
【转载】如何在不触碰模型权重的情况下超越GRPO
字数 3913,阅读大约需 19 分钟
GRPO需要数万次 rollout 才能收敛。每次 rollout 会产生一条包含推理步骤、工具调用和自我修正的5000 token 完整轨迹,但 GRPO 将这一切压缩成一个标量奖励。
因此,我们最终在一个轨迹只对应一个比特的信息上反向传播,而丢弃了数千比特的结构化信号。
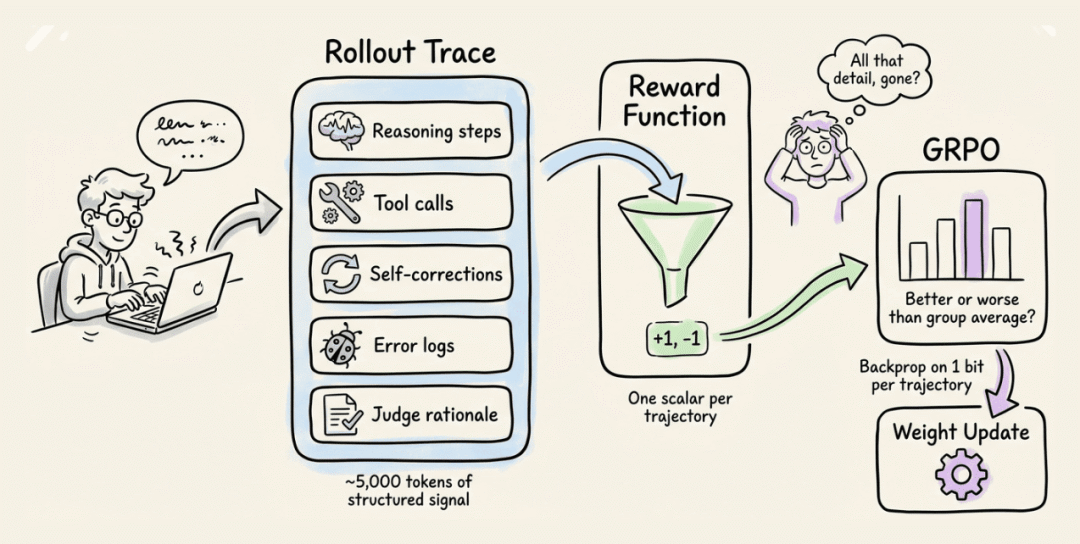
GEPA 采用了不同的方法。
它不是在这个标量上计算策略梯度,而是将完整的 rollout 轨迹交给一个反思 LLM,并询问:“哪里出了问题?提示词应该怎么改?”
反思模型会编写一个新的提示词,你去测试它,如果它改进了,就保留它。
这篇论文于2025年7月发布,被 ICLR 2026 接收,DSPy 将其作为一等优化器,Hugging Face 和 OpenAI 都围绕它发布了 cookbook。
在复合智能体系统(具有独立提示词的多模块流水线)上,GEPA 与 GRPO 相当或更优,同时计算量减少10到50倍,且完全不需要训练基础设施。
让我们深入解析它为什么有效、如何与 GRPO 比较,以及如何在 DSPy 中使用它。
RL 中的信号压缩问题
在语言模型上进行强化学习有一个大多数从业者忽视的信号问题。每个智能体产生的 rollout 是一份5000 token 的文档,包含:
- • 推理步骤
- • 工具调用
- • 自我修正
- • 编译器错误
- • 评判理由
这条轨迹是丰富且结构化的,包含了你想要学习的诊断信息。
但在训练智能体时,GRPO 将这一切压缩成一个数字。
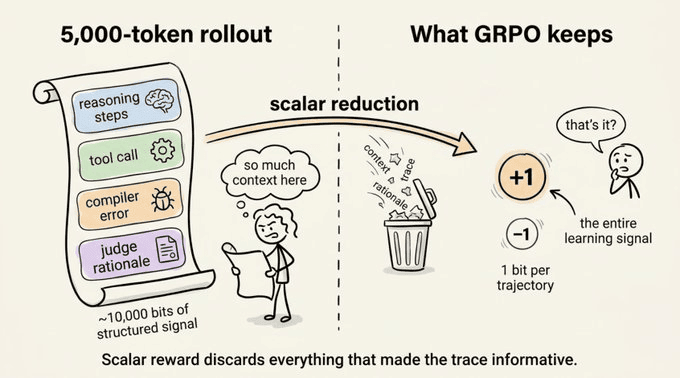
它丢弃了数千比特的结构化信息,这部分解释了为什么需要数万次 rollout 才能收敛。
信号并不稀疏,但最终奖励使其变得稀疏。
让信号自己读懂自己
GEPA 的核心思想是:rollout 本身就是一个自然语言产物,所以让 LLM 来阅读它。不要将轨迹压缩成一个数字。
将它连同失败模式交给一个反思模型,并询问:“这里出了什么问题?提示词应该怎么改?”
