
C++之set,map的使用
set是按一定顺序来存储数据的容器,而且数据是独一无二,不重复的。并且数值不能修改,但是可以插入和删除。
接下来我们来看set的使用
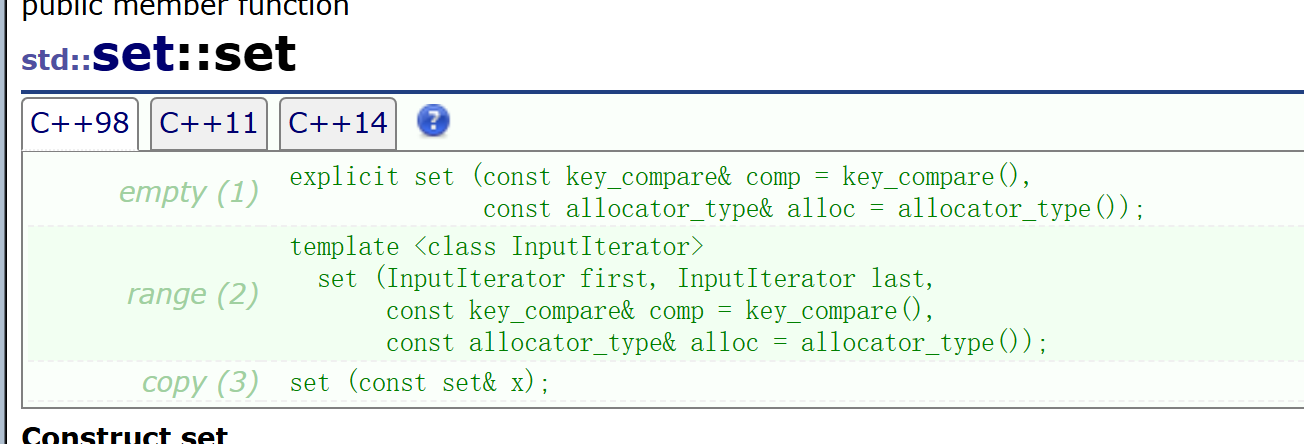
迭代器进行初始化
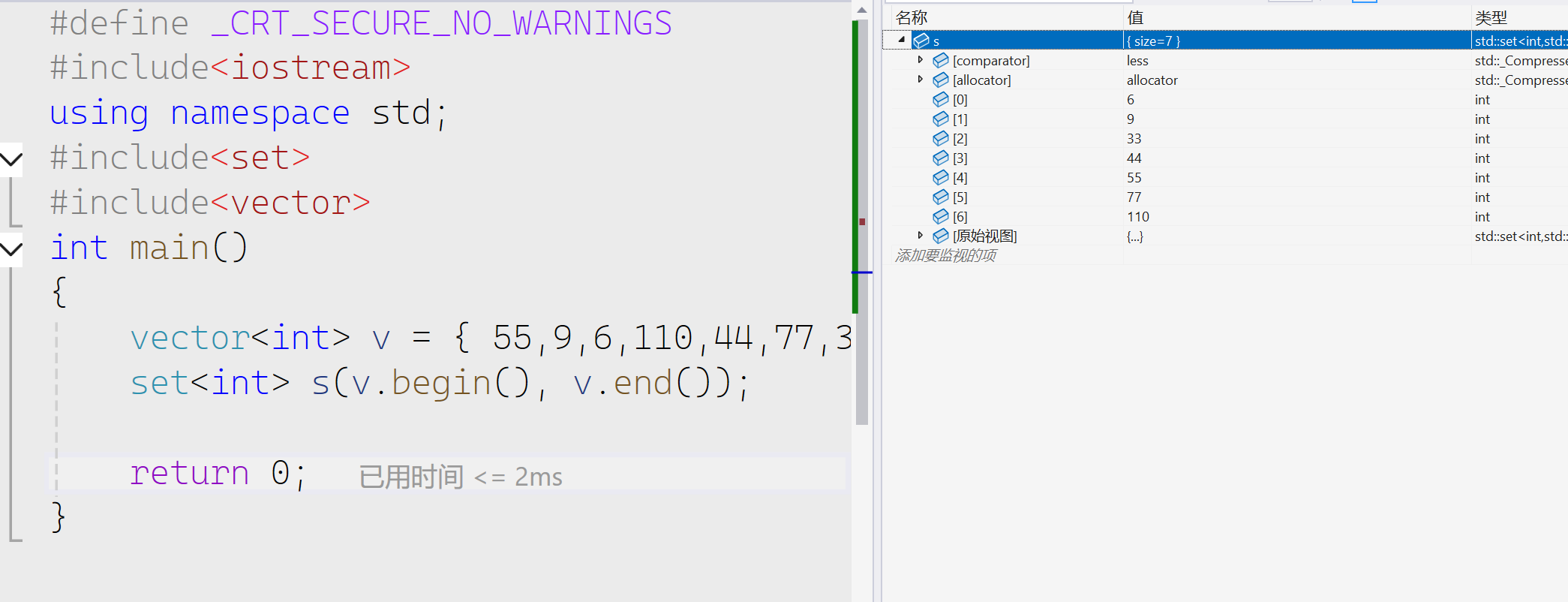
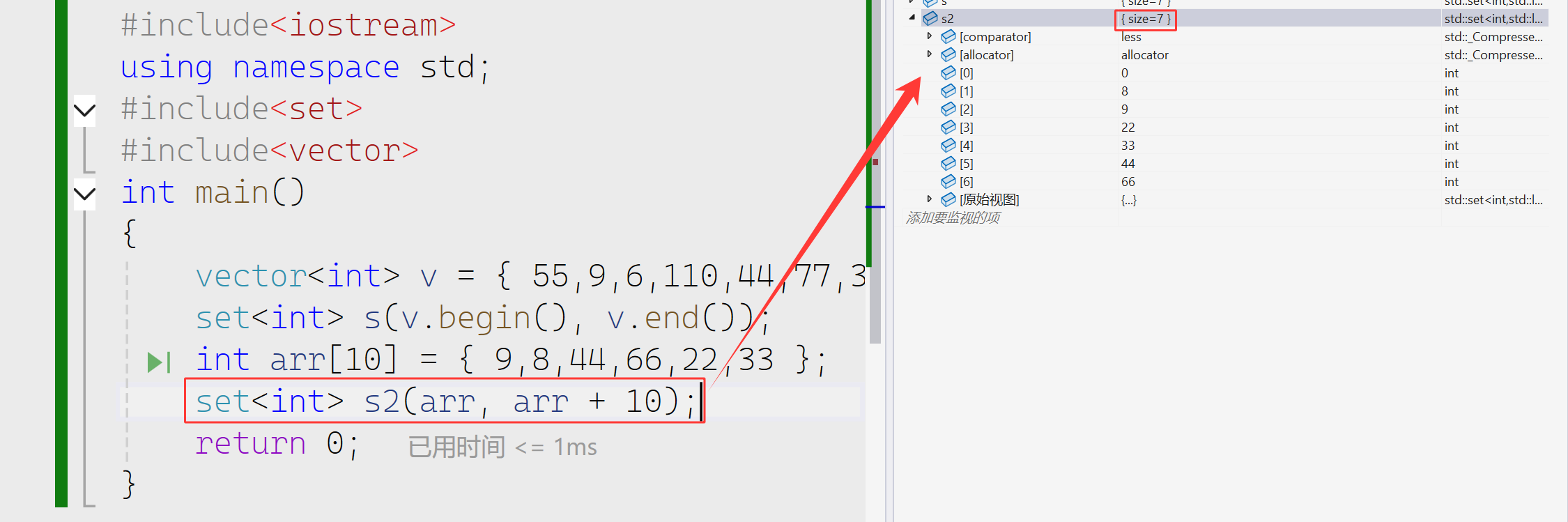
数组进行初始化
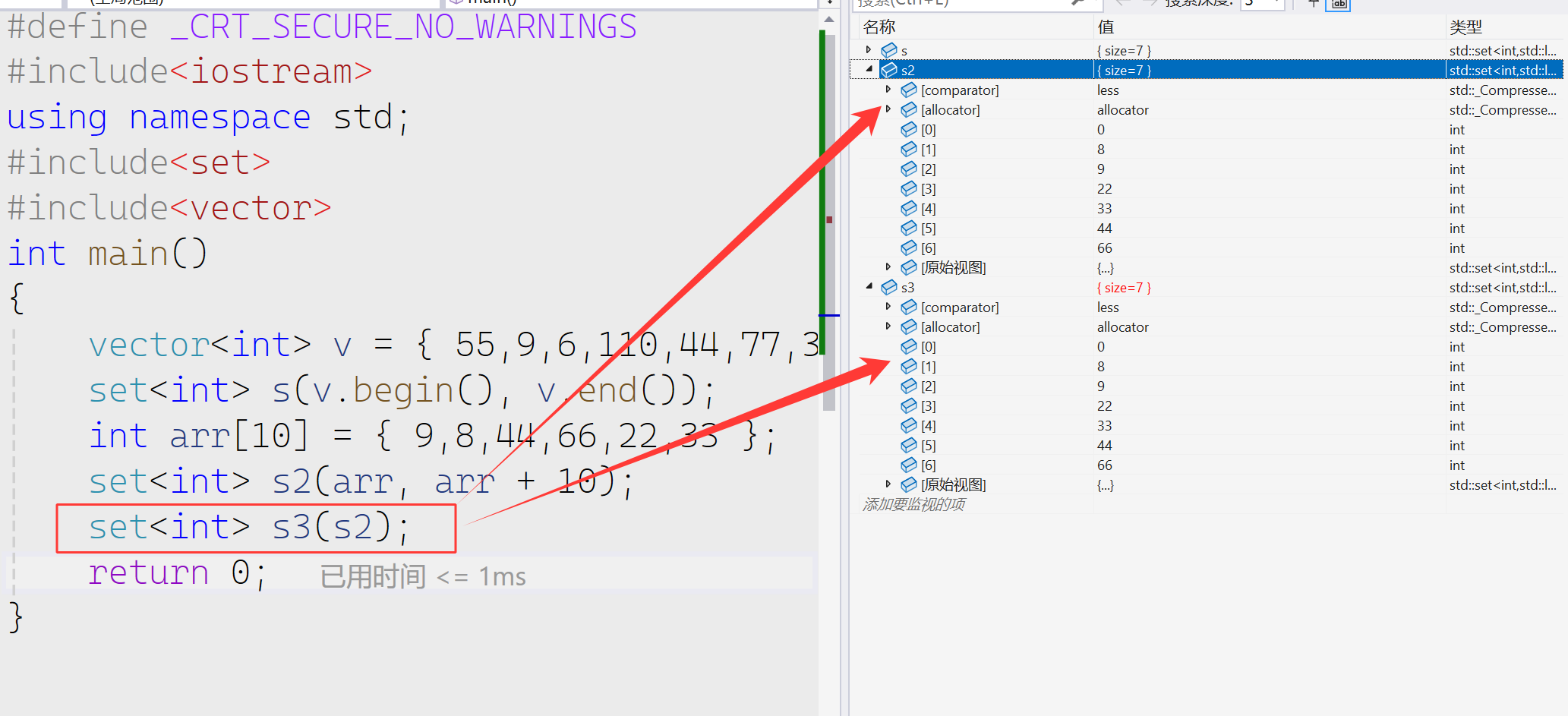
构造进行初始化
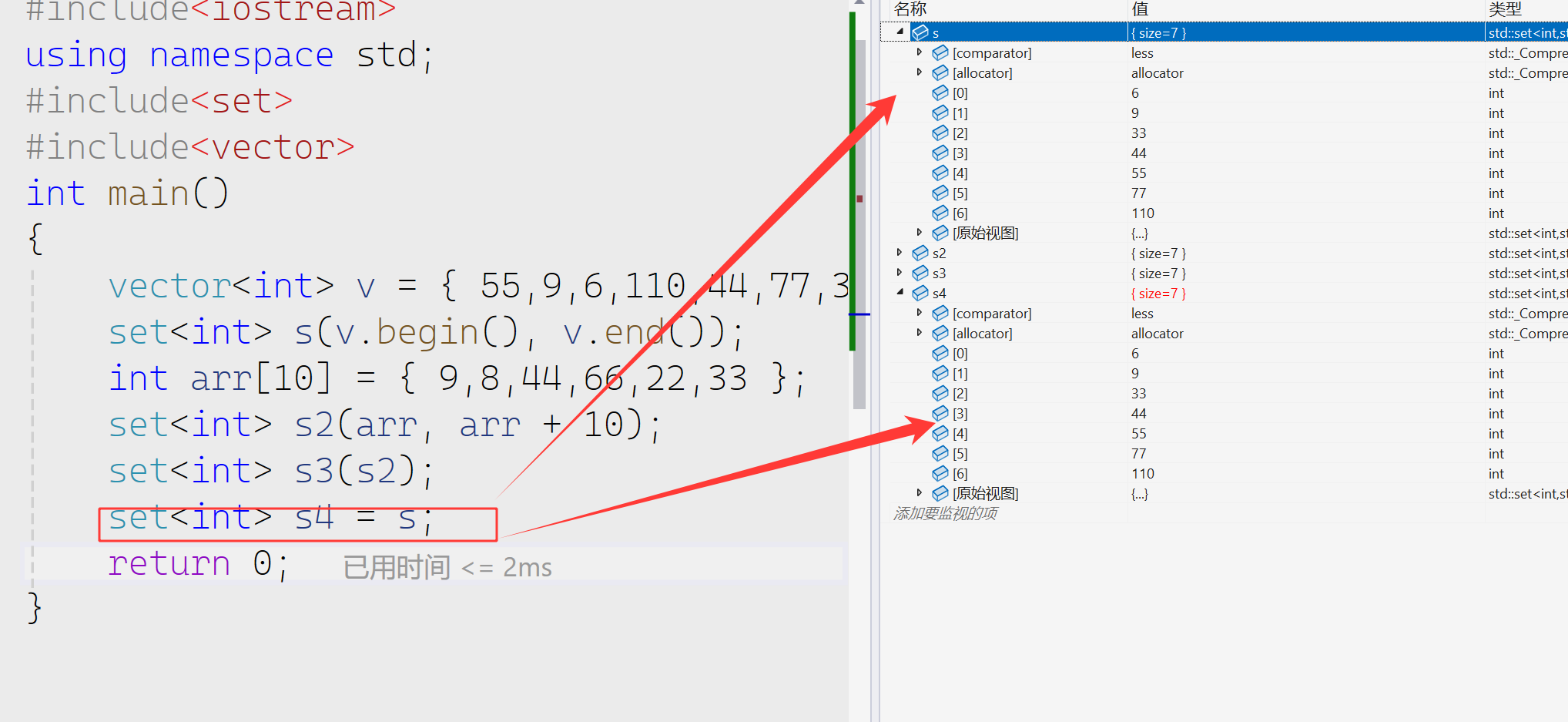
