
agent开发框架对比
学习笔记,复习用
1、AutoGen :
- 分层设计: 框架被拆分为两个核心模块:用这两个模块来写代码,引入autogen_agentchat这个包来实现快速部署和配置
autogen-core:作为框架的底层基础,封装了与语言模型交互、消息传递等核心功能。它的存在保证了框架的稳定性和未来扩展性。autogen-agentchat:构建于core之上,提供了用于开发对话式智能体应用的高级接口,简化了多智能体应用的开发流程。 这种分层策略使得各组件职责明确,降低了系统的耦合度。
- 异步优先: 新架构全面转向异步编程 (
async/await)。在多智能体协作场景中,网络请求(如调用 LLM API)是主要耗时操作。异步模式允许系统在等待一个智能体响应时处理其他任务,从而避免了线程阻塞,显著提升了并发处理能力和系统资源的利用效率。
使用时,先在环境中导入autogen_agentchat 这个包,然后在项目中引入AssistantAgent 和UserProxyAgent 来进行角色的配置,这两种角色,前者代表执行者,就是进行工作的人,后者代表使用agent的用户来进行提出要求,使用等。
当任务需要多个智能体协作时,就需要一个机制来协调对话流程。在早期版本中,GroupChatManager 承担了这一职责。而在新架构中,引入了更灵活的 Team 或群聊概念,例如 RoundRobinGroupChat
新版的autogen的全新分层架构产物(都是在代码中可以引用使用的子包):
autogen-core ← 地基:消息协议、运行时、Model 接口(只定义"应该长什么样")
autogen-agentchat ← 二楼:AssistantAgent、GroupChat、Swarm 这些你直接用的 API
autogen-ext ← 三楼:具体对接谁(OpenAI?Claude?Ollama?Docker?MCP?)
2、AgentScope :
AgentScope 选择了组合式架构和消息驱动模式。
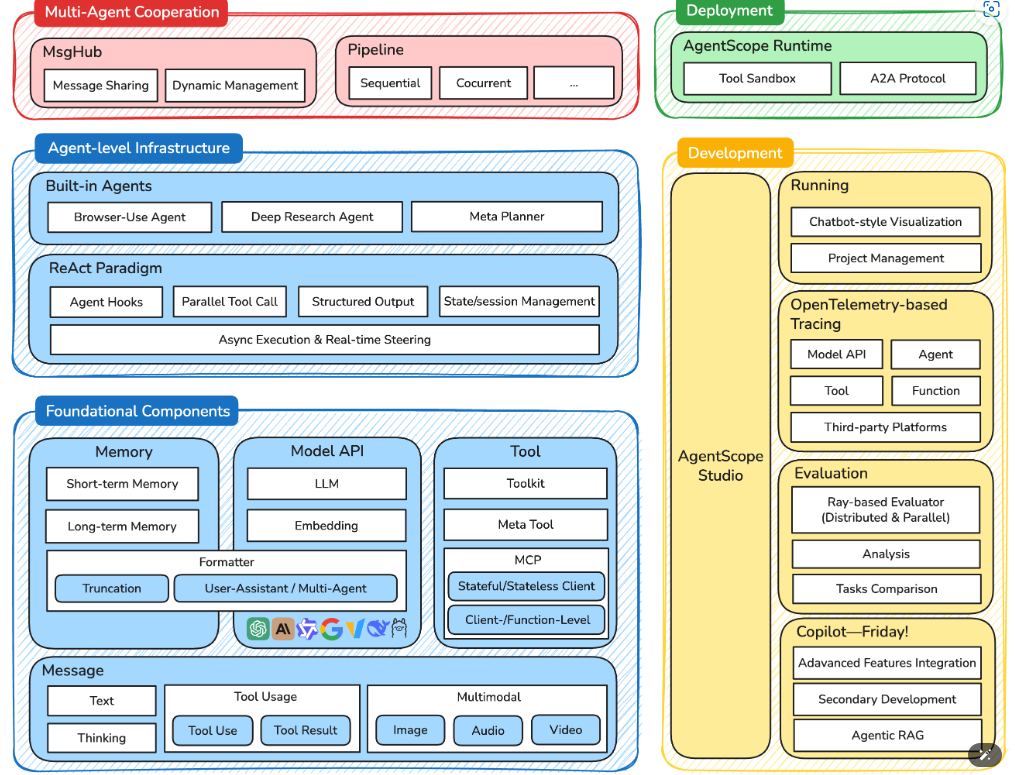
在这个架构中,最底层是基础组件层 (Foundational Components),它为整个框架提供了核心的构建块。Message 组件定义了统一的消息格式,支持从简单的文本交互到复杂的多模态内容;Memory 组件提供了短期和长期记忆管理;Model API 层抽象了对不同大语言模型的调用;而 Tool 组件则封装了智能体与外部世界交互的能力。
在基础组件之上,智能体基础设施层 (Agent-level Infrastructure) 提供了更高级的抽象。这一层不仅包含了各种预构建的智能体(如浏览器使用智能体、深度研究智能体),还实现了经典的 ReAct 范式,支持智能体钩子、并行工具调用、状态管理等高级特性。特别值得注意的是,这一层原生支持异步执行与实时控制,这是 AgentScope 相比其他框架的一个重要优势。
多智能体协作层 (Multi-Agent Cooperation) 是 AgentScope 的核心创新所在。MsgHub 作为消息中心,负责智能体间的消息路由和状态管理;而 Pipeline 系统则提供了灵活的工作流编排能力,支持顺序、并发等多种执行模式。这种设计使得开发者可以轻松构建复杂的多智能体协作场景。
最上层的开发与部署层 (Deployment & Development)则体现了 AgentScope 对工程化的重视。AgentScope Runtime 提供了生产级的运行时环境,而 AgentScope Studio 则为开发者提供了完整的可视化开发工具链。
总体来说:
AgentScope有着很完备的组件配置,包括Tools,memory,模型api,在使用agentscope.model配置大模型后,还可以使用agentscope.agent去指定agent的范式,比如ReAct