反思模型编写一个新的提示词。你测试它。如果它改进了,就保留它。
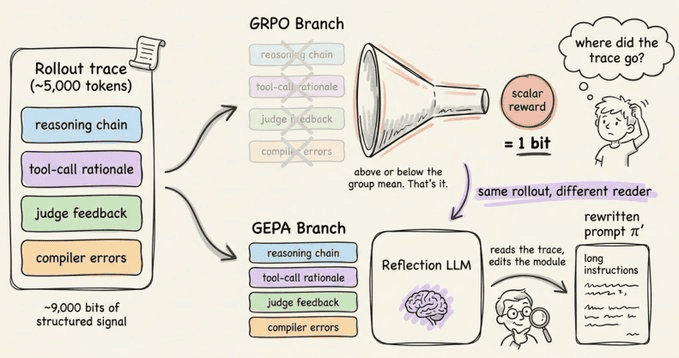
这就是完整的优化循环。论文中的其他一切都是使其在大规模上工作的工程。
GEPA 实际优化的内容
GEPA 面向复合智能体系统。
由各自独立提示词的 LLM 模块组成的流水线,通过 Python 控制流粘合在一起。例如,一个多跳问答智能体可能有:
- • 第一跳查询编写器
- • 检索器
- • 摘要器
- • 第二跳查询编写器
- • 最终回答器
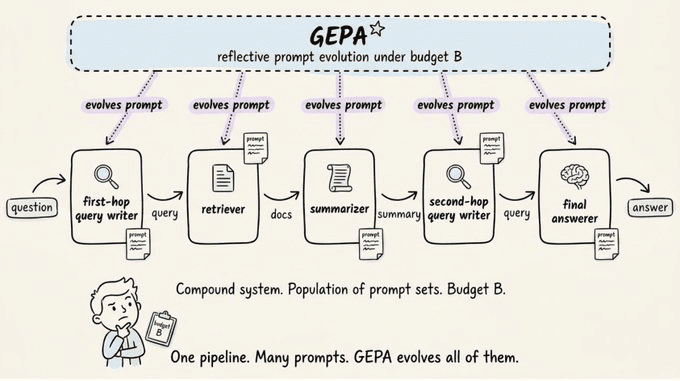
每个模块都有一个提示词,GEPA 会演化所有的这些提示词。
优化目标很简单:在 rollout 预算约束下最大化任务的预期指标。新颖之处在于如何花费这个预算。
反馈函数
GEPA 用反馈函数 μ_f 替代你的标量指标。
它包含 GRPO 给出的相同分数,加上对发生了什么的事实描述。
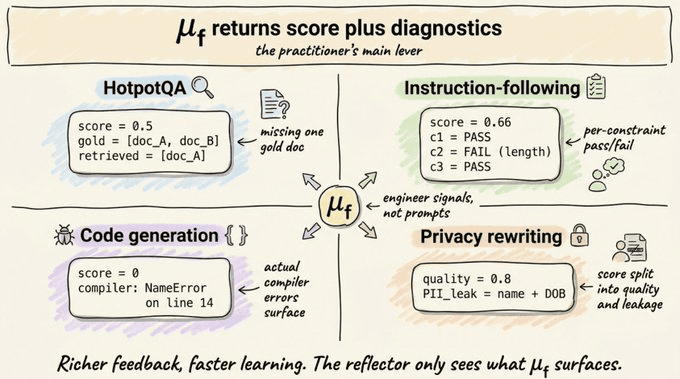
对于多跳问答,它返回你检索到了哪些黄金文档,哪些还需要。对于指令跟随,它返回每个约束的通过/失败描述。对于代码生成,它返回实际的编译器错误和性能分析跟踪。对于隐私保护重写,它将分数分解为质量和 PII 泄露,并附带详细拆解。
六步算法
主循环的每次迭代执行以下操作:
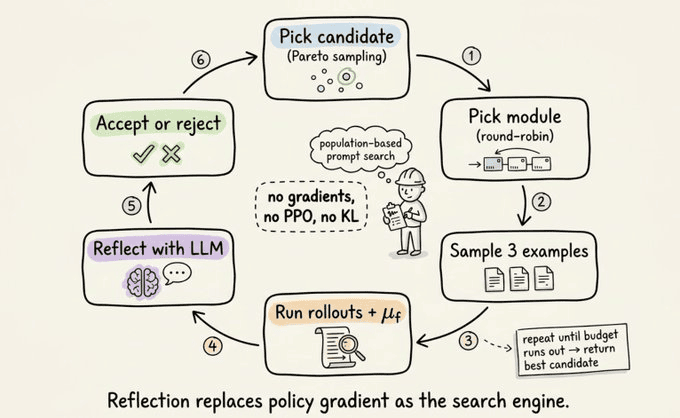
-
- 从种群中选择候选提示词集(帕累托采样,更多细节见下文)
