
LangGraph 多步骤任务规划全解
能将一个复杂任务分解为多个步骤并依次执行。实现一个能分解复杂任务的 Agent。
一、什么是多步骤任务规划?
多步骤任务规划(Task Planning)是智能体(Agent)的核心高阶能力,指的是LLM 先将一个模糊、复杂、无法一步完成的大任务,拆解为多个有序、可执行、目标明确的子步骤,再按顺序执行每个子步骤,最终汇总结果完成原任务的能力。
它和你之前实现的 ReAct Agent(边思考边调用工具)的核心差异,也是它的核心优势:
| 特性 | ReAct 反应式 Agent | Plan-and-Execute 规划执行 Agent |
|---|---|---|
| 执行逻辑 | 走一步看一步,单轮思考 + 单轮行动 | 先全局规划,再分步执行,有完整的全局视角 |
| 适用场景 | 单轮问题 + 简单工具调用(查天气、做计算) | 复杂长周期任务(写报告、做方案、多文档分析、项目落地) |
| 上下文控制 | 容易迷失方向,长任务易出现幻觉 | 有明确的步骤约束,每一步目标清晰,不易偏离 |
| 资源消耗 | 每一步都要重新思考全局,Token 消耗高 | 规划仅做一次,执行聚焦单步目标,Token 效率更高 |
| 错误处理 | 单步失败易导致全局崩溃 | 单步失败可单独重试 / 调整计划,不影响全局 |
LangGraph 是实现多步骤任务规划的最佳框架,它的状态机 + 图结构天然适配「规划 - 执行 - 校验 - 调整」的循环逻辑,也是 LangChain 官方推荐的复杂任务 Agent 标准实现方案。
二、核心架构:Plan-and-Execute 规划执行范式
生产级多步骤任务 Agent 的标准架构是 Plan-and-Execute(规划 - 执行),核心分为 5 个解耦的模块,完全对应 LangGraph 的节点设计:
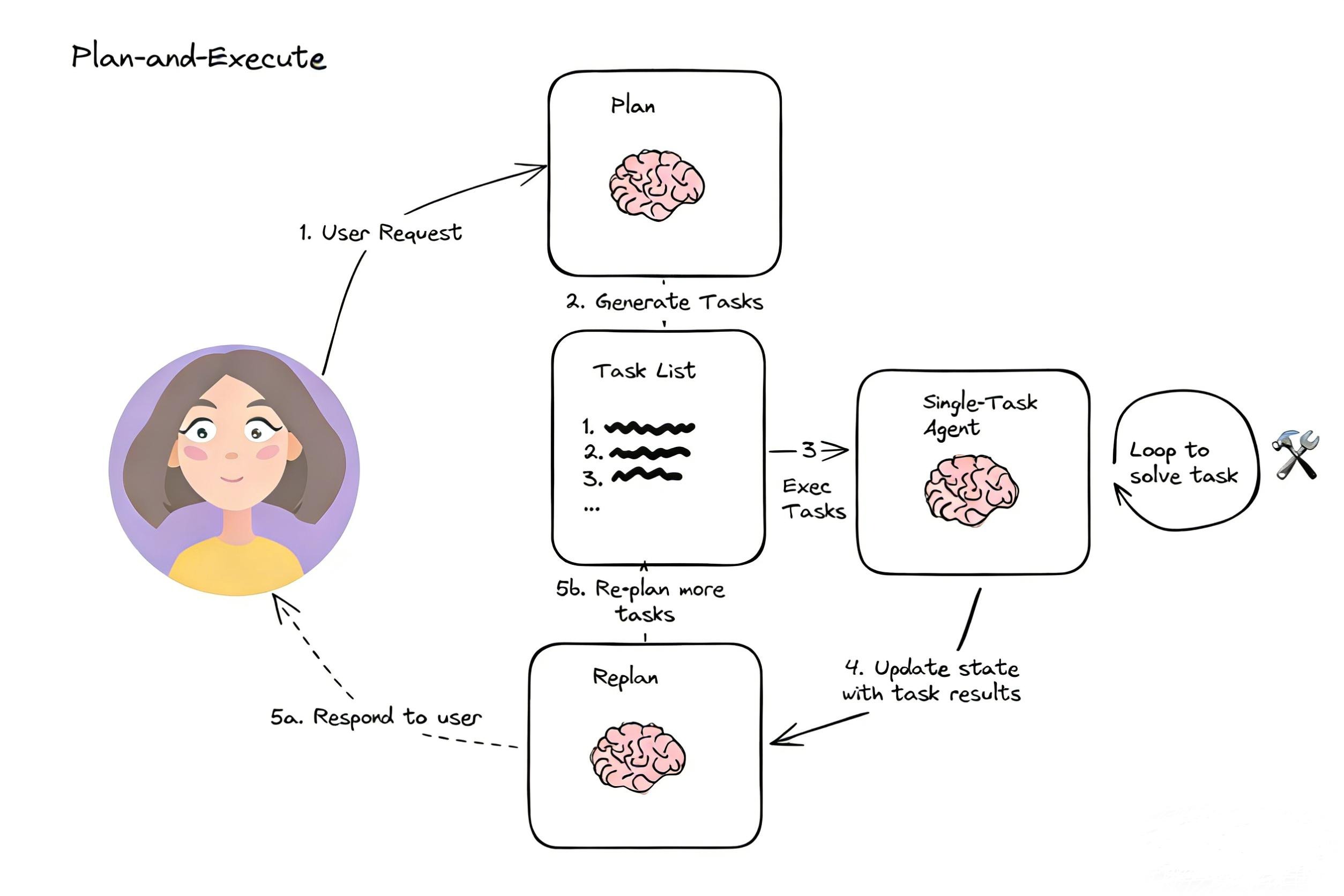
| 模块 | 核心职责 | 对应 LangGraph 节点 |
|---|---|---|
| 规划器(Planner) | 接收用户复杂任务,拆解为有序的子步骤列表,定义每个步骤的目标、输入输出 | plan_node 规划节点 |
| 执行器(Executor) | 接收单个子步骤,调用 LLM / 工具完成该步骤的执行,输出步骤结果 | execute_node 执行节点 |
| 校验器(Validator) | 校验当前步骤的执行结果是否合格,判断是否需要重跑、调整计划,还是进入下一步 | validate_node 校验节点 |
| 重规划器(Re-Planner) | 当步骤执行失败、或发现原计划有缺陷时,动态调整步骤列表,更新计划 | replan_node 重规划节点 |
| 状态管理器 | 维护整个任务的全生命周期状态:任务目标、计划步骤、当前进度、每步结果、错误信息 | State 状态定义 + Checkpointer 持久化 |
标准执行流程
用户输入复杂任务 → 规划节点生成全局步骤计划 → 执行当前步骤 → 校验步骤结果
↓(合格) ↓(不合格/计划缺陷)
判断是否有下一个步骤 → 无 → 汇总结果 → 结束
↓(有)
回到执行节点,执行下一个步骤三、核心 State 设计(多步骤规划的灵魂)
多步骤规划的 State 必须包含任务全生命周期的完整信息,这是整个工作流的核心,设计完全兼容你之前的代码风格:
from typing import TypedDict, Sequence, Annotated, List, Tuple
from langchain_core.messages import BaseMessage
from langgraph.graph import add_messages
import operator
# 多步骤任务规划的State定义
class TaskPlanState(TypedDict):
# 1. 基础任务信息
input_task: str # 用户输入的原始复杂任务
user_id: str # 用户ID,绑定持久化和长期记忆
# 2. 规划核心信息
plan_steps: List[str] # 拆解后的完整步骤列表
current_step_index: int # 当前执行到第几步(从0开始)
# 已执行完成的步骤:(步骤内容, 步骤执行结果)
past_steps: Annotated[List[Tuple[str, str]], operator.add]
# 3. 执行结果信息
current_step_result: str # 当前单步的执行结果
final_answer: str # 所有步骤完成后的最终汇总答案
# 4. 控制与错误处理
loop_count: int # 循环计数,防死循环
error: str | None # 错误信息
messages: Annotated[Sequence[BaseMessage], add_messages] # 对话历史
设计关键点
plan_steps:存储拆解后的完整步骤列表,是整个工作流的执行蓝图past_steps:用operator.add做 reducer,自动追加已完成的步骤和结果,无需手动拼接current_step_index:记录当前执行进度,实现步骤的顺序流转loop_count:防止无限重试、死循环,是生产级代码的必备防护
四、完整可运行代码实现
基于你之前的代码风格,实现了带任务拆解、分步执行、结果校验、错误重试、动态重规划、会话持久化的生产级多步骤任务 Agent,完全兼容智谱 API、国内网络环境。
第一步:环境准备与依赖安装
pip install -U langgraph langchain langchain-openai langchain_community pydantic_settings python-dotenv
第二步:完整代码实现
import os
import json
import re
from dotenv import load_dotenv
