
Java数据结构7(优先级队列)
一,目录
1,概念
2,堆的创建及相关方法的实现
3,常用接口介绍
4,top(k)问题
5,堆排序
一,概念
前⾯介绍过队列,队列是⼀种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先 级,⼀般出队列时,可能需要优先级⾼的元素先出队列,该中场景下,使⽤队列显然不合适,⽐如: 在⼿机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话;初中那会班主任排座位 时可能会让成绩好的同学先挑座位。 在这种情况下,数据结构应该提供两个最基本的操作,⼀个是返回最⾼优先级对象,⼀个是添加新的 对象。这种数据结构就是优先级队列(Priority Queue)。
优先级队列底层是使用了堆这种数据结构,而堆就是在完全二叉树的基础上进行了一些调整
二,创建及相关方法
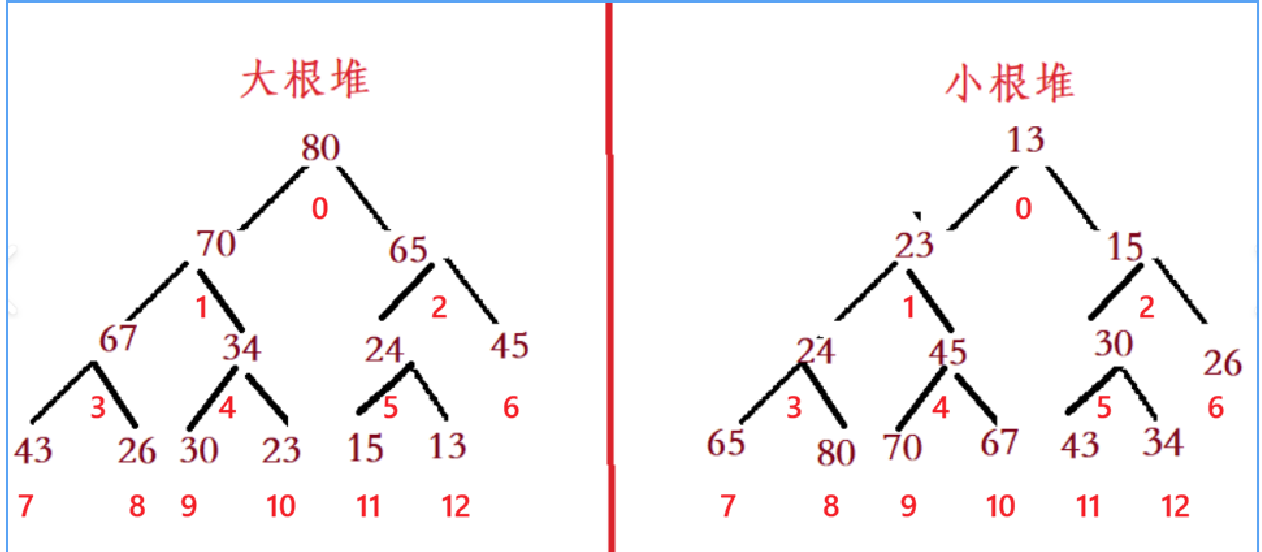
堆主要分为大根堆和小根堆
这两种都是在完全二叉树的基础上进行调整得来的,大根堆就是每一棵树的根都是根及其左右子树中最大的,小根堆就是每一棵树的根都是根及其左右子树中最小的,所以也有一个特点就是大根堆中根节点是最大的元素,小根堆中根结点是最小的元素,如下80就是所有元素里最大的,13就是所有元素里最小的
一:创建
1,我们先根据堆的思想来创建一个大根堆,其中的parent和child均为下标
2,具体做法是先找到最后一个左孩子的父亲节点的下标:我们就按照上图的树,也就是找到5的下标,我们还要引入一些前情数据,usedsize为13,那么根据完全二叉树的公式就知道,不管是左孩子还是右孩子,他们的父亲节点都是-1再/2,所以父亲节点的下标为(usedsize-1-1)/2,所以初始的parent=(usedsize-1-1)/2,然后parent依次往上,然后进行一个向下的调整
3,接下来就是要完成向下调整的一个代码,具体操作就是在左右孩子节点中找到最大的,然后将他的下标标记为chlid,然后将他和父亲节点进行比较,观察是否需要交换,交换完,交换下来的那个值并不一定是待在那个地方的,可能还需要和下面的数值进行一个调整,所以让parent等于child,然后child乘2加1,继续进行一个调整,当不需要调整的时候,就退出循环
具体代码如下
public class TestHeap {
public int[] elem;
public int usedsize;
public TestHeap(){
this.elem = new int[15];
}
public void init(int[] array){
for (int i = 0; i < array.length; i++) {
