
创新实训(7)—— 问答系统(搜索功能)
目前,我们的搜索逻辑被限制在“当前会话”内。在接下来的改进中,考虑扩大搜索域,只需要将 ChromaDB的元数据过滤条件从session_id升级为当前用户的user_id。此外,也考虑用轻量级的MySQL搞定会话标题的精准查询,用重量级的ChromaDB + 大模型解决复杂对话内容的语义检索。此外,考虑到虽然大模型具备零运维、长文本兼容和强大的语义泛化优势,而本地小模型在处理短文本聊天记录时具有
考虑到平时使用AI时,可能出现遇到了一个比较好的问题解答结果,但由于当时没有及时记录,后续想找到这个问题却只能凭借记忆中的个别关键词逐条翻阅查找,但这样效率较低,因此希望在问答系统中引入一个对话搜索功能,从而可以快速通过一些关键词找到相关的问题及解答。
一、采用什么方式实现搜索功能
现阶段,打算先完成一个可以在会话内,对该会话里的消息进行关键词检索的功能。刚开始设计功能时,打算采用传统的搜索引擎技术,如Lucene,Elasticsearch等方法。但结合之前基于Lucene做的搜索引擎的搜索程序,发现这种方法虽然可以精准检索到需要的结果,但其更是对关键词是否一致的比对,少了对于关键词的语义理解,从而难以找到其余相关内容。这在这类学习系统中,如果用户想搜一个概念,但忘记了具体名字,而是用了一个相似的关键词去搜,这种情况下传统搜索引擎很难达到用户的需要。
随后,我了解到了向量检索,该方法会先将数据转化为向量,通过计算向量间的相似度实现对问题的问题,该方法可以通过文本embedding相关的大模型将文本转化为高维空间向量,利用向量间的相似度进行数学比对,从而摆脱了传统搜索对关键字的依赖,实现了‘语义级’智能查询。具体而言,我对两种方法进行了以下几个方面的对比。