from typing import TypedDict, List, Annotated, Tuple, Sequence, Literal
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from pydantic_settings import BaseSettings, SettingsConfigDict
from pydantic import BaseModel, Field
import operator
from work.langgraph_memory_store import checkpointer
#加载环境变量
load_dotenv()
# 配置管理
class Settings(BaseSettings):
# 必须配置 再.env文件中配置
ZHIPU_API_KEY: str
ZHIPU_BASE_URL: str
LLM_MODEL: str
LLM_BACKUP_MODEL: str
# 可选配置
LLM_TIMEOUT: int = 120
MAX_LOOP_COUNT: int = 30
MAX_RETRY_COUNT: int = 5
# pydantic 2.x 标准配置
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore"
)
settings = Settings()
# 定义State(多步骤规划核心)
class TaskPlanState(TypedDict):
# 1.基础任务信息
input_task: str # 用户输入的原始复杂任务
user_id: str # 用户id 绑定持久化和长期记忆
# 2.规划核心信息
plan_steps: List[str] #拆解后的完整步骤列表
current_step_index: int # 当前执行到第几步(从0开始)
# 已执行完成的步骤:(步骤内容,步骤执行结果)
past_steps: Annotated[List[Tuple[str, str]], operator.add]
# 3.执行结果信息
current_step_result: str # 当前单步的执行结果
final_answer: str # 所有步骤完成后的最终汇总答案
# 4.控制与错误处理
loop_count: int # 循环计数,放死循环
error: str | None # 错误处理
messages: Annotated[Sequence[BaseMessage], add_messages] # 对话历史
validate_result: str
# LLM 初始化(主模型 + 备用模型)
main_llm = ChatOpenAI(
api_key=settings.ZHIPU_API_KEY,
base_url=settings.ZHIPU_BASE_URL,
model=settings.LLM_MODEL,
temperature=0,
timeout=settings.LLM_TIMEOUT,
max_retries=0
)
# 备用LLM:用于重试 降级
backup_llm = ChatOpenAI(
api_key=settings.ZHIPU_API_KEY,
base_url=settings.ZHIPU_BASE_URL,
model=settings.LLM_BACKUP_MODEL,
temperature=0,
timeout=settings.LLM_TIMEOUT,
)
# 结构化输出定义(保证规划步骤格式统一)
class TaskPlan(BaseModel):
"""任务拆解后的计划结构,保证LLM输出的步骤格式统一"""
steps: List[str] = Field(
description="拆解后的有序执行步骤,每个步骤是一个独立可执行的子任务。步骤之间有明确的先后顺序,最后一步是汇总最终结果"
)
# 核心节点实现
# 规划节点:拆解复杂任务为步骤
def plan_node(state: TaskPlanState):
"""规划节点:接收用户的复杂任务,拆解为有序的执行步骤"""
print("\n-- 📋执行节点:任务规划 --")
input_task = state["input_task"]
loop_count = state["loop_count"]
error = None
plan_steps = []
# 定义输出解析器
parser = JsonOutputParser(pydantic_object=TaskPlan)
# 规划Prompt : 保证拆解的步骤合理、可执行、无遗漏
plan_prompt = ChatPromptTemplate.from_template("""
你是专业的任务规划专家,需要将用户的复杂任务拆解为多个有序、可执行、目标明确的子步骤。
拆解规则:
1. 步骤必须按执行顺序排列,前一步的结果可以作为后一步的输入
2. 每个步骤必须是独立可执行的,目标清晰,不能模糊
3. 步骤数量控制在3-8个之间,不要太细碎,也不要太笼统
4. 最后一步必须是「汇总所有步骤的结果,生成最终的完整答案」
5. 严格基于用户的原始任务拆解,不要添加无关的步骤
用户的原始任务:{input_task}
""")
try:
# 用结构化输出 保证步骤格式正确
# planner_chain = plan_prompt | main_llm.with_structured_output(TaskPlan)
# plan_result : TaskPlan = planner_chain.invoke({"input_task": input_task})
# plan_steps = plan_result.steps
##planner_chain = plan_prompt | main_llm | parser
##plan_result = planner_chain.invoke({"input_task": input_task})