赋值重载进行初始化
我们也可以在上面看出set会自动去重,默认从小到大进行排序。
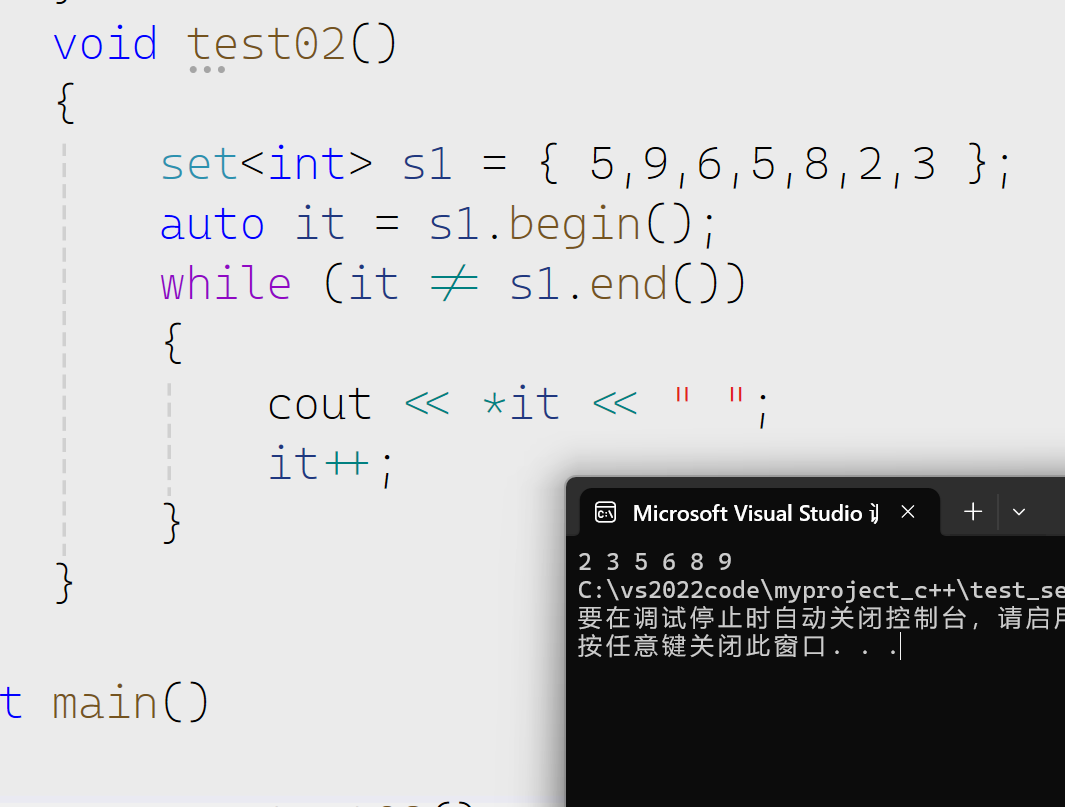
迭代器部分
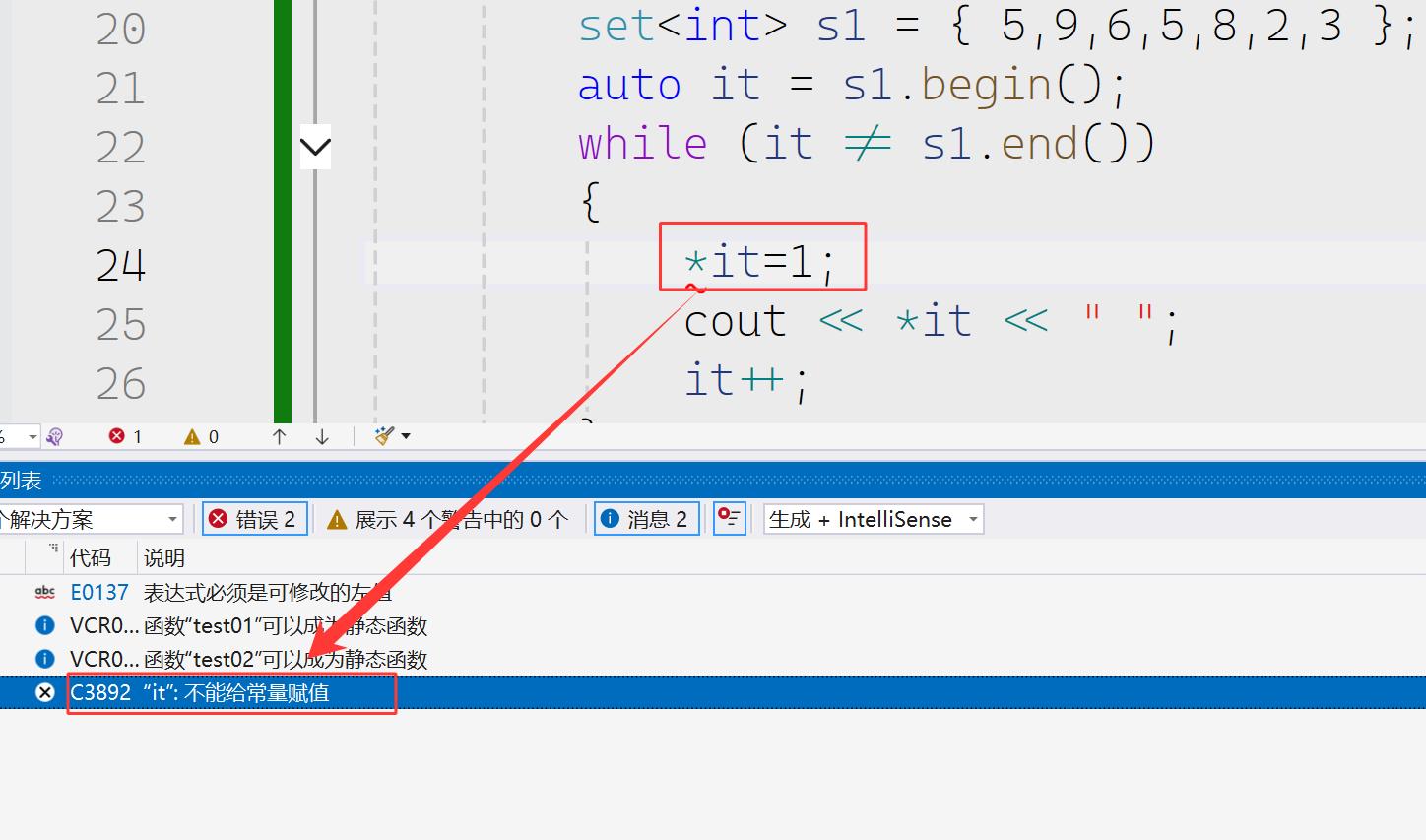
当然这是一个普通的迭代器是不支持修改的
修改部分
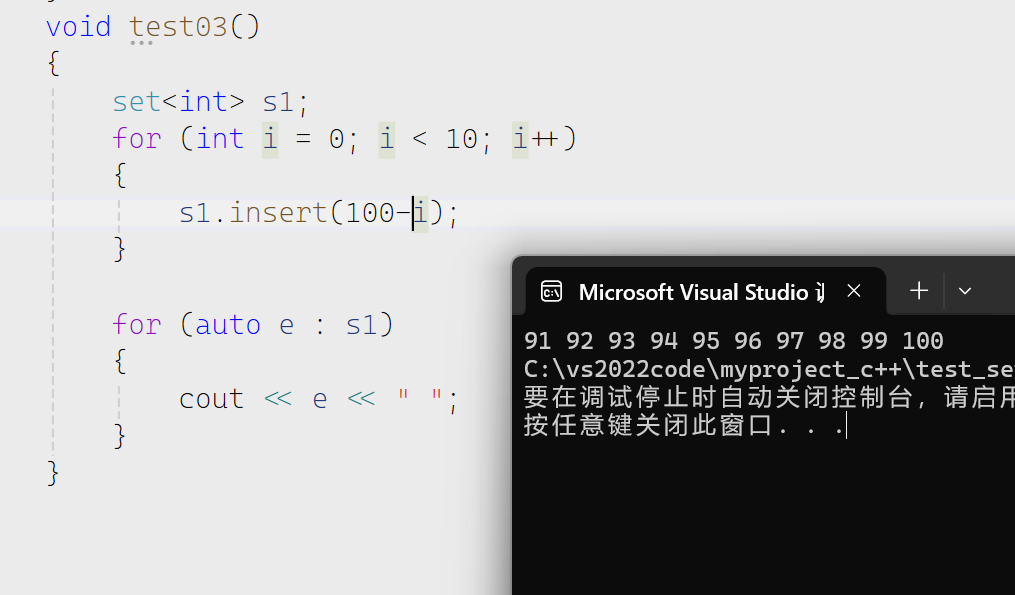
insert
相对而言第一种插入使用会更多
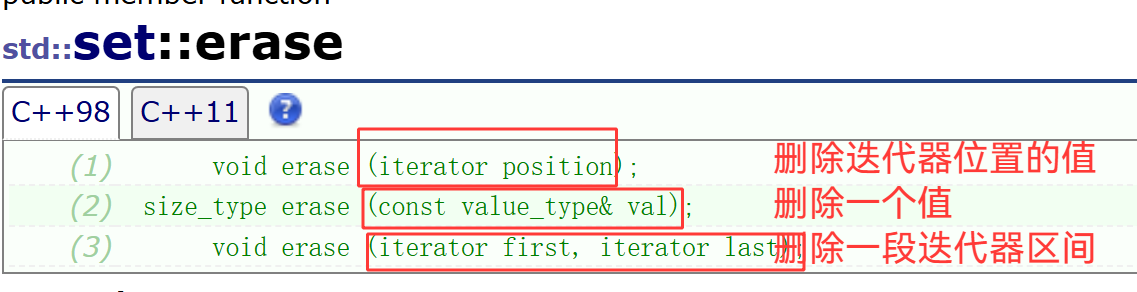
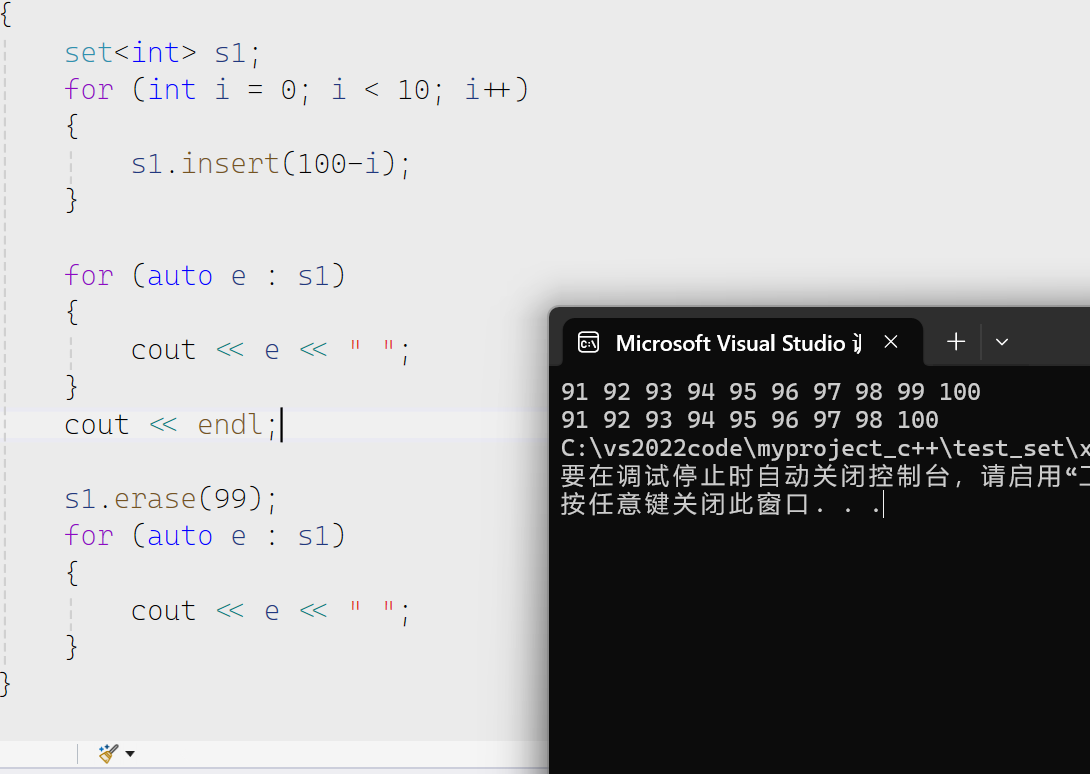
earse