| 维度 | 基于大模型的“语义检索” (向量检索) | 基于搜索引擎的“全文检索” (ES/Lucene) |
| 核心原理 | 将一句话压缩成几千维的数字向量,计算两句话的“空间距离”。距离越近,意思越相近。 | 将文本拆分成词语,通过倒排索引,搜索时严格匹配这些词语。 |
| 优点 |
支持模糊记忆和同义词 |
精准、极速、带高亮 |
| 缺点 |
1. 存入时需要调用 Embedding 模型,会产生微量 API 费用或算力消耗。 2. 有时过于“发散”,搜具体的特定人名或专有名词时,精确度不如全文检索。 |
1. 比较“死板”。搜“番茄”绝对搜不到“西红柿”。 2. ES 这种组件部署运维成本高。 |
二、后端实现
决定使用语义检索后,我找到了智谱的Embedding模型,决定暂时采取此模型实现此功能。Embedding-3 是智谱AI 推出的第三代文本向量化模型,在前代基础上全面升级,提供更强的语义理解能力和更灵活的向量维度选择。该模型支持自定义向量维度,在保持高质量语义表示的同时,为不同应用场景提供了更优的性能和成本平衡。
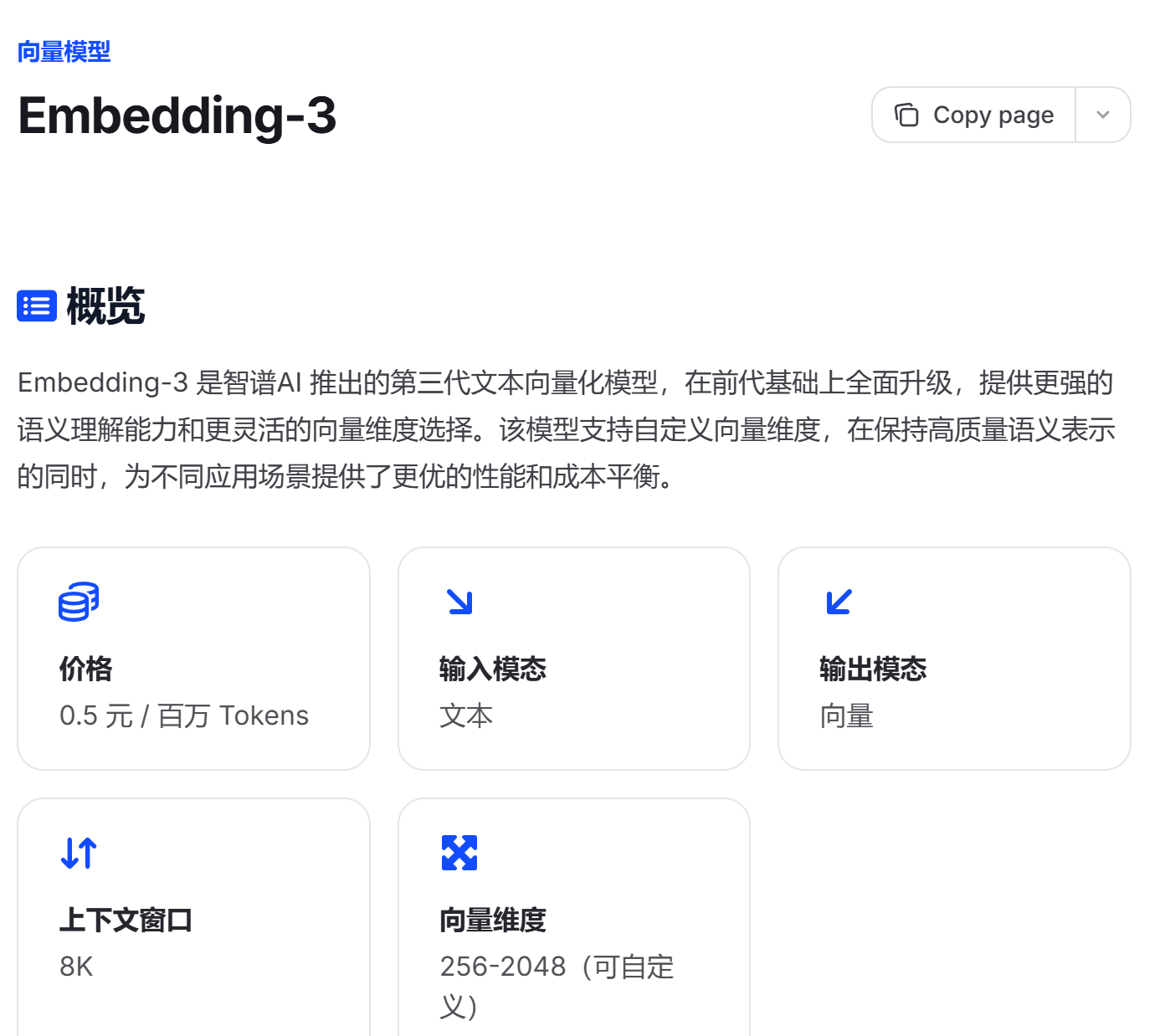
在引入语义检索后,我首先改变了对于message的存储架构:
-
MySQL(关系型数据库)负责存储完整的聊天记录(时间、角色、状态等),保证基础功能绝对稳定。
-
ChromaDB(向量数据库)负责将文本转化为高维向量存储。只负责计算相似度,不参与核其它功能的实现。