##plan_steps = plan_result["steps"] # 注意:返回的是 dict
# 直接调用 LLM,不用 structured_output
response = main_llm.invoke(plan_prompt.format(input_task=input_task))
raw_content = response.content.strip()
print(f"LLM 原始输出:\n{raw_content[:500]}...")
# 尝试直接解析 JSON
try:
plan_result = json.loads(raw_content)
if isinstance(plan_result, dict) and "steps" in plan_result:
plan_steps = plan_result["steps"]
else:
raise ValueError("JSON 格式不符合预期")
except (json.JSONDecodeError, ValueError):
# 如果失败,尝试从 Markdown 中提取 JSON
json_match = re.search(r'\{[^{}]*"steps"[^{}]*.∗?[ ^ {}] * \}', raw_content, re.DOTALL)
if json_match:
plan_result = json.loads(json_match.group())
plan_steps = plan_result["steps"]
else:
# 最后兜底:从列表中提取步骤
plan_steps = re.findall(r'\d+\.\s*\*\*([^*]+)\*\*', raw_content)
if not plan_steps:
plan_steps = re.findall(r'\d+\.\s*(.+?)(?=\n\d+\.|\n*$)', raw_content, re.DOTALL)
plan_steps = [s.strip() for s in plan_steps if s.strip()]
print(f"✅️ 任务拆解完成,共{len(plan_steps)}个步骤")
for i, step in enumerate(plan_steps):
print(f" 步骤{i + 1}:{step}")
# print(f"✅️ 任务拆解完成,共{len(plan_steps)}个步骤")
# for i, step in enumerate(plan_steps):
# print(f" 步骤{i + 1}: {step}")
except Exception as e:
print(f"❌️ 任务规划失败:{str(e)}")
error = str(e)
plan_steps = []
return {
"plan_steps": plan_steps,
"current_step_index": 0,
"loop_count": loop_count + 1,
"error": error
}
# 执行节点: 执行当前单步任务
def execute_node(state: TaskPlanState):
"""执行节点: 执行当前步骤, 输出步骤结果"""
current_index = state["current_step_index"]
plan_steps = state["plan_steps"]
past_steps = state["past_steps"]
loop_count = state["loop_count"]
error = None
# 边界判断:所有步骤已执行完成
if current_index >= len(plan_steps):
return {
"current_step_result": "所有步骤已执行完成",
"loop_count": loop_count + 1
}
# 获取当前要执行的步骤
current_step = plan_steps[current_index]
print(f'\n-- 🚀 执行节点:执行步骤{current_index+1}/{len(plan_steps)} --')
print(f"当前步骤:{current_step}")
# 执行prompt :聚焦单步目标,结合已完成的步骤结果
execute_prompt = ChatPromptTemplate.from_template("""
你是专业的任务执行专家,需要严格按照当前步骤的目标,完成该步骤的执行。
执行规则:
1. 仅完成当前步骤的目标,不要做超出步骤范围的事情
2. 可以参考之前已完成的步骤结果,保证上下文连贯
3. 输出内容要完整、准确、符合步骤目标
4. 如果步骤无法执行,直接说明原因,不要编造内容
当前步骤目标:{current_step}
已完成的步骤和结果:{past_steps}
""")
try:
# 执行当前步骤
response = main_llm.invoke(execute_prompt.format(
current_step=current_step,
past_steps=past_steps
))
step_result = response.content
print(f"✅️ 步骤执行完成,结果长度:{len(step_result)} 字符")
except Exception as e:
print(f"❌️ 步骤执行失败:{str(e)}")
# 降级到备用LLM
try:
print("🔄 切换到备用LLM重试")
response = backup_llm.invoke(execute_prompt.format(
current_step=current_step,
past_steps=past_steps
))
step_result = response.content
error = None
except Exception as e2:
