
【作品集】小红书社区搜索相关性智能审核打标
一、作品概览
作品名称
小红书社区搜索相关性智能审核打标 Copilot
作品类型
AI 业务应用落地 / 多模态审核打标 / N8N 自动化工作流 / 人机协作 Copilot
项目定位
本作品面向小红书社区搜索相关性审核打标场景,目标是通过大语言模型、多模态模型和自动化工作流,将原本依赖人工经验的搜索相关性判断流程,转化为一套可结构化分析、可批量运行、可复盘优化的 AI 辅助审核系统。
该项目不是单点调用大模型,而是围绕“query 与笔记内容是否相关、相关到什么程度、应该给几分”这一业务判断,搭建了从数据读取、query 拆解、多模态内容理解、规则匹配、分值计算、结果写入、人工复核到 bad case 迭代的完整流程。
我的角色
在项目中,我主要负责业务规则理解、流程拆解、Prompt 设计、N8N 工作流搭建、模型调用链路设计、数据清洗、评分逻辑实现、baseline 测算和 bad case 复盘。
二、项目背景与业务痛点
小红书社区搜索相关性审核的核心任务,是判断用户搜索词 query 与笔记内容之间的匹配程度,并按照业务规则输出相关性分值。笔记内容可能包含标题、正文、图片、视频、话题 tag、链接等多种信息。人工需要综合判断用户需求、内容主题、是否命中实体、是否满足限制条件,以及有效内容在整篇笔记中的占比。
原始人工流程存在以下问题:
- 内容阅读成本高:一条笔记可能包含长正文、多张图片,甚至长视频。
- 规则理解成本高:评分规则包含需求、实体、限制条件、主题占比、有效内容等多个维度。
- 人工一致性不足:不同作业人员对边缘 case 的理解存在差异,容易出现打分不一致。
- 培训周期长:新人需要理解大量规则和案例,爬坡成本高。
- 复盘成本高:当人工与 AI 或双盲标注结果不一致时,需要人工回看完整分析链路。
根据项目过程文档,该业务具有明显的人力密集型特征:作业人员需要长时间阅读和判断,日常复盘频繁,复杂规则会导致返工和标注差异。因此,本项目希望构建一个面向作业人员的 Copilot,把“人工阅读、主观分析、经验决策”转化为“AI 自动化处理、人机协同校验、过程可追溯”的新模式。
审核打标工作模式流程框架图
三、项目目标
项目目标分为业务目标和技术目标。
业务目标
第一阶段目标是达到 Copilot 级别:系统作为作业人员的轻量化智能辅助工具,帮助作业人员快速理解 query、拆解需求、判断笔记相关性,并给出可解释的评分建议。项目过程文档中明确提出,第一阶段希望实现业务提效 30% 以上。
第二阶段目标是向 Agent 级别演进:在 Copilot 辅助分析基础上,进一步实现部分业务动作的自动化执行,目标是实现 10% 以上的业务自动化操作。

图07:Copilot 业务目标示意图

图08:Agent 业务目标示意图
技术目标
技术目标包括:
- 构建 query 结构化解析能力。