elem[i]=array[i];
usedsize++;
}
}
//
public void creatheap(){
//先找到最后一颗子树的根节点的下标
for (int parent = (usedsize-1-1)/2; parent >=0; parent--) {
shelldown(parent, usedsize);
}
}
//向下调整
private void shelldown(int parent,int usedsize){
//1,先取得左孩子节点的下标
int child=parent*2+1;
//调整到child小于usedsize的时候
while (child<usedsize){
//先取得左右孩子中最大的,并且得保证有右孩子的情况下,没有就直接不用变
if (child+1<usedsize && elem[child]<elem[child+1]){
child++;
}
//现在child里面存储的就是左右孩子里的最大值的下标,然后进行交换
if (elem[child]>elem[parent]){
swap(elem,parent,child);
//只能保证调整了的是正确的,但是还得向下调整保证换完的也是大根堆
parent=child;
child=parent*2+1;
} else {
break;
}
}
}
//交换
private void swap(int[] elem,int i,int j){
int tmp=elem[i];
elem[i]=elem[j];
elem[j]=tmp;
}
}二:相关方法
1,增加元素
public void offer(int val){
//先判断有没有满,满了就得扩容
if (isfull()){
elem= Arrays.copyOf(elem,2*elem.length);
}
elem[usedsize]=val;
siftup(usedsize);
usedsize++;
}
private void siftup(int child) {
int parent=(child-1)/2;
//调整到parent>=0或者child>0的时候
while (child>0){
if (elem[child]>elem[parent]){
swap(elem,child,parent);
child=parent;
parent=(child-1)/2;
}else {
break;
}
}
}
public boolean isfull(){
return usedsize==elem.length;
}2,删除元素(头删)
public void pull(){
if (isempty()){
return;
}
//让首元素和最后一个元素交换