step_result = f"步骤执行失败:{str(e2)}"
error = str(e2)
return {
"current_step_result": step_result,
"loog_count": loop_count + 1,
"error": error
}
# 校验节点:检查步骤执行结果
def validate_node(state: TaskPlanState):
"""检验节点:检查当前步骤的执行结果是否合格,决定下一步走向"""
print("\n-- ✅️ 执行节点:结果校验 --")
current_index = state["current_step_index"]
current_step = state["plan_steps"][current_index]
step_result = state["current_step_result"]
past_steps = state["past_steps"]
loop_count = state["loop_count"]
error = state["error"]
# 先处理错误
if error:
print(f'❌️ 步骤执行错误,错误信息:{error}')
return {
"loop_count": loop_count + 1,
"validate_result": "failed",
}
# 校验prompt: 判断结果是否符合步骤目标
validate_prompt = ChatPromptTemplate.from_template("""
你是严格的结果校验员,需要判断当前步骤的执行结果是否符合步骤目标。
判断规则:
1. 结果是否完整覆盖了步骤的所有要求
2. 结果是否准确、无编造内容
3. 结果是否可以作为后续步骤的输入
4. 仅输出「合格」或「不合格」,不要输出其他内容
步骤目标:{current_step}
执行结果:{step_result}
""")
try:
response = main_llm.invoke(validate_prompt.format(
current_step=current_step,
step_result=step_result
))
validate_result = response.content.strip()
print(f"校验结果:{validate_result}")
except Exception as e:
print(f"⚠️ 校验调用失败,默认按合格处理")
validate_result = "合格"
# 校验合格:把当前步骤和结果加入已完成列表,索引+1
if validate_result == "合格":
return {
"past_steps": [(current_step, step_result)],
"current_step_index": current_index + 1,
"loop_count": loop_count + 1,
"validate_result": "passed"
}
# 校验不合格:不更新索引,重试当前步骤
else:
return {
"loop_count": loop_count + 1,
"validate_result": "failed"
}
# 重规划节点:动态调整计划
def replan_node(state: TaskPlanState):
"""重规划节点:当计划有缺陷时,动态调整步骤列表"""
print("\n-- 🔄 执行节点:重新规划 --")
input_task = state["input_task"]
current_plan = state["plan_steps"]
current_index = state["current_step_index"]
past_steps = state["past_steps"]
loop_count = state["loop_count"]
error = None
replan_prompt = ChatPromptTemplate.from_template("""
你是专业的任务规划专家,需要根据已执行的情况,调整原有的任务计划。
原始任务:{input_task}
原有计划:{current_plan}
已执行完成的步骤:{past_steps}
当前执行到第 {current_index} 步,发现原计划有缺陷,需要调整。
要求:
1. 保留已执行完成的步骤,不要修改
2. 调整后续未执行的步骤,解决原计划的缺陷
3. 输出完整的新计划,包含已执行的步骤和调整后的后续步骤
4. 最后一步必须是「汇总所有步骤的结果,生成最终的完整答案」
""")
try:
# replan_chain = replan_prompt | main_llm.with_structured_output(TaskPlan)
# new_plan: TaskPlan = replan_chain.invoke({
# "input_task": input_task,
# "current_plan": current_plan,
# "past_steps": past_steps,
# "current_index": current_index,
# })
# new_steps = new_plan.steps
# print(f"✅️ 重规划完成,新计划共{len(new_steps)}个步骤")
response = main_llm.invoke(replan_prompt.format(
input_task=input_task,
current_plan=current_plan,
past_steps=past_steps,
current_index=current_index
))
raw_content = response.content.strip()
print(f"replan_node LLM 原始输出:\n{raw_content[:500]}...")