- 构建正文、图片、视频等多模态内容理解能力。
- 将业务评分规则转化为可执行的流程节点。
- 将模型输出统一为 JSON 结构,方便后续计算和复核。
- 通过 N8N 实现可视化、可扩展、可复用的流程编排。
- 建立 baseline 测算和 bad case 归因机制。
- 为后续 Model Hub、RAG、Agent 自动化作业打基础。
四、整体方案设计
项目采用 Workflow 作为技术载体,围绕 N8N 搭建工作流驱动的模型协同体系。整体链路包括数据输入、规则拆解、模型分析、结果合并、评分计算和输出写入。
图09:Copilot 流程价值示意图
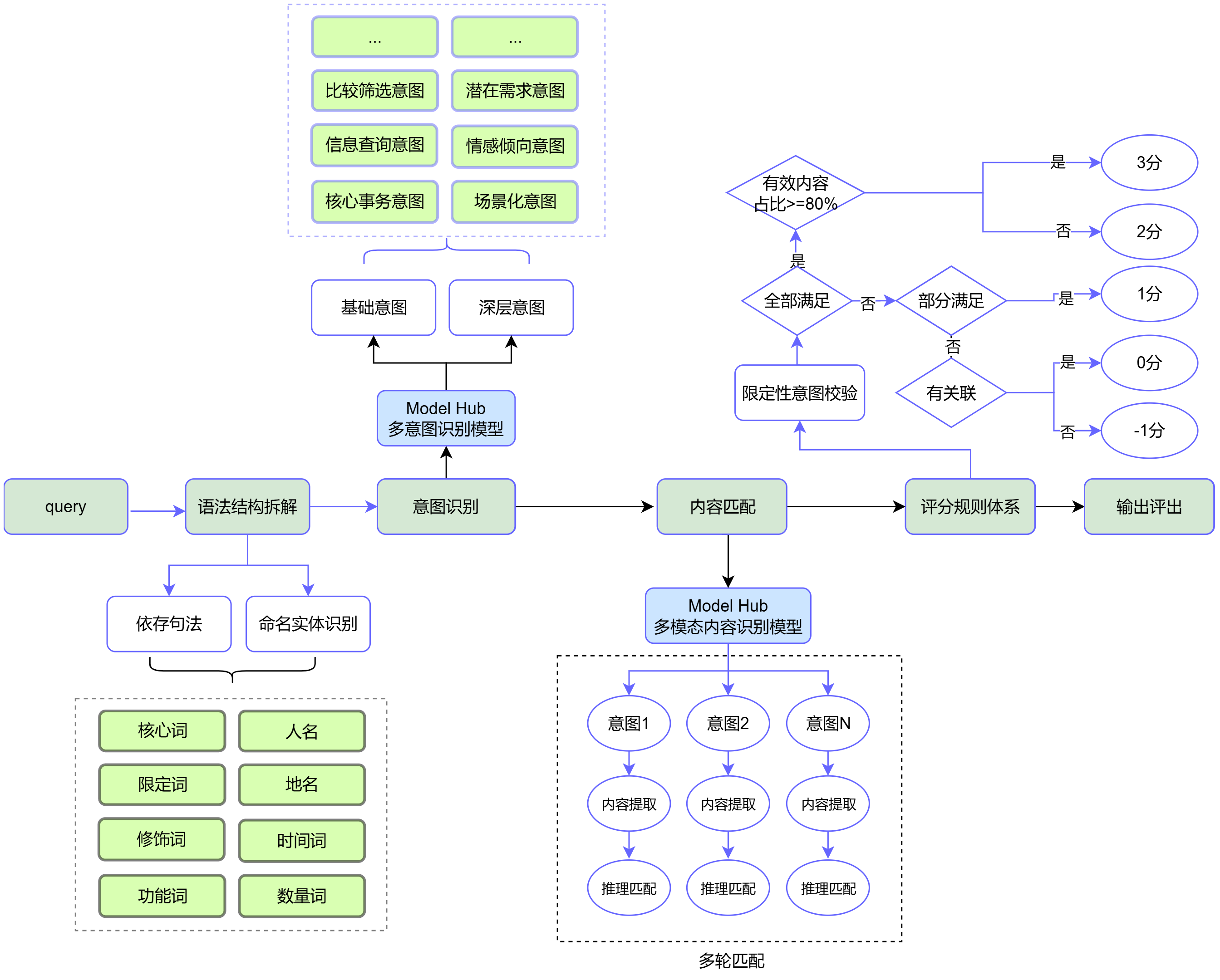
图12:Workflow 模型协同体系图
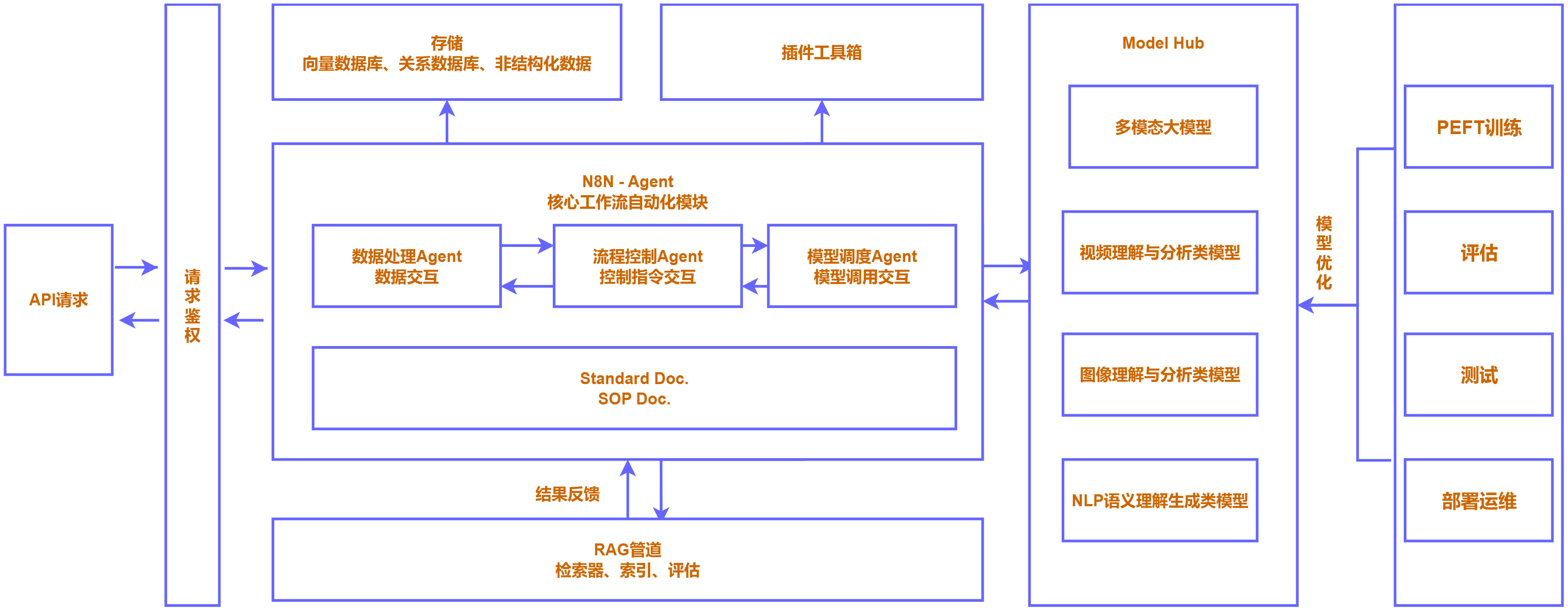
图13:Model Hub 技术架构图
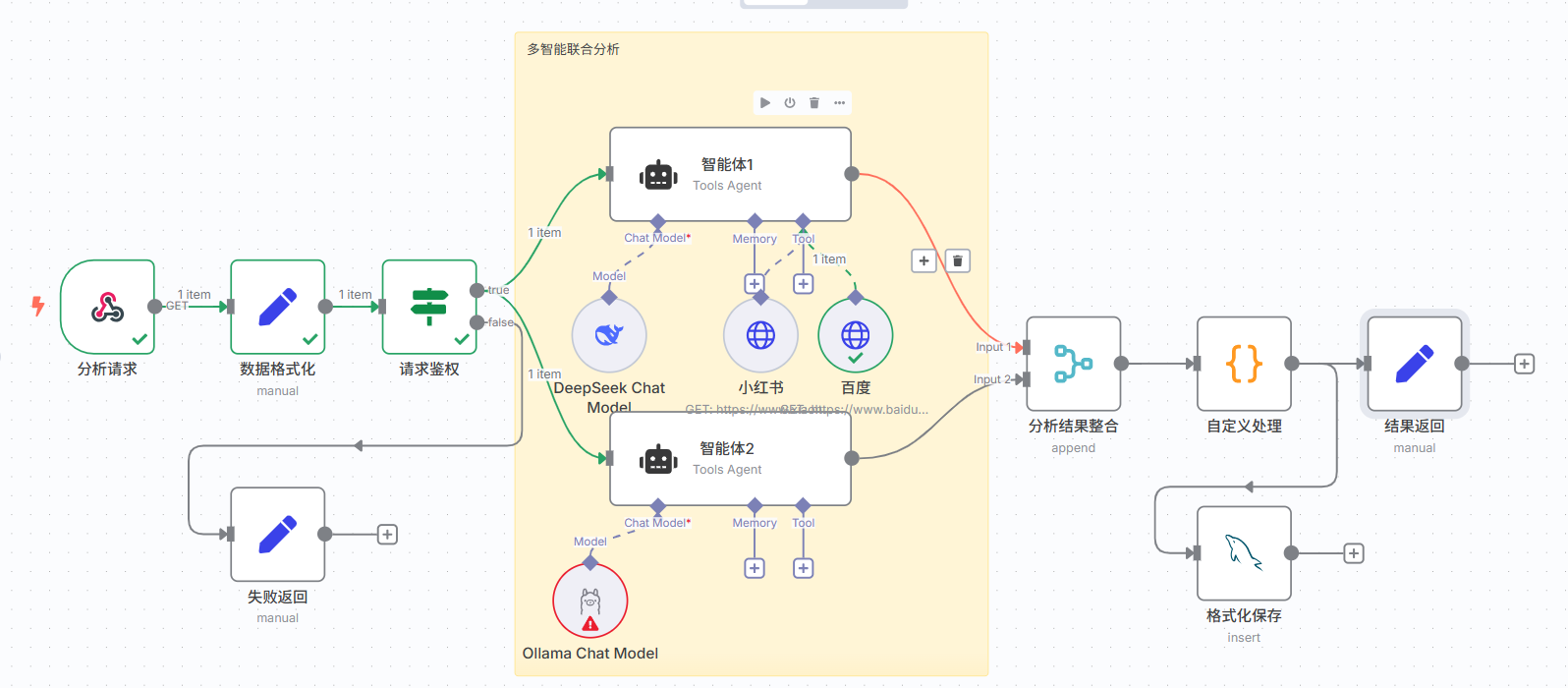
图14:N8N 工作流示意图
五、数据输入与处理对象
系统处理的数据主要包括:
- query:用户搜索词。
- title:笔记标题。
- content:笔记正文。
- file:图片或视频链接。
- tag:话题标签。
- 人工 score:人工评分结果。
- AI score:模型计算结果。
N8N 中通过 Code 节点对数据进行清洗,自动识别图片和视频文件链接。图片链接会被转换为模型可识别的 image_url 格式,视频链接会被转换为 video_url 格式。这样可以保证后续文本模型、多模态模型在统一的数据格式下工作。
项目过程文档中还记录了数据构建问题,例如业务数据抓取不完整、部分数据缺失结果信息、同张图片重复出现等。这些问题会直接影响 baseline 准确性,因此在项目中被列为后续优化点。
六、query 拆解框架
query 是整个评分流程的入口。系统首先需要判断 query 是否可理解,再判断它属于什么需求类型,并进一步拆解出主需、次需、实体和限制条件。
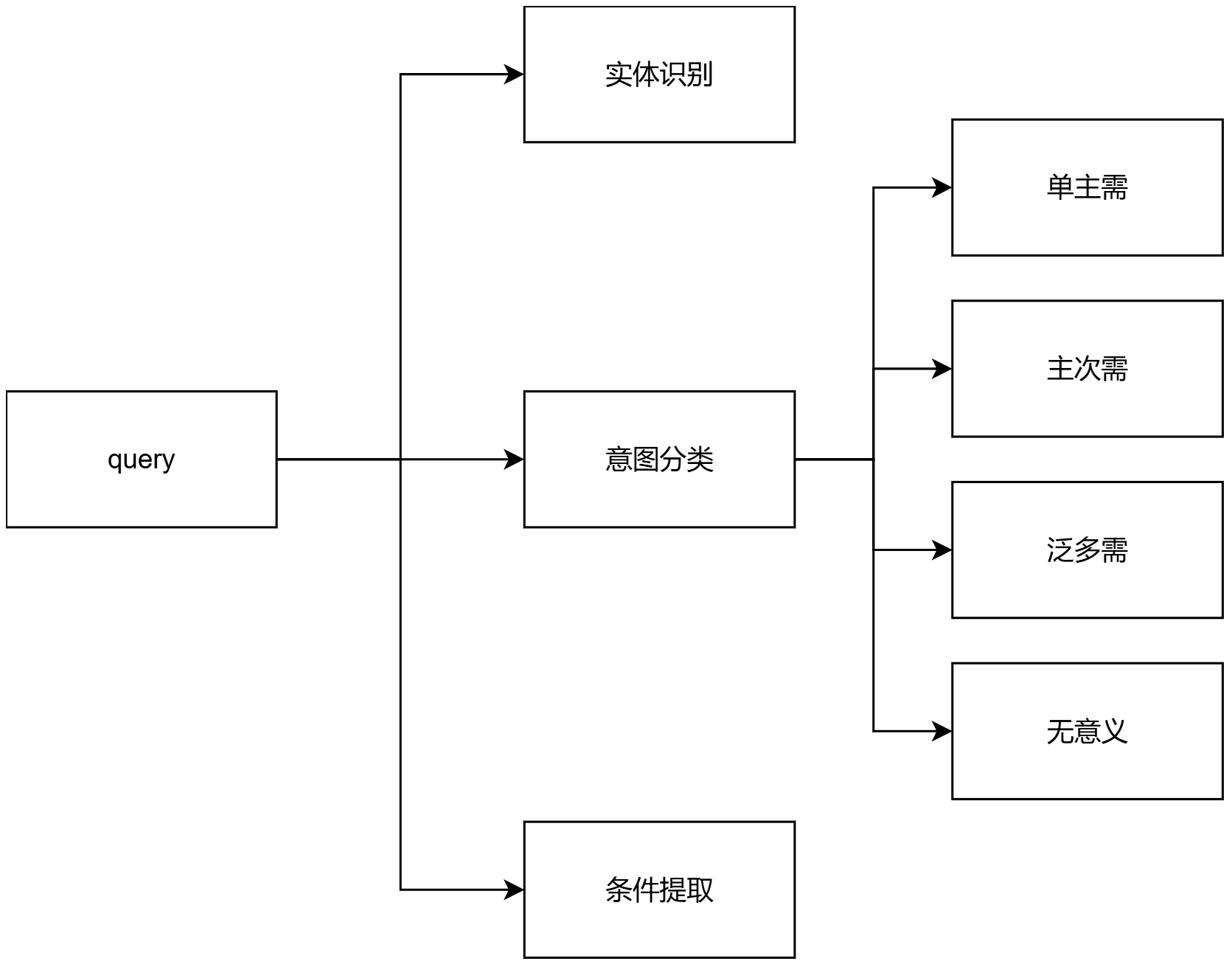
图01:Query 分解框架
1. query 可理解性判断
系统会先判断 query 是否符合基本语言表达规则,是否具有明确语义,是否能在正常认知范围内理解。如果 query 不可理解,则进入异常处理或降级流程。
2. 需求类型判断
项目中将 query 分为几类:
- 单主需:查询中只有一个明确、具体的需求。
- 主次需:一个主要需求附带一个或多个次要需求。
- 泛多需:包含多个需求,但没有明确主次。
- 无意义:无法识别有效需求。
在后续规则优化文档中,这套体系进一步整理为精准需求、多需求、泛多需求等分类方式。
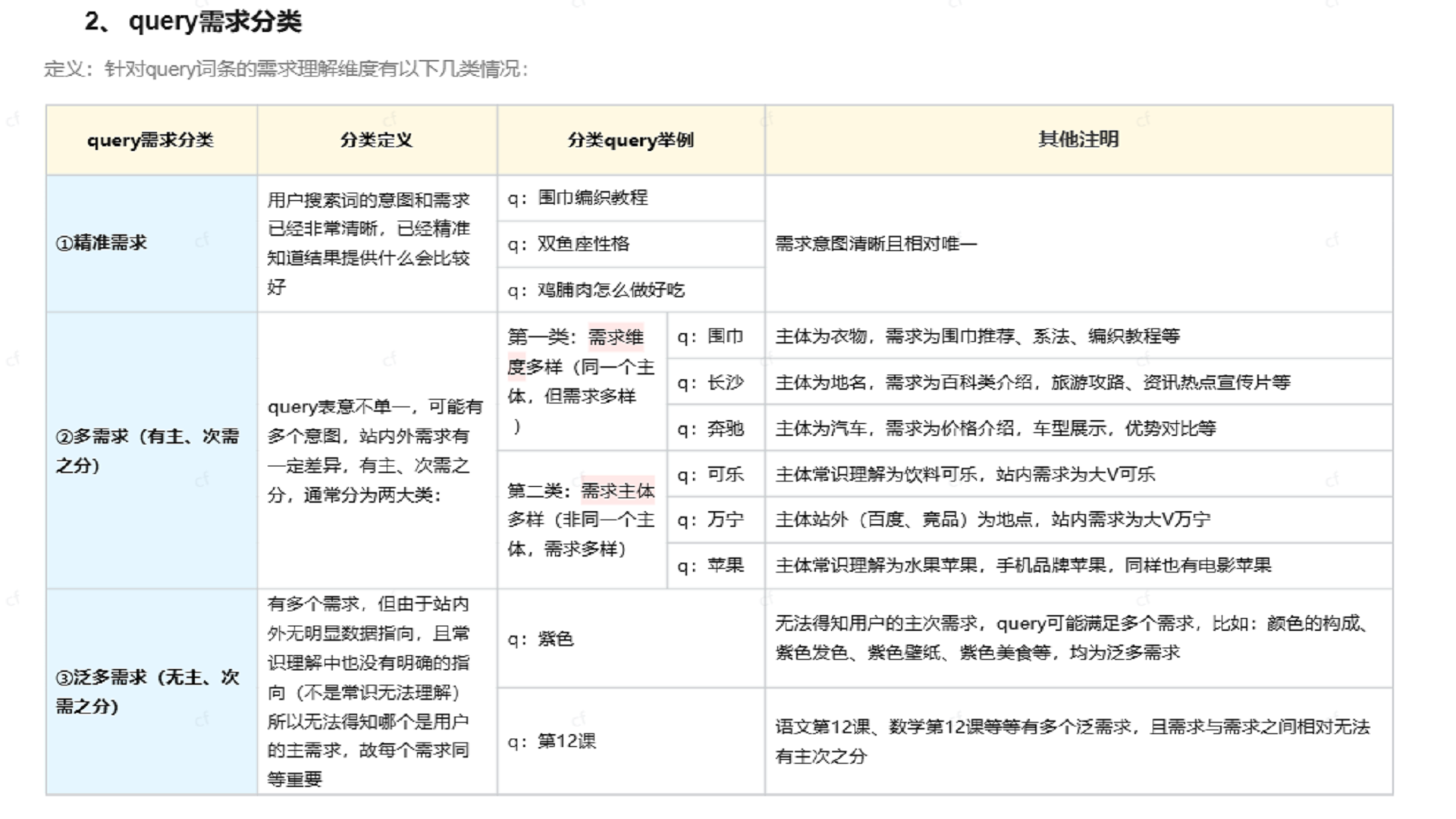
图17:规则优化整理中的 Query 需求分类

