
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (5)--- 异步处理
概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
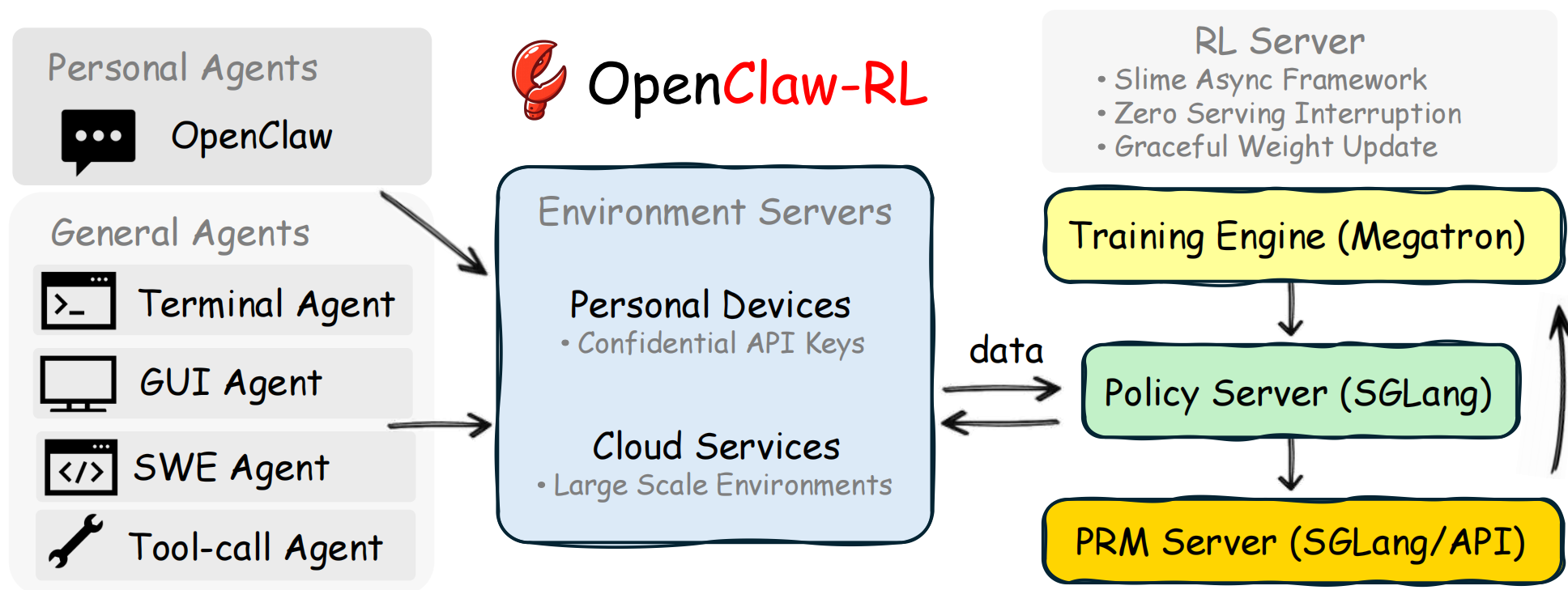
0x01 异步架构
OpenClaw-RL 的系统设计是四个异步解耦的循环——policy serving、environment hosting、reward judging、policy training 同时运行、互不阻塞,因此模型可以一边持续服务,一边从刚刚发生的真实交互中在线学习。
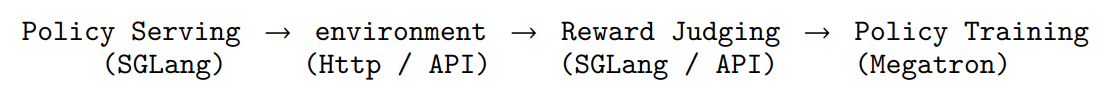
这四个组件以零协调开销异步运行:模型服务用户请求的同时,PRM正在评判上一轮交互,训练器同步更新策略------ 三者互不等待。这一设计使得从实时、异构的交互流中进行连续训练成为可行,无需任何流被暂停或批处理来配合其他组件。
在这种模块化设计中,各组件既保持功能独立性又实现数据互通。即,其总体是异步进行的,具体如下:
时间轴 (完全异步, 各组件不相互阻塞):
----------------------------- Policy Serving ---------------------------------
SGLang: 服务用户 ─────────────────── 暂停(503) ─ 加载新权重 ─ 服务用户 ──►
Proxy: 采集数据 ─────────────────── 暂停 ─────── 恢复 ───── 采集数据 ──►
----------------------------- Reward Judging ---------------------------------
PRM: 评分 ───── 评分 ───── 评分 ─────────────────────── 评分 ───── 评分 ──►
----------------------------- Policy Training---------------------------------
Megatron: ─ 等待数据 ───────────── 训练 ─ 同步 ─ 等待数据 ─── 训练 ─────────►
系统通过完全异步的设计实现四大核心优势:
- 服务连续性保障:策略服务与训练过程解耦,确保7×24小时无中断服务。通过双缓冲机制实现模型热切换,权重更新期间仍可维持原有策略响应。
