
XML格式详解与PDF转XML技术方案:从数据交换标准到Python批量转换
【摘要】本文从数据交换标准的角度解析XML格式的定义、结构特征及其在国家电子发票标准(GB/T 39043)中的应用。技术方案部分涵盖:基于XSL-FO的声明式转换、Python生态(xml.etree + reportlab + pdfplumber)的程序化转换、以及OCR辅助的扫描件转换流程。附完整的Python代码示例和命令行工具链速查表,适合需要系统了解XML及其在财务自动化中应用的开发者和技术管理者。
在国家电子发票标准(GB/T 39043-2020)全面推行的背景下,XML作为电子发票的标准数据格式,其与PDF之间的格式转换成为财务系统对接中的关键环节。本文从技术角度系统阐述XML的数据模型和PDF-to-XML的多种转换方案。
XML数据交换标准概述
XML(eXtensible Markup Language,W3C Recommendation)的核心特性是自描述性(Self-describing)和平台无关性。其数据模型基于树形结构(DOM),每个节点由标签(Tag)、属性(Attribute)和文本内容(Text Content)组成。
XML Schema Definition(XSD)是XML的类型系统:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="发票">
<xs:complexType>
<xs:sequence>
<xs:element name="金额" type="xs:decimal"/>
<xs:element name="税额" type="xs:decimal"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Schema验证确保发票数据类型的正确性——金额必须是decimal而非string,这是PDF格式无法提供的约束。

方案一:XSL-FO声明式转换
技术栈:XSLT(转换) + XSL-FO(格式化) + Apache FOP(渲染引擎)。工作流:XML文档 → XSLT处理器 → XSL-FO中间格式 → FOP → PDF。适合需要精确控制输出排版的企业级场景。

通过命令行调用Apache FOP:
fop -xml input.xml -xsl stylesheet.xsl -pdf output.pdf
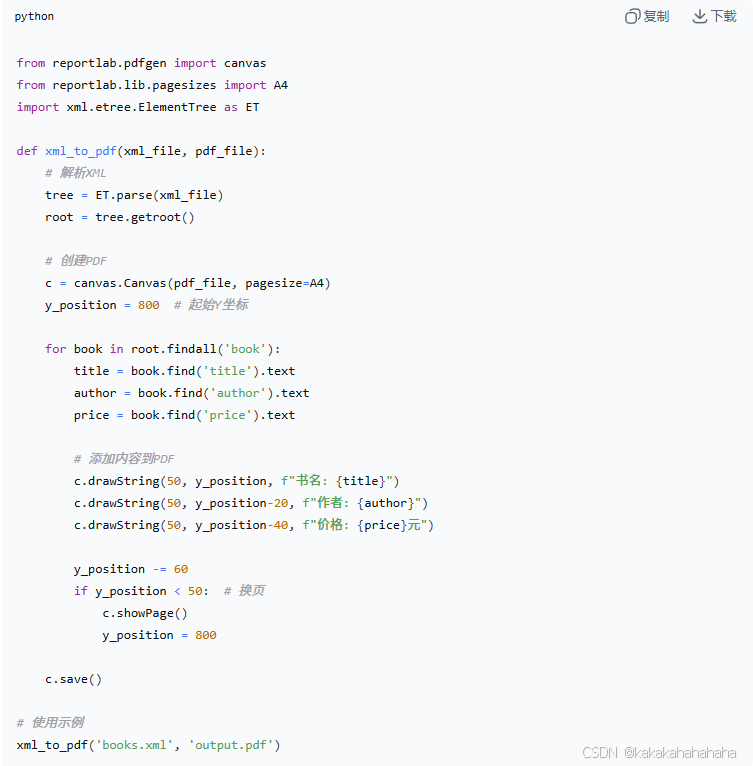
方案二:Python程序化转换
Python生态提供了完整的PDF↔XML转换链路。核心依赖:
pip install reportlab pdfplumber lxml
XML → PDF(使用reportlab):
from xml.etree import ElementTree as ET
from reportlab.pdfgen import canvas
tree = ET.parse("invoice.xml")
root = tree.getroot()
amount = root.find("金额").text
c = canvas.Canvas("output.pdf")
c.drawString(100, 750, f"金额: ¥{amount}")
c.save()
PDF → XML(使用pdfplumber提取文本+自定义标签):
import pdfplumber
with pdfplumber.open("invoice.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()
# 正则匹配提取结构化数据 → 生成XML
方案三:在线转换服务
Convertio等平台提供REST API,适合轻量级集成。通过curl调用:
curl -X POST https://api.convertio.co/convert \
-F "file=@invoice.pdf" \
-F "apikey=YOUR_KEY" \
-F "outputformat=xml"
方案四:OCR辅助扫描件转换
对于扫描版PDF(图片型),需增加OCR预处理环节:PDF → 图片提取 → Tesseract OCR → 文本结构化 → XML生成。
pip install pytesseract pdf2image
tesseract invoice_scan.png output -l chi_sim
命令速查
| 操作 | 命令 |
|------|------|
| XML Schema验证 | xmllint --schema invoice.xsd invoice.xml --noout |
| FOP转换 | fop -xml in.xml -xsl style.xsl -pdf out.pdf |
| Python安装依赖 | pip install reportlab pdfplumber lxml pytesseract |
| OCR提取 | tesseract scan.png output -l chi_sim |
| curl调用在线API | curl -F "file=@invoice.pdf" -F "outputformat=xml" api.convertio.co/convert |
| 验证XML格式 | python -c "import xml.etree.ElementTree as ET; ET.parse("file.xml")" |
PDF到XML的转换技术选型取决于输入PDF的类型(文字型/扫描型)和处理规模(单次/批量)。文字型PDF推荐pdfplumber提取+正则结构化方案,准确率高且无需OCR;扫描型PDF必须引入Tesseract等OCR引擎,但需注意识别率受原始扫描质量影响。对于企业级部署,建议将XSL-FO方案封装为微服务,对外提供RESTful转换接口。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)