
Python 文件 IO 操作与序列化详解:with 语法、文件读写、pickle/json 序列化全梳理
·
前言
在 Python 开发中,文件 IO 读写和对象序列化是高频基础知识点,日常配置文件存储、数据落地、对象持久化都离不开这两块内容。本文结合实操代码,分两大模块讲解:with上下文管理器文件操作、pickle&json对象序列化,所有示例代码和实操截图保持一致,可直接复制运行。
一、文件 IO:with 上下文管理器用法
原生open()打开文件需要手动调用close()关闭文件,容易遗漏造成文件句柄泄露,Python 提供with语法自动管理文件开关,代码块结束自动执行 close (),简化文件读写代码。
with 语法核心特点
- 自动调用
close(),无需手动关闭文件; - 语法格式:
with open(文件路径,打开模式) as 文件别名: 业务代码; - 支持同时打开多个文件,实现一键多文件读写、文件复制。
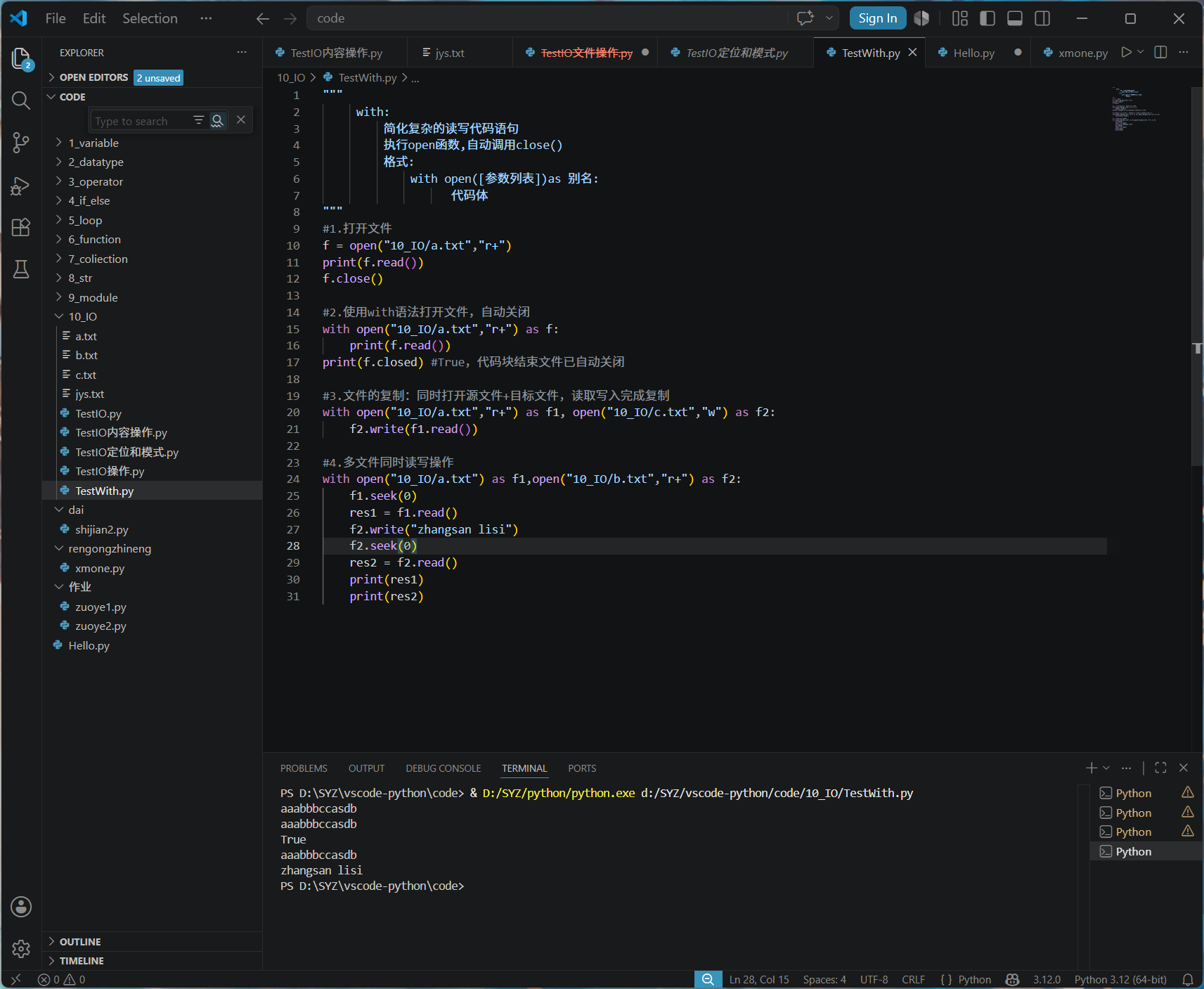
代码说明
r+:读写模式,文件必须存在;w:只写模式,不存在新建、存在清空原内容;seek(0):文件指针回到文件开头,从头读取内容;f.closed:查看文件是否关闭,with 代码执行完毕自动关闭,结果返回True
二、Python 对象序列化:pickle 与 json 模块
序列化概念