-
- 选择要突变的模块(在模块间轮转)
-
- 从训练集中采样3个样本
-
- 运行 rollout 并收集完整轨迹和来自 μ_f 的反馈
-
- 反思:将轨迹和反馈输入反思 LLM,获得新的提示词
-
- 接受或拒绝:在相同的3个样本上重新运行。如果更好,保留;如果不是,丢弃。
重复直到预算耗尽,返回最佳候选。
整个循环不使用梯度、PPO 或 KL 惩罚。
GEPA 对比 GRPO,正面交锋
先快速看一下 GRPO:
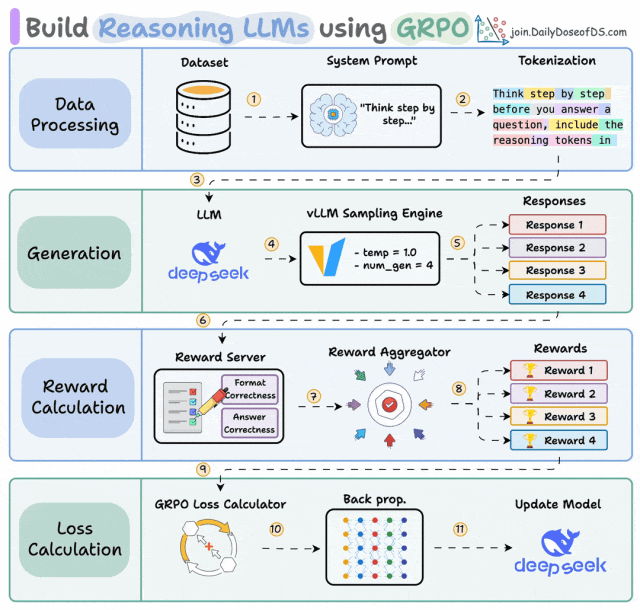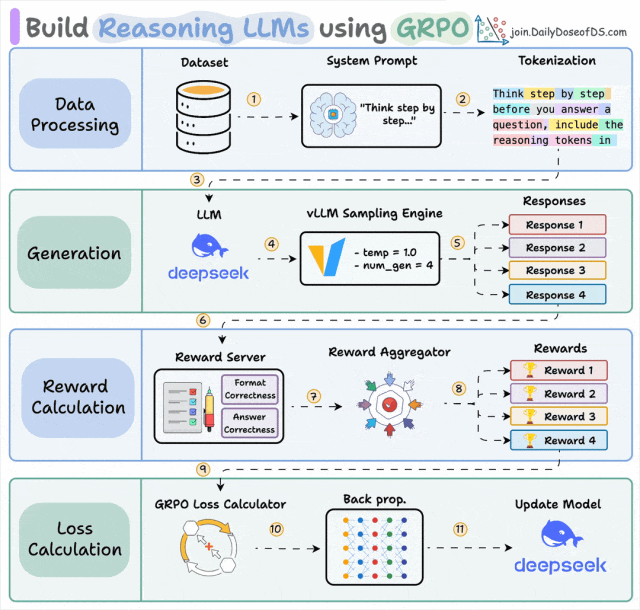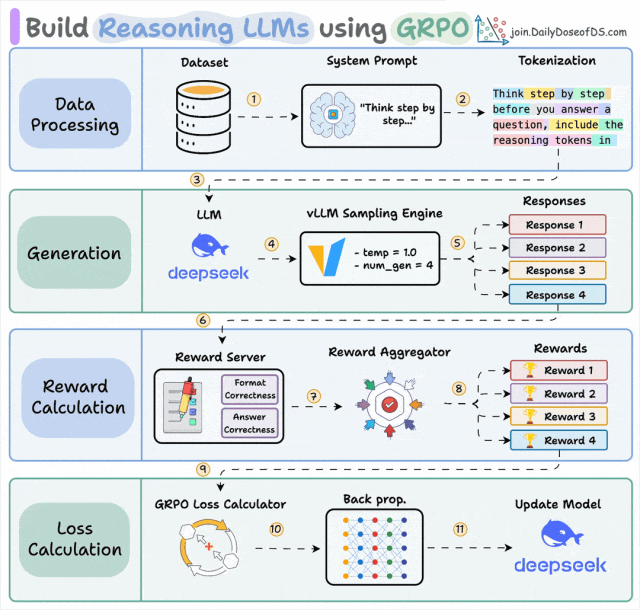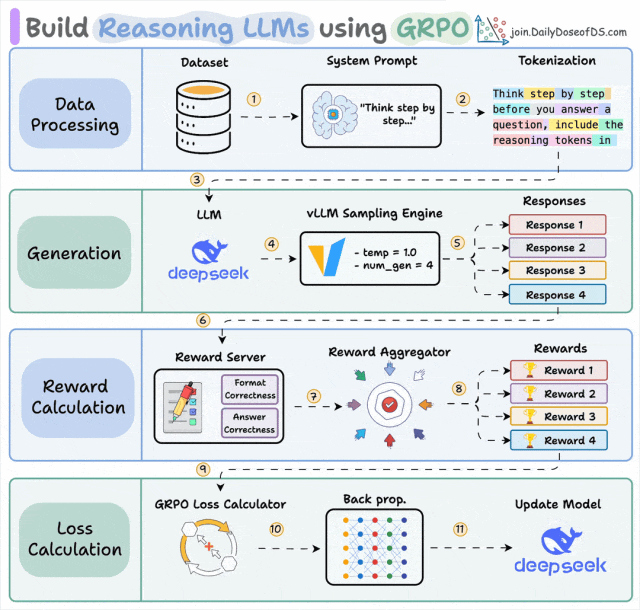
GRPO 和 GEPA 都接收反馈并改进系统。这是相似之处的终点。
GRPO 用策略梯度在标量奖励上更新模型权重。GEPA 用自然语言反思在完整轨迹上更新提示词。
以下是它们之间的并排比较:
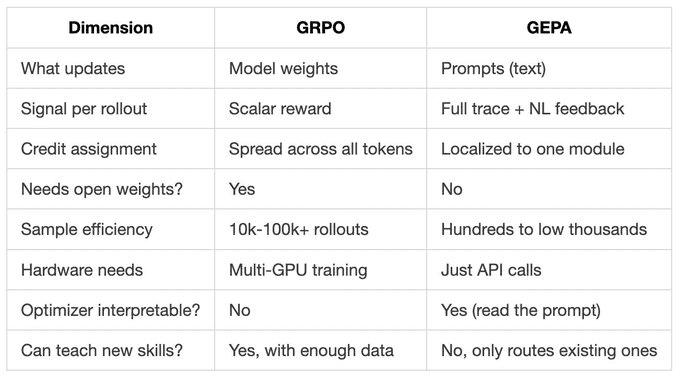
一个重要的注意事项。GRPO 可以改变模型知道什么。GEPA 只能改变你如何提问它。
如果你的基础模型根本无法完成任务,没有任何提示词演化能救你。当需要新能力时进行微调。当需要从现有模型中提取更多有用信息时使用 GEPA。
一个真实例子
让我们用论文中的一个真实例子使其具体化。