swap(elem,elem[0],elem[usedsize-1]);
usedsize--;
//让首元素进行向下调整
shelldown(0,usedsize);
}
public boolean isempty(){
return elem.length==0;
}
}三,常用接口介绍
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列, PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,本⽂主要介绍 PriorityQueue,PriorityQueue当中也有相应的方法,如offer,peek等
PriorityQueue<Integer> priorityQueue=new PriorityQueue<>();
priorityQueue.offer(10);
priorityQueue.offer(3);
priorityQueue.offer(9);
System.out.println(priorityQueue.peek());我们通过peek方法可以知道系统自带的PriorityQueue是个小根堆,然后我们通过源码来看看它的构造方法,以及有没有方法来使其变成一个大根堆
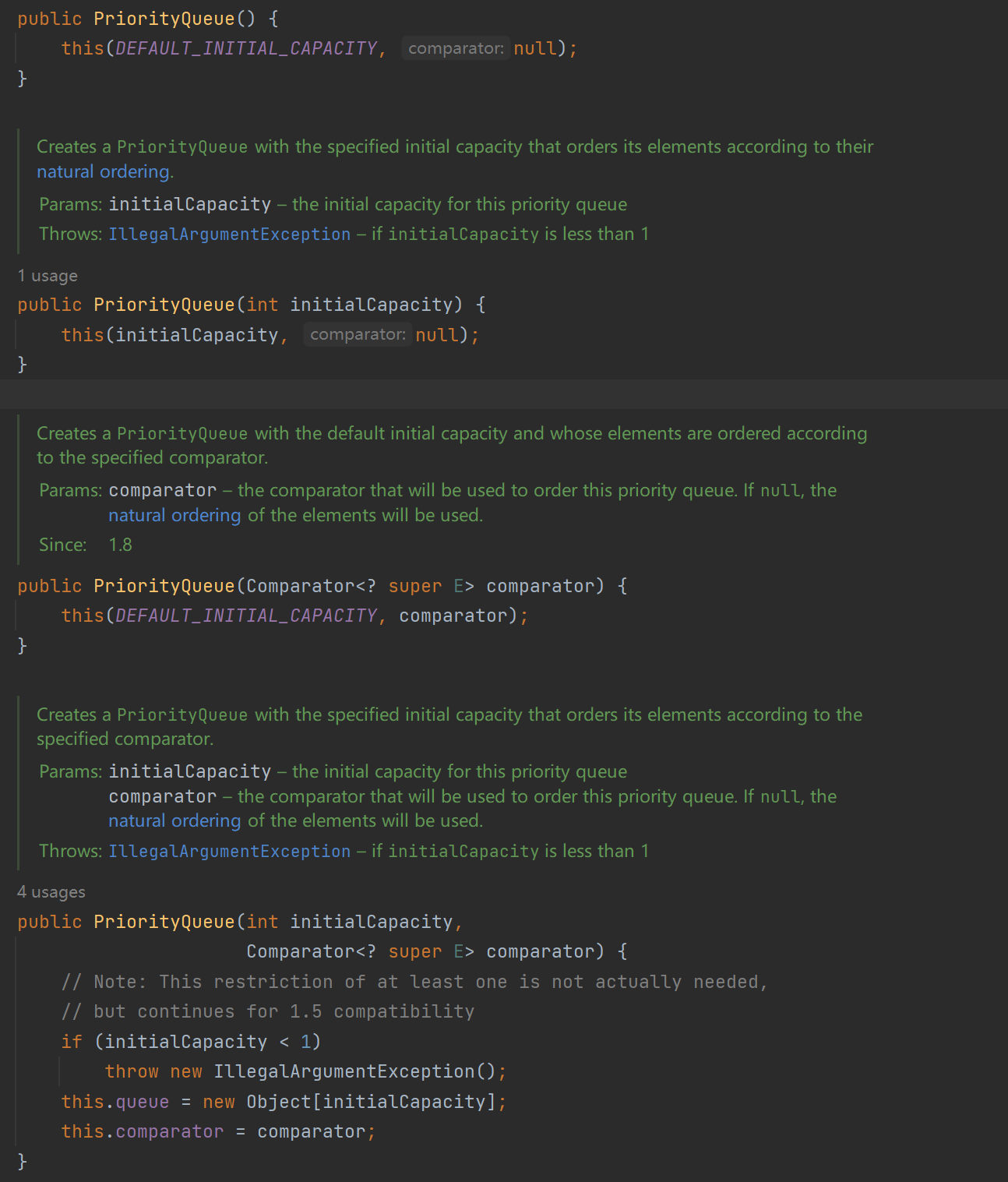
通过源码的构造方法可以看出,有没有参数的也有两个参数的,其中的传入的比较器成为了关键
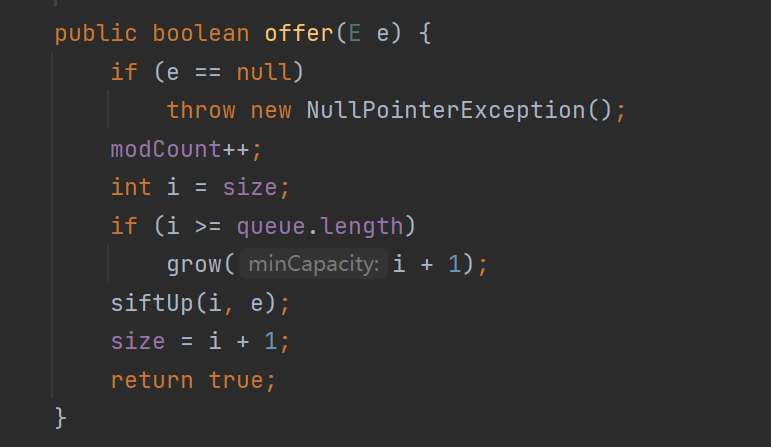
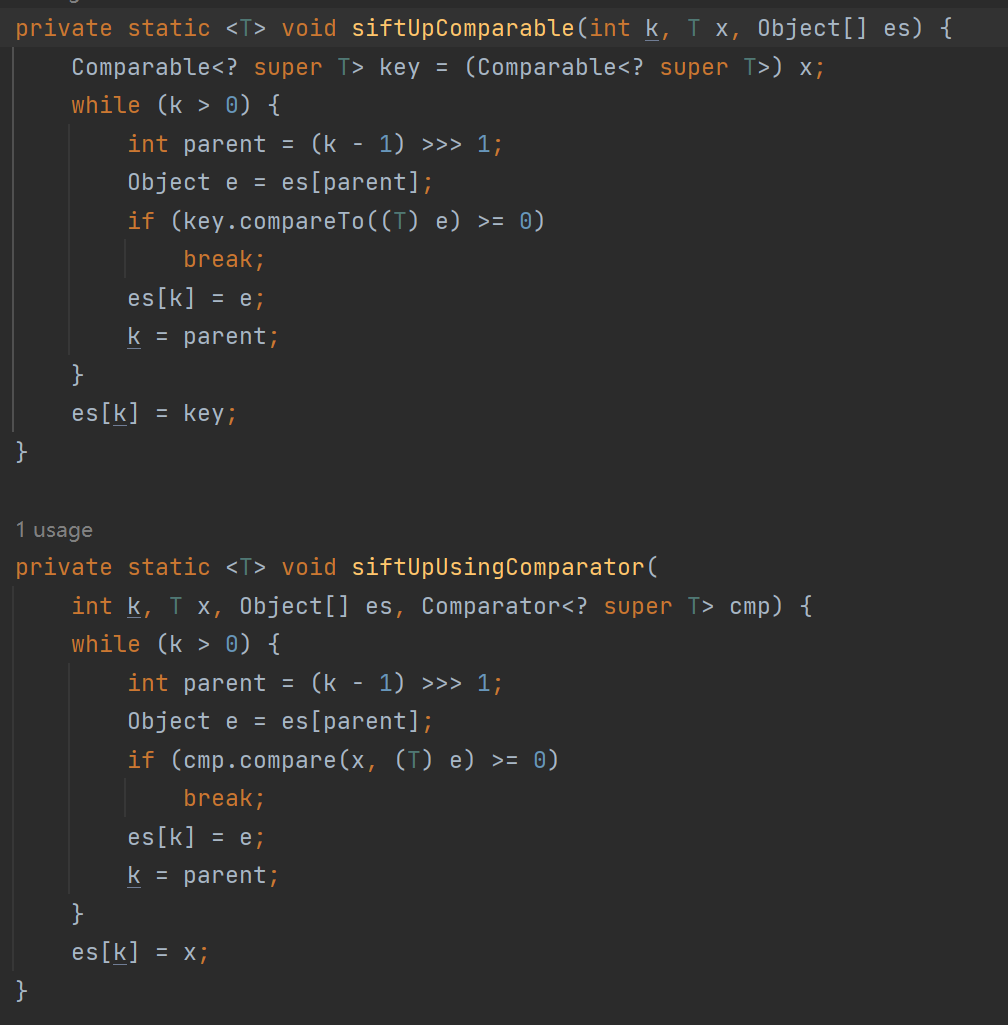
点入到offer方法里面可以发现有两种,一种是传入比较器,一种是使用默认的比较方法,所以我们只要写一个比较器,里面比较的方法根默认的是相反的话,那么就可以实现大根堆了,我来展示两种重写的比较方法
class imp implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
}第一种就是写一个比较器,在PriorityQueue调用的时候传入这个imp类就行了
PriorityQueue<Integer> priorityQueue2=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});第二种方法通过匿名内部类来实现
什么是匿名内部类
没有名字的局部内部类,只用一次、用完就丢,不用单独新建 .java 文件写类;
只能实现一个接口 / 继承一个父类;
核心场景:快速实现函数式接口(Comparator、Runnable 等)。
四,top(k)问题
