
DeepSeek 版 Claude Code 火了,暴涨 2.4 万 Star!
DeepSeek-TUI是一款基于DeepSeek模型的终端编程代理工具,已在GitHub获得2.4万星标。它将AI编程助手集成到终端环境中,支持文件读写、Shell命令执行、Git操作等功能,并提供三种交互模式(Plan/Agent/YOLO)满足不同风险偏好需求。项目采用开源架构,支持多语言界面和本地化工作区,通过MCP协议和子代理机制处理复杂任务。安装方式灵活,适合需要多步代码修改且重视上下
大家好,我是Java1234_小锋老师。
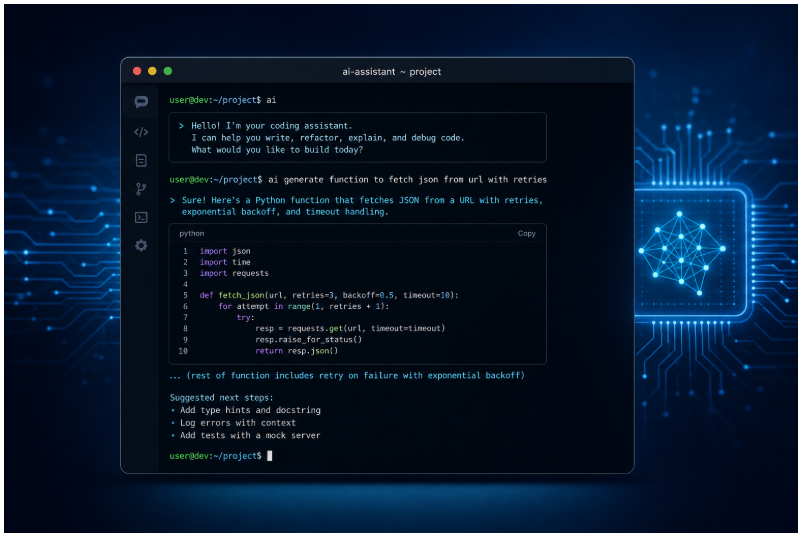
先聊现象:为什么在终端里做「代理式编程」会爆火
如果你过去几年一直在关注「AI 帮你改代码」这条产品线,应该会有一种直观感受:IDE 里的补全很好用,但真正想让它连读带改、顺带跑几条命令的时候,往往需要一种更接近「会话 + 工具调用」的形态。行业里类似形态不少,有的在编辑器里安家,有的在网页里安家;而最近这一波把 终端(Tauri/TUI) 当作主舞台的项目,又因为 开源、本地化工作区、可对工具调用做门禁(批准/自动),很容易在开发者圈子里形成复利传播。
Hmbown/DeepSeek-TUI 就是其中一个代表:围绕 DeepSeek 的模型能力与 OpenAI 兼容的流式接口习惯,把一个「会读仓库、会下命令、会改文件」的 Coding Agent,收敛成你可以 deepseek 一下就能启动的日常工具。项目在 GitHub 上增长很快——截至笔者查阅时已 超过 2.4 万个 Star。数字本身只能说明「很多人愿意点开星标」,更关键的仍是:它是否真的解决你在终端里的高频问题。下面我们把项目放回「功能与设计选择」里看。
DeepSeek-TUI 是什么:一句话与定位边界
官方 README 的第一句很明确:它是 运行在终端里的 DeepSeek 模型编程代理(Coding agent)——你也可以把它理解成一种「DeepSeek 版的终端型编码助手」体验:不一定要和某个商业产品逐项对标,但它的产品承诺非常工程师化:把你的 API Key、你的工作区、你的键盘习惯,接进一个有工具能力的对话式代理里。仓库入口
另外需要记住 README 里也写清楚的边界声明:它与 DeepSeek 公司并无附属关系。因此讨论它时,更适合把它看成社区开源作品:模型能力来自你选择的后端(默认 DeepSeek 平台等),产品的质量来自项目维护者与贡献者迭代。
它到底能干什么:能力与使用场景

结合官方特性列表,这个项目通常适合这些「真的很终端」的日常:
- 读改文件、跑 shell、折腾 git:把最常用手工复制粘贴的步骤,转成「可追溯的多步执行」。
- 需要「看得见推理过程」时使用 DeepSeek V4 的 thinking streaming:它不是只给你最终答案黑箱,而是一边展示推理片段一边推进。(是否展示、以及如何展示会受配置与交互影响)
- 偏工程化的扩展面:文档里提到了 MCP(Model Context Protocol)、子代理(sub-agents)、以及在合适场景下的 原生 RLM 等——本质都是在解决「单靠一次对话不够用」的工程问题。
- 长会话与可追溯:会话保存/恢复、durable task queue、以及与工作区快照/恢复相关的机制,都是在回答「Agent 不可靠时,如何把损失控制在可撤回范围」这一类老问题。
- 多语言界面:内置
zh-Hans等本地化,对中文用户上手更友好(模型侧自然语言仍可随你的输入语言走)。