任务:HotpotQA 是一个多跳问答基准。你得到一个问题,需要来自两篇不同维基百科文章的信息才能回答。你不能只在一个地方找到答案。
示例问题:“圣维森特教区所在地区的人口是多少?”
要回答这个问题,你的智能体需要:
-
- 第一跳 → 搜索"圣维森特教区",检索文档,了解到它在马德拉
-
- 第二跳 → 搜索"马德拉人口",检索那篇文档,得到数字
-
- 回答:结合两者
智能体在每一跳都有独立的模块。我们将查看第二跳查询编写器的提示词,这个模块决定在第一次检索后搜索什么。
该模块接收的输入:
- • question:原始用户问题
- • summary_1:第一跳检索内容的摘要
它产生的输出:
- • query:第二跳的搜索查询
以下是 DSPy 默认给你的种子提示词:
“给定字段 question、summary_1,产生字段 query。”
这是通用描述,因为它只描述模式,在验证集上的分数约为38%。
GEPA 在几个样本上运行并观察发生了什么。例如,查询编写器可能一直犯同样的错误,比如它复述原始问题并检索它已有的相同文档。
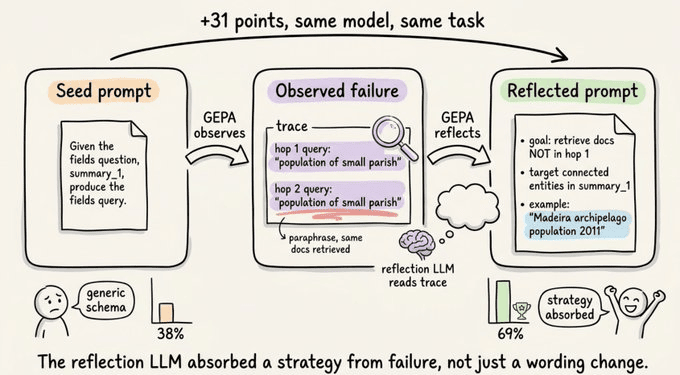
对于我们的圣维森特例子,给定关于教区的摘要,它会再次搜索"圣维森特教区人口",检索不到新内容并失败。
反思 LLM 看到这种失败模式在轨迹中的多个样本上反复出现,它编写了一个新的提示词:
“生成针对多跳检索第二跳优化的搜索查询。第一跳查询是原始问题,因此第一跳文档已经涵盖了直接提及的实体。你的目标:检索第一跳未找到但完整回答所必需的文件。避免复述原始问题。以摘要中提及但在问题中未明确出现的关联实体或更高级实体为目标。例如,如果摘要描述了一个教区但问题询问的是更广泛地区的总人口,你的查询应该针对该地区,而非教区。所以对于关于圣维森特地区的问题,查询’马德拉群岛人口’而非’圣维森特人口’。”
这个重写后的提示词得分69%,从种子的38%提升。
模型和任务保持不变。唯一改变的是一个模块的提示词,而该模块是多个模块中的一个。
反思 LLM 不仅仅是复述种子,而是从观察到的失败中吸收了一个实际策略:
- • 不要复述问题
- • 第一跳已经涵盖了直接提及的实体
- • 瞄准连接它们的更广泛实体
这是一个模式的工作示例。
你无法将这种信息编码到策略梯度中。RL 只会告诉你"这个轨迹比组均值低0.3",然后让反向传播在数千个 token 上搞清楚。GEPA 用纯英文写下这一课,并将其作为新提示词发布。
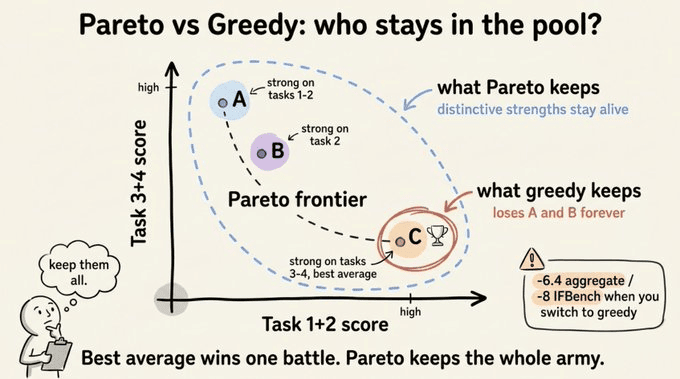
帕累托选择
演化/优化提示词的想法并不新鲜。
但大多数方法往往从当前最佳候选进行突变,这听起来合理,但它会快速坍缩到局部最优。
GEPA 使用了一种更聪明的方法,借鉴自质量-多样性优化。
想象三个候选提示词和四个任务:
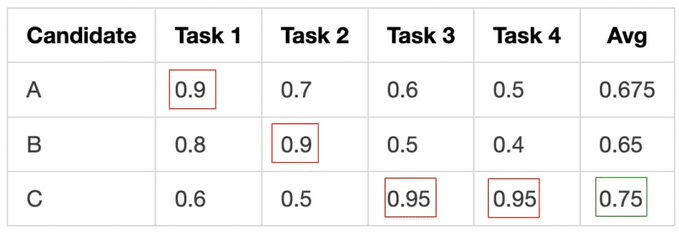
贪心方法每次都会选择 C,因为它有最好的平均分。
但 A 是唯一能良好处理任务1的,B 能良好处理任务2。如果你只突变 C,你会永远失去这些策略。