当我们要求一些数据的最大或者最小的k个的时候,我们可以用排序来找到前面的数据,当然也可以运用到堆,当我们要求前k个最小的数据的时候,我们可以创建一个大根堆,堆的数据个数为k,并且每次用下一个数据跟堆顶的元素进行比较,因为堆顶的数据肯定是k个中最大的,我们考虑换元素也是优先考虑它,具体代码如下
//top k问题
public int[] smallk(int[] array,int k){
//先判断数据
int[] ret=new int[k];
if (array==null||k==0){
return null;
}
//创建一个大根堆
PriorityQueue<Integer> priorityQueue=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
//将前k个数据放在大根堆里面
for (int i = 0; i <= k; i++) {
priorityQueue.offer(array[i]);
}
//将后面的数据跟堆顶进行比较,来调整堆
int peekval=priorityQueue.peek();
for (int i = k+1; i < array.length; i++) {
if (peekval>array[i]){
priorityQueue.poll();
priorityQueue.offer(array[i]);
}
}
for (int i = 0; i < k; i++) {
int val=priorityQueue.poll();
ret[i]=val;
}
return ret;
}五,堆排序
我们以从小到大来排序,就紧接在我们刚刚自己实现的大根堆下面,堆排序主要的思路就是找到堆顶元素,因为它是最大的,然后将其和最后一个元素进行交换,可以拿一个end下标来记录大的元素,end就等于usedsize-1,然后进行向下调整,最后调整到堆顶元素为最小值,然后依次增大
//从小到大排
public void heapsort(){
int end=usedsize-1;
while (end>0){
swap(elem,0,end);
shelldown(0,end);
end--;
}
}自己的小问题以及理解:怎么理解创建堆的时候,传入的parent是最后一颗子树的父亲节点,但是后面我要自己调整的时候可以直接传入0下标
因为建堆的时候,所有数据都是乱给的,没有一个数据是排序好的,所以从最后一个往前调整,但是排序的时候,我们交换了最后一个以及堆顶的元素的时候,堆顶的左右子树都是完整的大根堆,已经是排序好的,所以堆顶的三个元素组成的树是需要调整的,所以传入0下标,然后后续下面有问题再shelldown里面也会接着调整
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)