- 实时学习能力:环境反馈与评估结果通过消息队列实时传输,训练模块可立即消化最新交互数据。系统支持每秒百次级的模型参数更新,实现真正意义上的在线学习。
- 长周期任务处理:针对软件工程等复杂任务,采用异步环境管理策略。不同任务轨迹可独立推进,通过工作流引擎协调依赖关系,有效缓解长尾延迟问题。
- 个性化适应机制:通过会话感知技术区分训练轮次与转发轮次,在保证用户体验的同时积累个性化数据。系统动态调整探索-利用平衡参数,实现用户偏好与模型能力的协同进化。
0x02 训推分离
因为异步架构和训推分离是一体两面,所以我们先介绍训推分离。
同步RL的理想情形(无漂移)是on-policy,即:
时刻 t:
1. rollout:使用π_t生成N条样本
2. update: 用这N条样本更新 → 得到π_{t+1}
3. rollout:使用π_{t+1}生成下一批...
即,Policy π_θ → 生成轨迹 → 立刻更新T_θ → 重复
每批训练数据100%来自当前policy → 完全on-policy,即生成数据时的 policy = 更新时的 policy = on-policy → 理论保证:importance weight = 1,无需修正。
ratio = π_{t+1}(a|s)/π_t(a|s) = 1(刚更新一步,变化很小)
然而,实际上这是理想情况。
2.1 为什么训练和推理通常分离?
2.1.1 内存布局根本冲突
训练和推理同时在同一块 GPU 上高效运行,物理上就冲突——KV cache 和优化器状态争同一显存。
| 训练引擎(FSDP/Megatron) | 推理引擎(vLLM/SGLang) |
|---|---|
| 显存用途:参数 + 梯度 + 优化器状态(约 4x 参数大小) | KV Cache(约 2x 参数大小) |
| 分片方式:ZeRO 参数分片(跨 GPU 不连续) | 每卡完整参数(连续 + 量化) |
| Attention:PyTorch Flash Attention | PagedAttention |
| 批处理:固定 batch(padding 对齐) | Continuous batching(动态) |
由于前向传播占用的显存小于反向传播,所以一般一个 step会首先 rollout 大量的轨迹,然后分批次进行梯度优化。
2.1.2 计算特性完全相反
- 训练:计算密集(矩阵乘法,GPU利用率高),延迟不敏感
- 推理:内存带宽密集(每token读权重),延迟极敏感
混合运行会让两者都变慢。
2.1.3 RL特有的权重同步问题
推理(rollout) → 收集数据 → 训练(更新权重) → 推理用新权重 → ...
