval-Augmented Generation) |
智能体中的记忆(Memory in Agents) |
|---|---|---|
|
时间感知(Temporal Awareness) |
没有时间或事件顺序的概念 |
追踪交互的顺序、时间点以及演变过程 |
|
状态保持(Statefulness) |
无状态,每次查询都是独立的 |
有状态,上下文可在多次会话中累积 |
|
用户建模(User Modeling) |
仅限于当前任务,与用户身份无关 |
随着用户的互动进行学习和进化 |
|
适应能力(Adaptability) |
不能从过去的交互中学习 |
基于过去有效或无效的经验自适应调整 |
在构建智能体时您需要两者——RAG 来为 LLM提供信息,记忆(Memory)来塑造其行为。
7.代理中的记忆类型:高级分类法
在基础层面,AI 智能体中的记忆有两种形式:
-
短期记忆:在一次交互中保存即时的上下文信息。
-
长期记忆:在不同的会话、任务和时间跨度中持续保留知识。
就像人类一样,这两种记忆类型承担着不同的认知功能,短期记忆帮助智能体在当前时刻保持连贯性,长期记忆则帮助它学习、个性化以及适应变化。
让我们进一步分解一下:
|
类型 |
作用 |
示例 |
|---|---|---|
|
工作记忆(短期) |
维持短期的对话连贯性 |
“你刚才问的最后一个问题是什么来着?” |
|
事实记忆(长期) |
保留用户偏好、沟通风格、领域上下文 |
“你更喜欢 Markdown 格式的输出和简短的回答。” |
|
情景记忆(长期) |
记住特定的过去交互或结果 |
“上次我们部署这个模型时,延迟增加了。” |
|
语义记忆(长期) |
存储随着时间积累的一般性、抽象性知识 |
“涉及 JSON 解析的任务通常会让你有压力,要不要一个快捷模版?” |
8.如何维护记忆(Memory)

记忆不仅仅是一个附加功能,更是AI智能体的核心。智能体构建一般围绕着以下策略打造真正的、类似人类的记忆能力:
-
智能过滤(Intelligent Filtering):
并非所有信息都值得被记住。可以使用优先级评分和上下文标签来决定哪些信息需要存储,这避免了记忆膨胀,让智能体专注于关键内容——就像人类会在潜意识中过滤掉噪音。 -
动态遗忘(Dynamic Forgetting):
一个好的记忆系统必须懂得有效遗忘。不要把记忆当作静态堆放的垃圾场,而是会随着时间衰减低相关度的条目,释放存储和注意力空间。忘记并不是缺陷,而是智能记忆的功能之一。 -
记忆巩固(Memory Consolidation):
我们会根据使用模式、最近性以及重要程度,在短期记忆和长期记忆之间移动信息,从而同时优化提取速度和存储效率。这模仿了人类将知识“内化”的方式。 -
跨会话连续性(Cross-Session Continuity):
大多数智能体在会话结束后都会重置。设计良好的记忆架构能在不同会话、不同设备、不同时间段中保持相关的上下文。
9.记忆的应用
以下是记忆在真实应用场景中如何改变智能体行为的方式:
-
客服助理(Support Agent):
不再把每次投诉都当作新的问题,而是记住过去的问题和解决方案 —— 从而提供更顺畅、更个性化的支持体验。 -
个人助理(Personal Assistant):
随着时间推移适应你的习惯 —— 例如根据你的日常作息来安排会议,而不仅仅是按日历时间表操作。 -
编程助手(Coding Copilot):
学会你的编码风格、偏好的工具,甚至会避免使用你不喜欢的代码模式。
10.总结:记忆是基础,而不是附加功能
在一个所有智能体都能使用相同模型和工具的世界里,记忆将成为关键的差异化因素。胜出的,不是那个仅会回应的智能体,而是那个会记住、会学习、并能与你一起成长的智能体。
记忆并不是精英智能体才有的附加功能或额外能力,它是把智能体从一次性工具转变为长期协作伙伴的基础。
本文奠定了基础,在接下来的文章中,我们将深入探讨:
-
记忆在底层是如何工作的 —— 从架构与数据流到实际的集成方式
-
记忆在智能体系统中的应用案例(实操示例)
-
记忆的评估指标(回忆率、重要性、衰减机制)
在此之前,请记住这一点:
在一个充满通用型智能体的世界里,如果你在思考人类与 AI 交互的未来,记忆不是可选项,而是必需品。让我们一起构建会记忆的 AI 吧。

欢迎加入北京社区
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)