
【开源】Yszen AI:一个开箱即用的 Harness 架构 Agent 脚手架(FastAPI + LangGraph + React)
Yszen AI 是一个把 Anthropic 的 Harness 架构与 Skill 渐进式披露思想完整落地的全栈 Agent 项目。后端用 FastAPI + LangGraph 实现状态机驱动的多轮工具调用,前端用 React 18 + shadcn/ui 实现现代化对话界面,开箱即用、生产可部署。
Yszen AI 是一个把 Anthropic 的 Harness 架构与 Skill 渐进式披露思想完整落地的全栈 Agent 项目。后端用 FastAPI + LangGraph 实现状态机驱动的多轮工具调用,前端用 React 18 + shadcn/ui 实现现代化对话界面,开箱即用、生产可部署。
源码地址:https://gitee.com/xcodinglifex/yszen-ai 觉得有用的话欢迎点个 ⭐ Star,也欢迎 PR / Issue。
一、为什么又要造一个 Agent 项目?
最近半年 Agent 框架井喷,但真正动手做项目时仍会被三类问题困扰:
- 上下文爆炸 —— Skill 一多就把窗口塞满,一个 prompt 就要 30k tokens
- 流程不可观测 —— 多轮工具调用之间到底发生了什么,只能看日志猜
- 业务接入慢 —— 想接企微/微信/Web,每一个都要从头写一遍
Anthropic 在工程实践博客里提出的 Harness 架构 正好对症下药:
- 🎯 渐进式披露:Skill 元数据常驻、正文按需加载,启动时只占百来 tokens
- 🛠️ 工具优先:Agent 只通过工具与世界交互,能力清晰可枚举
- 🔁 可观测:思考、调用、结果全部走事件总线,前端实时拿到流
Yszen AI 就是把这三条原则完整落地的开源脚手架,适合直接拿来当你下一个 AI 项目的起点。
二、整体架构一图看懂
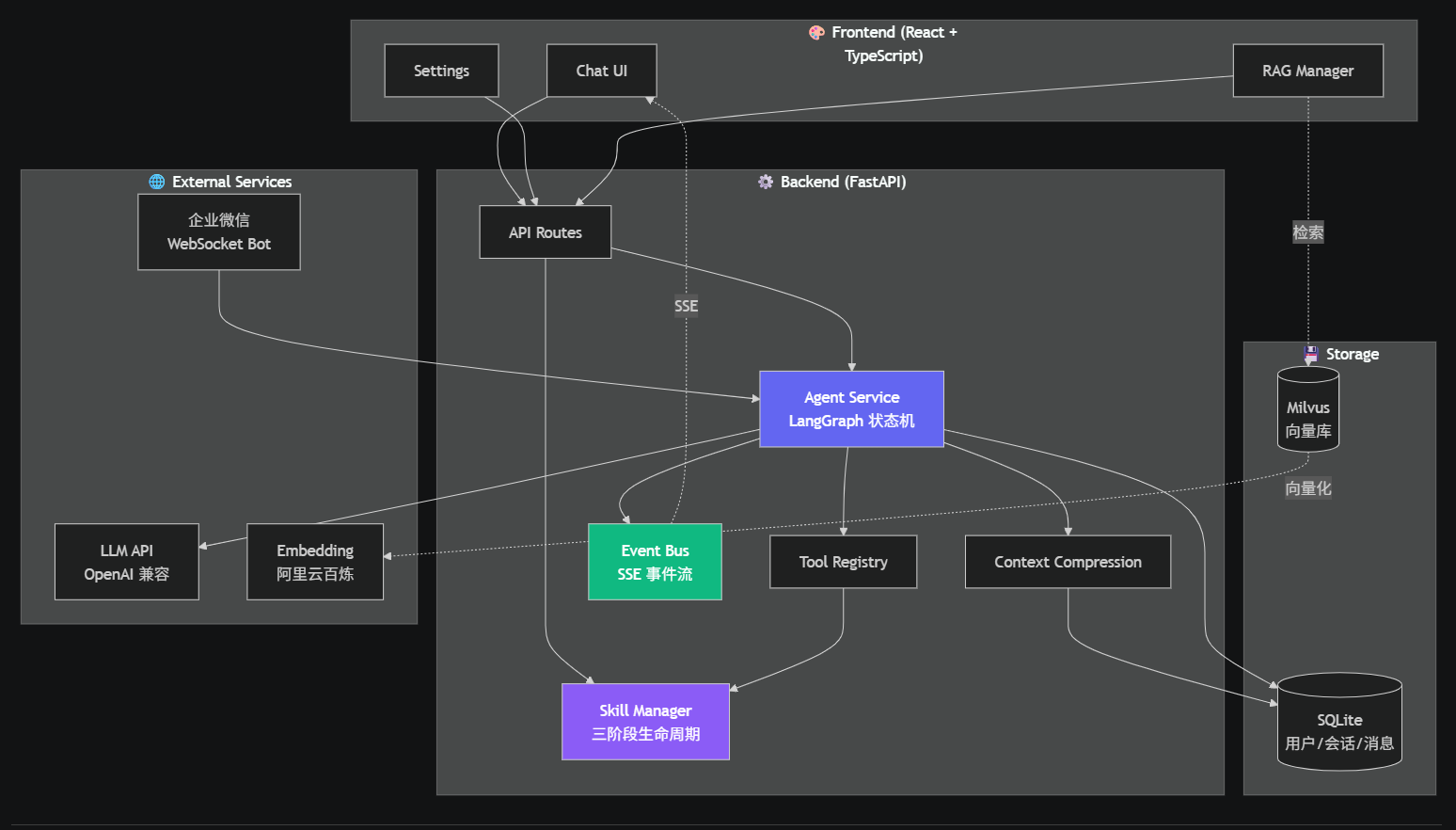
整个系统分三层:
- 前端 Chat UI 走 SSE 实时拿后端推流的事件
- 后端 Agent Service 是 LangGraph 状态机,每一步都把事件发给 Event Bus
