
零基础学AI大模型之LangChain Output Parser
文章首先通过实际场景对比,解释了为什么需要Output Parser:将大模型的非结构化文本输出转换为结构化数据(如列表、JSON),便于工程化开发。教程详细介绍了Output Parser的工作原理(格式引导+结构化转换)和核心接口(parse、parse_with_prompt、get_format_instructions)。最后提供了基础代码框架,包括环境准备、解析器导入和Prompt构建
| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之Stream流式输出实战 |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
本文章目录
零基础学AI大模型之LangChain Output Parser
大家好,我是工藤学编程 🦉
在前几篇LangChain系列文章里(第10篇讲PromptTemplate、第11篇聊ChatModel),我们解决了“如何给大模型传精准提示”的问题,但实际开发中又遇到了新卡点:大模型返回的是自由文本,没法直接用代码处理。比如你让它列3个水果,它可能回复“常见水果有苹果、香蕉,还有橙子哦~”——这种非结构化文本,想提取成Python列表得自己写正则,太麻烦了。
今天这篇就来解决这个问题:LangChain的Output Parser(输出解析器) ,教你把大模型的“随口回答”变成“标准结构化数据”(比如列表、JSON),附完整实战代码和避坑指南。
一、先搞懂:为什么一定要用Output Parser?
在讲原理前,先明确一个核心问题:我们明明能直接拿大模型的输出,为啥要多此一举加个“解析器”?
答案很简单:大模型的原始输出是“非结构化文本”,而工程化开发需要“结构化数据” 。
举个真实场景对比,你就懂了:
| 场景需求 | 大模型原始输出(非结构化) | Output Parser解析后(结构化) |
|---|---|---|
| 提取商品评论关键词 | “这个手机续航好、拍照清晰,但系统有点卡” | [“续航好”, “拍照清晰”, “系统卡顿”] |
| 生成用户信息 | “用户叫张三,25岁,手机号138xxxx1234” | {“name”:“张三”,“age”:25,“phone”:“138xxxx1234”} |
| 分析订单状态 | “订单号A123已发货,预计3天到;订单B456还在待付款” | [{“orderId”:“A123”,“status”:“已发货”,“estimate”:“3天”},{“orderId”:“B456”,“status”:“待付款”}] |
如果没有解析器,你得写大量字符串处理代码(正则、分割、提取),而且大模型输出风格多变(比如有时加“哦”“呢”,有时换行),代码很容易崩。
Output Parser的核心价值就是:
- 统一输出格式:让大模型按我们规定的格式(列表、JSON)输出,不用猜;
- 自动格式校验:如果大模型输出格式错了,解析器能提示(部分能自动重试);
- 降低开发成本:不用自己写文本处理逻辑,直接调用解析器接口拿结构化数据。
二、Output Parser工作原理:3步把“自由文本”变“标准数据”
Output Parser不是什么“黑科技”,本质是“Prompt格式引导 + 结果结构化转换”的组合。整个流程分五步,用一张图就能看明白:

关键细节:格式指令从哪来?
解析器的核心是“让大模型知道该输出什么格式”,这个“格式要求”不是我们手动写的,而是通过解析器的get_format_instructions()方法自动生成的。
比如你用“逗号分隔列表解析器”(CommaSeparatedListOutputParser),调用这个方法会生成这样的指令:
“请将结果以逗号分隔的形式返回,不要包含其他内容。例如:苹果,香蕉,橙子”
相当于解析器帮你写好了“格式提示词”,你只需要把它嵌入到PromptTemplate里就行——这也是LangChain“低代码”理念的体现。
三、Output Parser核心接口:3个方法搞定所有场景
不管是哪种解析器(列表、JSON、自定义),都遵循LangChain的统一接口规范,核心就3个方法,学会这3个就等于掌握了所有解析器的用法:
| 核心接口 | 作用说明 | 适用场景 |
|---|---|---|
parse(text) |
把LLM返回的原始文本,解析成结构化数据(如列表、字典) | 单轮对话、无上下文依赖的场景 |
parse_with_prompt(text, prompt) |
结合原始Prompt上下文解析(比如多轮对话中,需要参考历史提示) | 多轮对话、上下文依赖场景 |