# 尝试直接解析 JSON
try:
new_plan = json.loads(raw_content)
if isinstance(new_plan, dict) and "steps" in new_plan:
new_steps = new_plan["steps"]
else:
raise ValueError("JSON 格式不符合预期")
except (json.JSONDecodeError, ValueError):
# 方法2:从文本中提取 JSON 片段
json_match = re.search(r'{[^{}]*"steps"[^{}]*.∗?[ ^ {}] *}', raw_content, re.DOTALL)
if json_match:
try:
new_plan = json.loads(json_match.group())
new_steps = new_plan["steps"]
except:
pass
new_steps = [s.strip() for s in new_steps if s.strip()]
if not new_steps:
new_steps = current_plan
except Exception as e:
print(f"❌️ 重规划失败:{str(e)}")
error = str(e)
new_steps = current_plan
return {
"plan_steps": new_steps,
"loop_count": loop_count + 1,
"error": error
}
# 汇总节点:生成最终答案
def summarize_node(state: TaskPlanState):
"""汇总节点:所有步骤完成后,汇总结果生成最终答案"""
print(f'\n-- 📝执行节点,结果汇总 --')
input_task = state["input_task"]
past_steps = state["past_steps"]
loop_count = state["loop_count"]
summarize_prompt = ChatPromptTemplate.from_template("""
你是专业的内容汇总专家,需要基于所有步骤的执行结果,生成最终的完整答案。
原始任务:{input_task}
所有步骤的执行结果:{past_steps}
要求:
1. 完整覆盖所有步骤的核心内容,符合原始任务的要求
2. 结构清晰、逻辑连贯、格式规范
3. 内容准确,不添加编造的信息
4. 语言通顺,符合中文表达习惯
""")
try:
response = main_llm.invoke(summarize_prompt.format(
input_task=input_task,
past_steps=past_steps
))
final_answer = response.content.strip()
print(f"✅️ 最终答案生成完成")
except Exception as e:
print(f"❌️ 汇总失败:{str(e)}")
final_answer = f"汇总失败:{str(e)}, 已完成步骤的结果:{past_steps}"
return {
"final_answer": final_answer,
"messages":[AIMessage(content=final_answer)],
"loop_count": loop_count + 1
}
# 条件路由逻辑 流程控制核心
def should_continue_after_plan(state: TaskPlanState) -> Literal["execute", "end"]:
"""规划完成后,判断是执行还是结束"""
# 规划失败 直接结束
if state["error"] or len(state["plan_steps"]) == 0:
return "end"
# 规划成功 进入执行
return "execute"
def should_continue_after_validate(state: TaskPlanState) -> Literal["execute", "replan", "summarize", "end"]:
"""校验完成后 判断下一步走向"""
loop_count = state["loop_count"]
validate_result = state["validate_result"]
current_index = state["current_step_index"]
total_steps = len(state["plan_steps"])
max_retry = settings.MAX_RETRY_COUNT
max_loop = settings.MAX_LOOP_COUNT
# 防止死循环 超过最大循环次数直接结束
if loop_count > max_loop:
print("⚠️ 超过最大循环次数,强制结束")
return "end"
# 校验失败 判断是重试还是重规划
if validate_result == "failed":
# 重试次数未达到上线 重试当前步骤
if state["current_step_result"].count("失败") < max_retry:
print("🔄 步骤执行不合格,重试当前步骤")
return "execute"
# 重试多次失败 重新规划
else:
print("🔄 多次重试失败,重新规划任务")
return "replan"
# 校验合格 判断是否还有下一个步骤
if current_index < total_steps:
# 还有未执行的步骤 继续执行
print("👉 步骤执行合格 进入下一个步骤")
return "execute"
else:
# 所有步骤执行完成 进入汇总
print("✅️ 所有步骤执行完成,进入结果汇总")
return "summarize"
# 构建图与编译
def build_task_plan_agent():
"""构建多步骤任务规划Agent"""