- 存储 SQLite 跑用户/会话,Milvus 跑 RAG 向量库
三、核心特性一览
| 模块 | 关键能力 |
|---|---|
| 🧠 智能 Agent | LangGraph 状态机,多轮工具调用,思考过程逐字流式输出 |
| 🧩 Skill 框架 | 三阶段生命周期(Discovery / Activation / Execution) |
| 📚 上下文管理 | 自动摘要压缩 + 消息级缓存 + Token 预算 |
| 🔧 工具系统 | 内置 Python 执行器、API 调用器、文件读取器,支持自定义注册 |
| 🔍 RAG | Milvus + 阿里云百炼 Embedding/Rerank |
| 💼 企微 Bot | WebSocket 接入企业微信智能机器人 |
| 🔐 多用户 | JWT + 用户级 API Key 覆盖 |
| 🎨 现代前端 | React 18 + shadcn/ui + 深色模式 + i18n |
| 🐳 一键部署 | Dockerfile + docker-compose |
四、Agent Loop:思考 → 调用 → 观察 → 再思考
整个 Agent 的工作流就是个标准的 ReAct 循环,但在工程上做了三件关键的事:
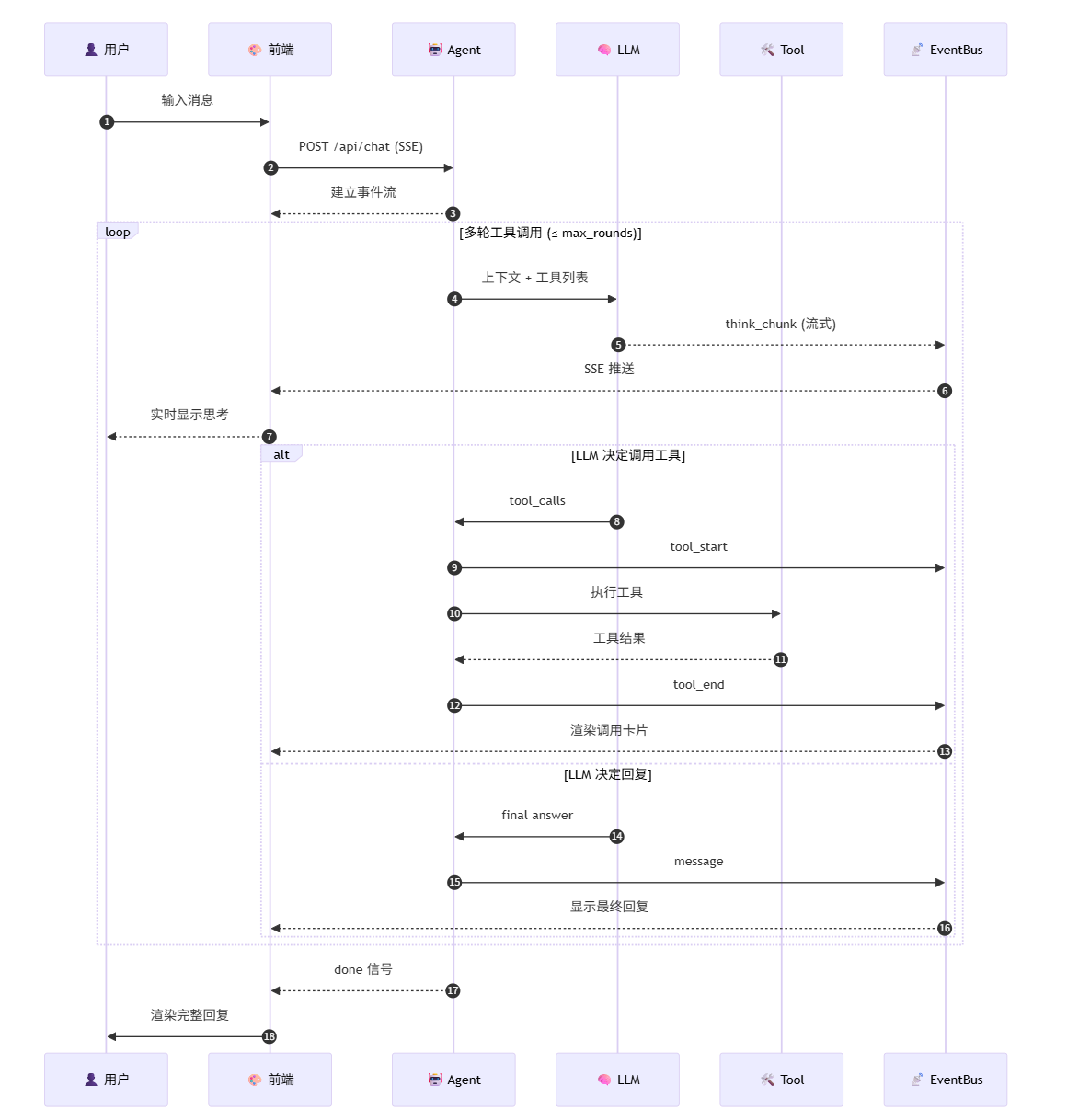
工程上的三个关键决定:
- 思考与正文分流 — 思考用
THINK_*事件,正文用MESSAGE_*事件,前端可以分开渲染折叠的"💡 思考中"卡片和正式回复气泡 - 中间轮 preamble 丢弃 — LLM 决定调工具前可能会"碎碎念"几句,这些内容直接在后端丢弃,避免闪现到 UI
- 最终轮逐字推流 —
response.content在 ainvoke 后用 8ms 间隔逐字推送,保留打字机效果
五、Skill 框架:本项目最有意思的地方
Skill 是 Yszen AI 最重要的扩展机制,灵感直接来自 Anthropic 的 Skill 生态。
三阶段生命周期

渐进式披露的好处:
- 启动阶段:只加载