我觉得它的最大特点是:1、可以用agentscope.pipeline引入MsgHub,作为“消息中心”,然后每个agent在回答后不是传统的调用下一个agent或者函数,而是发送一个消息在消息中心,然后就可以干别的事,这种异步执行极大减少了agent之间的调用等待时间。(这个相当于java中的消息队列,比如rabbitmq)
当然使用的时候还可以用其他的子包来使用,比如agentscope.formatter使用DashScopeMultiAgentFormatter来实现消息的格式统一,方便特定api的消息识别
3、CAMEL:
CAMEL 实现自主协作的基石是两大核心概念:角色扮演 (Role-Playing) 和 引导性提示 (Inception Prompting)
这个框架比较简单
from camel.models import ModelFactory来连接配置大模型,然后配置
from camel.societies import RolePlaying来汇总指定:model(前一个步骤),不同角色,prompt即可
特点:
CAMEL 通过精心设计的初始提示就能实现高质量的智能体协作。这种自然涌现的协作行为,往往比硬编码的工作流更加灵活和高效。
目前的拓展下,CAMEL已经支持:
- 多模态能力:支持文本、图像、音频等多种模态的智能体协作
- 工具集成:内置了丰富的工具库,包括搜索、计算、代码执行等
- 模型适配:支持 OpenAI、Anthropic、Google、开源模型等多种 LLM 后端
- 生态联动:与 LangChain、CrewAI、AutoGen 等主流框架实现了互操作性
局限:
- 提示设计门槛:需要深入理解目标领域和 LLM 的行为特性
- 调试复杂性:当协作效果不佳时,很难定位是角色定义、任务描述还是交互规则的问题
- 一致性挑战:不同的 LLM 对相同提示的理解可能存在差异
4、LangGraph:
LangGraph 作为 LangChain 生态系统的重要扩展,代表了智能体框架设计的一个全新方向。与前面介绍的基于“对话”的框架(如 AutoGen 和 CAMEL)不同,LangGraph 将智能体的执行流程建模为一种状态机(State Machine),并将其表示为有向图(Directed Graph)。在这种范式中,图的节点(Nodes)代表一个具体的计算步骤(如调用 LLM、执行工具),而边(Edges)则定义了从一个节点到另一个节点的跳转逻辑。这种设计的革命性之处在于它天然支持循环,使得构建能够进行迭代、反思和自我修正的复杂智能体工作流变得前所未有的直观和简单。
三个基本构成要素:
1、全局状态(State)(案例):
class SearchState(TypedDict):
messages: Annotated[list, add_messages]
user_query: str # 用户查询
search_query: str # 优化后的搜索查询
search_results: str # Tavily搜索结果
final_answer: str # 最终答案
step: str # 当前步骤这个state是全局都要用的,每执行一步,会对这个数据进行追加,特别是messages,后面的add_messages就是提醒langGraph,这个message不要覆盖,要追加,其他的变量就是直接填写即可
2、节点(Nodes):
每个节点就像一个函数,在节点中配置信息、调用llm等,最后会在工作流workFlow中挨个添加这些节点(下面是一个节点的例子)
def generate_answer_node(state: SearchState) -> SearchState:
"""步骤3:基于搜索结果生成最终答案"""
# 检查是否有搜索结果
if state["step"] == "search_failed":
# 如果搜索失败,基于LLM知识回答
fallback_prompt = f"""搜索API暂时不可用,请基于您的知识回答用户的问题:
用户问题:{state['user_query']}
请提供一个有用的回答,并说明这是基于已有知识的回答。"""