图18:Query 需求判断规则
3. 实体提取
实体指真实世界中具有明确指代的人、地点、组织、品牌、产品、IP、作品名等。例如“潮汕站”“揭阳机场”“布老虎”“老虎膏”等都可能被识别为实体。
实体提取的意义在于:如果 query 明确指向某个实体,笔记内容必须真正命中该实体或其强关联内容,否则不能简单因为同类词出现就判高分。
4. 限制条件提取
限制条件包括时间、空间、数量、程度、对象属性、逻辑关系、格式、类型等。例如:
- “附近”是空间限制。
- “英文文案”包含语言和内容形式限制。
- “背后的拉链底部翘起”包含部位和问题描述限制。
- “使用方法和功效”包含信息类型限制。
限制条件是影响评分的重要先决条件。若笔记未满足核心限制条件,即使主题相关,也不能直接判高分。
七、规则体系设计
《新社区搜索相关性-规则优化整理》文档将业务规则以截图形式完整整理。该文档主要包含项目背景、分值介绍、query 分类、query 需求判断、笔记匹配规则、模型分析流程、新旧规则映射和完整判分流程。
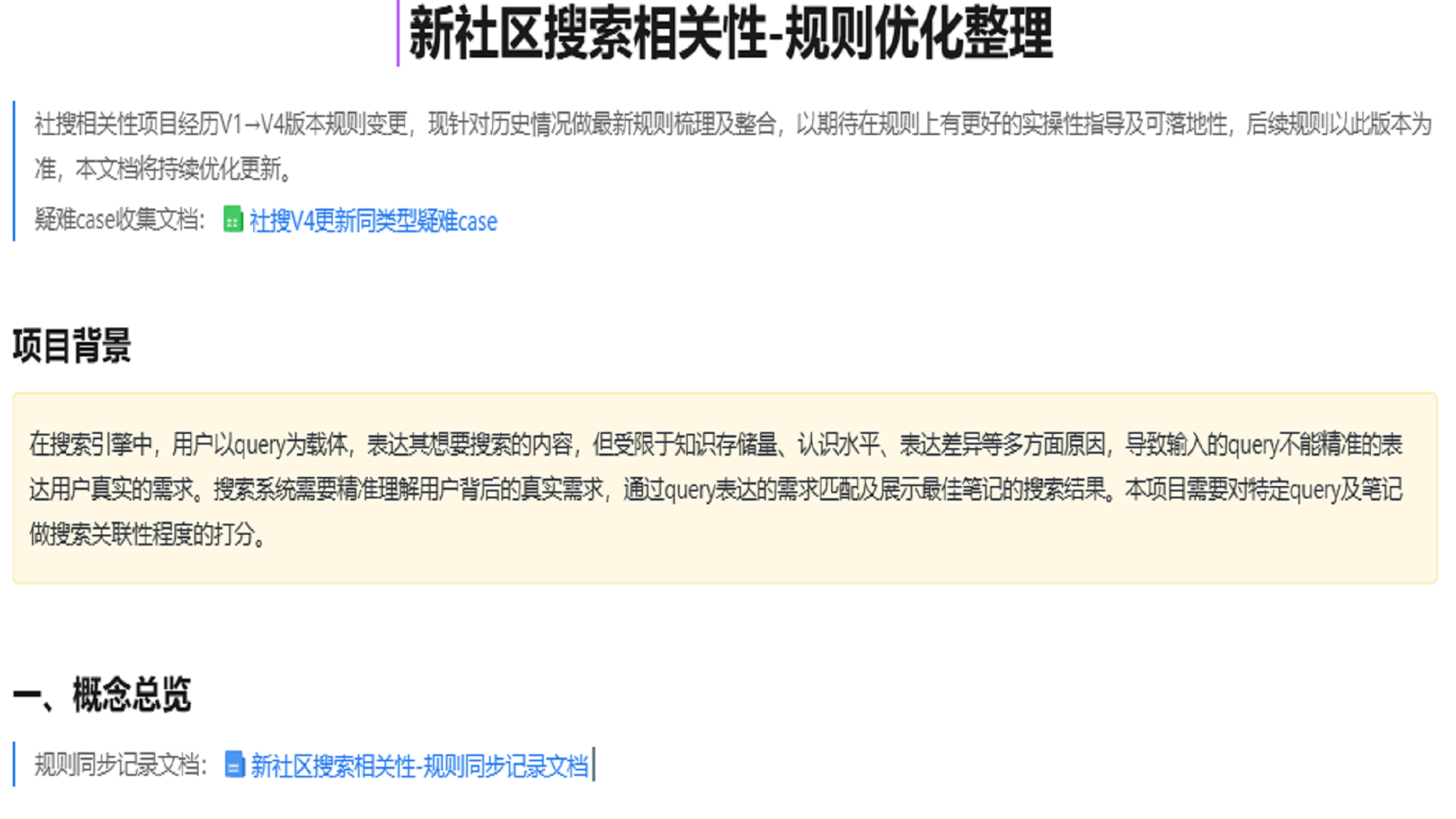
插入图15:规则优化整理项目背景
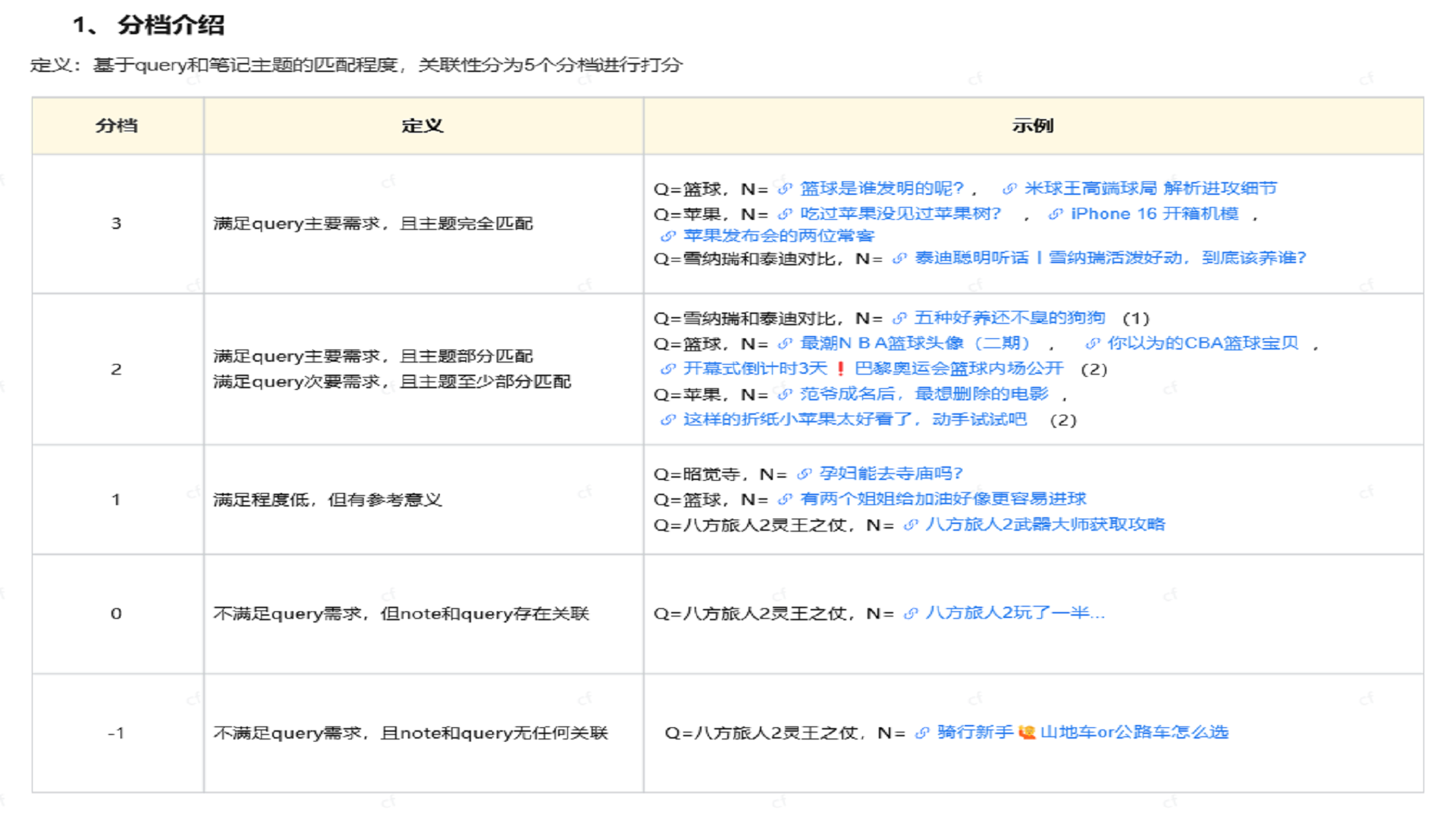
插入图16:分值介绍
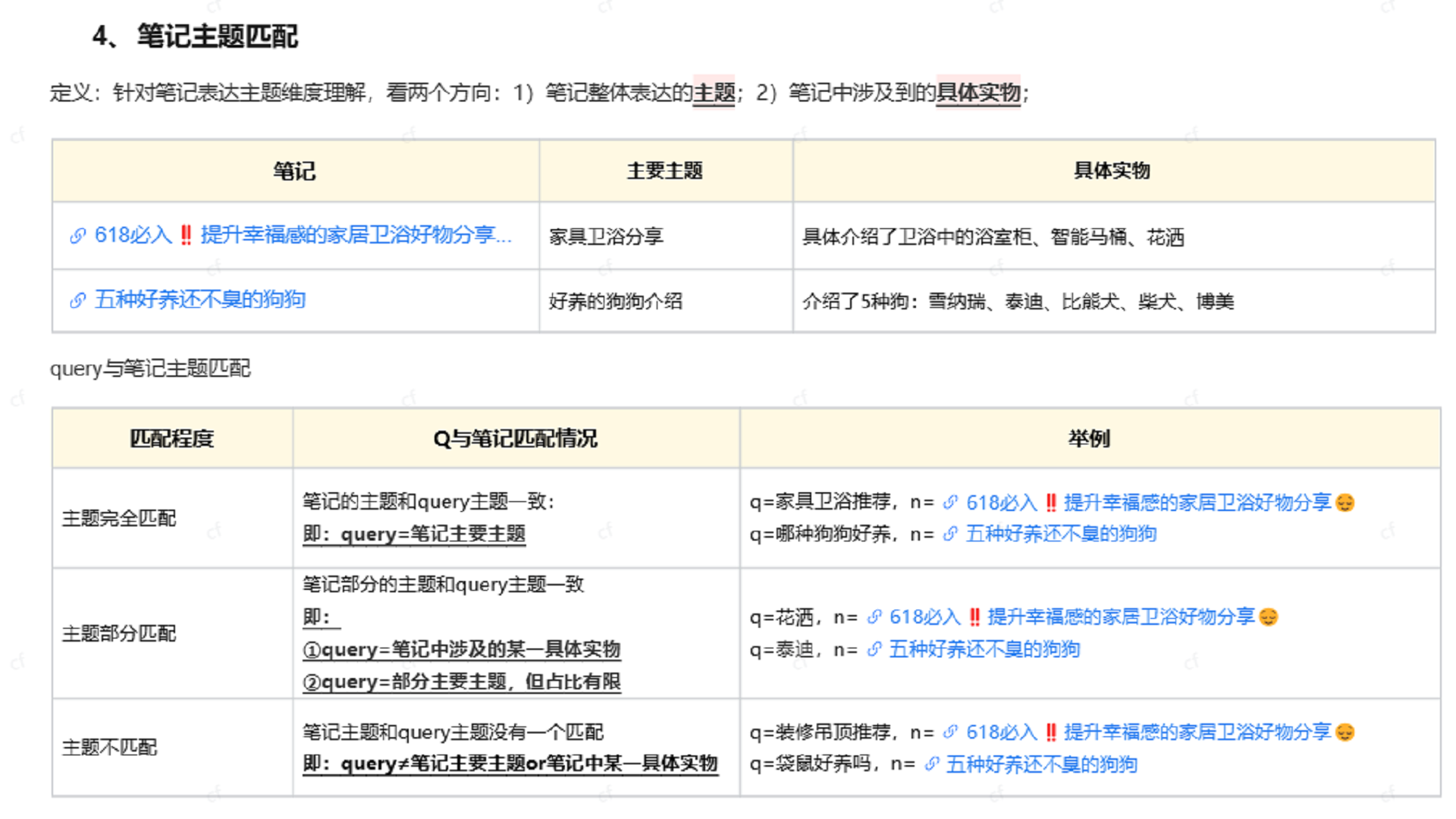
插入图19:笔记匹配规则
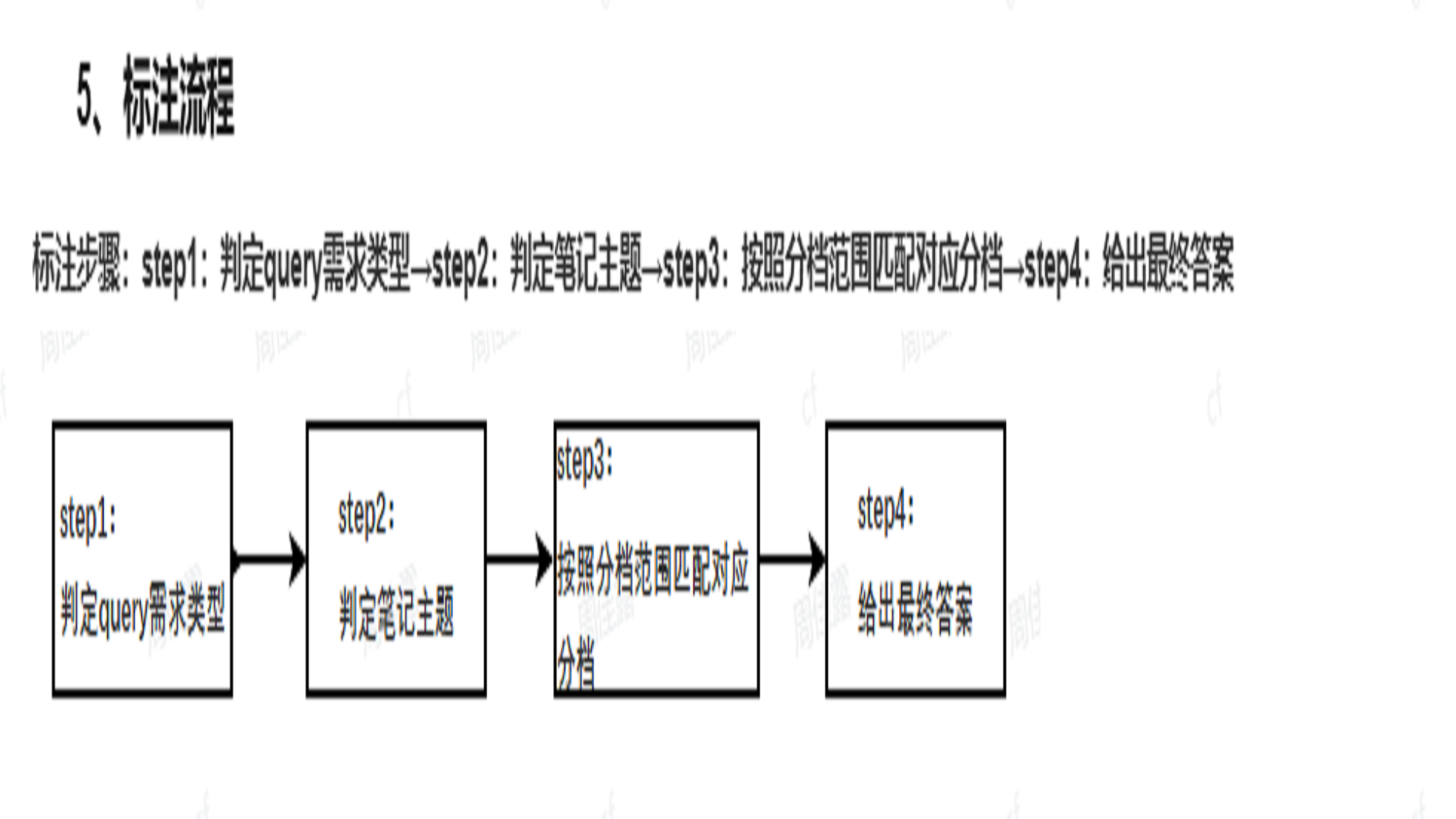
插入图20:模型分析流程
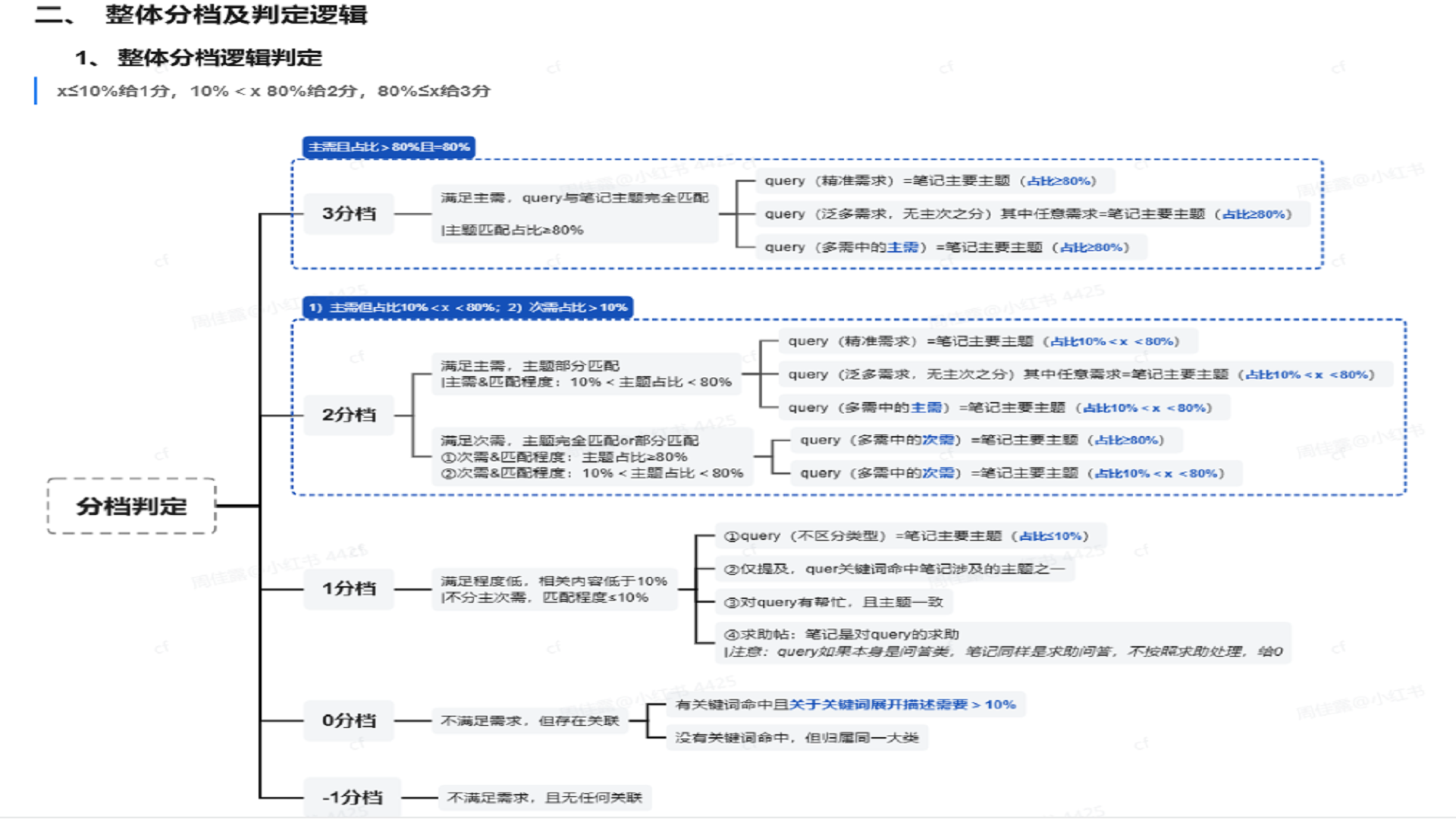
插入图21:新旧评分规则映射
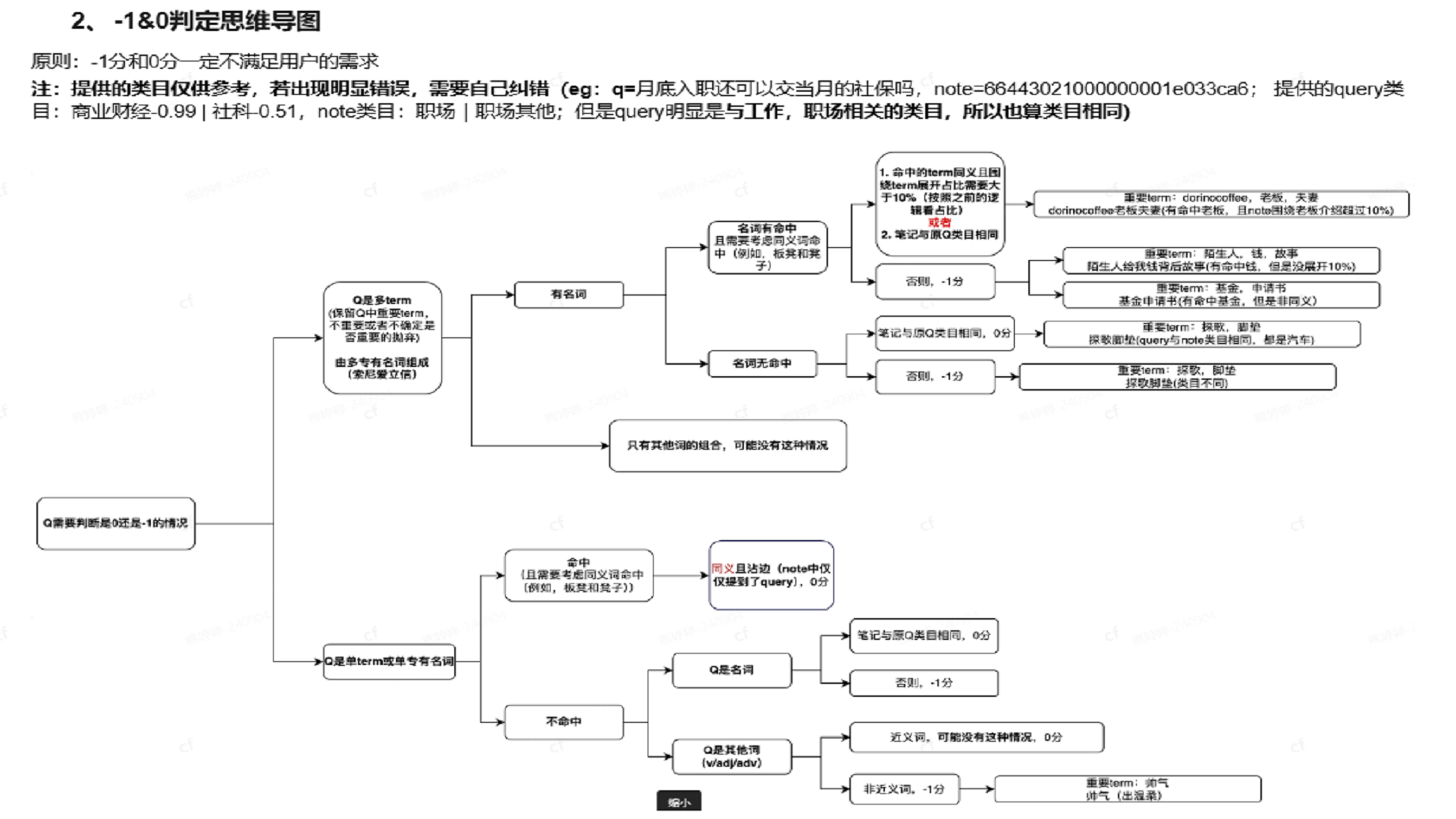
插入图22:完整判分流程
评分分档
系统最终将笔记与 query 的相关性映射为分值:
- 3 分:满足主需求且主题完全匹配。
- 2 分:满足主次要需求且主题至少部分匹配。
- 1 分:满足程度低但有参考意义。
- 0 分:不满足需求,但 note 和 query 有关联。
- -1 分:不满足需求,且 note 和 query 无任何关联。
- -2 分:无法查看或不参评。
项目早期使用“有效内容占比”进行计算,例如有效内容占比大于等于 80% 判 3 分,大于等于 10% 判 2 分。后续优化中,将有效内容占比进一步抽象为“有效内容等级”,减少模型在字数统计和比例计算上的不稳定。