帕累托选择保留任何在至少一个任务上最佳的候选。然后按它们赢得的任务数量加权抽样父代。所以 C 最可能被选中,但 A 和 B 留在种群中。它们的独特优势稍后可以与 C 相结合。
这一个设计选择将 GEPA 与早期的进化提示词方法区分开来。
GEPA 在领域中的位置
谁做什么的快速地图:
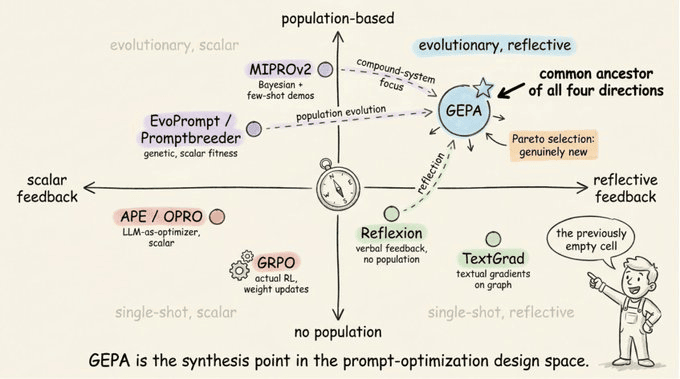
APE、OPRO:都使用 LLM 提出候选提示词,由标量指标评分。APE 从输入-输出演示生成候选并选择最佳。OPRO 将先前的提示词及其分数输入元提示词,使 LLM 能提出有依据的改进。单一提示词,不对轨迹进行反思。
EvoPrompt、Promptbreeder:通过 LLM 调用将进化算子(交叉、变异)应用于提示词种群。Promptbreeder 添加了一个自参照层:它也演化变异提示词本身。两者都使用标量适应度进行选择,针对单一提示词,不针对多模块流水线。
Reflexion:智能体在每次试验后反思任务反馈,并将反思存储在情景记忆缓冲区中以供下次尝试使用。改进跨重试的逐实例行为,不是在训练集上进行种群级提示词演化。
TextGrad:PyTorch 风格的反向传播,但使用自然语言批评而非数值梯度。LLM 通过计算图传播文本反馈以产生逐变量改进建议。每次迭代单一候选,无种群。
MIPROv2:DSPy 先前的旗舰。从训练数据引导少量样本,提出基于数据摘要和轨迹的指令候选,然后使用贝叶斯优化(Optuna TPE)在所有模块的联合指令-样本空间搜索。一次性生成所有候选,而非通过反思逐步演化。