builder = StateGraph(TaskPlanState)
# 添加所有节点
builder.add_node("plan", plan_node)
builder.add_node("execute", execute_node)
builder.add_node("validate", validate_node)
builder.add_node("replan", replan_node)
builder.add_node("summarize", summarize_node)
# 定义与流程
# 入口: 开始 -> 规划节点
builder.add_edge(START, "plan")
# 规划完成后的条件路由
builder.add_conditional_edges(
"plan",
should_continue_after_plan,
{
"execute": "execute",
"end": END
}
)
# 执行完成 校验节点
builder.add_edge("execute", "validate")
# 重新规划完成 执行节点
builder.add_edge("replan", "execute")
# 校验完成后的 条件路由
builder.add_conditional_edges(
"validate",
should_continue_after_validate,
{
"execute": "execute",
"replan": "replan",
"summarize": "summarize",
"end": END
}
)
# 汇总完成 结束
builder.add_edge("summarize", END)
# 编译图 带持久化
# 开发环境 用MemorySaver 生产环境用RedisSaver
checkpointer = MemorySaver()
# checkpointer = RedisSaver("redis://localhost:6379/0")
return builder.compile(checkpointer=checkpointer)
# 全局Agent实例
task_agent = build_task_plan_agent()
# 测试运行
if __name__ == "__main__":
print("===== 🚀 LangGraph 多步骤任务规划Agent 启动 =====")
# 会话配置 同一个thread_id 可恢复会话 持久化执行状态
config = {
"configurable": {
"thread_id": "task_plan_session_001",
"user_id": "user_001"
}
}
# 测试用的复杂任务(可替换为任意复杂任务)
test_task = "写一份2026年北京地区个人所得税优化方案,包含最新政策解读、个税计算步骤、3个不同收入人群的完整计算示例、合法避税建议、风险提示"
# 初始化状态: 启动agent
initial_state = {
"input_task": test_task,
"user_id": "user_001",
"plan_steps": [],
"current_step_index": 0,
"past_steps": [],
"current_step_result": "",
"final_answer": "",
"loop_count": 0,
"error": None,
"messages": [HumanMessage(content=test_task)]
}
# 执行agent
result = task_agent.invoke(initial_state, config=config)
# 输出结果
print("\n" + "=" * 50)
print("📄 最终完整答案:")
print(result["final_answer"])
print("=" * 50)五、核心能力与运行效果
1. 核心能力
- ✅ 自动任务拆解:将复杂任务自动拆解为有序的可执行步骤
- ✅ 分步串行执行:按计划顺序执行每个步骤,保证上下文连贯
- ✅ 结果自动校验:每步执行后自动校验结果,不合格自动重试
- ✅ 动态重规划:多次重试失败后自动调整计划,适配执行中的变化
- ✅ 错误降级处理:主 LLM 失败自动切换备用 LLM,避免全局崩溃
- ✅ 会话持久化:支持服务重启后恢复任务执行进度,断点续跑
- ✅ 防死循环保护:最大循环次数、最大重试次数双重防护
2. 典型运行流程
✅️ Redis store 索引已创建
===== 🚀 LangGraph 多步骤任务规划Agent 启动 =====
-- 📋执行节点:任务规划 --
LLM 原始输出:
1. **解读2026年北京地区个税最新政策**
收集并整理2026年适用的国家及北京地区个人所得税法律法规,重点分析税率表、起征点、专项附加扣除标准及北京地区特有的社保公积金缴纳比例上限。
2. **梳理个税计算标准步骤与公式**
基于最新政策,明确北京地区个税计算的核心逻辑,列出税前收入、社保公积金扣除、专项附加扣除、应纳税所得额及最终税款的计算公式和顺序。
3. **选取3类典型收入人群并进行完整计算演示**
设定低收入、中等收入、高收入三个具体人群画像(包含薪资结构、专项扣除情况),代入上述计算步骤,分别演示并得出其2026年的个税计算结果。
4. **制定合法合规的个税优化与避税建议**
结合政策解读和计算结果,针对不同收入层级,提出利用专项附加扣除、年终奖计税方式选择、公积金比例调整等手段的合法节税具体策略。
5. **整理个税筹划过程中的风险提示**
分析在执行上述优化建议时可能面临的税务稽查风险、政策变动风险及合规红线,列出具体的注意事项。
6. **汇总所有步骤的结果,生成最终的完整答案**
将政策解读、计算步骤、三个示例...
-- 🚀 执行节点:执行步骤1/6 --
当前步骤:解读2026年北京地区个税最新政策
✅️ 步骤执行完成,结果长度:110 字符
-- ✅️ 执行节点:结果校验 --
校验结果:不合格
🔄 步骤执行不合格,重试当前步骤
-- 🚀 执行节点:执行步骤1/6 --