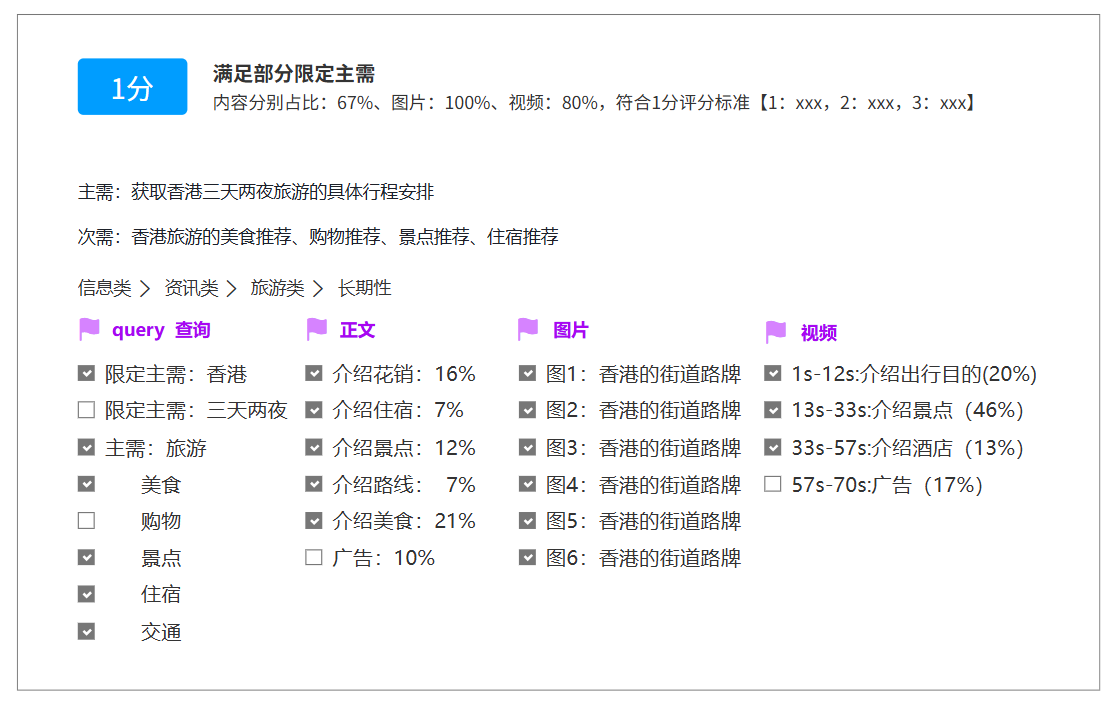
插入图10:评分标准样例,1 分规则展示
八、核心工作流 SOP
项目过程文档中将作业 SOP 拆为五个步骤:
- query 变量结构化提取。
- 遍历变量,进行变量与笔记的双向匹配。
- 处理匹配结果,将文本、图片、视频三维度结果合并。
- 根据匹配结果计算内容得分,形成三维度加权得分模型。
- 根据得分输出最终结果,进入结果分级输出机制。
Step 1:query 变量结构化提取
输入原始 query,输出结构化 JSON:
{ "可理解": true, "限制条件": [], "实体": [], "需求": { "主需": [], "次需": [] }, "分析说明": "" }
Step 2:正文、图片、视频分别匹配
系统分别调用不同 Prompt 判断:
- 文本是否满足意图列表。
- 文本是否命中实体。
- 文本是否满足限制条件。
- 图片是否满足意图列表。
- 图片是否命中实体。
- 图片是否满足限制条件。
- 视频是否满足意图、实体和限制条件。
每个节点都要求模型输出 JSON,包含 result、list、有效内容数量或比例、是否有关联、分析说明等字段。
Step 3:三维度结果合并
系统合并文本、图片、视频的匹配结果,得到:
{ "限制条件": true, "实体": true, "需求": "满足/部分满足/不满足", "是否有关联": true }
Step 4:计算内容得分
系统根据限制条件、实体、需求满足情况和有效内容等级计算最终分数。若限制条件、实体和需求都满足,则根据有效内容等级判断 3 分、2 分或 1 分;若不满足需求但有关联,则进入 0 分;若完全无关联,则进入 -1 分。
九、案例展示:多模态样例与规则应用
项目过程文档中使用多个具体 case 展示规则如何落地。
案例 1:布老虎信息可视化
该 case 用于说明 query 拆解、多图片内容理解和信息可视化需求匹配。query 会被拆成“获取布老虎相关信息、整理分类布老虎信息、选择可视化工具、设计呈现形式、完成信息可视化”等多个需求方向。系统需要判断笔记中图片和正文是否真正围绕布老虎知识、分类、展示方式展开。