1: 基础设施搭建(初始化 ChromaDB 与Embedding大模型)
首先,我在本地持久化一个 ChromaDB,并给它挂载一个智谱的Embedding模型。它的作用是把中文自动转化为向量。
2: 将数据存入数据库
当产生一条新聊天记录时,我需要同时写入MySQL和ChromaDB。
但在写入ChromaDB时,做了一些额外的处理,在向ChromaDB中写入时,排除掉了太短的无用词、系统提示词,或者非文本消息(比如图片)。
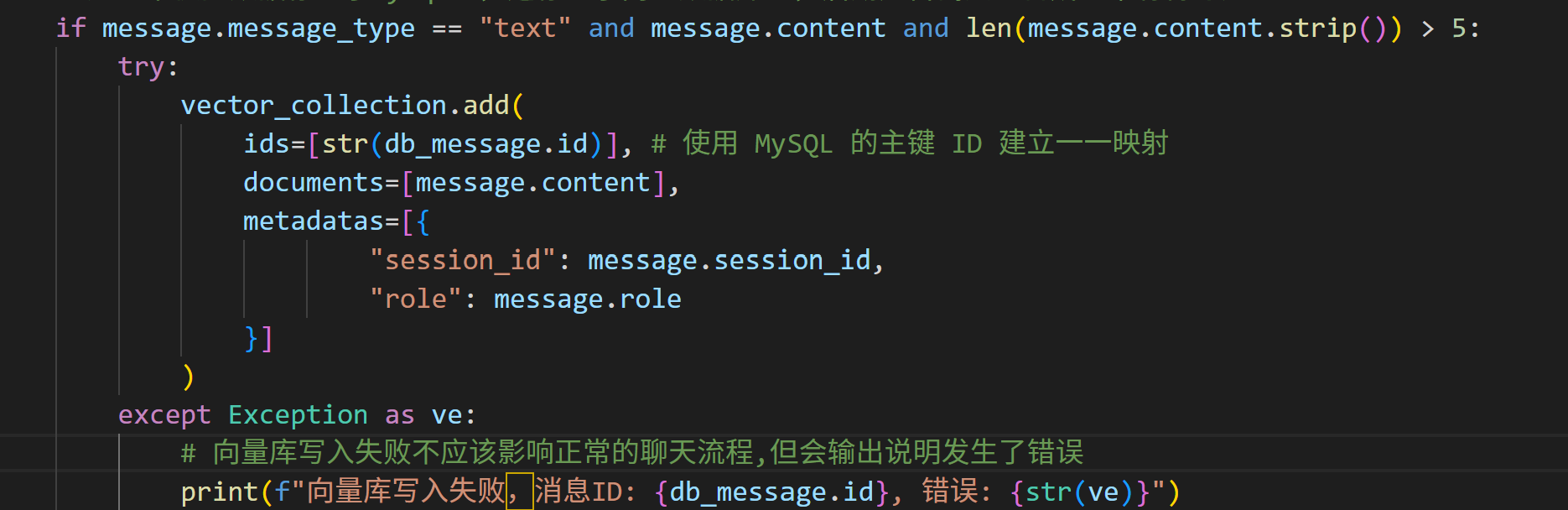
3: 语义检索与数据整形
当用户发起搜索时,我们在指定的 session_id 下寻找最相似的 Top K 条记录,并将 ChromaDB 原生复杂的嵌套数据结构洗成前端友好的 JSON 格式。
此外,目前返回结果采用top-k的方式,返回最为相似的10个结果,后续考虑可以设置一个相似度阈值进行结果返回,可能效果会更好。
三、前端实现
前端实现过程中,由于前端构建的经验不足,起初我尝试将所有代码写在chatView.vue中,但渐渐发现该文件的内容越来越多,可读性差,因此将搜索相关的界面写在了一个单独的vue文件中,而非都堆积在chatView.vue中。对于前端的设计,主要是以下想法:在搜索框输入问题后,点击搜索,有个界面弹出来,是搜索结果,点击想要的结果就会定位到对应的会话中的位置。 具体实现流程如下。
1. 搜索框切换动效
默认只显示一个放大镜图标,点击后向左展开。
2. 异步搜索流