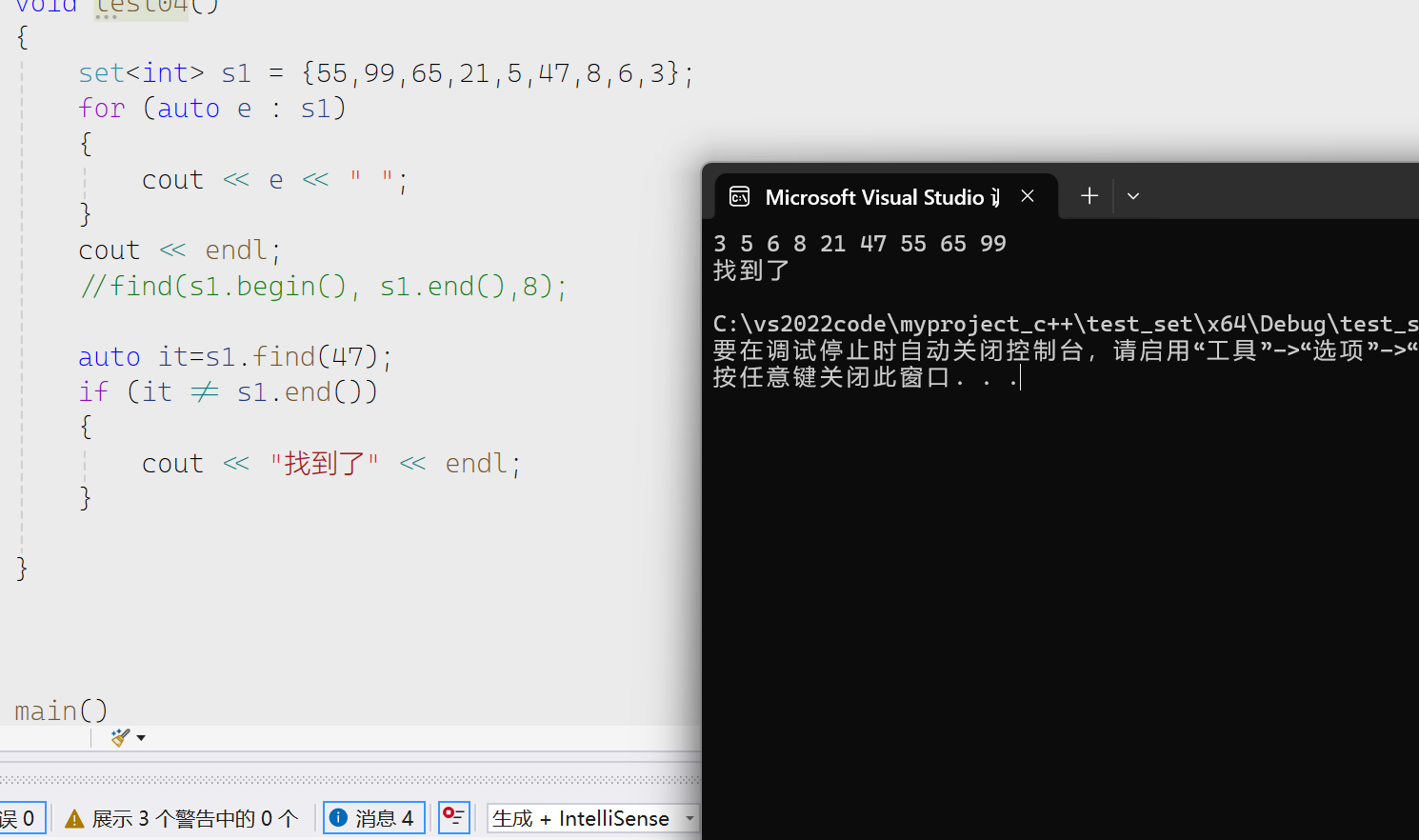
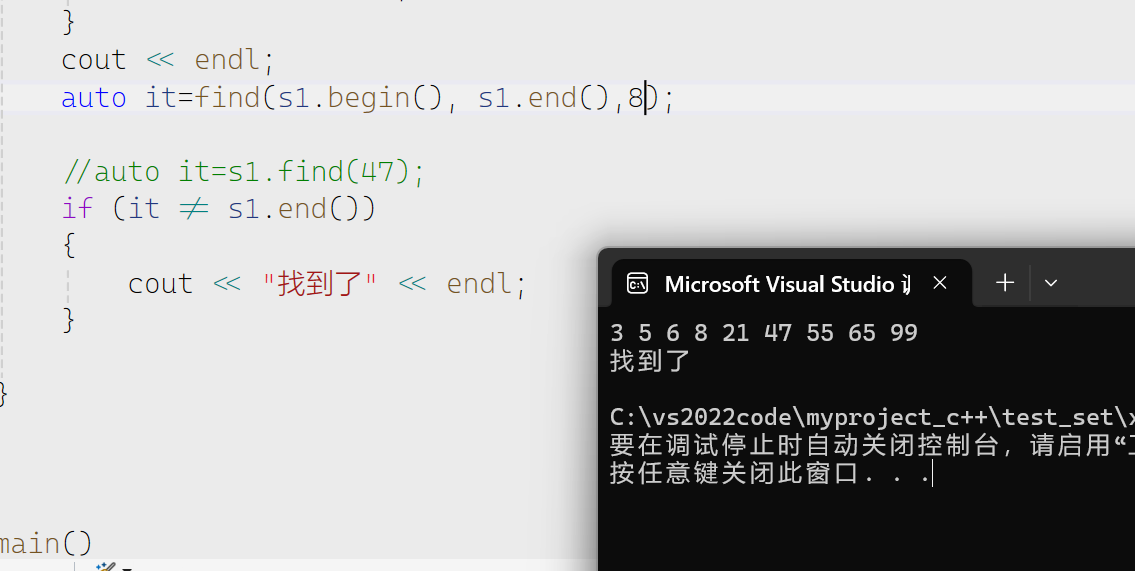
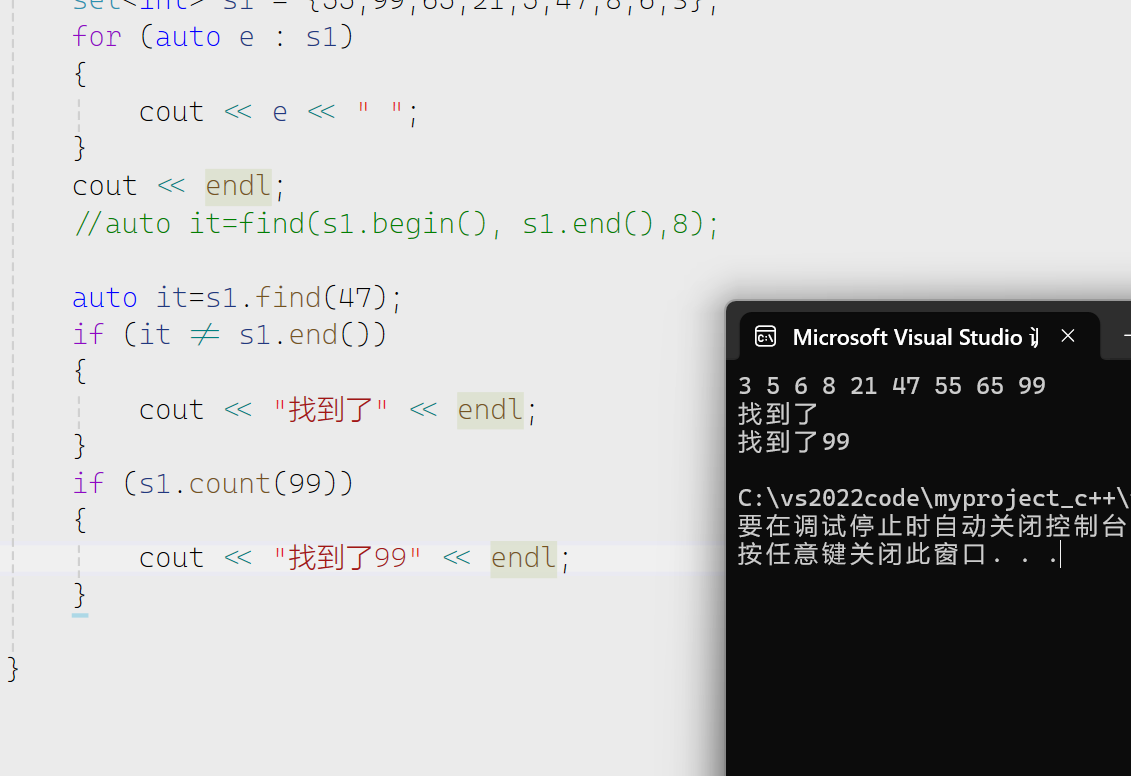
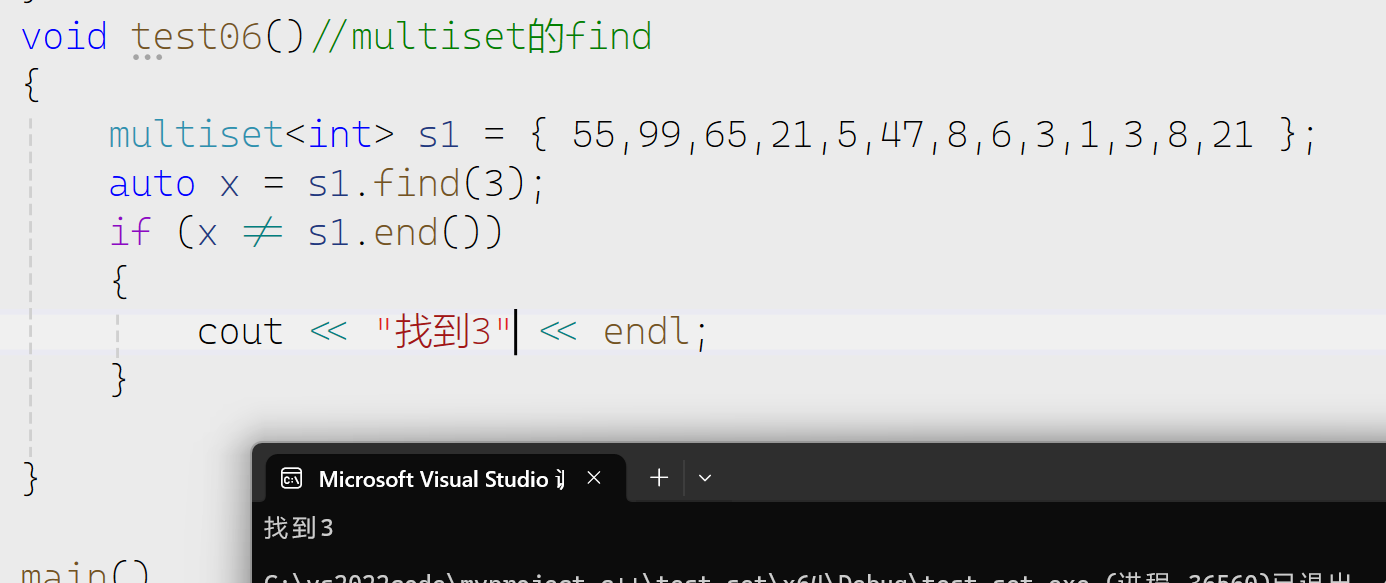
find
我们看到算法库和set成员函数都有find,但是我们用set的因为两个时间效率上有巨大的差异,set的find底层使用二叉搜索树来实现的最优时间复杂度是log2N。
swap就是解决深拷贝效率太低的问题,clear清除所有的节点。
接下来我们来看count
就是找有没有搜索的数字存在,在set里面只返回1或者0.