当前步骤:解读2026年北京地区个税最新政策
✅️ 步骤执行完成,结果长度:112 字符
-- ✅️ 执行节点:结果校验 --
⚠️ 校验调用失败,默认按合格处理
👉 步骤执行合格 进入下一个步骤
-- 🚀 执行节点:执行步骤2/6 --
当前步骤:梳理个税计算标准步骤与公式
✅️ 步骤执行完成,结果长度:1451 字符
-- ✅️ 执行节点:结果校验 --
校验结果:合格
👉 步骤执行合格 进入下一个步骤
-- 🚀 执行节点:执行步骤3/6 --
当前步骤:选取3类典型收入人群并进行完整计算演示
✅️ 步骤执行完成,结果长度:2742 字符
-- ✅️ 执行节点:结果校验 --
校验结果:合格
👉 步骤执行合格 进入下一个步骤
-- 🚀 执行节点:执行步骤4/6 --
当前步骤:制定合法合规的个税优化与避税建议
✅️ 步骤执行完成,结果长度:2355 字符
-- ✅️ 执行节点:结果校验 --
校验结果:合格
👉 步骤执行合格 进入下一个步骤
-- 🚀 执行节点:执行步骤5/6 --
当前步骤:整理个税筹划过程中的风险提示
✅️ 步骤执行完成,结果长度:2116 字符
-- ✅️ 执行节点:结果校验 --
校验结果:合格
👉 步骤执行合格 进入下一个步骤
-- 🚀 执行节点:执行步骤6/6 --
当前步骤:汇总所有步骤的结果,生成最终的完整答案
✅️ 步骤执行完成,结果长度:3699 字符
-- ✅️ 执行节点:结果校验 --
校验结果:合格
✅️ 所有步骤执行完成,进入结果汇总
-- 📝执行节点,结果汇总 --
✅️ 最终答案生成完成
==================================================
📄 最终完整答案:
**2026年北京地区个人所得税优化方案(基于现行政策编制)**
**特别说明:**
鉴于当前时间为2024年,2026年北京地区个人所得税的具体政策尚未由国家税务总局或北京市税务局发布。根据专业准则,无法对未来政策进行预测或编造。因此,本方案严格依据**现行有效(2024年)**的《中华人民共和国个人所得税法》及相关政策法规编制,涵盖标准计算逻辑、典型人群案例演示、合法合规的优化建议及风险提示,可作为当前及未来的基础参考框架。
---
### 一、 政策背景与计算标准
#### 1. 政策解读基础
目前北京地区执行全国统一的个人所得税法。核心税制为“综合与分类相结合”,将工资薪金、劳务报酬、稿酬和特许权使用费四项收入纳入综合所得,按年度合并计算个人所得税。
#### 2. 个税计算标准步骤与公式
**核心计算公式:**
> **应纳税额 = (全年收入总额 - 减除费用 - 专项扣除 - 专项附加扣除 - 其他扣除)× 适用税率 - 速算扣除数**
**详细计算步骤:**
1. **确定全年收入总额:**
* 合并计算以下四项所得:
* 工资、薪金所得
* 劳务报酬所得(收入额 = 收入 × (1-20%))
* 稿酬所得(收入额 = 收入 × (1-20%) × 70%)
* 特许权使用费所得(收入额 = 收入 × (1-20%))
2. **计算各项扣除:**
* **减除费用(起征点):** 标准为60,000元/年(5,000元/月)。
* **专项扣除:** 个人缴纳的“三险一金”(社保+公积金)。
* **专项附加扣除:** 包括子女教育、3岁以下婴幼儿照护、继续教育、大病医疗、住房贷款利息、住房租金、赡养老人等7项。
* **其他扣除:** 个人养老金、税优健康险等符合国家规定的项目。
3. **确定应纳税所得额:**
* 应纳税所得额 = 全年收入总额 - 60,000 - 专项扣除 - 专项附加扣除 - 其他扣除
* *注:若结果小于0,则无需纳税。*
4. **匹配税率与速算扣除数:**
根据应纳税所得额,对照下表确定税率:
| 级数 | 全年应纳税所得额 | 税率 (%) | 速算扣除数 (元) |
| :--- | :--- | :--- | :--- |
| 1 | 不超过36,000元的部分 | 3 | 0 |
| 2 | 超过36,000元至144,000元的部分 | 10 | 2,520 |
| 3 | 超过144,000元至300,000元的部分 | 20 | 16,920 |
| 4 | 超过300,000元至420,000元的部分 | 25 | 31,920 |
| 5 | 超过420,000元至660,000元的部分 | 30 | 52,920 |
| 6 | 超过660,000元至960,000元的部分 | 35 | 85,920 |
| 7 | 超过960,000元的部分 | 45 | 181,920 |
5. **计算最终税额:**
应纳税额 = 应纳税所得额 × 适用税率 - 速算扣除数
---
### 二、 典型人群个税计算示例
以下选取三类典型收入人群,基于上述标准进行完整计算演示:
#### 1. 低收入职场新人(无需纳税)
* **人员画像:** 刚毕业,年薪8万,租房,独生子女需赡养老人。
* **收入与扣除数据:**
* 全年工资收入:80,000元
* 三险一金(个人部分):12,000元
* 专项附加扣除:租房(12,000元) + 赡养老人(24,000元) = 36,000元
* **计算过程:**
* 应纳税所得额 = 80,000 - 60,000(起征点) - 12,000(三险一金) - 36,000(专项附加) = **-28,000元**
* **结果:** 应纳税所得额为负,**全年应纳税额为 0 元**。
#### 2. 中等收入家庭(适用20%税率)
* **人员画像:** 企业中层,年薪30万,有房贷、有子女、独生子女赡养老人。
* **收入与扣除数据:**
* 全年工资收入:300,000元
* 三险一金(个人部分):45,000元
* 专项附加扣除:子女教育(12,000) + 房贷利息(12,000) + 赡养老人(24,000) = 48,000元
* **计算过程:**
* 应纳税所得额 = 300,000 - 60,000 - 45,000 - 48,000 = **147,000元**
* 对应级数:第3级(144,000元至300,000元),税率20%,速算扣除数16,920元。