如果你对「这是不是又一个玩具」拿捏不准,可以这样判断:你是否经常需要在仓库里做多步改动,并希望每次改动前后都有可解释的上下文链条。若是,它就非常对症。
从命令到界面:交互与三种模式
日常使用上,你可能会反复遇到三条路径:
交互 TUI:直接 deepseek,进入键盘驱动的界面。
一句话任务:例如 deepseek "解释这个函数",适合轻量问询。
更「放手」:例如 deepseek --yolo,在可信工作区追求效率(但也要明白自动批准意味着风险自担)。
在项目提供的模式划分里(Plan / Agent / YOLO),你可以把它理解为 谨慎 → 默认 → 更激进 的梯度:Plan 更偏向先读摸清再规划;Agent 是多步工具但在交互里保留门禁;YOLO 则把批准成本压到最低。模式不是玄学口号,而是你风险管理策略的选择。
Auto 模式与成本意识:省事但不玄学
Auto 模式的工程解释很直白:项目在真正发起「正式那一轮对话」之前,会先用 deepseek-v4-flash 做一次很轻的路由,根据最近上下文和用户请求去选择 这一轮到底用 Flash 还是 Pro,以及 thinking 的强度档位。上游 API 不会收到 model: "auto" 这种抽象值,你看到的账单与上下文统计也会对「实际跑的那个模型」对齐——这对既要省事又要对成本敏感的人非常关键。
再配合 README 中对 前缀缓存(prefix cache)telemetry、按轮/按会话的费用估算 等能力的描述,这东西的目标用户画像就更清晰了:不是只会 chat,而是会持续 multi-turn 的工程使用者。
安装几条路:按需选择就好
官方的「安装优先级」其实很照顾现实世界的工具链分叉:你可以选择 npm 全局包装(背后是拉预编译二进制)、Cargo 源码链(更偏 Rust 用户)、Homebrew / Windows Scoop,也可以 Docker 或直接 GitHub Releases 下载。对中国大陆用户,README也给了镜像与 npm registry 的实践建议。
最小心智模型是:deepseek 是入口,deepseek-tui 是对应的 TUI 运行时;把它们安装到 PATH 后,再配合 deepseek doctor 做自检会更稳。安装细节以官方 INSTALL 文档为准。
架构鸟瞰:信息流怎么转起来(Mermaid)
README 用文字勾过一条链路:deepseek(调度 CLI)→ deepseek-tui → ratatui 渲染 ↔ 异步引擎 ↔ OpenAI-compatible 流式客户端;工具调用走类型化注册表,再把结果回填到 transcript。把它画成流程图,大致是这样理解最省力:
你可以把这张图当作「心智模型」而不是实现细节的全部:真正踩坑时,还是要回到官方 docs/ARCHITECTURE.md 去对照模块边界。
延伸阅读与负责任的期待

如果你准备认真用起来,建议按这个顺序读官方文档,会比只看 Star 数更省时间:
- 架构:ARCHITECTURE.md
- 配置:CONFIGURATION.md
- MCP:MCP.md
- HTTP/SSE 运行时:RUNTIME_API.md
最后补一句很务实的话:任何带文件写入与命令执行能力的 Agent,本质都是「一把很锋利的电动螺丝刀」——它可以极快地把事情做对,也可能在错误的工作区里极快地把事情做炸。DeepSeek-TUI 通过模式、审批、快照/恢复、诊断与配置把风险「工程化」,但责任边界仍然在你:从小仓库试起、先跑 doctor、先理解工具会碰哪些路径,再谈自动化。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)