count的使用相对于find找是否这个数字存在是相对简单的。
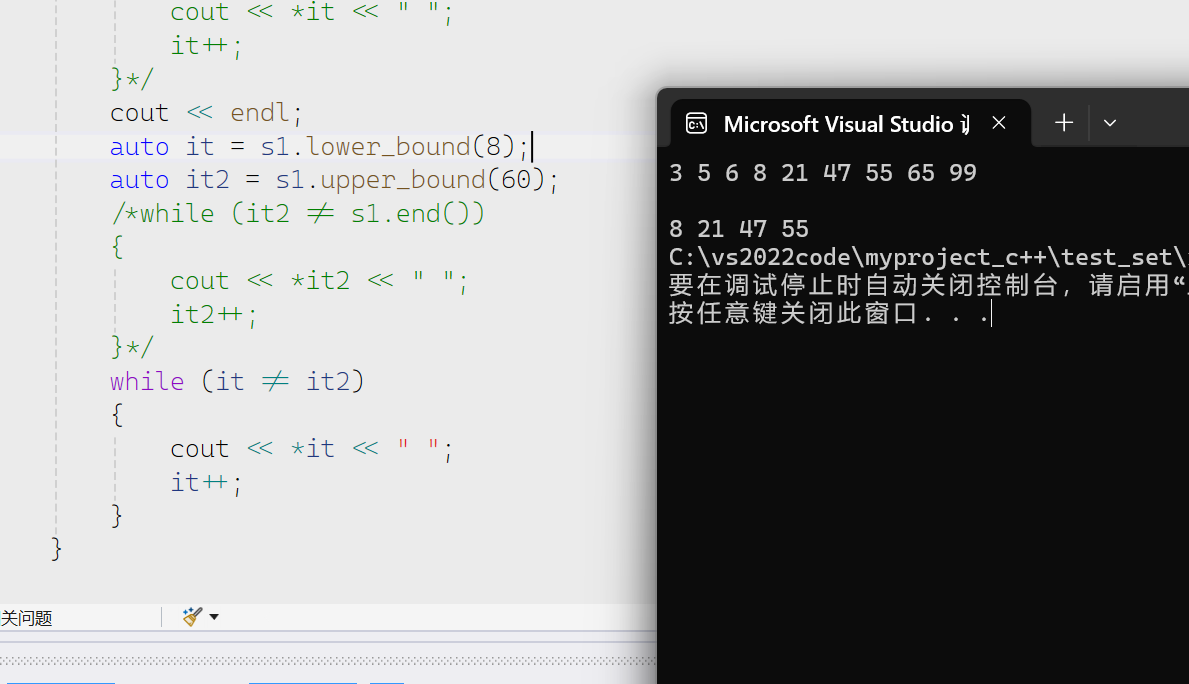
lower_bound与upper_bound
两者都是返回迭代器。前者是返回比传入数值>=的第一个迭代器的位置,后者则是返回比传入值<的第一迭代器








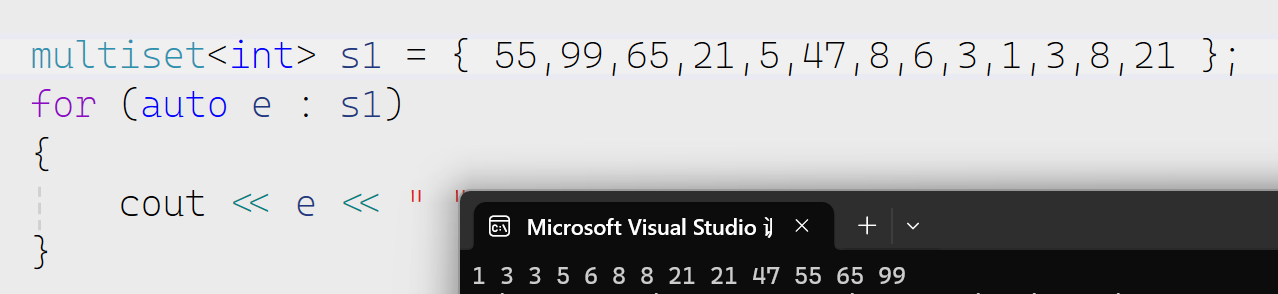
multiset和set的差异
可以看出multiset是支持数据的重复
主要区别点在于multiset支持值冗余,那么insert/find/count/erase都围绕着支持值冗余有所差异。
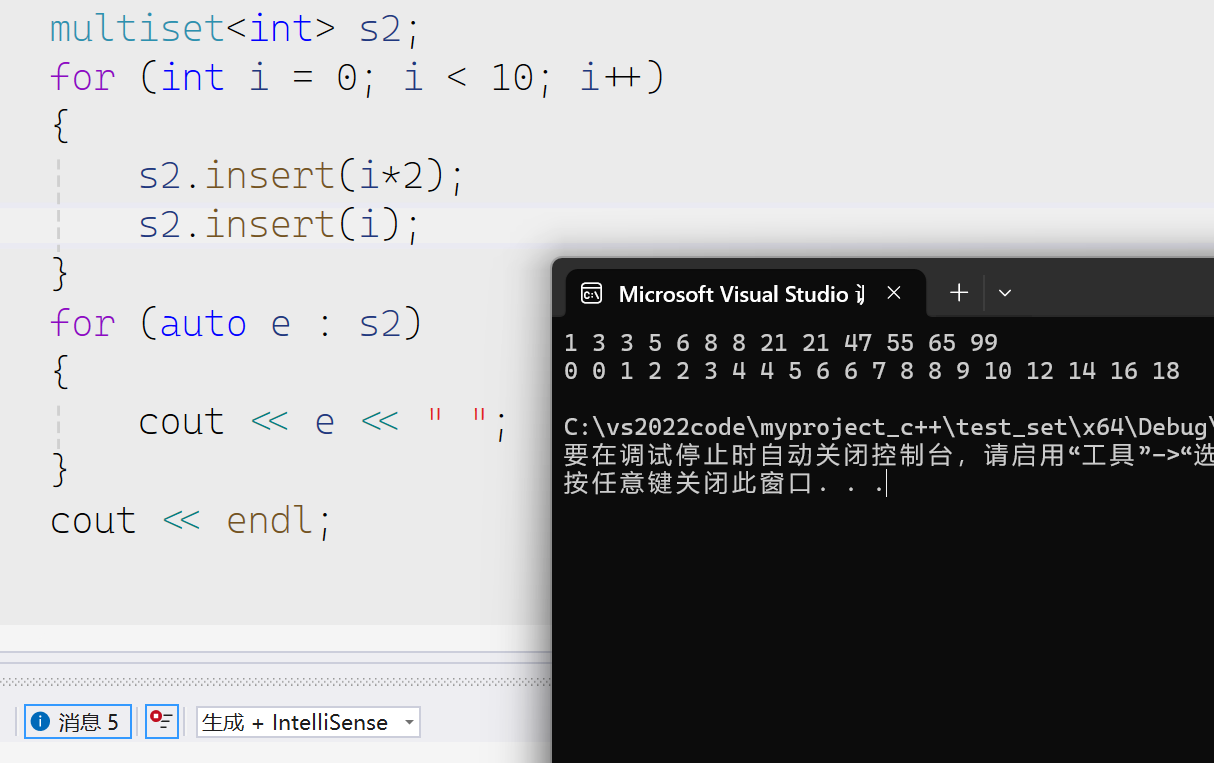
insert
find
返回的迭代器是中序遍历第一次出现相同value的迭代器的位置
count
multiset返回value出现的次数
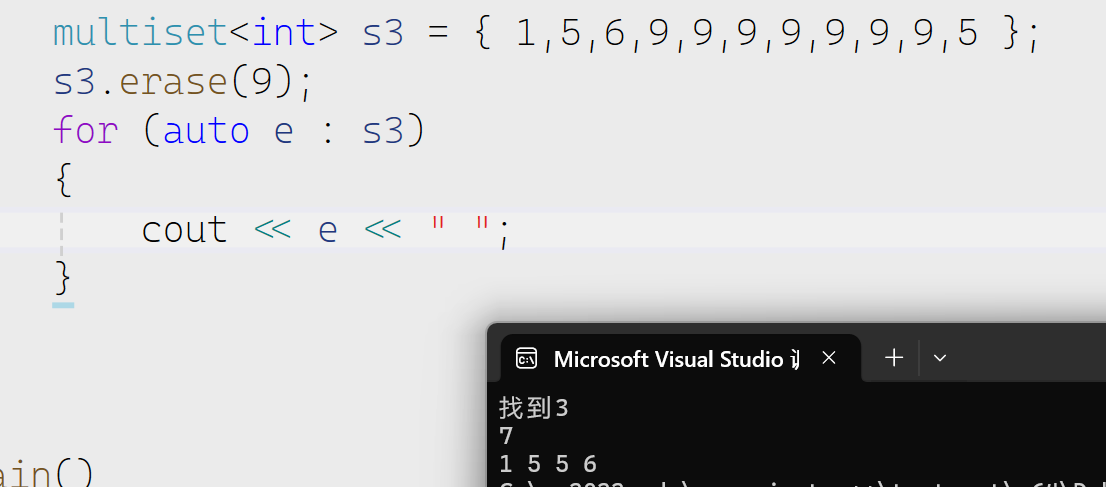
erase
会删除所有与value相同的数


map的使用