name + description(~50 tokens / Skill),100 个 Skill 总开销也就 5k tokens - 匹配阶段:LLM 看到全部候选 → 选中一个或多个
- 执行阶段:才加载完整 SKILL.md 正文 + scripts + references + assets
这跟"一次性把所有能力塞进 system prompt"的方式比,Token 占用降低 1-2 个数量级。
创建一个 Skill 只需 3 步
1️⃣ 在 backend/skills/ 下建目录:
backend/skills/my-skill/
├── SKILL.md # 必需
├── scripts/ # 可选
├── references/ # 可选
└── assets/ # 可选
2️⃣ 写 SKILL.md:
---
name: my-skill
description: 当用户需要 XX 时使用。支持 YY,能输出 ZZ。
---
# 我的技能
## When to Use
描述触发场景。
## How It Works
1. 步骤一
2. 步骤二
3️⃣ 重启后端,自动生效
之后用户既可以直接说"帮我做 XX"(自然语言匹配),也可以输入 /my-skill(显式触发)。
六、三种部署方式,5 分钟跑起来
方式一:本地一键启动(推荐开发)
git clone https://gitee.com/xcodinglifex/yszen-ai.git
cd yszen-ai
cp .env.example .env
# 编辑 .env 填入 LLM API Key
make run
启动完访问:
- 前端:http://localhost:5173
- 后端 API 文档:http://localhost:8000/docs
方式二:分别启动
# 后端
cd backend && pip install -r requirements.txt
uvicorn app.main:app --reload --port 8000
# 前端(另开终端)
cd frontend && npm install && npm run dev
方式三:Docker(推荐生产)
cp .env.example .env
docker-compose up -d
容器跑起来后访问:
