
Fluentd:日志收集这件事,它想统一标准
Fluentd:日志收集这件事,它想统一标准
做运维或者搞数据的人都知道,日志管理是个老大难问题。应用日志、系统日志、网络日志,格式五花八门,存的地方也不一样。想做个统一分析?先得把散落各处的日志收集起来。
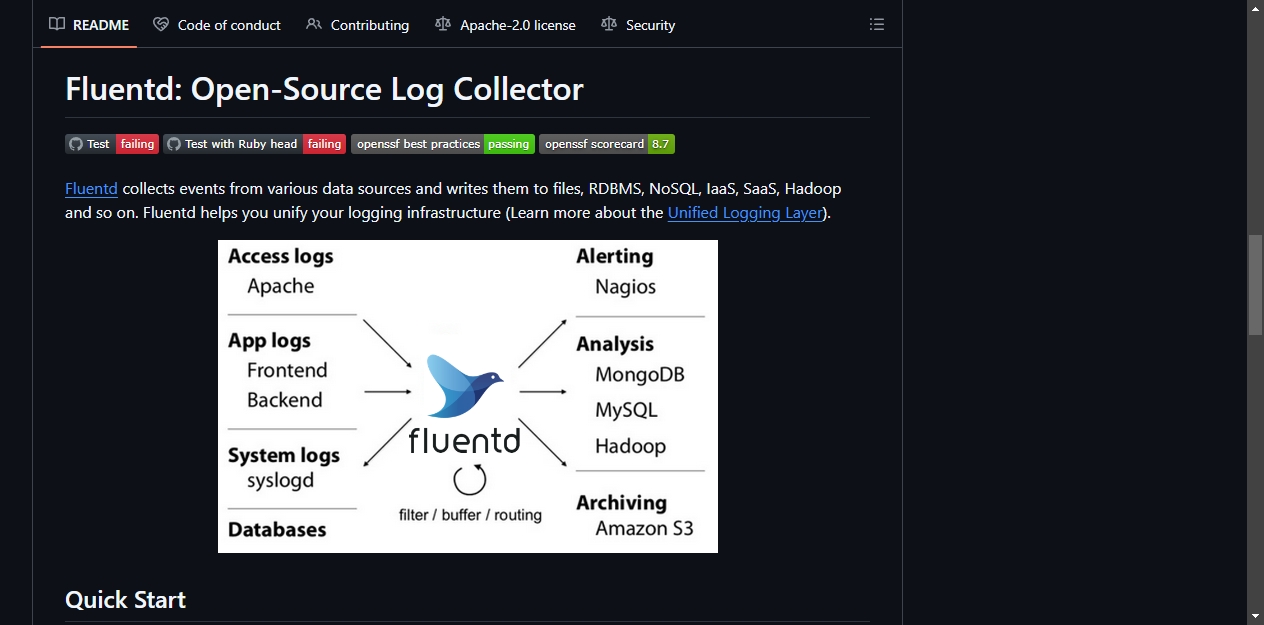
Fluentd 就是干这个的。它是一个开源的日志收集器,目标很明确:统一日志层。把各种来源的日志收集起来,统一格式,然后转发到你指定的地方存起来。
能干什么
Fluentd 的核心能力就两点:收集和转发。
收集端,它支持从文件、Socket、HTTP 等多种方式接收日志。不管你日志是 JSON 格式、纯文本还是自定义格式,它都能处理。
转发端,它能把日志写到文件、数据库(MySQL、MongoDB)、搜索引擎(Elasticsearch)、云存储(S3)等各种地方。你用什么存储,它就往哪写。
用法也简单。装好之后写个配置文件,指定日志来源和去向,启动就行。Ruby 写的,gem install 直接装。
$ gem install fluentd
$ fluentd -s conf
$ fluentd -c conf/fluent.conf &
$ echo '{"json":"message"}' | fluent-cat debug.test
为什么值得关注
1. CNCF 毕业项目
Fluentd 是云原生计算基金会(CNCF)的毕业项目,和 Kubernetes 同级别。这意味着它经过了严格的社区审核,质量有保障。在云原生领域,它的地位很稳。
2. 插件生态丰富
官方插件超过 500 个,覆盖了主流的日志来源和存储目标。你想接什么系统,基本都有现成的插件可用。不用自己写代码去对接。
3. 架构轻量
单个 Fluentd 实例资源占用很小,适合在每台服务器上部署。收集完本地日志再统一转发,架构清晰。大规模场景下也能横向扩展。
实际使用场景
最常见的场景是 Kubernetes 日志收集。在每个节点跑一个 Fluentd,收集容器日志,然后统一发到 Elasticsearch。配合 Kibana 做可视化,就是一套完整的日志分析方案。
另一个场景是多云环境下的日志统一。你可能同时用了 AWS、阿里云,日志分散在各处。Fluentd 能把它们收集到一个地方,方便统一查询。
适合谁用
如果你在做运维、SRE 或者数据工程,日志收集是绕不开的环节。Fluentd 是这个领域的主流选择之一,文档完善,社区活跃。
如果你在用 Kubernetes,Fluentd 几乎是标配。很多 K8s 发行版自带 Fluentd 作为日志组件。
当然也有局限。Fluentd 是 Ruby 写的,性能上比 Go 写的同类工具(如 Fluent Bit)差一些。但对大多数场景来说够用了。真有性能瓶颈,可以考虑 Fluent Bit 作为轻量替代。
这是个实实在在解决运维痛点的工具,不花哨,但管用。
能瓶颈,可以考虑 Fluent Bit 作为轻量替代。
这是个实实在在解决运维痛点的工具,不花哨,但管用。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)