Map(映射)是一种关联结构,用来把一组“键(Key)”和对应的“值(Value)”成对存储起来,形成 Key → Value 的对应关系。
可以这样理解:
像一本字典:通过“单词”(Key)快速查到“释义”(Value);
而pair就是来完成这个操作
首先我们来看pair
先来看构造
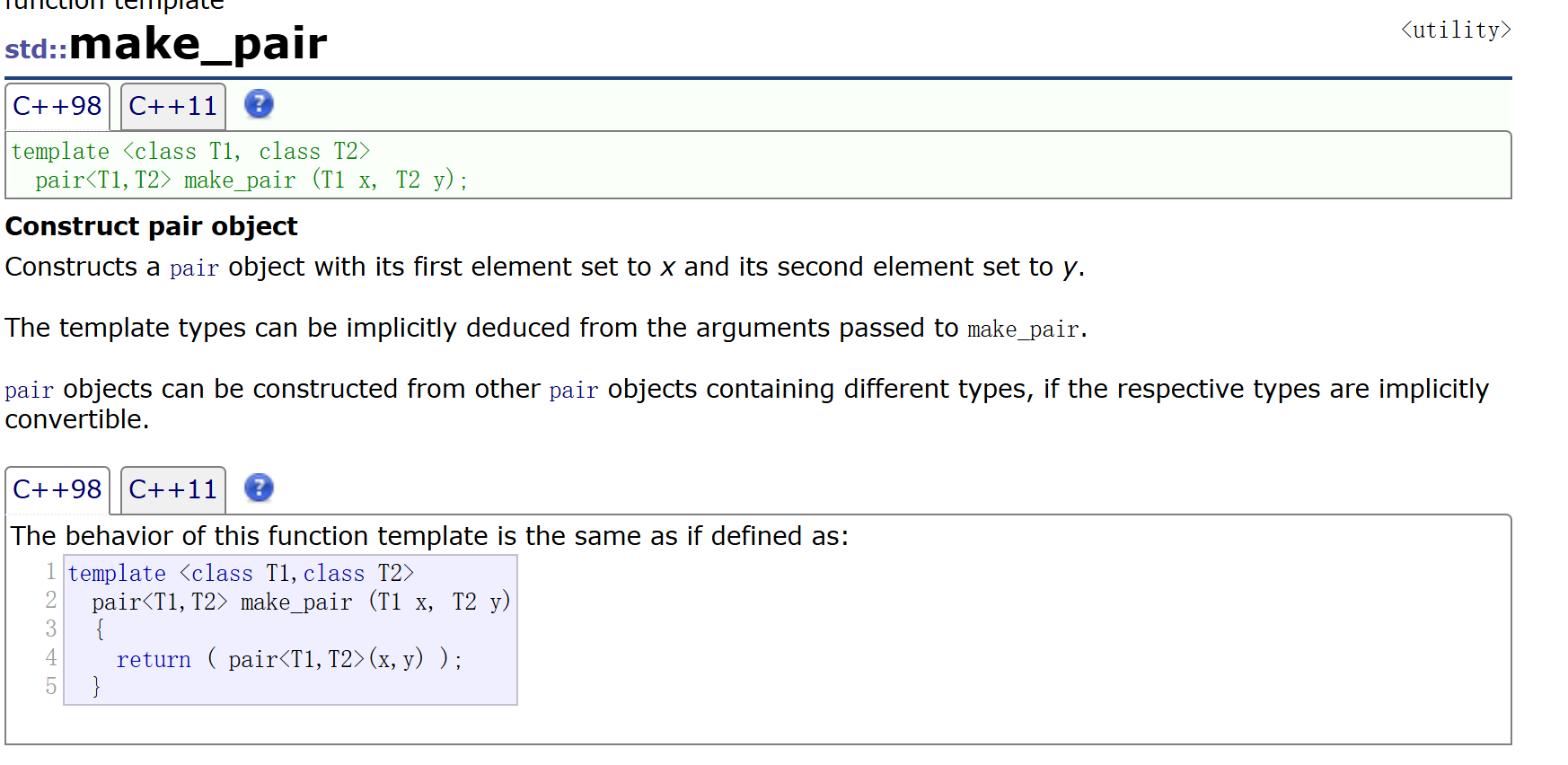
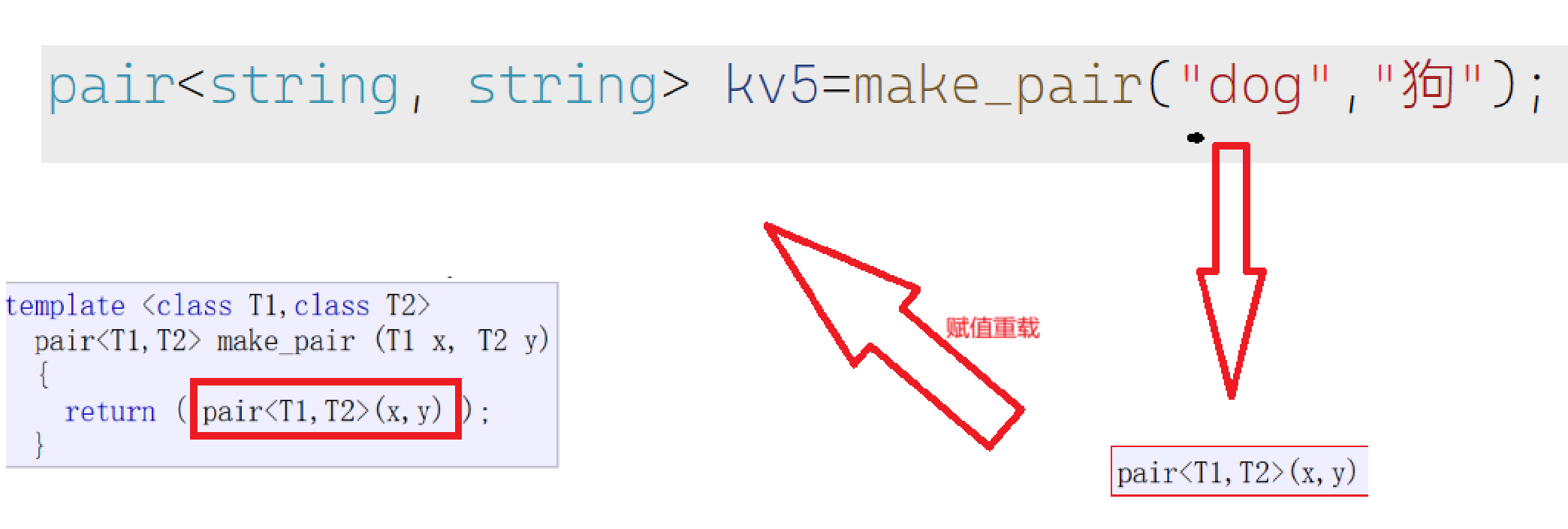
还可以用赋值重载和make_pair
当然也是支持initialize初始化
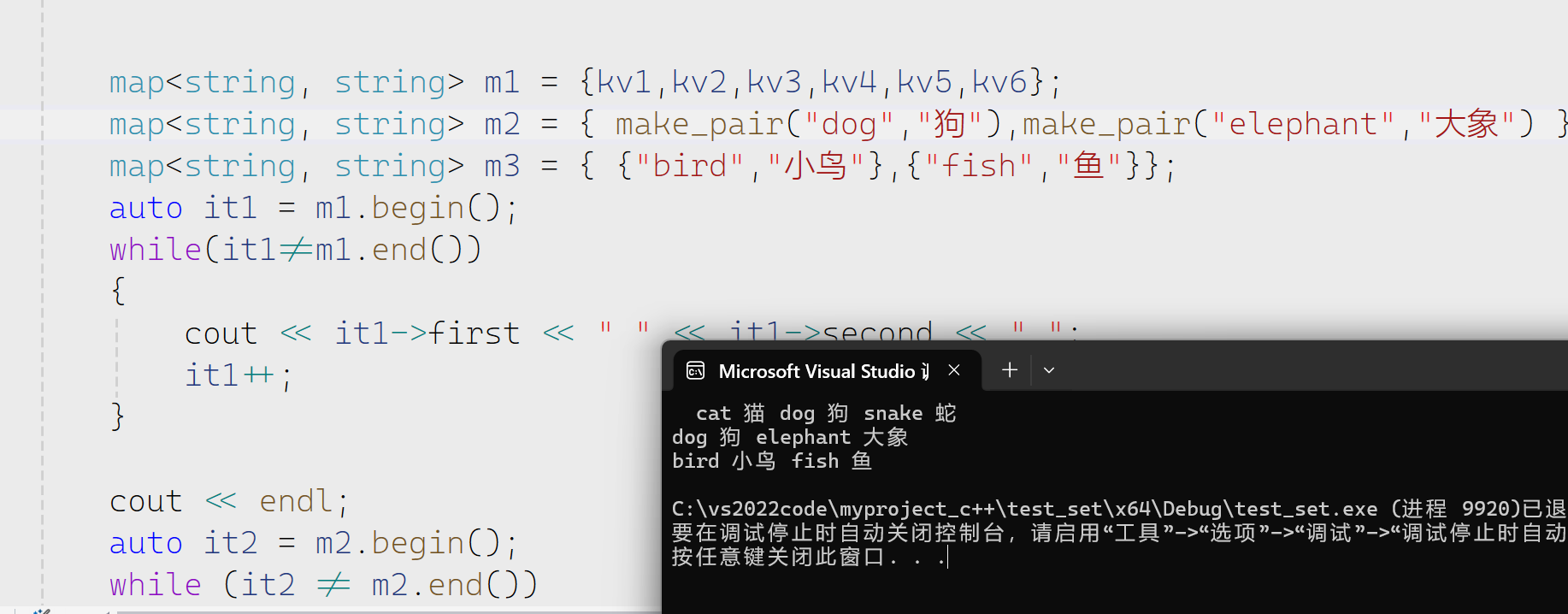
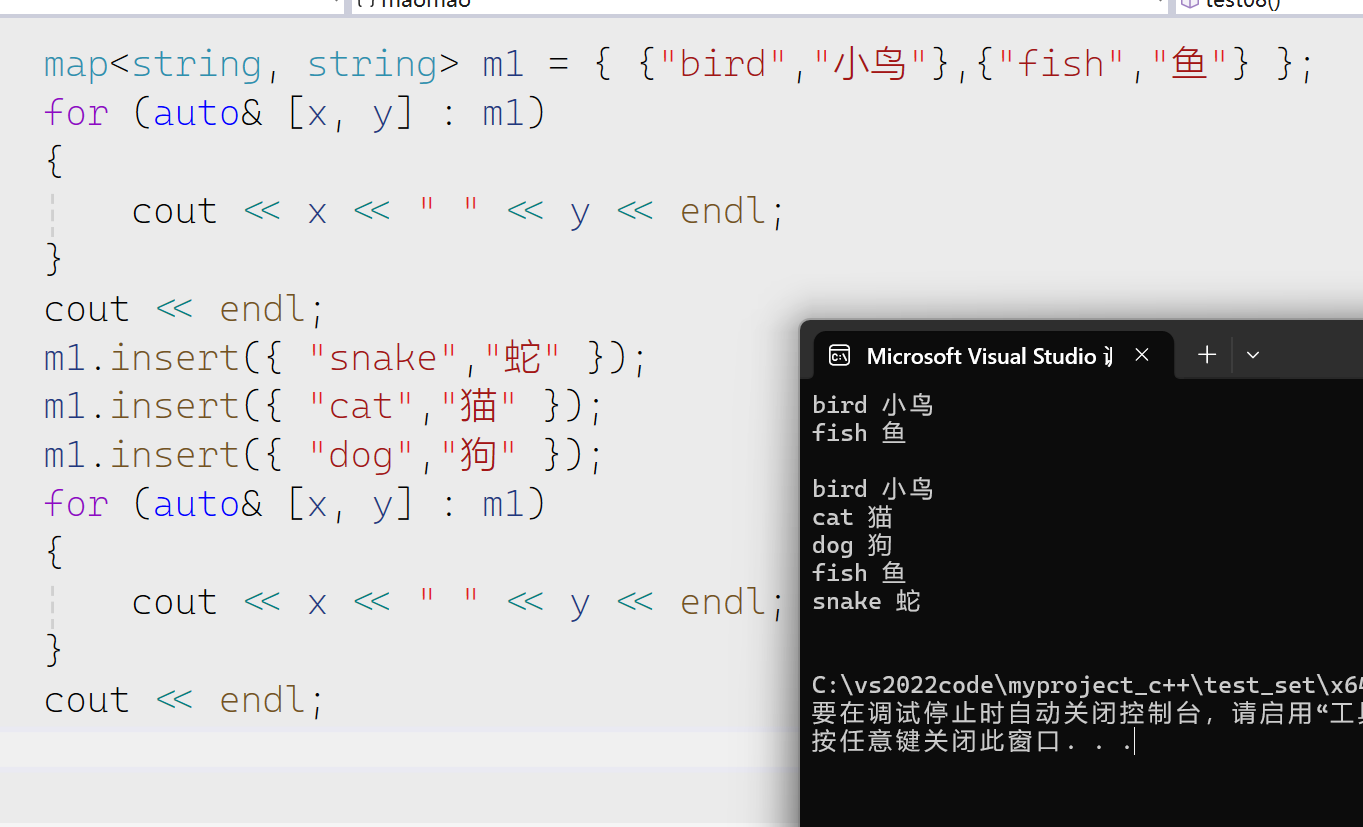
我们将这些运用到map里面
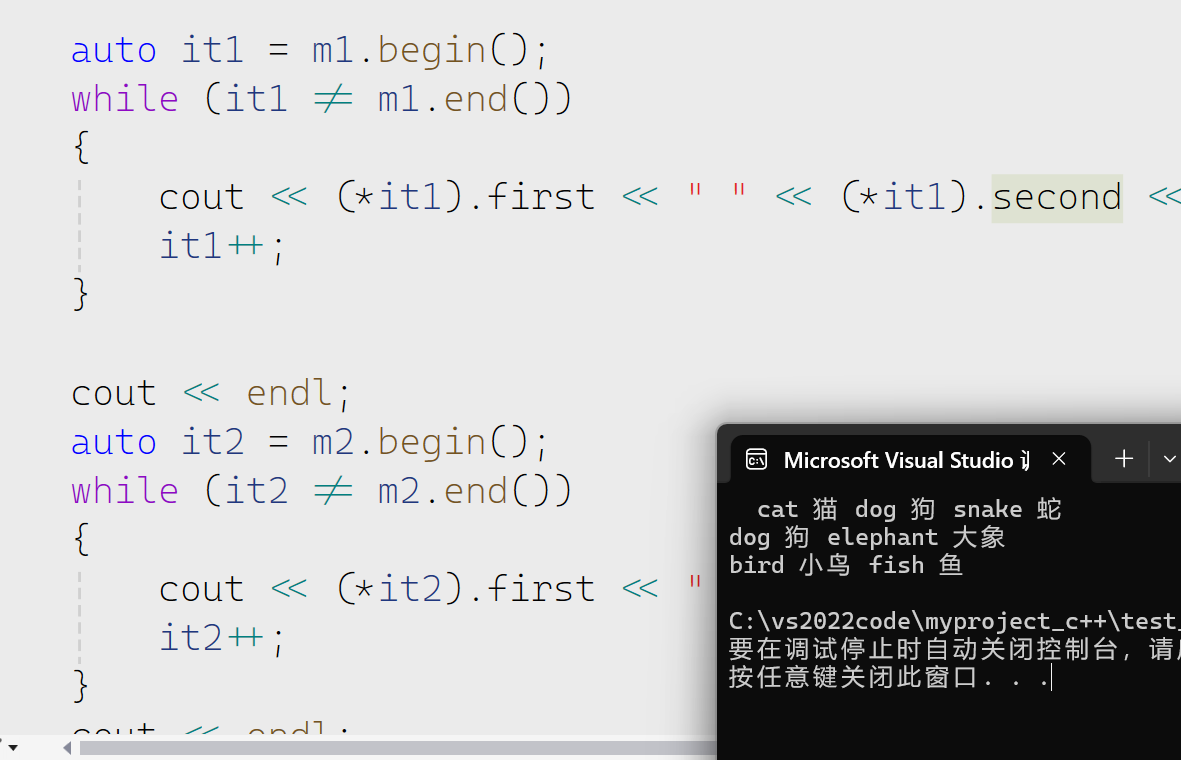
接下来遍历
值得注意的是返回的迭代器解引用是pair的一个整体,我们要访问里面的元素就要用箭头或者是.。我们仔细看也可以看出这个也是有排序的。
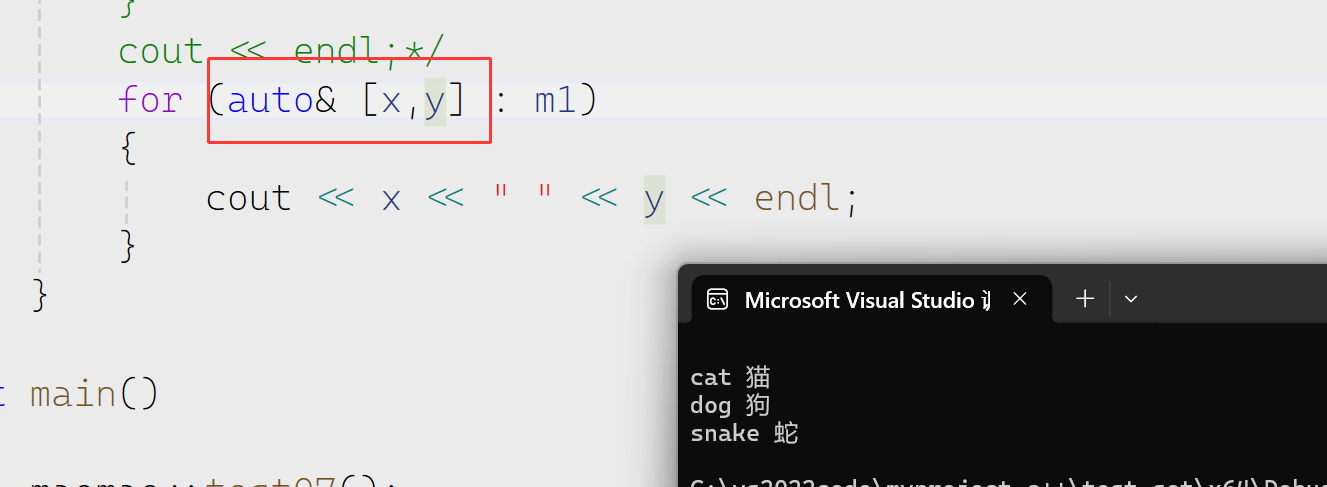
当然除了上面这两种方式我们还可以用结构化绑定