如果训练和推理在同一进程,参数更新期间无法同时做推理。虽然可以用xccl广播把新权重从Megatron传到 SGLang,但是,这本身就是跨引擎同步,不是同框架内的操作。
比如:
GPU 0-3(Megatron)更新后 → 同步到GPU 4-5(SGLang)
同步期间(几十秒到几分钟): → 在途的rollout用的是旧weights → 同步完成前所有新对话都是off-policy
2.1.4 工程复杂度爆炸
维护一个同时优化 FlashAttention、PagedAttention、ZeRO-3、梯度 checkpoint 的框架,代码复杂度是各自独立的 5-10 倍。因此,主要框架选择了各自专精:
| 框架 | 策略 |
|---|---|
| OpenRLHF | 彻底分离:Actor(vLLM) + Trainer(DeepSpeed) |
| VeRL | "混合引擎"(同卡串行切换,不是真并行) |
| AReaL | 异步解耦:SGLang 推理 + FSDP 训练,用 xccl 同步权重 |
| TRL | 简单 PPO,训练和推理共用 HF 权重(效率最低) |
2.1.5 小结
因此,在第 2 个批次及以后,所优化的轨迹都不是那个 model 自己生成的,而是上一个 step 的 model 生成的,这就引入了 off-policy。另外,在 partial rollout 中,一条轨迹可能来自不同的 model,就更加加剧了这个问题。
2.2 Agentic RL的三个分布
在Agentic RL中,有三个分布:
π_rollout:采样时的策略分布(策略模型产生训练数据的policy)π_learner:更新时见到的样本分布(learner实际梯度计算用的数据)π_deploy:最终部署时系统实际执行的策略分布(真实环境下policy的行为)
一致的理想情形:完全on-policy + 训练分布 = 部署分布。然而,这三个分布几乎不可能天然一致。
三层分歧的汇总如下:
生成数据 处理数据 真实服务
π_rollout ────► π_learner ────► π_deploy
↑ ↑ ↑
异步更新Gap Filter + Buffer Gap 探索/利用+分布漂移Gap
k步policy差异 训练分布被人为塑造 用户分布随时间变化
PPO clip约束 ?(通常无显式约束) 通常完全不处理
以下,我们会结合OpenClaw-RL 逐层分析为何这几乎不可能。
2.2.1 第一层分歧
第一层分歧:π_rollout ≠ π_learner(Off-Policy Gap)
原因A:异步更新(权重同步延迟)
时刻t: rollout生成样本(s_0,a_0,...,s_T)使用`π_θ_t`
时刻t+k:learner处理这批样本,更新π_θ_{t+k}
π_θ_{t+k} ≠ π_θ_t(中间已经k步更新了)
importance ratio = π_{t+k}(a|s)/π_t(a|s) ≠ 1
在单轮RL里:
- k很小(一次更新周期)。
在Agentic RL里:
- 一个episode跑T=20步,在此期间其他worker可能更新了policy
- step 1的数据用的是
π_t,step 20的数据已经是π_{t+20}的环境下生成的
比如(Weight Sync 窗口):
-
权重同步期间(503 阻断了新的 rollout): → 但已在队列里的样本是同步之前生成的
-
同步完成后(SGLang 有了新的权重):
→ learner 还在处理同步前的旧样本 → 旧样本的 rollout_log_probs 来自"旧权重的 SGLang"
→ 当前 policy 是"新权重的 Megatron" → ratio 在 weight sync 边界处跳跃
ratio 时间线(示意):
-------------------------[weight sync]-------------------
ratio: 1.0, 1.1, 0.9, 1.2, ... | 1.8, 1.5, 2.1, ...
↑ sync 后 ratio 突然变大
原因B:队列/Buffer的时间延迟
OpenClaw具体情况:
- 轮次N的response进入queue → 等待PRM打分(异步)
- 在此期间,其他样本继续训练 → policy继续更新
- PRM打完分,样本进入训练 → 这时policy已经是
π_{N+k} - policy用
π_{N+k}在π_N生成的数据上更新 → off-policy
即,系统架构决定了异步性:
rollout worker ────► buffer/queue ────► learner
(连续产生数据) (样本等待处理) (继续更新policy)
样本在buffer里等待期间:
- learner继续更新policy
- policy从
π_t变成了π_{t+k}
当样本被learner取出时:
- 样本的log_prob是
π_t计算的 - gradient更新的是
π_{t+k} ratio=π_{t+k}(a|s)/π_t(a|s)← 不再 ≈ 1
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)