插入图02:布老虎案例素材 1

插入图03:布老虎案例素材 2
插入图04:布老虎案例素材 3
案例 2:潮汕站到揭阳机场
该 case 展示了 query 中实体和时间限制的复杂性。query 包含“潮汕站”“揭阳机场”“15:02 到站”“17:10 飞机起飞”“五一期间”等信息。系统不仅要识别地点实体,还要理解交通方式、时间是否来得及、节假日交通影响等隐含判断。

插入图05:潮汕站到揭阳机场案例图片
十、规则优化与细分类目展示
规则优化文档中还整理了大量细分类目、判分边界和案例。由于原文档内容以截图为主,以下图片全部保留作为规则体系附录,可在作品集中按“规则文档展示”章节插入。
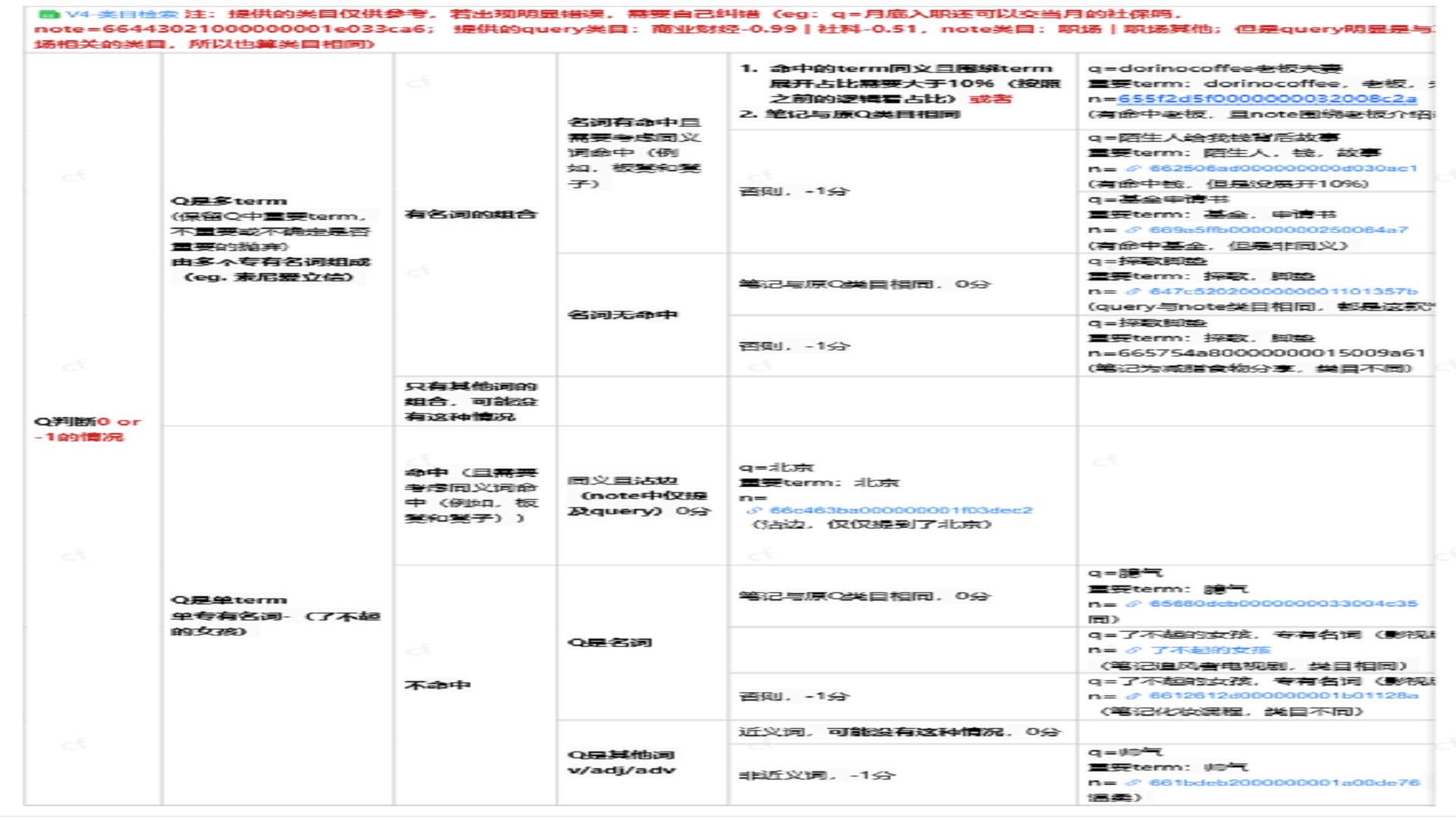
插入图23:重点规则总览 01
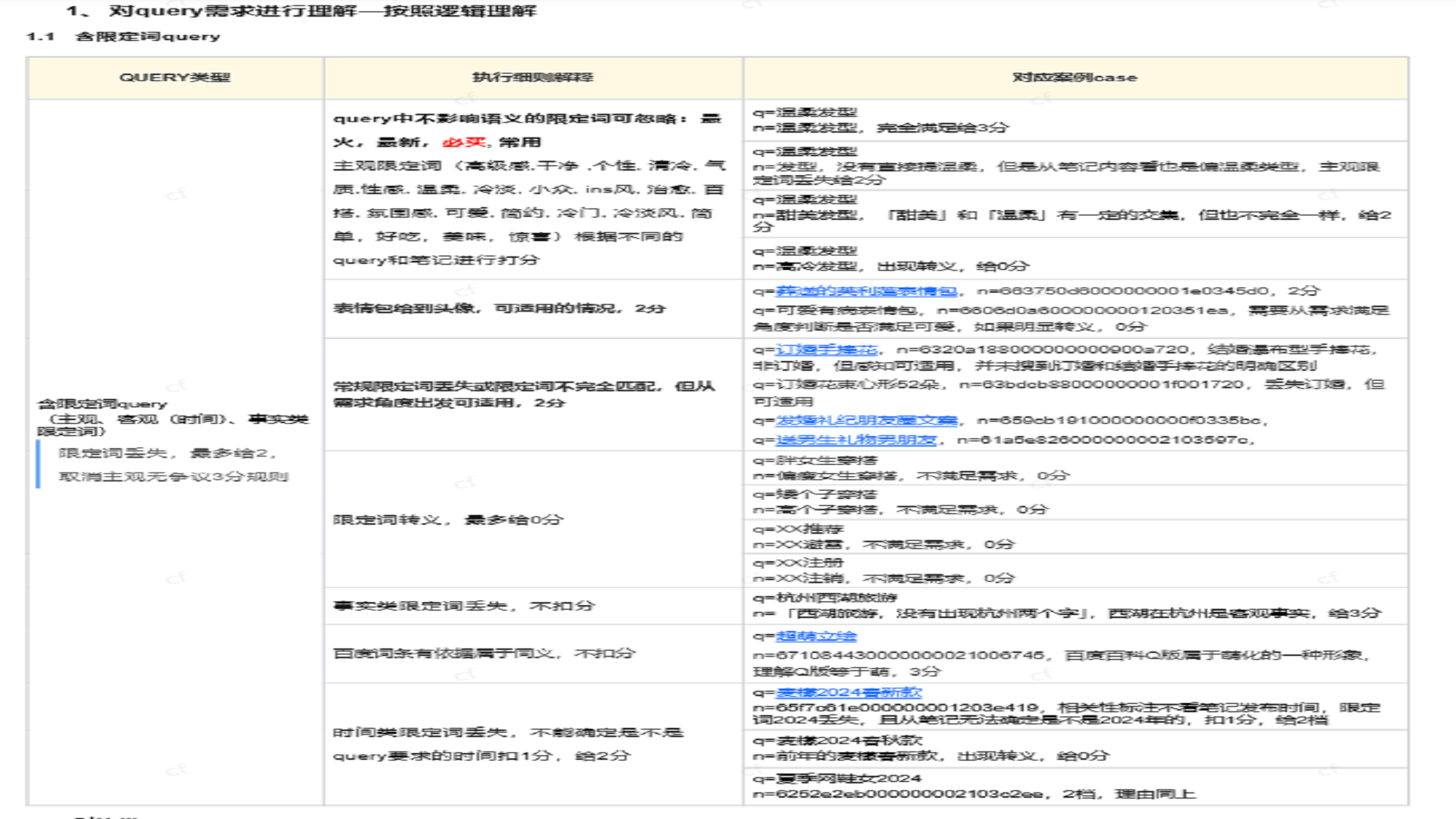
插入图24:重点规则总览 02