序列化:将内存中列表、字典、元组、集合这类抽象 Python 对象,转换成可落地保存的字节 / 字符串数据存入文件;反序列化:从文件读取字节 / 字符串,还原成原始 Python 对象。两大常用模块:
pickle:对象 <=> 二进制字节,支持所有 Python 数据类型;json:对象 <=> 普通字符串,只支持字典、列表、基础数值类型,跨语言通用。
pickle 模块实操代码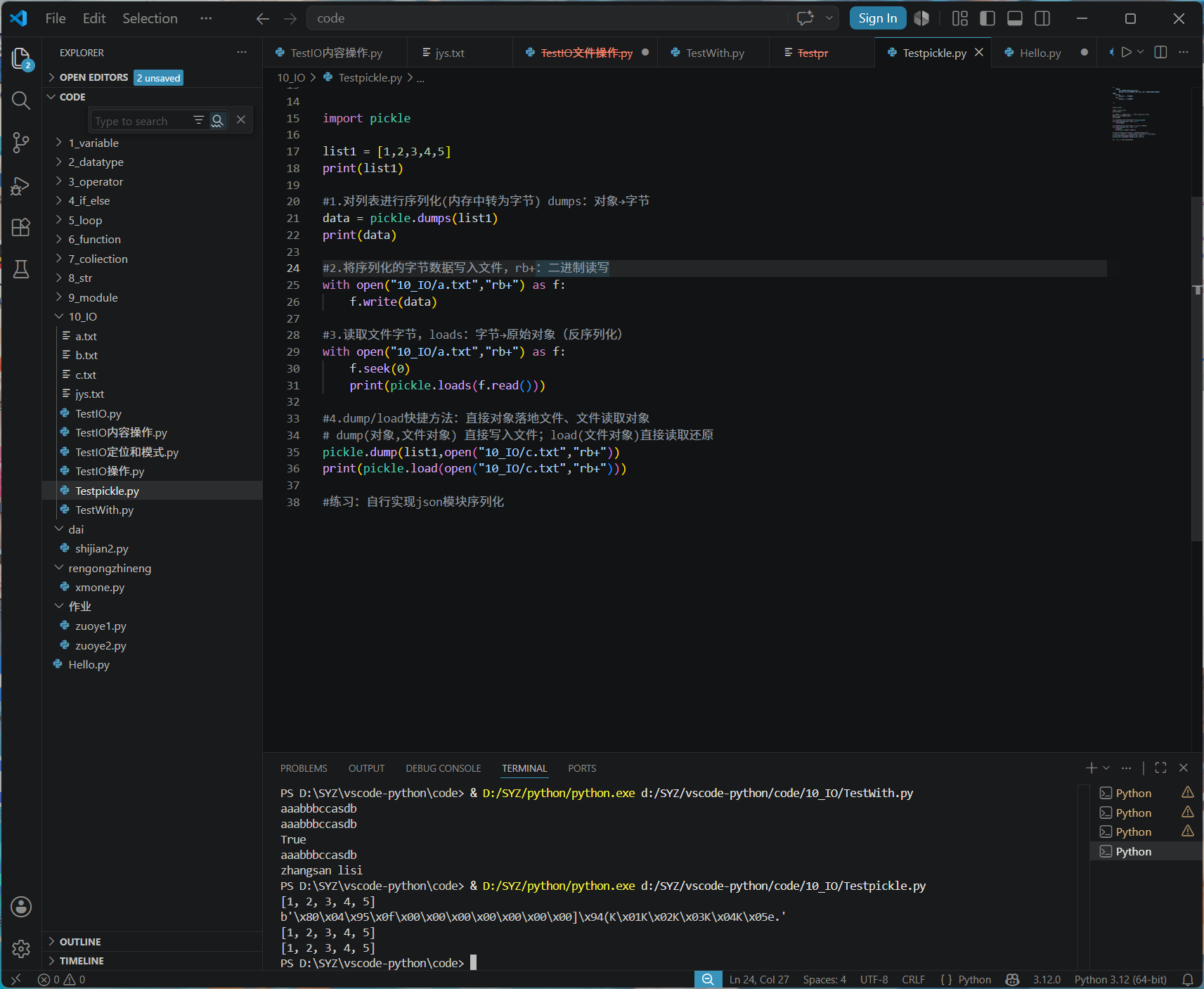
pickle 四个核心方法
表格
| 方法 | 作用 |
|---|---|
dumps(obj) |
内存序列化:对象→二进制 bytes |
loads(bytes) |
内存反序列化:bytes→原对象 |
dump(obj,fp) |
落地序列化:对象直接写入文件 |
load(fp) |
落地反序列化:从文件读取还原对象 |
拓展:json 序列化练习参考
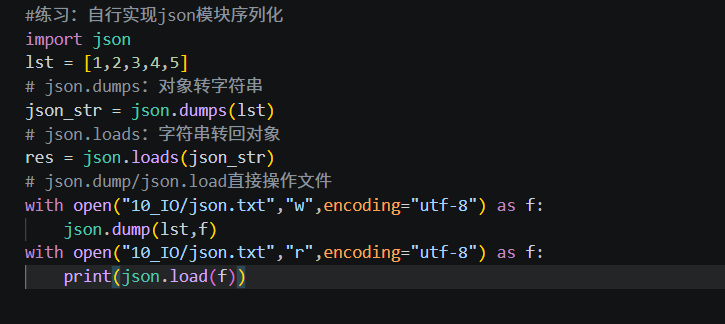
三、知识点总结
- with 文件操作:优先使用 with 代替原生 open+close,自动回收资源,支持多文件同时打开,适合文件复制、批量读写;
- pickle 适用场景:Python 程序内部数据持久化,保存自定义对象、集合等 Python 独有类型;
- json 适用场景:前后端交互、跨语言数据传输,通用文本格式,只能序列化基础数据。
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)