GRPO:真正的 RL,有权重更新。每次提示词采样一组 rollouts,使用组均值作为基线计算逐轨迹优势,然后通过带 KL 惩罚的策略梯度更新权重。这里唯一改变模型知道什么而非只是你如何提示它的方法。
GEPA 从这些方法中借鉴了想法。它像 Reflexion 一样使用语言反思,但将其应用于候选种群而非单一智能体的记忆。
它像 EvoPrompt 一样使用选择压力演化种群,但由自然语言反馈而非标量适应度驱动突变。
它像 MIPROv2 一样针对复合多模块流水线,但通过反思迭代演化提示词而非一次性生成所有候选。
GEPA 的新部分是帕累托选择,它保留即使只在一个任务上最佳的候选,而非总是从最高平均表现者突变。
在 DSPy 中使用它
API 与 MIPROv2 只有一行之差:
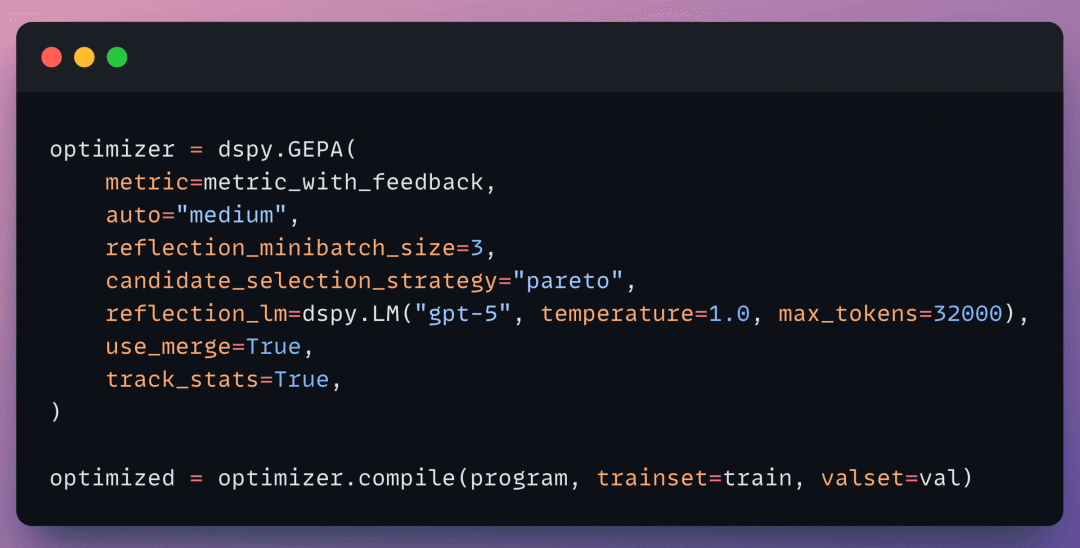
诀窍:你的指标函数需要正确的签名。
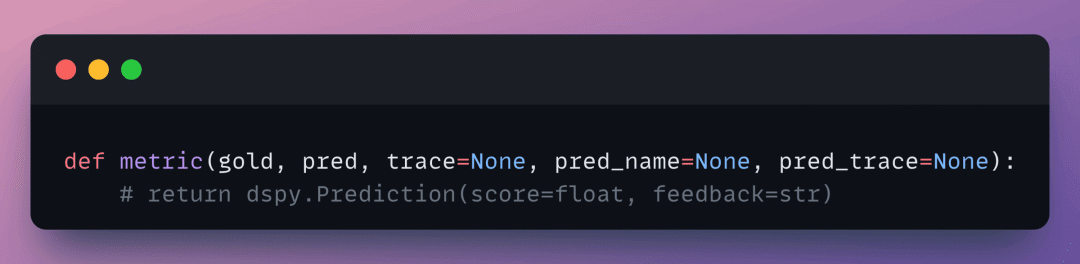
返回一个同时包含分数和反馈字符串的预测。反馈被输入到反思 LLM,所以要使其具有诊断性和具体性。
如果你的反馈字符串只是"错误答案",你就回到了标量领地,GEPA 退化为更慢的 MIPROv2。
如果你的反馈说"漏掉了实体X,检索了文档Y而黄金答案是Z,第3步格式违规",那么 GEPA 就能很好地处理这种细节。
2026年现实核查
GEPA 特别是在与 GRPO 对比时胜出,并非每种 RL 方法都超越。