插入图25:细分类目规则 01

插入图26:细分类目规则 02

插入图27:细分类目案例 01

插入图28:细分类目案例 02

插入图29:问答求解类规则 01
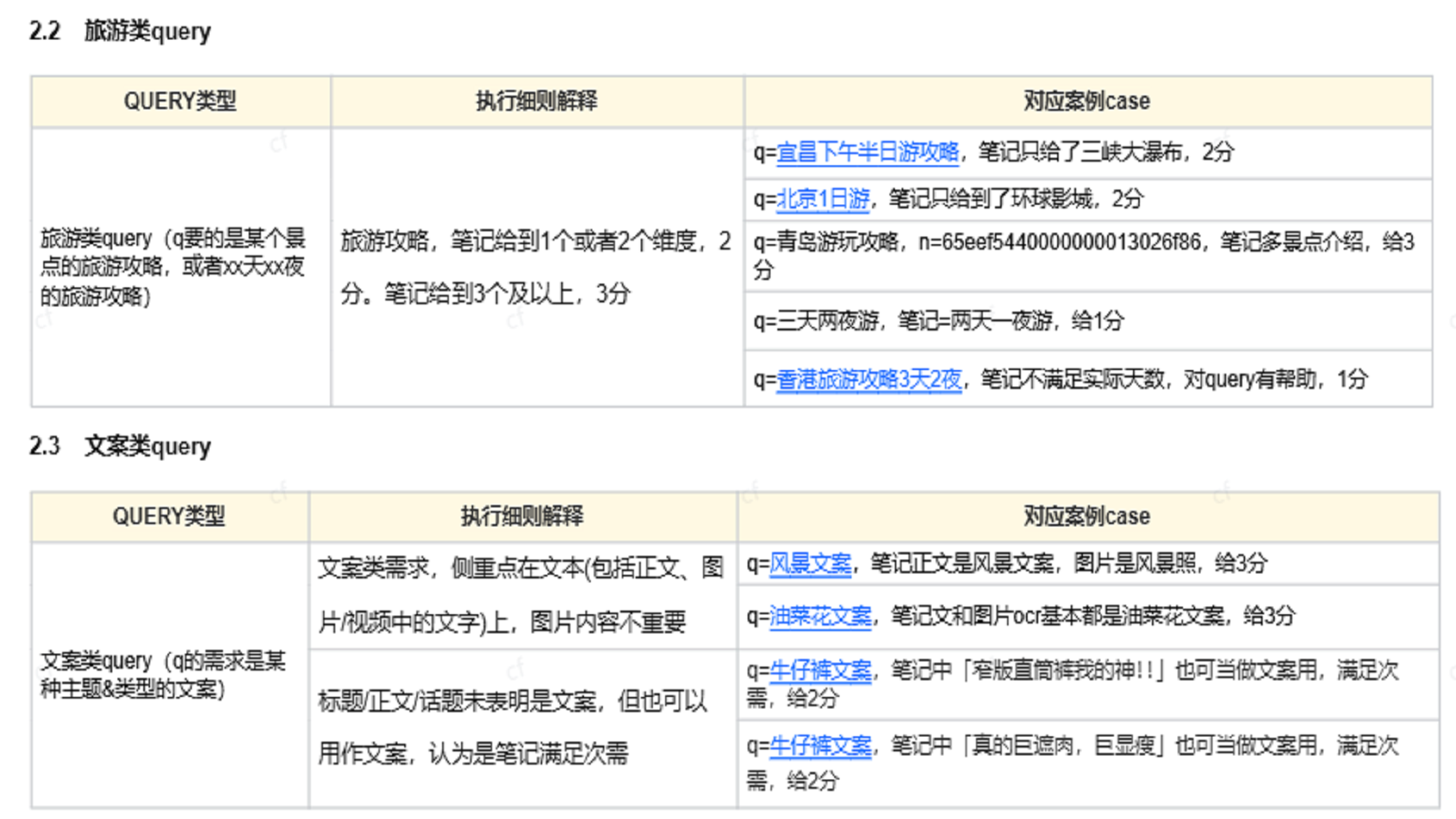
插入图30:问答求解类规则 02

插入图31:问答求解类案例 01

插入图32:问答求解类案例 02

插入图33:POI Query 规则

插入图34:场景 Query 规则
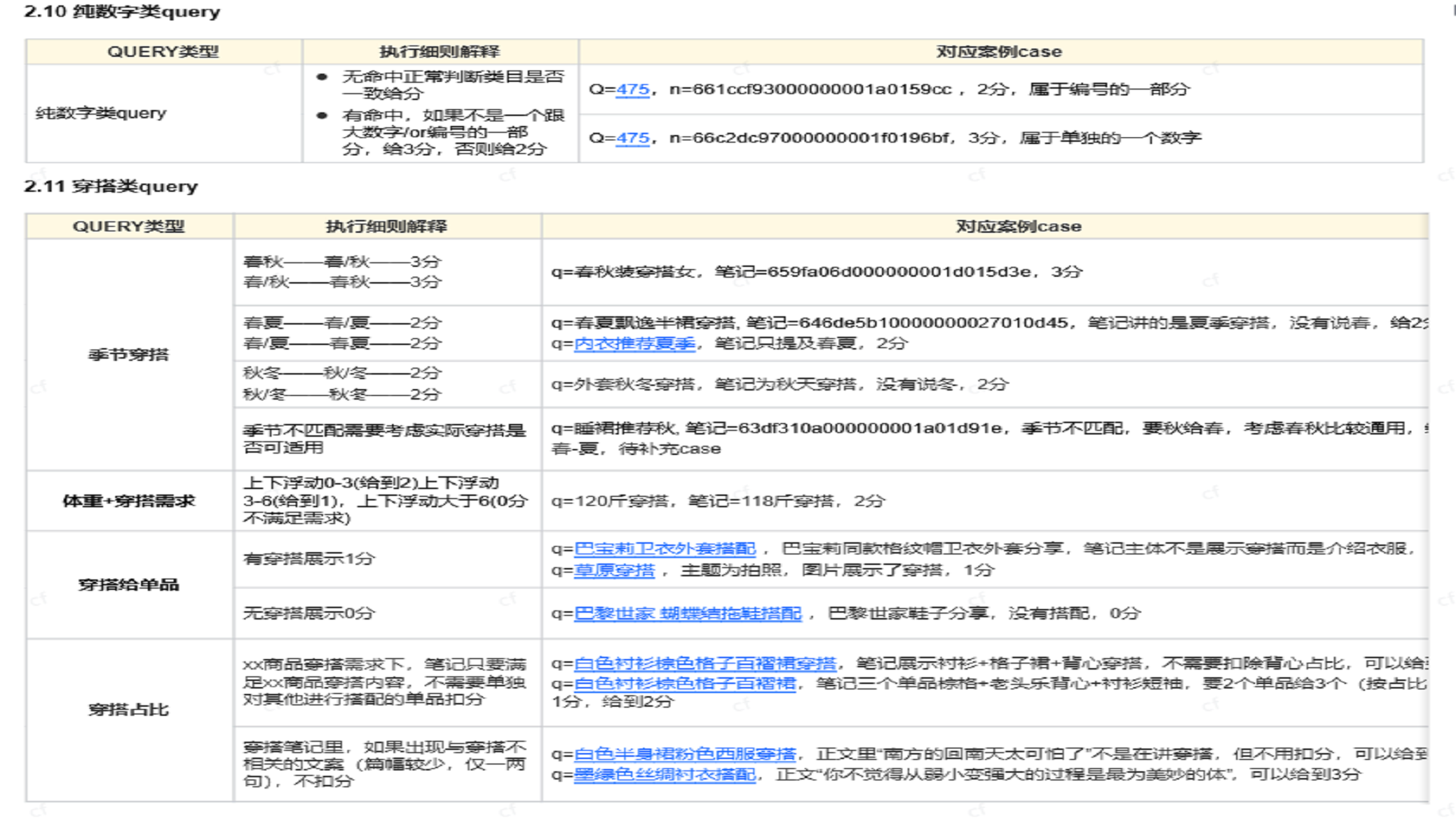
插入图35:细分 Query 规则 03

插入图36:细分 Query 规则 04

插入图37:标签与链接案例

插入图38:特殊 Query 案例 01

插入图39:特殊 Query 案例 02
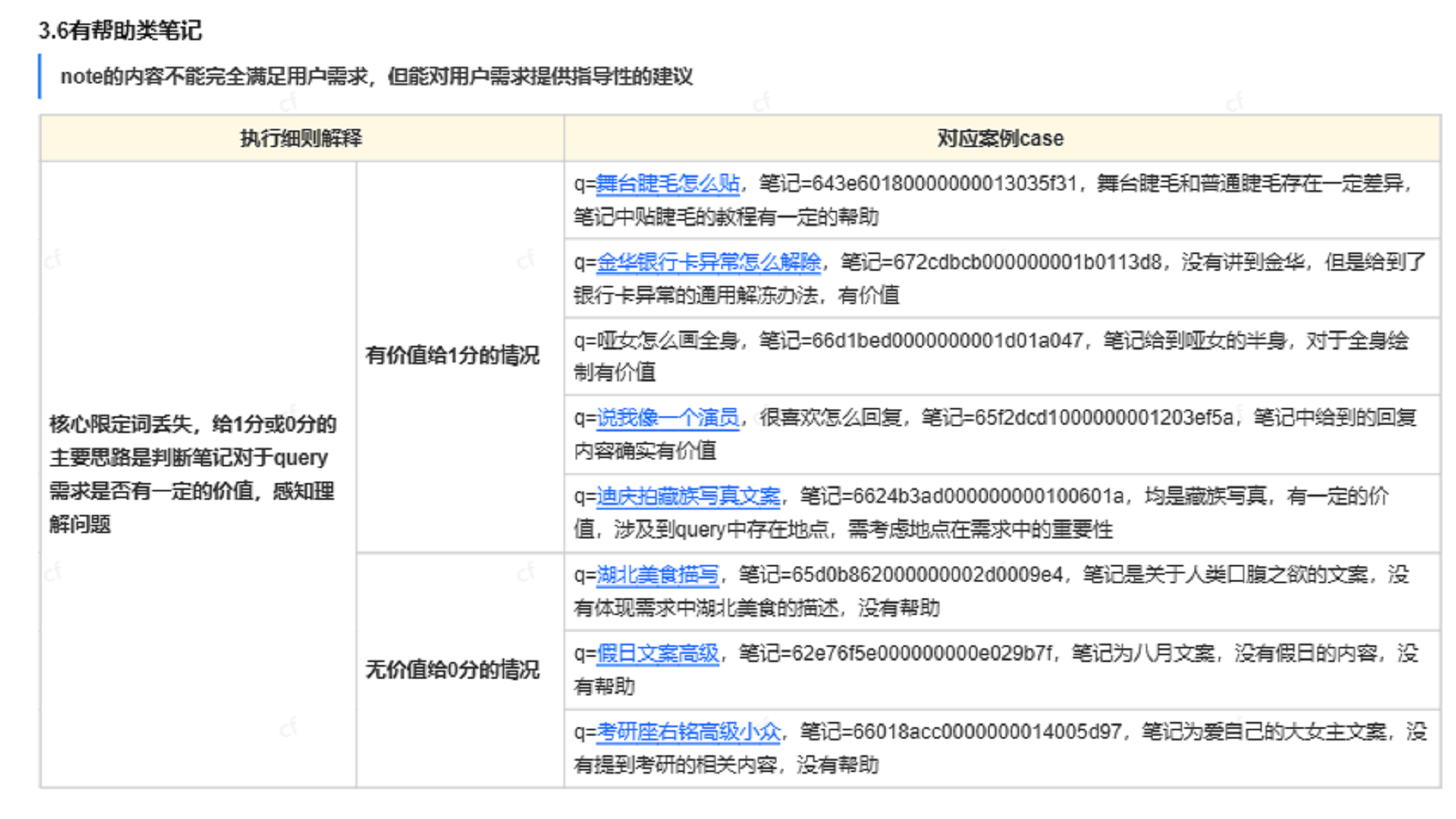
插入图40:特殊 Query 案例 03

插入图41:冲突与修正案例

插入图42:综合规则案例 01
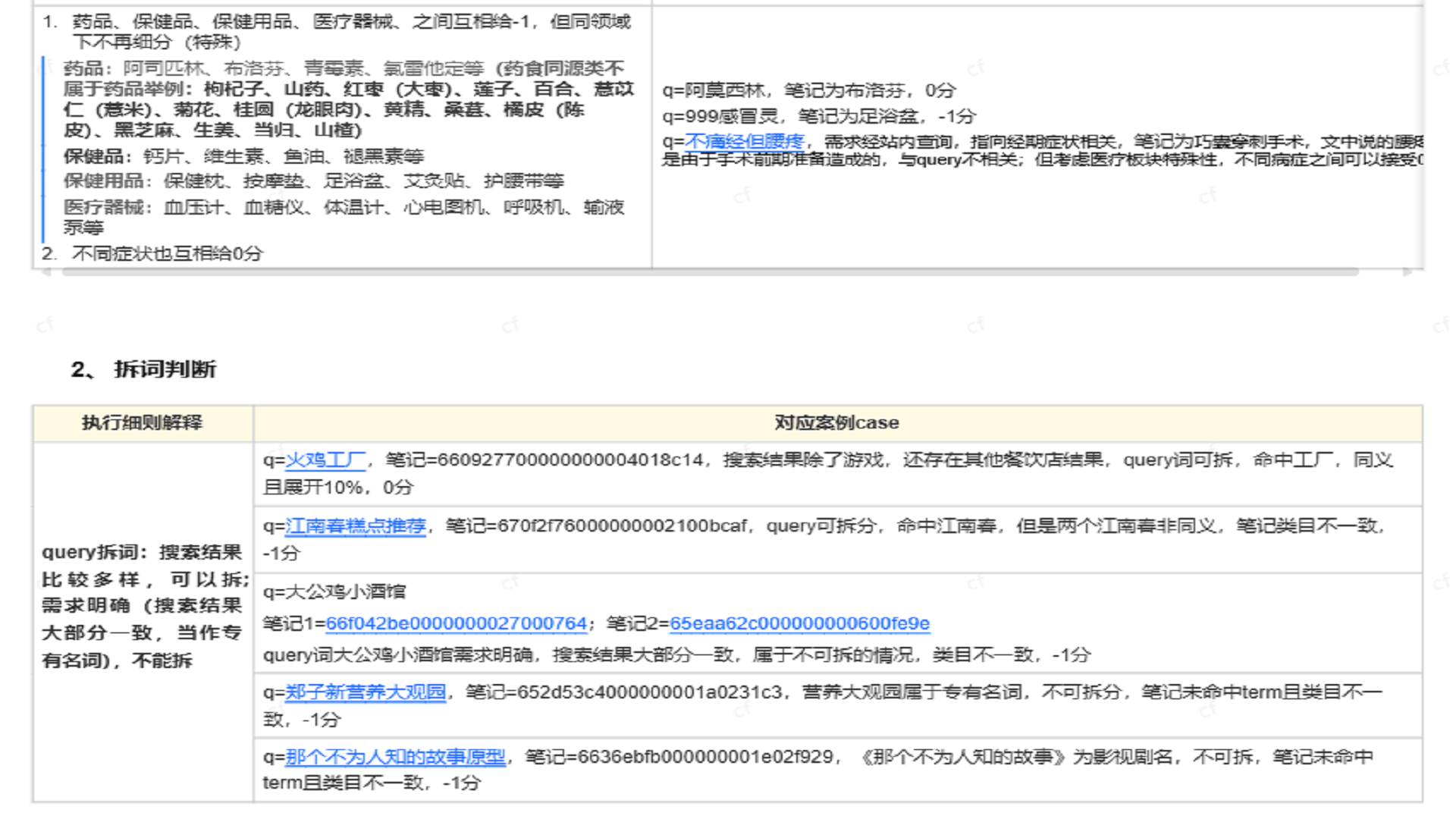
插入图43:综合规则案例 02
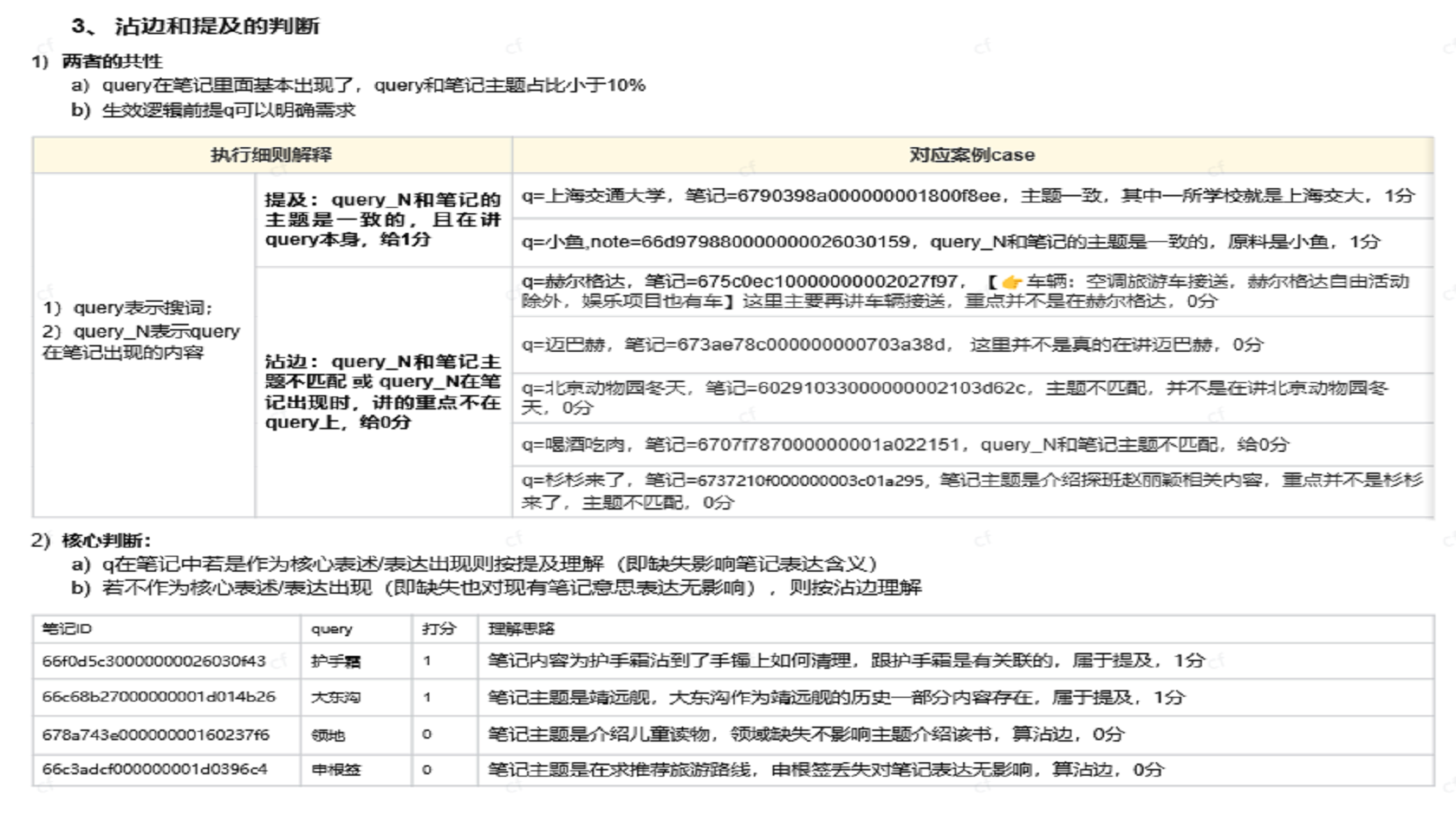
插入图44:总结与案例