* 应纳税额 = 147,000 × 20% - 16,920 = **12,480元**
* **结果:** 全年应纳税额 **12,480 元**。
#### 3. 高收入自由职业者(适用25%税率)
* **人员画像:** 独立撰稿人,劳务报酬50万,稿酬10万,自行缴纳社保,非独生子女赡养老人。
* **收入与扣除数据:**
* 劳务报酬收入额:500,000 × (1-20%) = 400,000元
* 稿酬收入额:100,000 × (1-20%) × 70% = 56,000元
* 全年收入总额:456,000元
* 扣除项:三险一金(10,000) + 赡养老人(12,000,分摊50%) = 22,000元
* **计算过程:**
* 应纳税所得额 = 456,000 - 60,000 - 22,000 = **374,000元**
* 对应级数:第4级(300,000元至420,000元),税率25%,速算扣除数31,920元。
* 应纳税额 = 374,000 × 25% - 31,920 = **61,580元**
* **结果:** 全年应纳税额 **61,580 元**。
---
### 三、 合法合规的个税优化与避税建议
在法律允许的框架内,通过合理规划降低税负:
1. **用足“专项附加扣除”**
* **全员申报:** 确保符合条件的7项扣除(子女教育、3岁以下婴幼儿照护、赡养老人、住房租金/贷款利息、继续教育、大病医疗)应扣尽扣。
* **分配策略:** 夫妻间的扣除项(如子女教育、房贷利息、婴幼儿照护)建议由**收入较高**的一方全额扣除,以最大化边际税率效益。
2. **优化全年一次性奖金计税**
* **选择方式:** 全年一次性奖金单独计税优惠政策已延续至2027年底。在年度汇算清缴时,应在个税APP中分别试算“单独计税”和“并入综合所得计税”,选择税额较低的一种。
* **避开陷阱:** 注意税率临界点,避免因多发少量奖金导致税率跳档,出现“多发一元,少拿几千”的现象。
3. **充分利用“其他扣除”政策**
* **个人养老金:** 每年最高12,000元额度,可在税前扣除,享受递延纳税优惠。
* **税优健康险:** 购买符合规定的商业健康保险,每年最高可税前扣除2,400元。
* **企业年金/职业年金:** 积极参与单位计划,单位缴费和个人缴费均在一定标准内不计入当期应纳税所得额。
4. **优化“三险一金”缴纳**
* 确保公司按照实际工资全额缴纳社保和公积金。虽然个人到手现金可能暂时减少,但公积金属于个人资产,且全额缴纳增加了税前扣除额,降低了当期个税。
5. **自由职业者收入结构优化**
* 对于高收入自由职业者,若业务稳定,可考虑成立个体工商户或个人独资企业,将“劳务报酬所得”转化为“经营所得”,在扣除成本、费用后纳税。
* *注意:* 必须有真实的业务场景,严禁利用空壳企业洗钱,且需关注“核定征收”政策收紧的风险。
---
### 四、 风险提示
在执行上述筹划时,必须警惕以下风险以确保合规:
1. **专项附加扣除申报风险**
* **虚假申报:** 虚构租房合同、填报不存在的子女教育信息等。税务部门已与多部门联网核查,虚假申报将面临补税、滞纳金及信用降级风险。
* **分配冲突:** 夫妻双方重复扣除同一项目(如均扣除100%子女教育),会导致申报失败或税务稽查。
2. **全年一次性奖金计税风险**
* **税率跳档:** 未经测算直接发放奖金,可能导致税负剧增,实际到手收入减少。
* **政策时效:** 年终奖单独计税政策目前延续至2027年底,未来若政策调整,需及时应对。
3. **自由职业者与经营所得风险**
* **业务真实性:** 注册空壳公司、虚开发票属于违法犯罪行为。必须确保“四流合一”(合同流、发票流、资金流、业务流)。
* **征收方式变动:** 若从“核定征收”改为“查账征收”,税负可能大幅上升,需做好财务规范。
4. **法律合规底线**
* 严禁阴阳合同、私卡收款等逃税手段。所有筹划必须在《税收征收管理法》允许的范围内进行,区分合法的“节税”与违法的“逃税”。
**总结:** 个税筹划的核心在于“合规”。纳税人应充分利用国家给予的扣除优惠和税收政策,同时保持对政策变动的关注,确保个人税务安全。
==================================================六、进阶优化方向
1. 集成工具调用能力
给执行节点集成工具调用能力,让 Agent 可以在执行步骤时调用搜索、代码执行、文档检索等工具,比如:
# 给执行器LLM绑定工具
execute_llm = main_llm.bind_tools([web_search_tool, python_execute_tool])
2. 人工介入能力
在关键步骤增加人工审核节点,用 LangGraph 的interrupt功能暂停工作流,等待人工确认 / 修改后继续执行,适合高风险的任务场景。
3. 并行步骤执行
对于无依赖关系的步骤,用 LangGraph 的并行节点能力同时执行多个步骤,提升任务执行效率。
4. 多智能体分工
将规划、执行、校验拆分为独立的智能体,比如「项目经理 Agent 负责规划」、「专家 Agent 负责执行」、「审核 Agent 负责校验」,实现更专业的多智能体协作。
5. 步骤结果持久化
将每个步骤的执行结果存入数据库 / 向量库,实现任务执行的全链路可追溯、可复盘。
七、什么时候应该使用多步骤任务规划 Agent?
当你的场景符合以下特征时,优先使用这套 Plan-and-Execute 架构:
- 任务复杂,无法一步完成:比如写研究报告、项目方案、完整的数据分析、多文档深度分析
- 需要全局视角和长期规划:任务有明确的最终目标,需要提前规划执行路径,避免走一步看一步导致偏离目标
- 步骤之间有明确的依赖关系:前一步的结果是后一步的输入,需要按顺序执行
- 需要高可观测性和可调试性:生产环境中需要知道任务执行到哪一步、每一步的结果是什么,方便定位问题
- 长周期任务,需要断点续跑:任务执行时间长,需要支持服务重启后从断点继续执行,无需从头开始
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)