response = llm.invoke([SystemMessage(content=fallback_prompt)])
return {
"final_answer": response.content,
"step": "completed",
"messages": [AIMessage(content=response.content)]
}
# 基于搜索结果生成答案
answer_prompt = f"""基于以下搜索结果为用户提供完整、准确的答案:
用户问题:{state['user_query']}
搜索结果:
{state['search_results']}
请要求:
1. 综合搜索结果,提供准确、有用的回答
2. 如果是技术问题,提供具体的解决方案或代码
3. 引用重要信息的来源
4. 回答要结构清晰、易于理解
5. 如果搜索结果不够完整,请说明并提供补充建议"""
response = llm.invoke([SystemMessage(content=answer_prompt)])
return {
"final_answer": response.content,
"step": "completed",
"messages": [AIMessage(content=response.content)]
}3、边(Edges):
负责连接节点,定义工作流的方向或者顺序:
边可以在workflow中直接定义顺序:
def create_search_assistant():
workflow = StateGraph(SearchState)
# 添加三个节点
workflow.add_node("understand", understand_query_node)
workflow.add_node("search", tavily_search_node)
workflow.add_node("answer", generate_answer_node)
# 设置线性流程
workflow.add_edge(START, "understand")
workflow.add_edge("understand", "search")
workflow.add_edge("search", "answer")
workflow.add_edge("answer", END)
# 编译图
memory = InMemorySaver()
app = workflow.compile(checkpointer=memory)
return app最后得到一个编译好的可执行工具app,执行spp这个工具即可,执行时,使用workflow.compile.astream()即可,有invoke, ainvoke, stream, astream这几种执行方式
其中,在 LangGraph 里,Checkpointer = 负责给图的状态做"存盘/读盘"的组件。然后指定为memory即可,这个memory是langgraph.checkpoint.memory包下的类,要实例化
使用langGraph:
1、langGraph统一了三种消息:
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
分别是用户问题,ai回答,系统提示词,传递消息时用这几个类实例即可
2、from langchain_openai import ChatOpenAI
提供了openai的统一配置格式,填入数据即可
LangGraph也有一个全局共用的message:SearchState,但是他由于要使用边(edge)来指定运行流程,所以和agentScope有些不同,agentScope的MsgHub也是全局通用的,但是他可以指定多个agent同时回答,所以更像消息队列,而LangGraph如果在边设定时设置一个分支,就是一个节点后同时有多个节点和其相连,那么也能实现这种并行执行的效果。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)