插入图45:附录案例
十一、Prompt 设计与模型输出约束
项目中 Prompt 设计遵循两个原则:
- 把业务规则明确写入模型指令中,减少模型自由发挥。
- 要求模型稳定输出 JSON,便于下游节点解析和打分。
典型 Prompt 包括:
- query 是否可理解判断。
- query 主需、次需识别。
- query 限制性条件提取。
- query 实体提取。
- 文本意图匹配。
- 图片意图匹配。
- 视频意图匹配。
- 文本/图片/视频实体匹配。
- 文本/图片/视频限制条件匹配。
为解决大模型输出不稳定问题,项目采用了 JSON 样例嵌入、结果校验、自动重试、AI 验证节点等方案。过程文档中将“大模型指定格式稳定输出”列为已完成事项,处理方式是增加重试节点和 AI 验证节点,对 JSON 格式异常数据进行修复。
十二、模型与系统工程实现
项目涉及多个模型和工具:
- 文本模型:qwen-flash、qwen3-coder-plus 等。
- 多模态模型:qwen-vl-max、GLM-4.1V-9B。
- 本地化模型:qwen7b、qwen32b、智谱 GLM 9B、TARS。
- 自动化能力:TARS、UI-TARS、Browser Use、Midscene、Magnetic-UI。
- 工作流:N8N。
- 数据库:MySQL。
- 容器部署:Docker Compose。
技术实现的重点不只是模型调用,而是把多个模型节点的输出组织成一个可计算的数据结构。项目通过 N8N 将多个模型调用拆成子流程,再由主流程合并结果。
系统实现中遇到的技术卡点包括:
- 多个模型请求合并后,如何不降低返回精度。
- 模型结果不一致、不稳定。
- 非常规限制词识别不足。
- 同义词、近义词、相似实体容易混淆。
- 图片和视频信息识别耗时长。
- 模型输出 JSON 格式异常。
- 业务数据抓取不完整或重复。
对应优化方向包括:
- 输入数据预处理。
- Prompt 细化限制。
- 建立限制词词典。
- 建立业务类目库。
- 引入重试和格式校验节点。
- 对异常数据进行人工二次复核。
十三、人机协作与自动化分析
《智能化-人机协作&自动化分析》文档对人机协作平台进行了调研。该部分为作品提供了后续 Agent 化演进方向。
当前主流人机协作平台基于 LLM,将用户自然语言指令解析为结构化操作序列,再通过浏览器控制、DOM 结构分析、截图理解、视觉定位等方式执行任务。
文档中拆解了多智能体协作角色:
- orchestrator:任务协调器,负责整体流程控制。
- web_surfer:网页内容获取模块,支持网页抓取。
- coder:代码生成与执行模块。
- file_surfer:本地文件检索模块。
- action_guard:动作防护模块,监控并过滤风险操作。
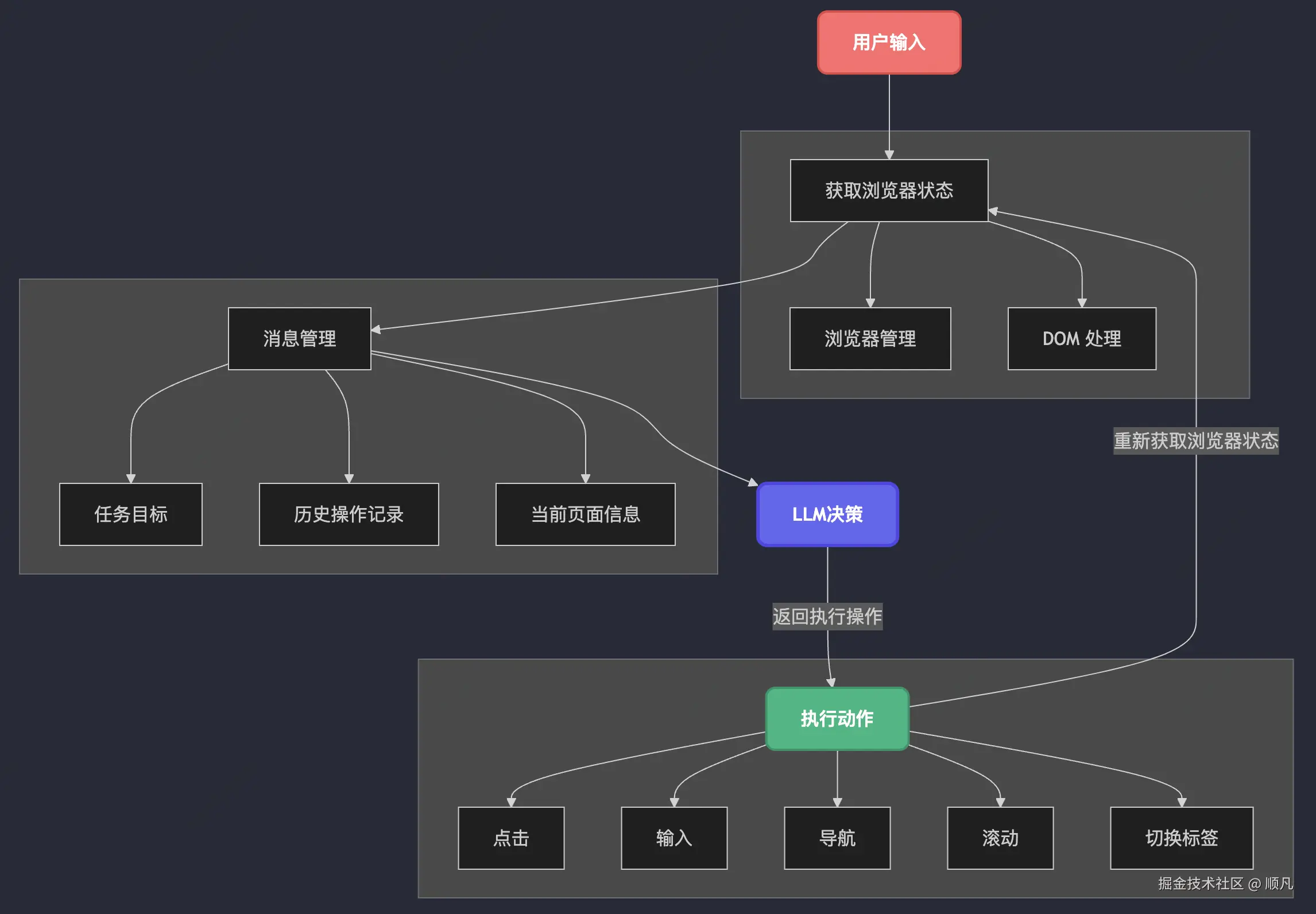
插入图46:人机协作平台流程架构图
项目文档提出的路线是“本地 agent 与云端专家 agent 协同交互作业”。本地 agent 负责浏览器、文件系统、任务解析和基础执行,云端专家 agent 负责复杂策略判断、模型分析和知识增强。
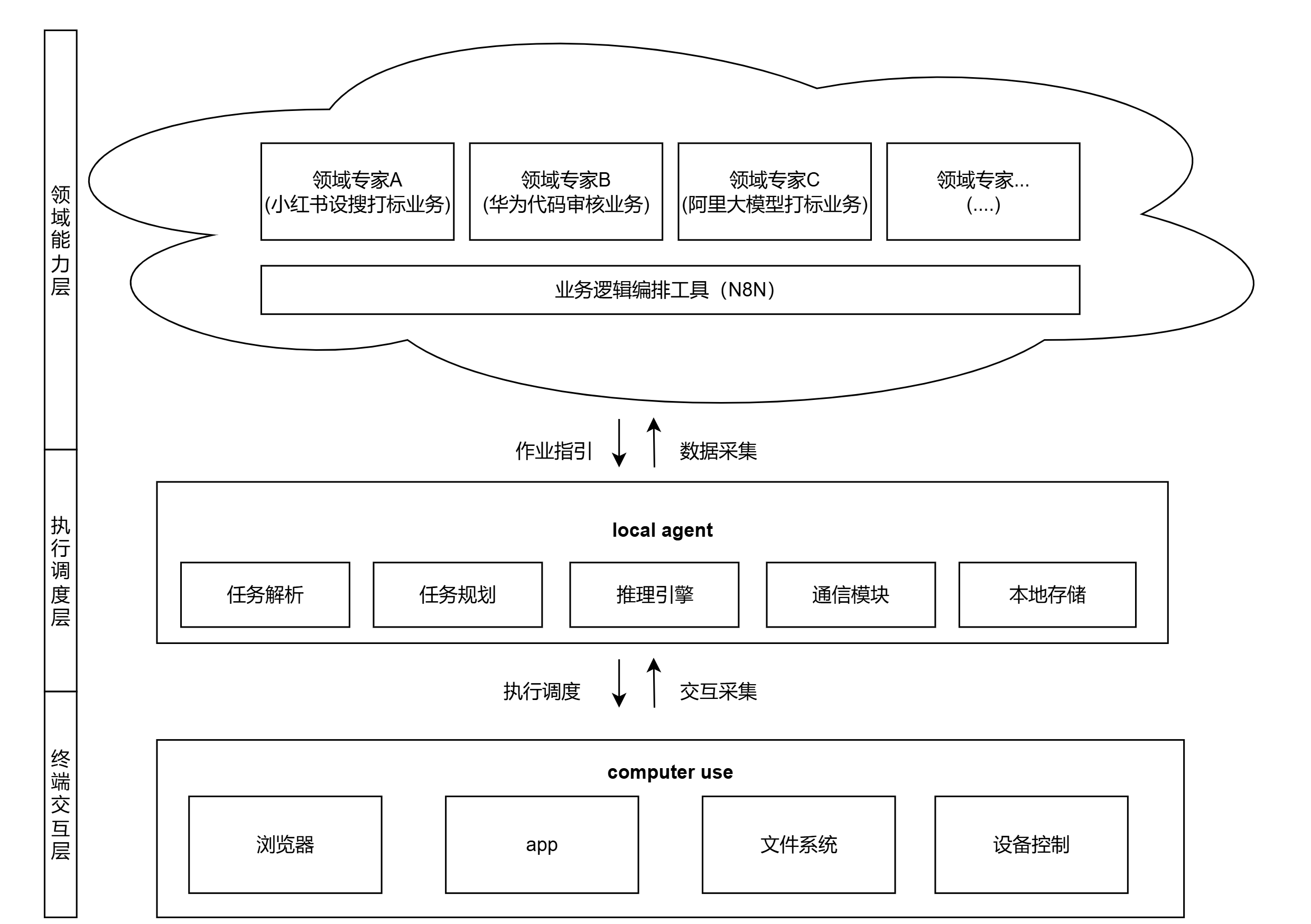
插入图47:本地 Agent 与云端专家 Agent 协作图
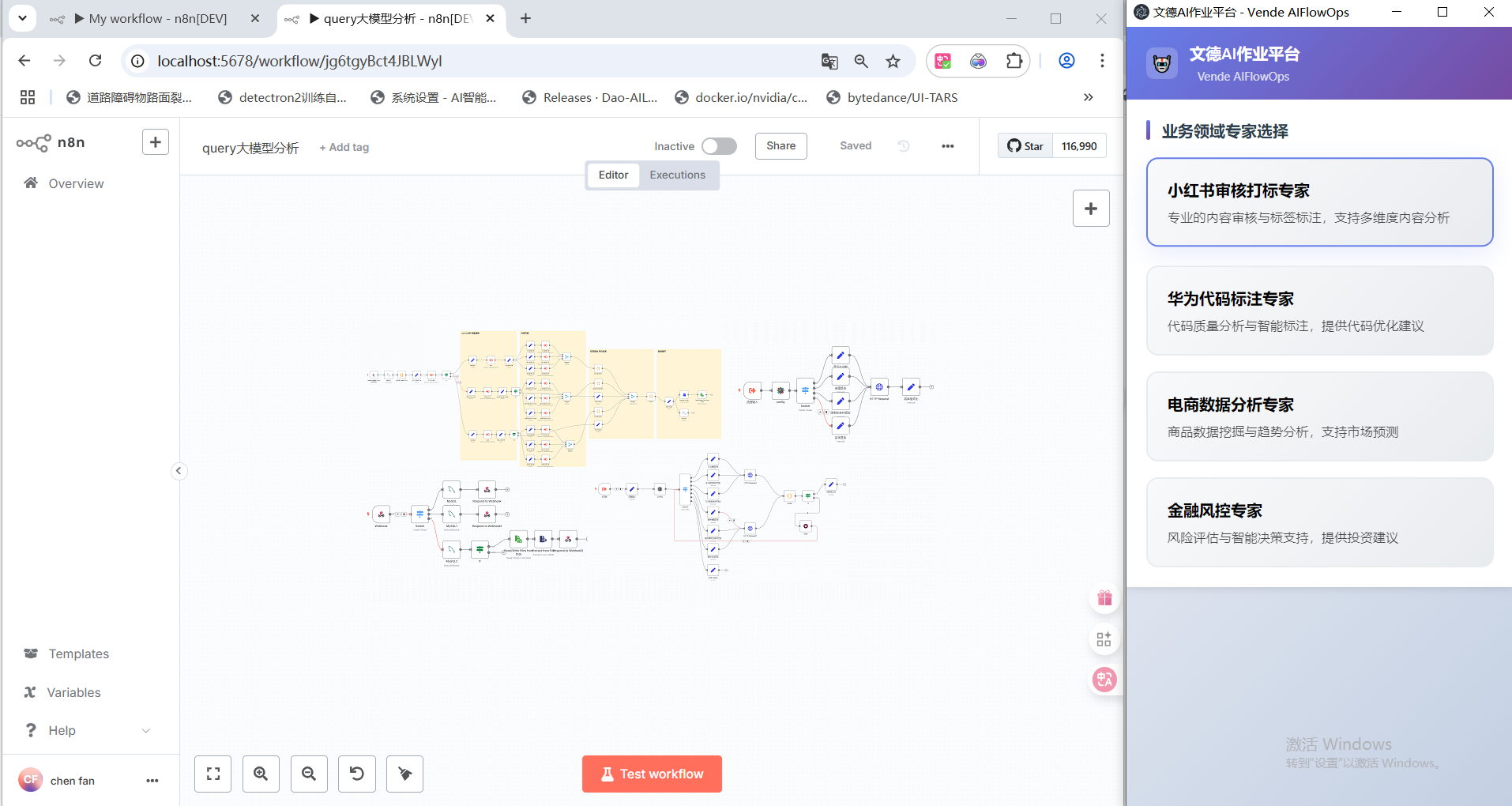
插入图48:Midscene 运行界面截图