七、技术栈
后端:FastAPI 0.115 + LangChain 0.3 + LangGraph 0.2 + SQLite + Milvus 2.5 + JWT
前端:React 18 + TypeScript 5.6 + Vite 5 + shadcn/ui + TailwindCSS 4 + Zustand + TanStack Query
基础设施:Docker + Nginx
八、什么场景适合用?
✅ 适合
- 想快速搭一个企业内部 AI 助手(支持多用户、各自配 API Key)
- 想做一个垂直领域 Agent(用 Skill 框架封装领域能力)
- 想接企微/微信群机器人,不想从头写 SSE/Bot 逻辑
- 想学习/参考 Harness 架构的工程落地
❌ 不适合
- 只想跑一个 ChatGPT 镜像(过度设计)
- 需要重型多 Agent 编排(请用 CrewAI / AutoGen)
九、路线图
- 多 LLM 提供商支持(OpenAI / Anthropic / 通义千问 / DeepSeek)
- Skill 市场(在线浏览、一键安装)
- 工具沙箱(隔离 Python 执行环境)
- 多模态支持(图片、音频输入)
- OpenTelemetry 完整可观测
十、最后
整个项目从 0 到 1 的设计哲学是:
不重复造轮子,但要把别人的好轮子组装成一台能跑的车。
如果你正在做 AI 产品的 0→1,或者想找个学习 Harness/Skill/LangGraph 的真实项目,这个仓库应该会给你不少参考。
🔗 源码:https://gitee.com/xcodinglifex/yszen-ai 🌟 欢迎点 Star、提 Issue、交流架构思路
如果文章对你有帮助,点赞 + 收藏 + 关注支持一下,后续我会出系列拆解:
- 《手把手解析 Yszen AI 的 LangGraph 状态机》
- 《Skill 框架的渐进式披露:Token 是怎么省下来的》
- 《SSE 事件总线的工程实现:思考、工具、正文如何分流》
评论区聊聊你正在做的 Agent 项目!
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)