在请求后端时,不仅要处理数据,更要处理UI的状态反馈。
3. CSS 文本截断
在展示搜索结果时,AI 的回复往往很长,我们使用CSS限制最多显示三行,超出部分自动显示省略号。
CSS
.content-preview {
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 3; /* 核心:限制3行 */
overflow: hidden;
}
4. 定位操作
当用户在弹窗中点击某条搜索结果时,会触发定位操作。
JavaScript
const handleLocate = (msgId) => {
showSearchDialog.value = false
emit('locate', msgId)
}
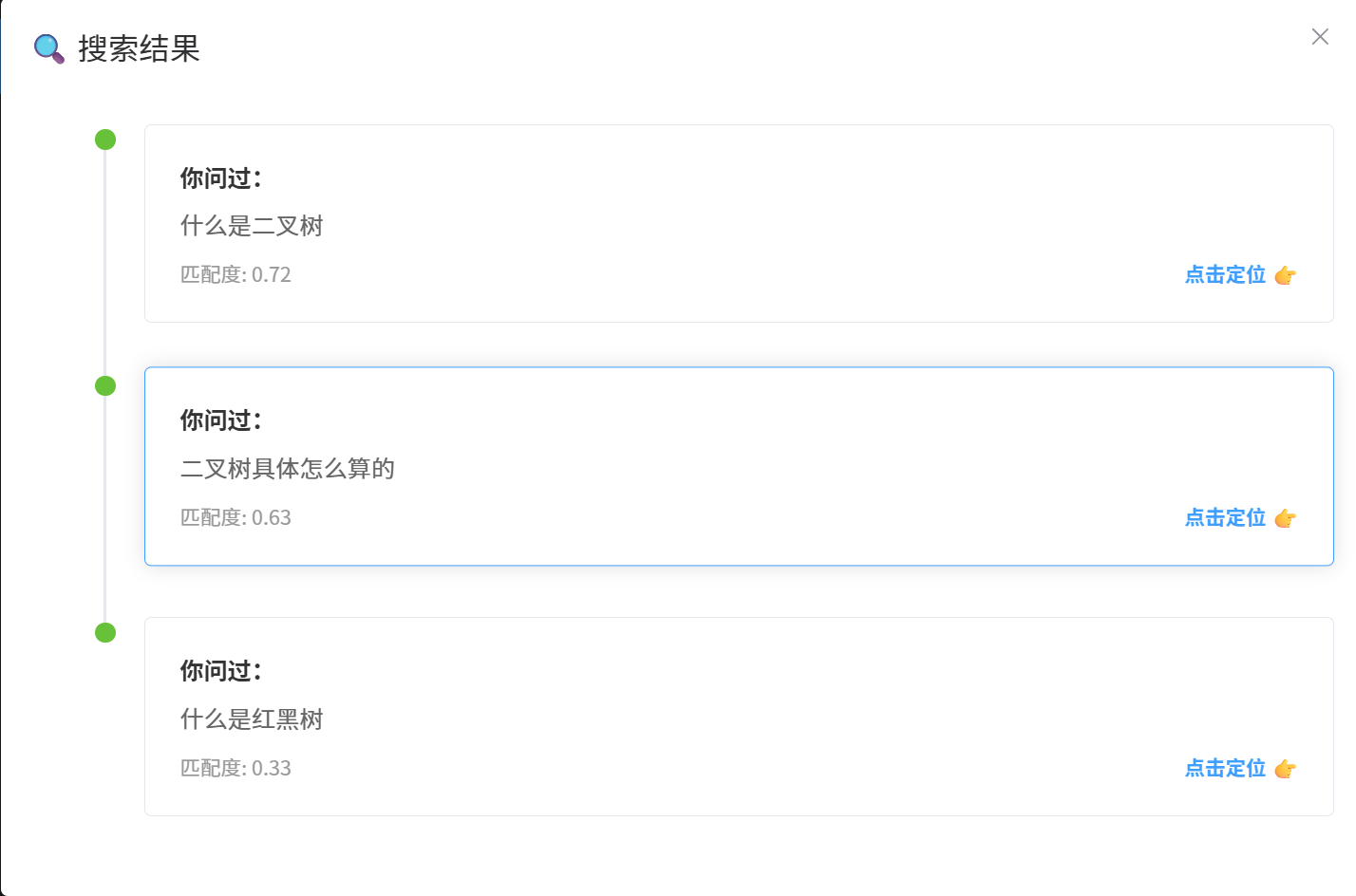
具体搜索结果的展示如下:
四、总结
目前,我们的搜索逻辑被限制在“当前会话”内。在接下来的改进中,考虑扩大搜索域,只需要将 ChromaDB的元数据过滤条件从 session_id 升级为当前用户的 user_id。此外,也考虑用轻量级的MySQL搞定会话标题的精准查询,用重量级的ChromaDB + 大模型解决复杂对话内容的语义检索。
此外,考虑到虽然大模型具备零运维、长文本兼容和强大的语义泛化优势,而本地小模型在处理短文本聊天记录时具有响应极快、数据绝对隐私且完全免费的特点。在系统后续的改进中,尝试引入本地开源小模型进行向量检索。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)