get_format_instructions() |
生成“格式要求提示词”,告诉LLM该输出什么格式(比如“用JSON输出,包含name和age字段”) | 构建PromptTemplate时必须用 |
记住:所有解析器都要先通过get_format_instructions()获取格式指令,再嵌入Prompt,最后用parse()解析结果——这是固定套路,实战中不会变。
四、Output Parser基础结构:3行代码搭起框架
不管你用哪种解析器,基础代码结构都是固定的,就像搭积木一样,分3步:
1. 环境准备:安装依赖
首先要安装LangChain和大模型依赖(这里用DeepSeek,你也可以换OpenAI、讯飞等):
pip install langchain langchain-openai python-dotenv # python-dotenv用于管理密钥,避免硬编码
2. 基础结构代码(以列表解析为例)
# 要素1:导入并创建解析器(类似Java里的Gson实例,负责数据转换)
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv # 加载环境变量,避免密钥硬编码
import os
# 1. 创建解析器实例(这里用“逗号分隔列表解析器”)
parser = CommaSeparatedListOutputParser()
# 2. 获取格式指令(让解析器自动生成“格式要求”)
format_instructions = parser.get_format_instructions()
# 3. 构建PromptTemplate(必须嵌入{format_instructions}占位符,告诉LLM格式)
prompt = PromptTemplate(
template="请列举3个常见的{subject}。{format_instructions}", # {format_instructions}是固定占位符
input_variables=["subject"], # 业务变量(这里是“要列举的类别”)
partial_variables={"format_instructions": format_instructions} # 注入格式指令
)
# 4. 创建大模型实例(这里用阿里云通义千问,换其他模型只需改参数)
model = ChatOpenAI(
model_name="deepseek-r1:7b", # DeepSeek模型名
base_url="http://127.0.0.1:11434/v1", # 通义千问兼容OpenAI的接口地址
api_key="none", # 从环境变量获取密钥,不要硬编码!
temperature=0.0 # 温度设为0,让输出更稳定(避免大模型乱加语气词)
)
# 5. 构建链(Prompt → 模型 → 解析器,类似Java的责任链模式)
chain = prompt | model | parser
# 6. 调用链,获取结构化结果
result = chain.invoke({"subject": "水果"})
print(result) # 输出:['苹果', '香蕉', '橙子'] → 直接是Python列表,能直接用!
关键说明:为什么要这么写?
- 解析器实例:相当于“数据转换器”,不同解析器对应不同数据类型(列表→CommaSeparatedListOutputParser,JSON→JsonOutputParser);
- 格式指令注入:
{format_instructions}是固定占位符,必须加在Prompt里,否则大模型不知道该输出什么格式; - 链(Chain)的作用:把“Prompt→模型→解析器”串起来,不用手动传递数据(比如不用先调用模型拿文本,再手动传个解析器),一步到位。
五、实战案例:2个常用场景带你练手
前面讲了基础结构,下面用两个最常用的场景实战,覆盖80%的开发需求。
场景1:解析成JSON(最常用,适合复杂数据)
比如需要生成“用户信息”,要求输出JSON格式(包含name、age、hobby字段),用JsonOutputParser实现:
# 场景1:解析成JSON格式
# 场景1:解析成JSON格式
from langchain_core.output_parsers import JsonOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 1. 创建JSON解析器
parser = JsonOutputParser()
# 2. 构建Prompt(明确告诉LLM要输出哪些字段)
prompt = PromptTemplate(