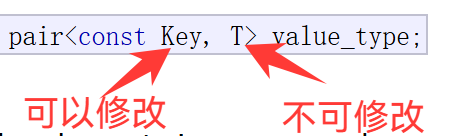
注意map这里key可以修改,T不能修改
insert
直接insert一个pair对象
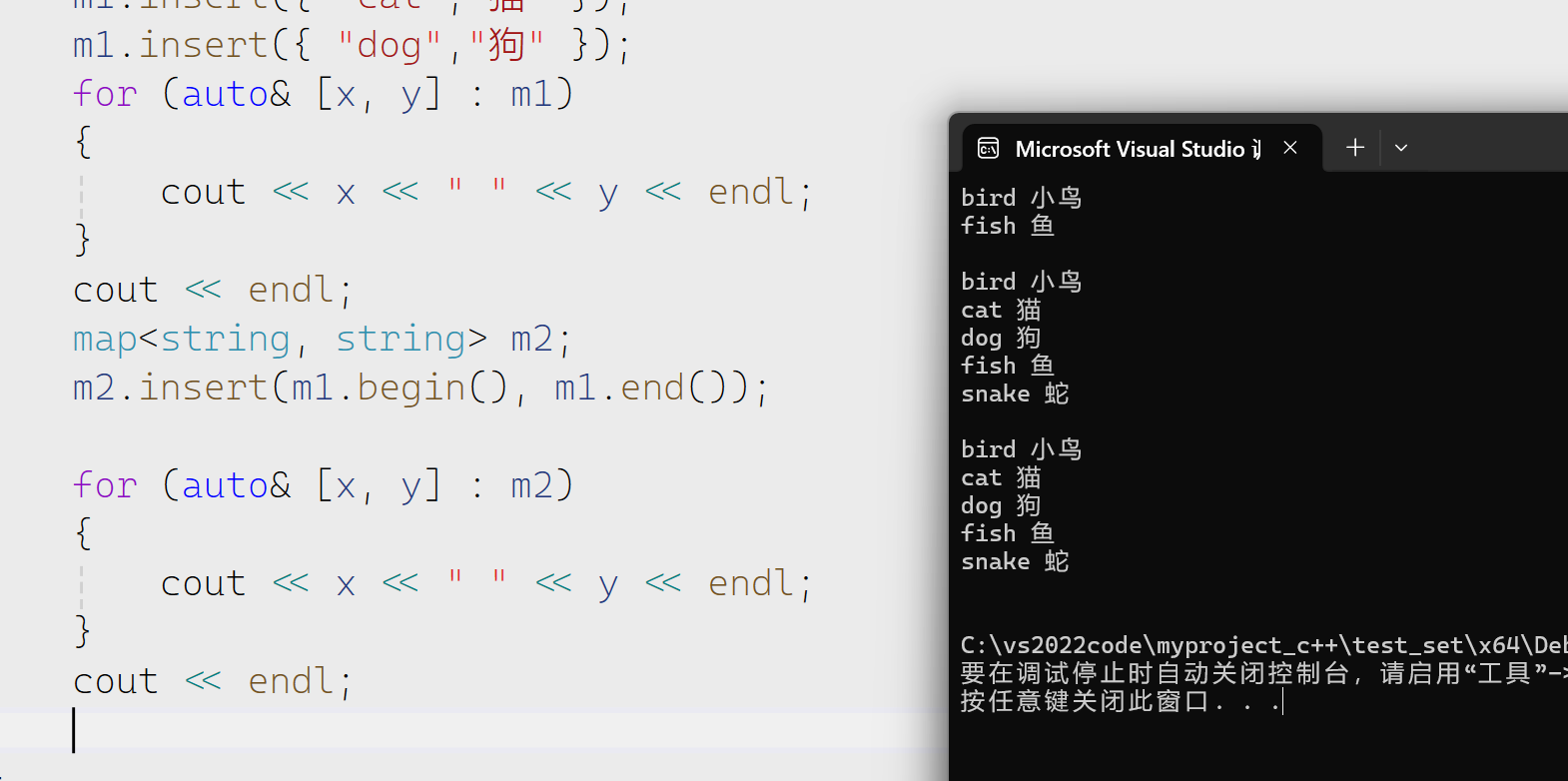
传入迭代器区间
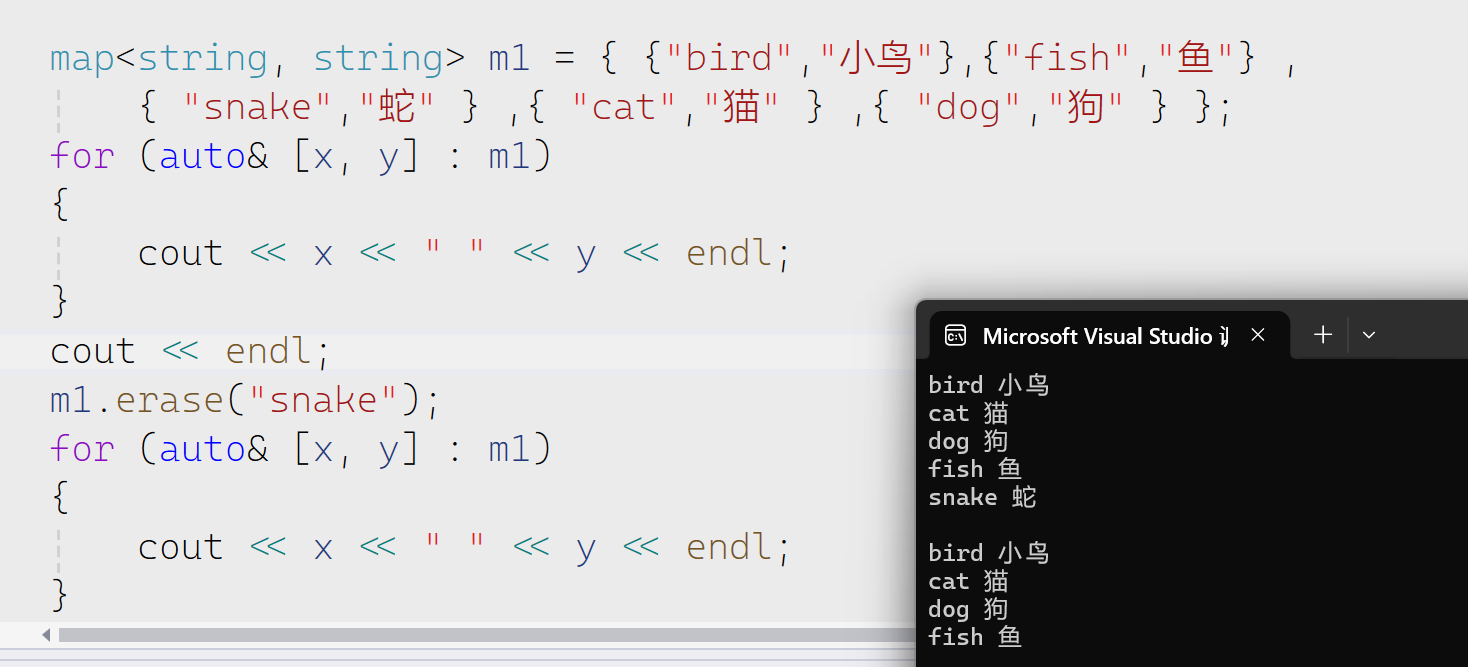
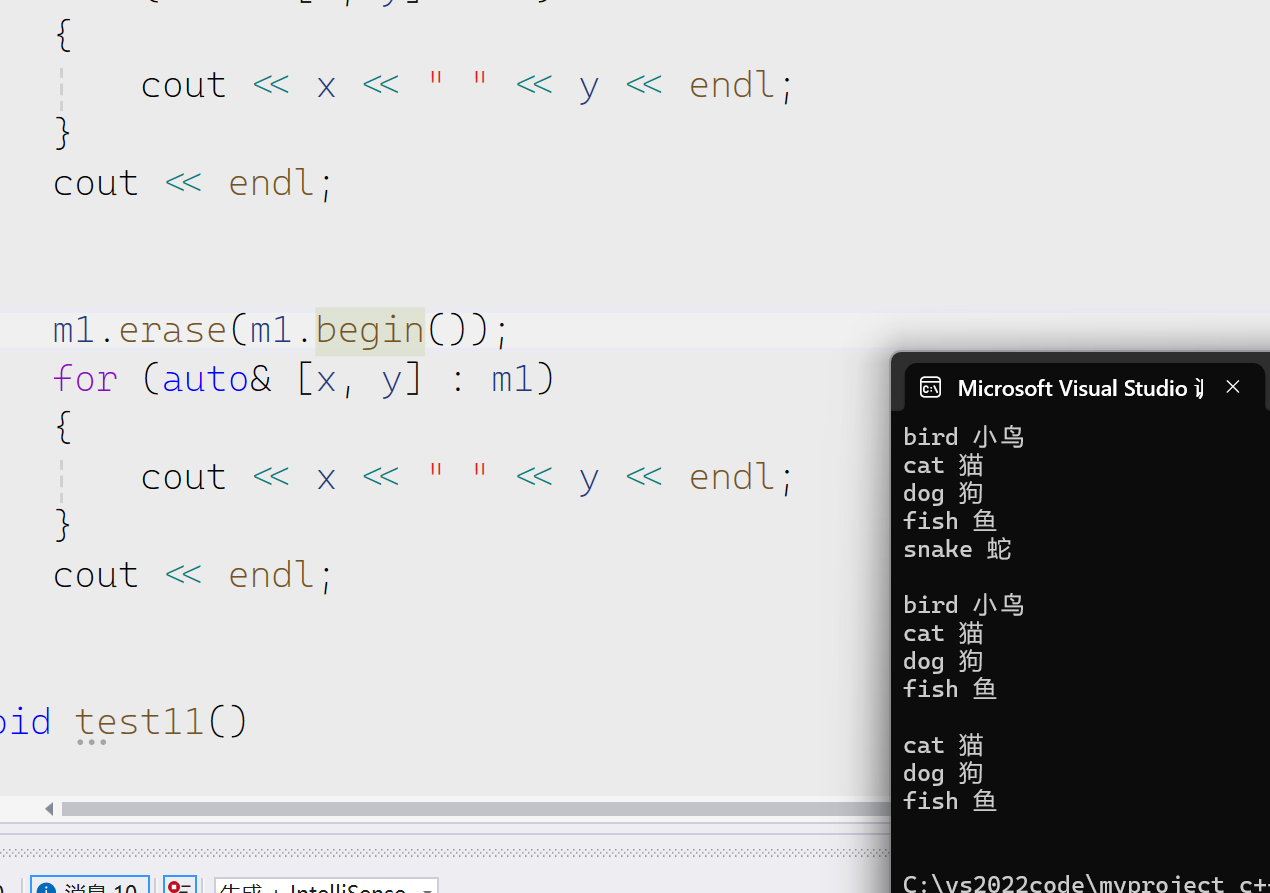
erase
可以删除一个迭代器位置的值,一个迭代器区间,或者是一个pair里面的第一个first。
find
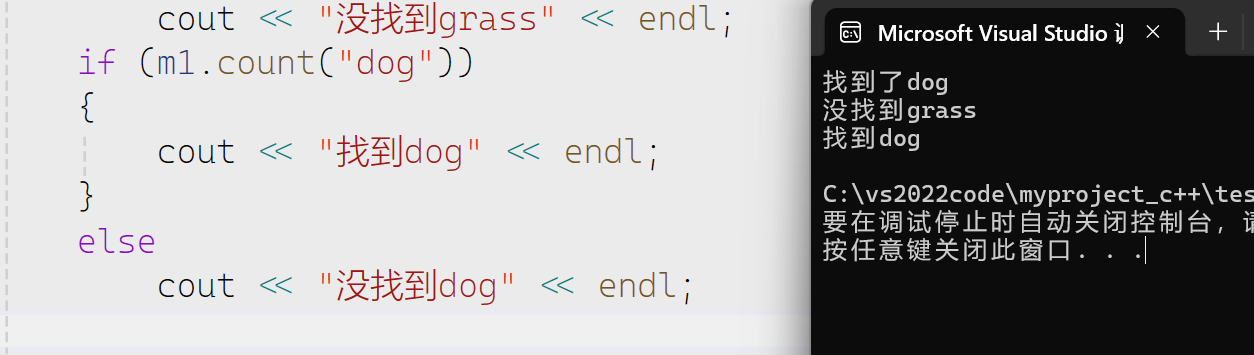
count
和set里面的count是相类似的,map的count也是只能返回1或者0.








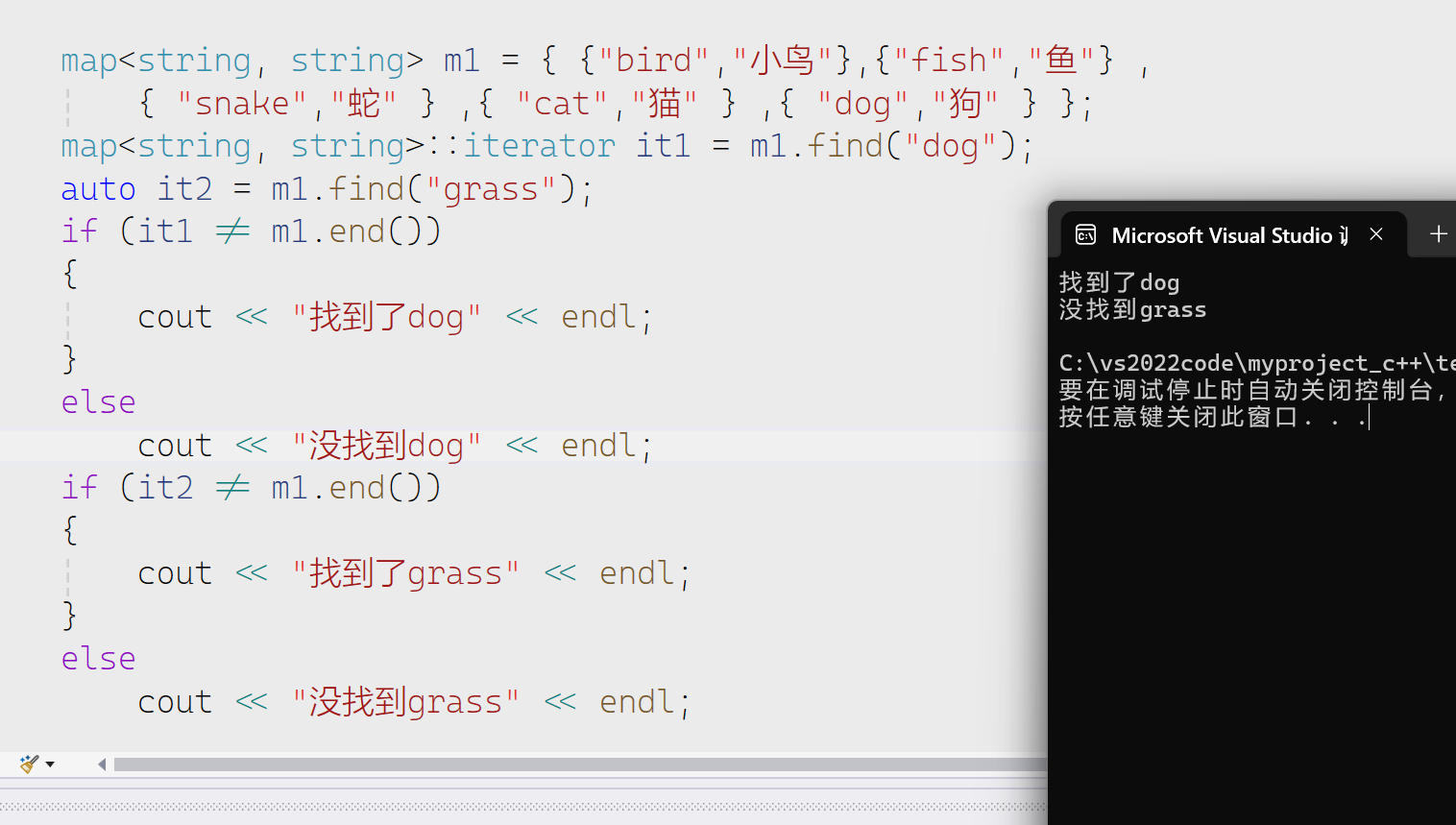

接下来我们先来看一个例子来理解operater[]
通过这样我们可以很简单的统计出水果的个数。
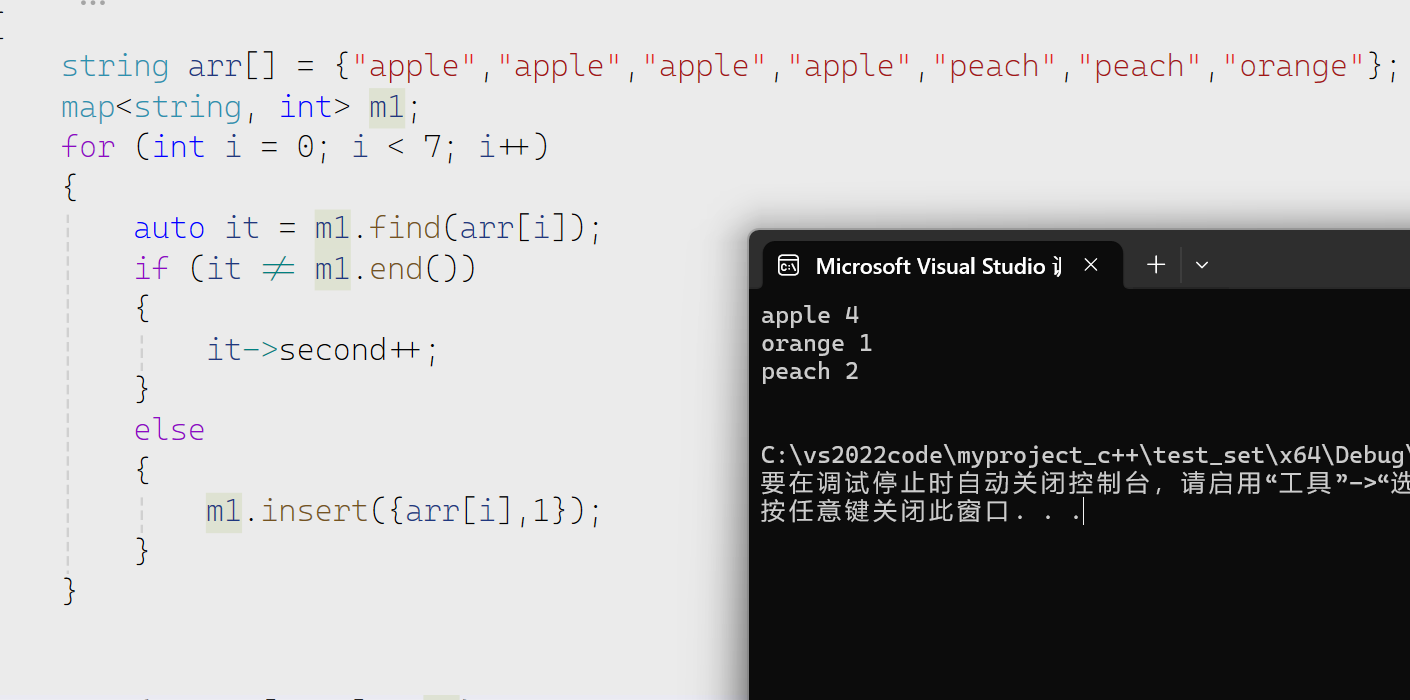