插入图49:VendeAI 平台登录页
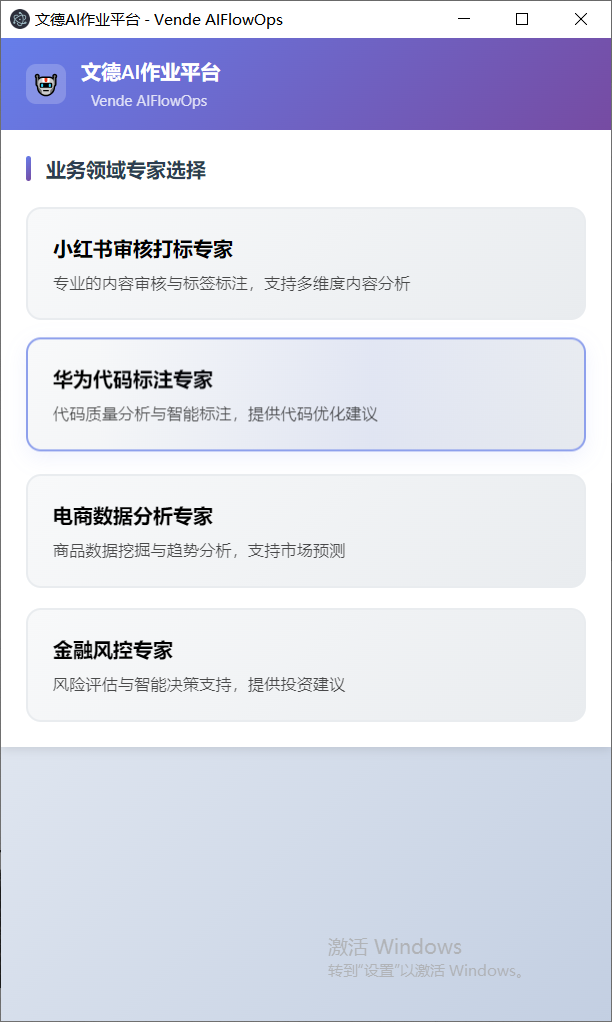
插入图50:VendeAI 作业列表页
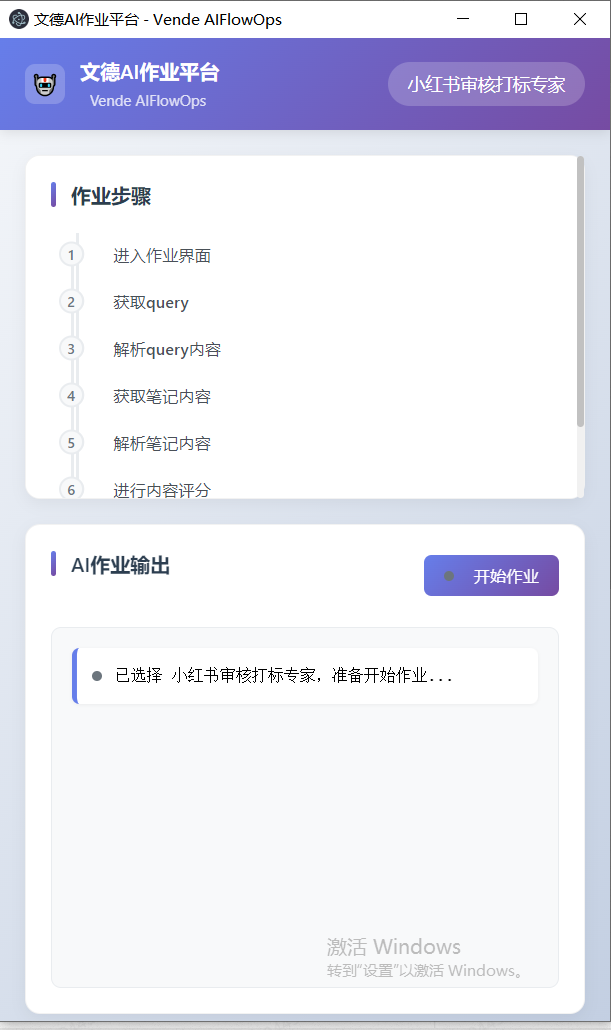
插入图51:VendeAI 任务执行页
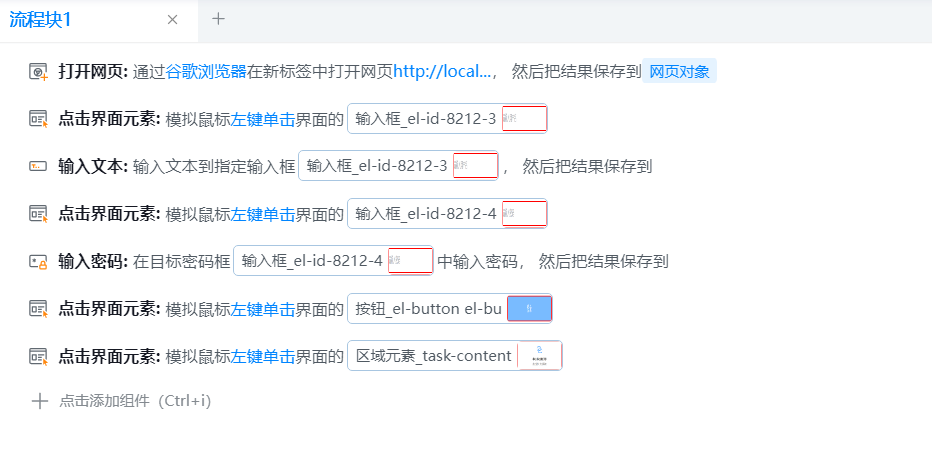
插入图52:自动化操作步骤截图
自动化平台调研结论
文档中对多个平台进行了比较:
- Browser Use:适合浏览器自动化,结合 LLM 和 Playwright,可以通过自然语言解析网页任务。
- UI-TARS-desktop:适合界面视觉定位和桌面级操作,但调试复杂,依赖模型输出。
- Magnetic-UI:基于多智能体协同,适合复杂网页任务规划和执行。
- 实在智能:面向 RPA 和数字员工场景,适合封闭系统操作。
- UFO² AgentOS:偏系统级深度集成,适用于 Windows 生态。
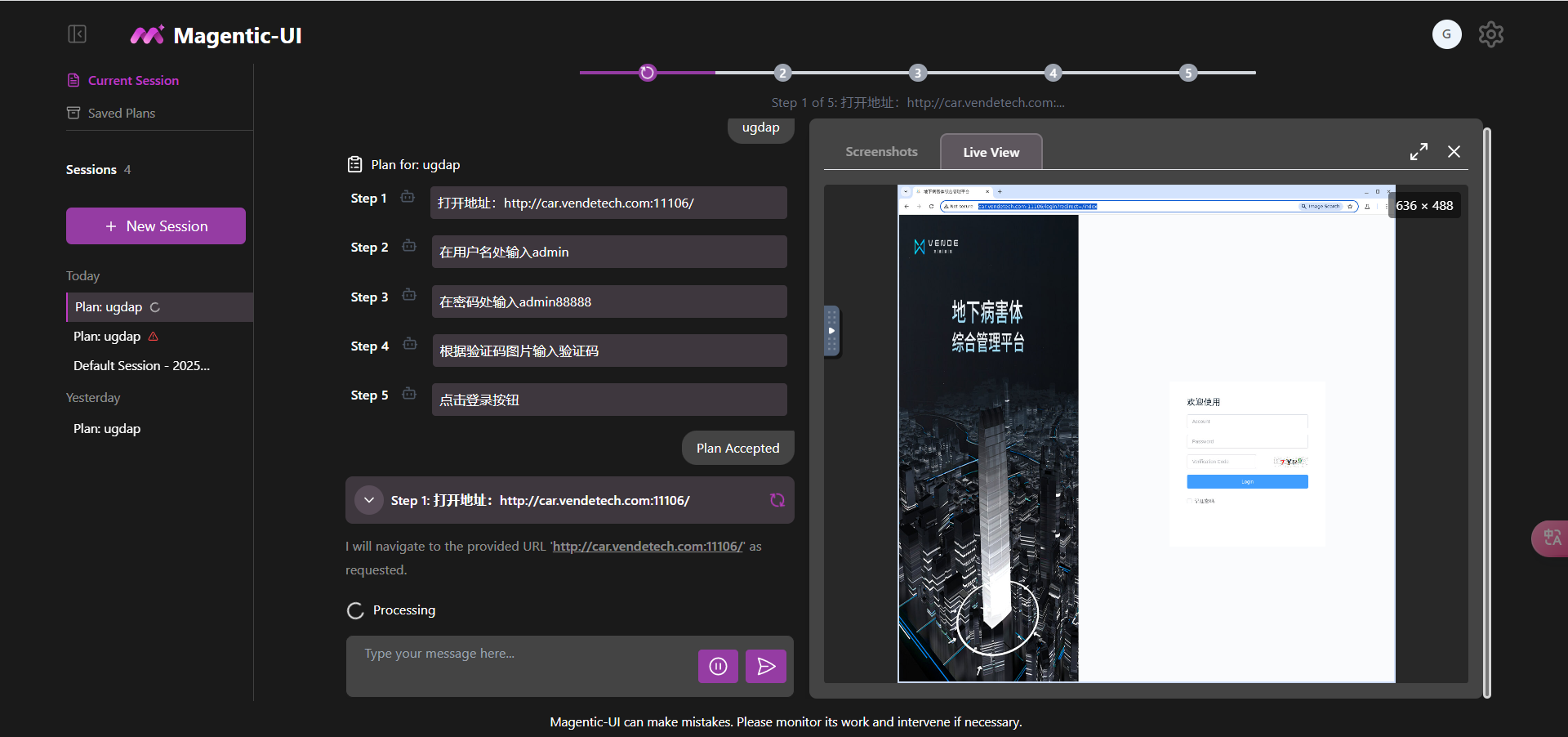
插入图53:Magnetic-UI 界面截图
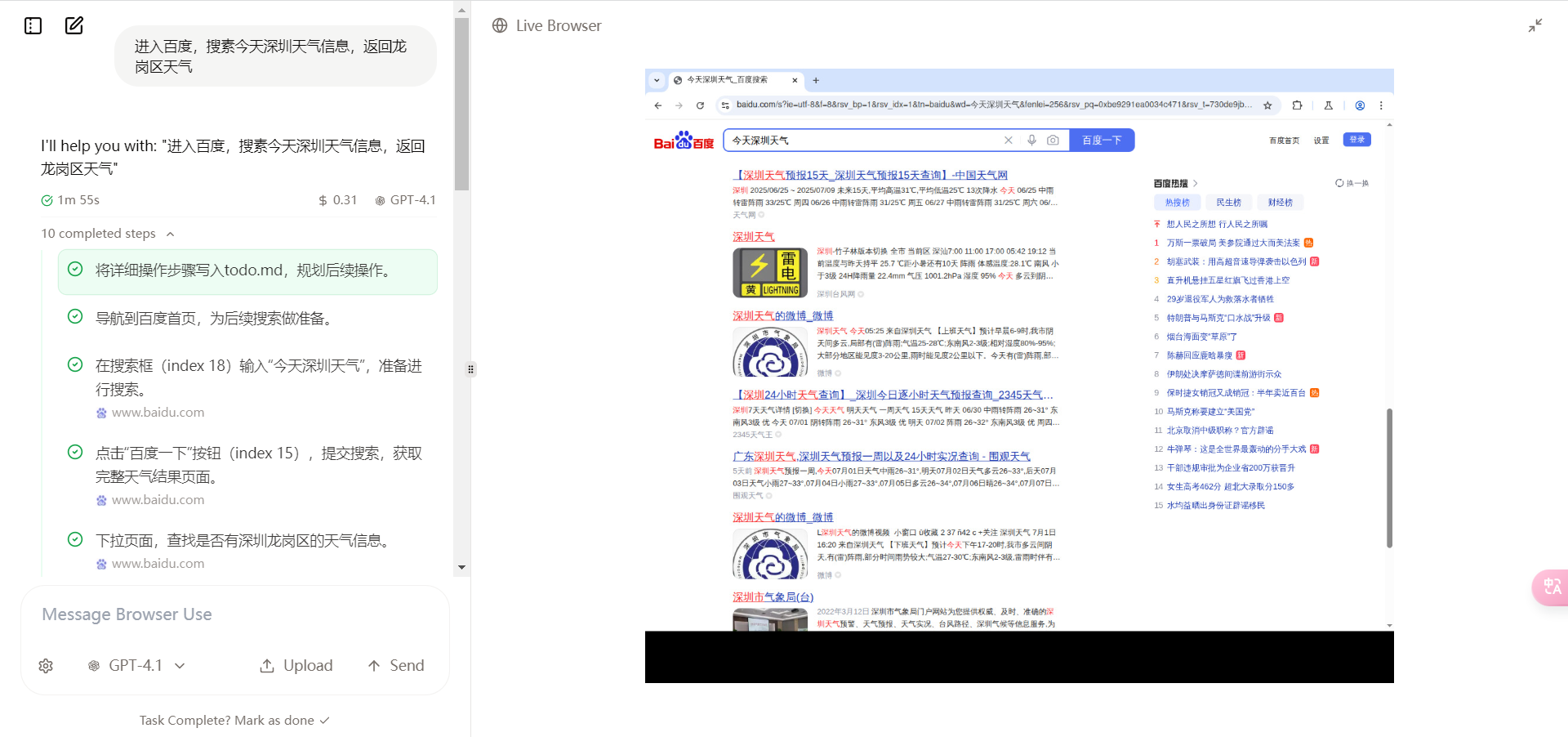
插入图54:Browser Use 运行界面截图
该调研说明,本项目不仅停留在 Copilot 辅助分析阶段,还考虑了后续向 Agent 自动化作业演进的可能性。
十四、项目成果
本项目形成了以下成果:
- 完成小红书社区搜索相关性审核打标业务流程梳理。
- 建立 query 结构化拆解框架。
- 建立需求、实体、限制条件、有效内容等级等评分维度。
- 搭建基于 N8N 的审核打标主流程和子流程。
- 实现文本、图片、视频的多模态匹配。
- 实现模型输出 JSON 化和自动化解析。
- 实现匹配结果合并和分值映射。
- 完成规则优化文档整理。
- 完成 Copilot 到 Agent 演进路径分析。
- 沉淀可复用的 AI 审核打标 SOP。
结合前序 baseline 测算材料,该项目通过规则细化、Prompt 优化、流程重构和人工复核,将早期模型评分一致性从较低水平提升到可验证的 MVP 阶段,为后续业务试点和模型专项调优提供了基础。
十五、项目难点与解决方案
难点 1:业务规则复杂,模型容易直接语义判断
搜索相关性不是简单的语义相似度任务。很多 case 中,query 和正文可能出现相同关键词,但不代表满足主需求。例如问答类 query 需要真正回答问题,对比类 query 需要覆盖对比对象和对比维度。
解决方式:将规则拆解为 query 类型、主需、次需、实体、限制条件、有效内容等级,并在 Prompt 中强制模型按步骤输出。
难点 2:多模态信息之间存在冲突
有些笔记正文满足 query,但图片无关;有些图片满足 query,但正文没有有效信息;有些 tag 与正文不一致。若简单合并,很容易高估或低估相关性。
解决方式:文本、图片、视频、tag 分开判断,再按规则合并。对于无实体 query,图片可不参与主题占比;对于 tag 与笔记内容完全不匹配的情况,忽略 tag。
难点 3:模型输出格式不稳定
大模型有时会返回自然语言,有时 JSON 格式错误,有时字段名不一致。
解决方式:Prompt 中嵌入 JSON 样例,增加结果校验和重试节点,并在 N8N 中使用代码节点对格式异常进行修复。
难点 4:外部知识缺失
例如地理位置、品牌别名、实体别称、药品概念等,如果模型没有外部知识,就可能误判。
解决方式:提出建立业务类目库、限制词词典、同义词/实体映射库,并在后续引入 RAG 或搜索增强能力。
难点 5:自动化作业不稳定
人机协作和浏览器自动化工具在复杂页面、跨域 iframe、验证码、动态 DOM、文件上传等场景下存在限制。
解决方式:对 Browser Use、UI-TARS、Midscene、Magnetic-UI 等方案进行调研,明确各自适用边界,为后续 Agent 级别自动化提供技术路线。
十六、个人能力体现
这个项目体现了以下能力:
- 业务理解能力:能够把复杂审核规则拆成模型可执行的结构化步骤。
- Prompt 工程能力:能够针对 query 分析、多模态匹配、实体识别、限制条件识别设计专门 Prompt。
- 工作流搭建能力:能够使用 N8N 搭建主流程、子流程、循环节点、模型调用节点和数据库写入节点。
- 数据处理能力:能够对原始业务数据进行清洗、格式化、图片视频识别和结构化存储。
- 多模态应用能力:能够将文本、图片、视频分析结果合并为统一评分依据。
- 工程落地能力:能够处理模型 JSON 输出不稳定、异常数据、重复图片、路径挂载等实际问题。
- 评测复盘能力:能够通过 baseline 测算和 bad case 归因持续优化规则。
- 自动化调研能力:能够分析 Browser Use、UI-TARS、Midscene、Magnetic-UI 等人机协作工具的适用场景。
十七、作品集展示摘要
本项目围绕小红书社区搜索相关性审核打标场景,构建了一套基于大模型、多模态理解和 N8N 工作流的智能审核打标 Copilot。系统将人工打标过程拆解为 query 结构化解析、正文/图片/视频匹配、实体和限制条件判断、有效内容等级计算、最终分值映射等环节,实现了从原始数据到 AI 评分建议的自动化闭环。
项目重点不在于简单调用大模型,而在于把复杂业务规则工程化、流程化、可解释化。通过规则文档整理、Prompt 设计、N8N 流程编排、MySQL 数据存储和 bad case 复盘,项目沉淀出一套可复用的 AI 审核打标方法论。同时,通过人机协作与自动化工具调研,为后续从 Copilot 辅助分析升级到 Agent 半自主执行提供了技术路线。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)