该领域已停止将这个框架设为 GEPA 对 RL,而是开始将其框架为 GEPA 和 RL。论文本身指出混合配方是自然的下一步。
在复合系统上,反思比 RL 的样本效率高得多。这两者越来越多地被结合使用,而非相互对立。
还有一个值得知道的细微差别:Decagon 2026年3月的生产消融实验发现,对于 GEPA 来说,更多数据并不总是更好。20到100个样本往往击败500个。当给它的太多时,反思循环会过拟合。
GEPA 从失败模式中学习。有了50个精心选择的样本,反思器看到清晰的信号。有了500个,它开始追逐噪声。
使用小而高质量的训练集,不要假设规模有帮助。
何时使用什么
如果你今天在构建一个复合智能体系统,以下是决策树。
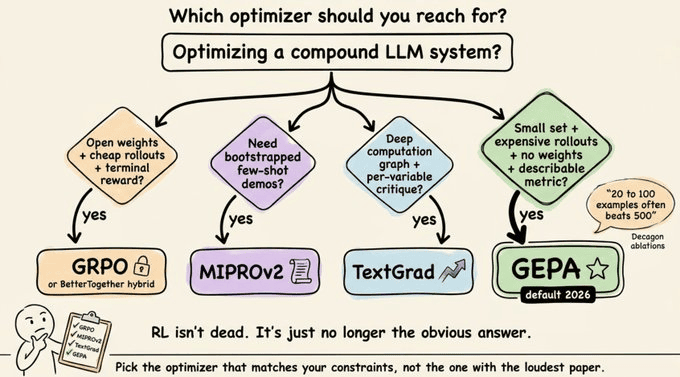
使用 GEPA 当:你有一个小训练集、昂贵的 rollout、无法访问权重,以及一个可以用语言描述的指标。
使用 GRPO 当:你有丰富便宜的 rollout、开放权重,以及一个可验证的终端奖励。
使用 MIPROv2 当:你特别需要在提示词中引导少量样本示例。
使用 TextGrad 当:你的计算图很深,且你想要明确的逐变量批评传播。
对于2026年大多数实际的复合系统工作,GEPA 是首先尝试的默认。
RL 仍有其用武之地,但当读取一个 rollout 的成本低于再运行一万次时,它不再是明显的默认选择。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)