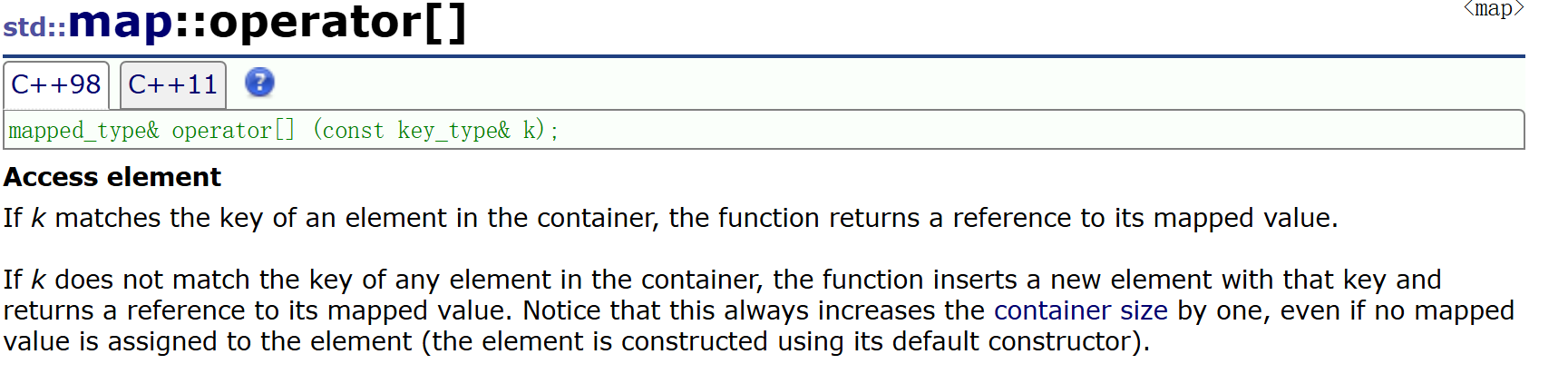
operator[]可以更简单的来实现
pair<key,value>
如果key存在就返回value
如果key不存在就先插入key然后返回value
然后我们看这个进一步理解这个到底是怎么做到的
所以[]也可以实现上面的操作而且更加简单。


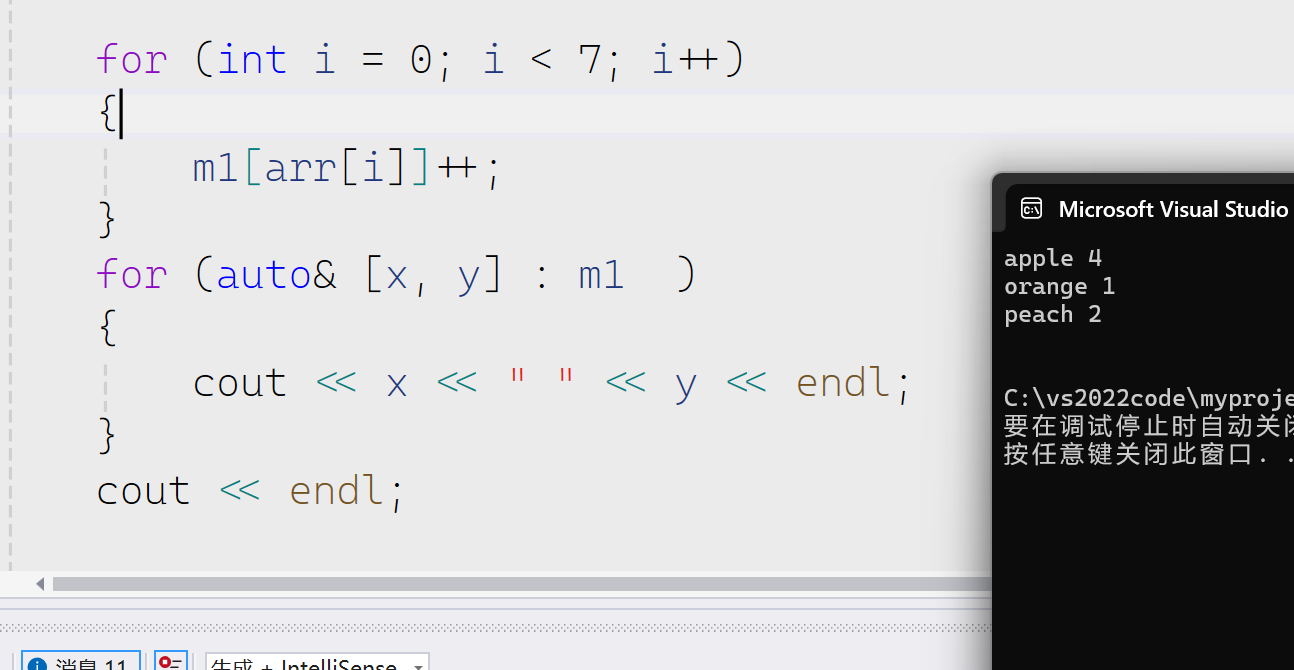

当然除了上面这一种还可以进行其他的操作
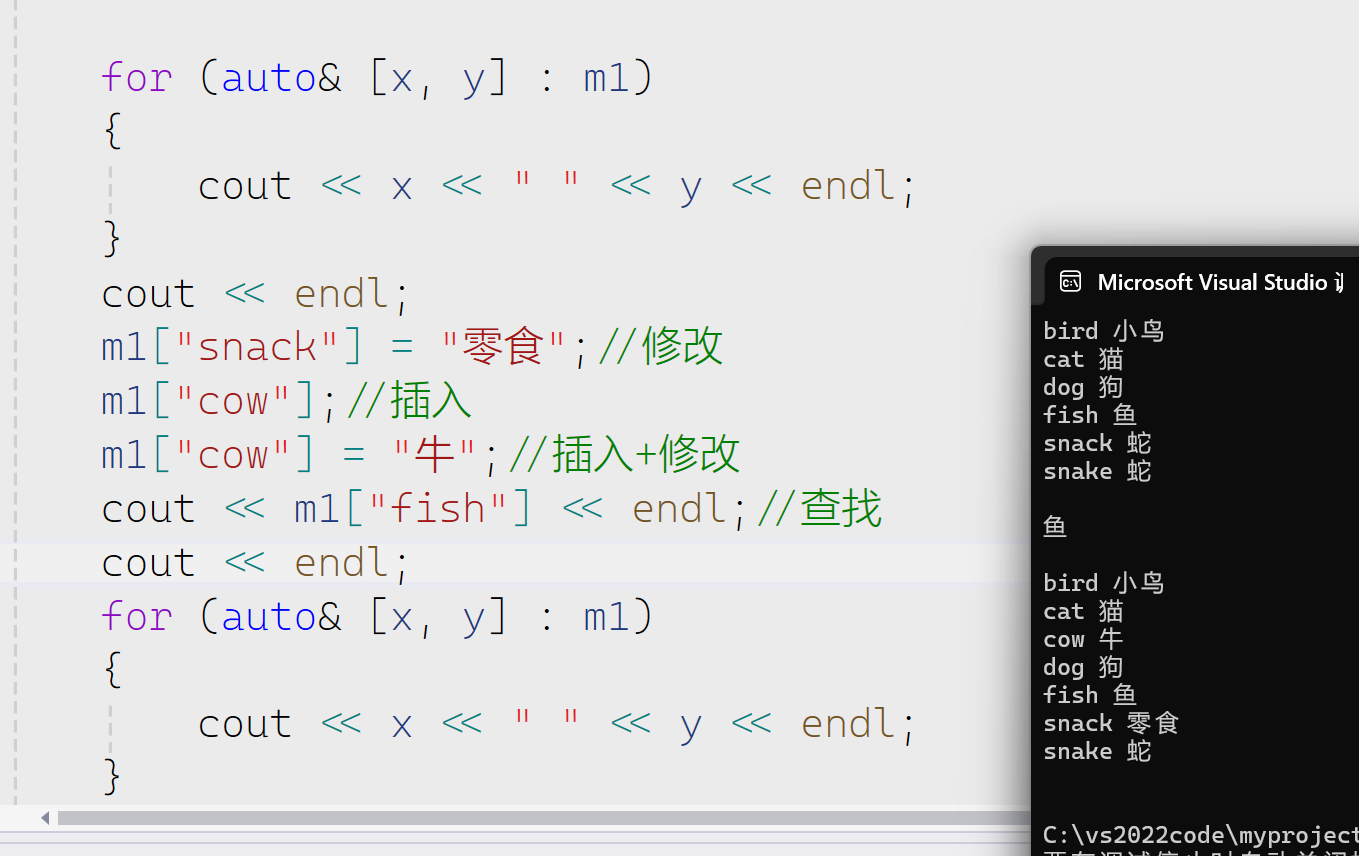
接下来我们来看multimap
multimap与map和multiset与set关系是类似的。
multimap允许key相同的值插入,不相同的也插入。
find,insert,erase,count
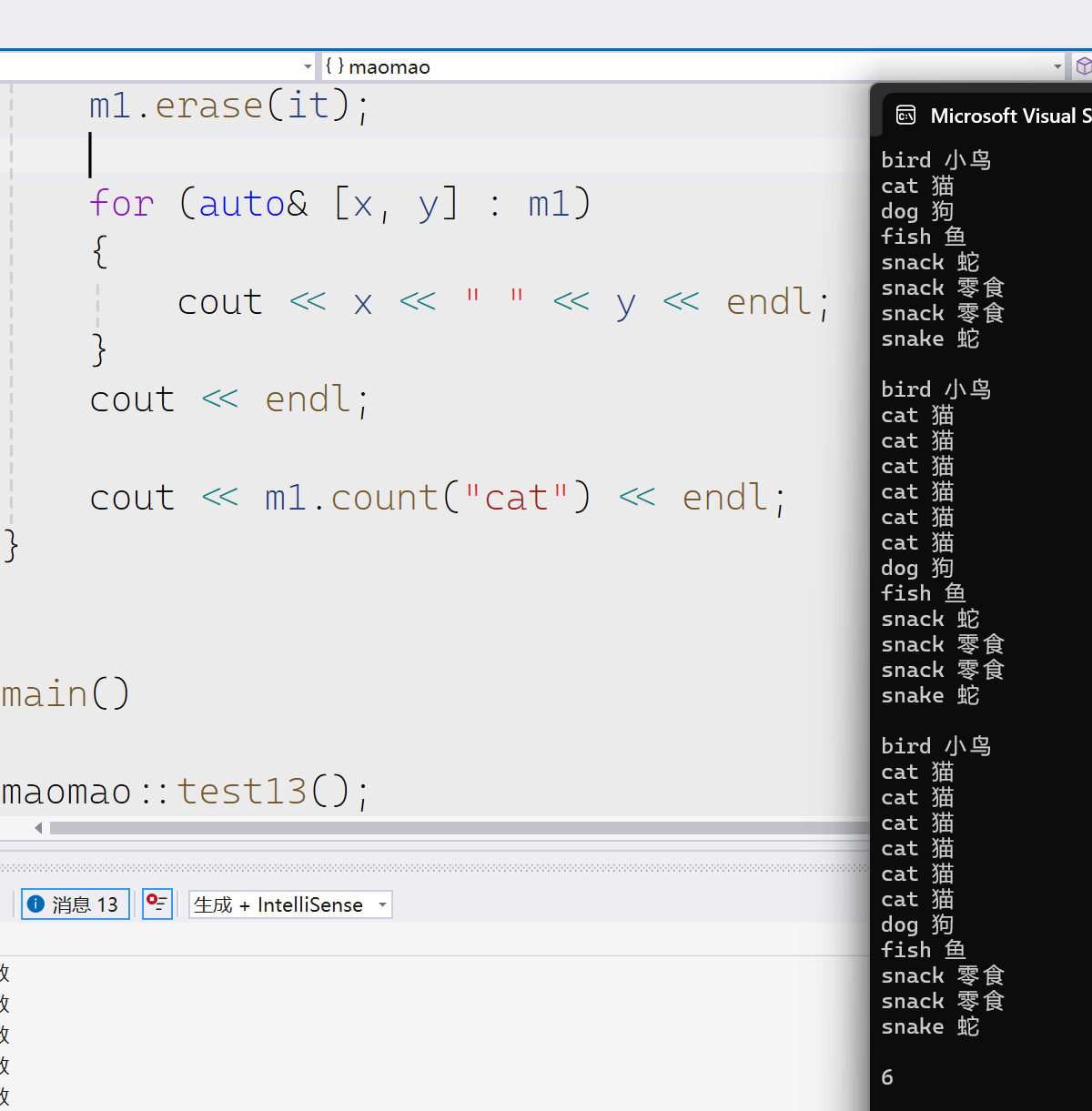
void test13() { multimap<string, string> m1 = { {"bird","小鸟"},{"fish","鱼"} , { "snake","蛇" } ,{ "cat","猫" } ,{ "dog","狗" } , { "snack","蛇" } ,{ "snack","零食" } ,{ "snack","零食" } }; for (auto& [x, y] : m1) { cout << x << " " << y << endl; } cout << endl; for (int i = 0; i < 5; i++) { m1.insert({ "cat","猫" }); } for (auto& [x, y] : m1) { cout << x << " " << y << endl; } cout << endl; auto it = m1.find("snack"); m1.erase(it); for (auto& [x, y] : m1) { cout << x << " " << y << endl; } cout << endl; cout << m1.count("cat") << endl; }

更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)