template="请生成一个{user_type}的用户信息,包含name(姓名)、age(年龄)、hobby(爱好,数组类型)。{format_instructions}",
input_variables=["user_type"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# 3. 创建模型
model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.5 # 适当提高温度,让结果更多样
)
# 4. 构建链并调用
chain = prompt | model | parser
result = chain.invoke({"user_type": "大学生"})
# 5. 直接用结构化数据(比如取姓名、遍历爱好)
print(f"用户名:{result['name']}")
print(f"用户年龄:{result['age']}")
print("用户爱好:")
for hobby in result['hobby']:
print(f"- {hobby}")
运行结果:
用户名:李华
用户年龄:20
用户爱好:
- 打篮球
- 看电影
- 编程
关键优势:
解析后直接是Python字典,能直接通过result['name']取字段,不用自己写json.loads()——解析器已经帮你做了。
注意,由于deepseek输出带think标签,所以会有报错,但是输出的内容没有问题
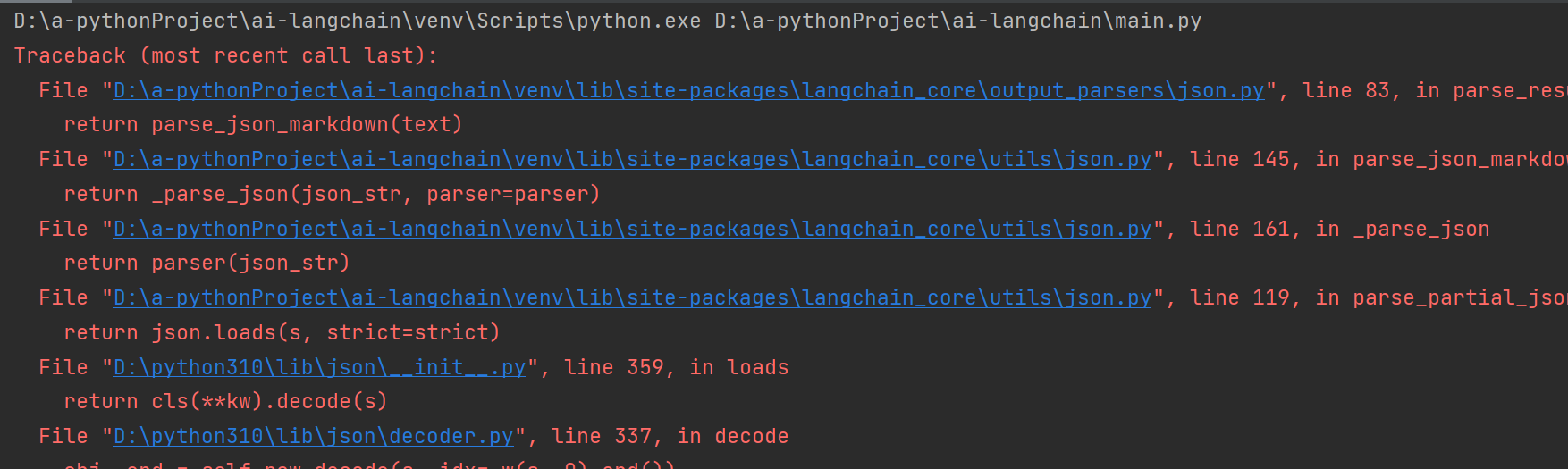

场景2:解析成自定义格式(比如Markdown表格)
如果业务需要大模型输出Markdown表格(比如商品对比),可以用StrOutputParser(基础文本解析器)配合自定义格式指令实现:
# 场景2:解析成Markdown表格(自定义格式)
from langchain_core.output_parsers import StrOutputParser # 基础文本解析器(不改变格式,只确保输出是字符串)
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# 1. 创建基础文本解析器(因为要保留Markdown格式,不用转成其他结构)
parser = StrOutputParser()
# 2. 自定义格式指令(告诉LLM要输出Markdown表格,包含商品名、价格、评分字段)
custom_format = """请以Markdown表格格式返回结果,表格包含3列:
- 商品名:商品的具体名称
- 价格:商品的参考价格(单位:元)
- 评分:1-5分的用户评分
表格格式示例:
| 商品名 | 价格 | 评分 |
|--------|------|------|
| 商品1 | 99 | 4.5 |
"""
# 3. 构建Prompt(注入自定义格式指令)
prompt = PromptTemplate(
template="请列举2个{product_type}的热门商品,按以下格式返回:\n{format_instructions}",
input_variables=["product_type"],
partial_variables={"format_instructions": custom_format} # 注入自定义格式
)
# 4. 创建模型并构建链
model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.3
)
chain = prompt | model | parser
result = chain.invoke({"product_type": "无线耳机"})
# 5. 输出Markdown表格(可以直接复制到博客、文档里用)
print(result)
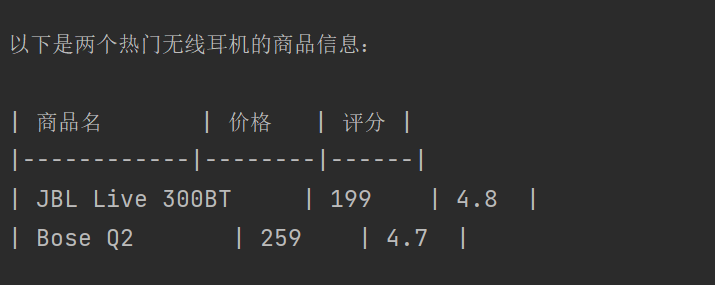
运行结果:
以下是两个热门无线耳机的商品信息:
| 商品名 | 价格 | 评分 |
|------------|--------|------|
| JBL Live 300BT | 199 | 4.8 |
| Bose Q2 | 259 | 4.7 |
关键技巧:
如果需要自定义格式,不用找特殊解析器,用StrOutputParser(基础文本解析器)+ 详细的格式示例即可——LLM能通过示例理解格式要求(这也是Prompt工程的“示例法”)。
六、避坑指南:大模型输出格式错了怎么办?
前面提到过一个关键问题:即使加了解析器,大模型也可能输出格式错误的内容(比如JSON少个括号、列表多了个顿号),这时候解析器会报错。
比如你用JSON解析器,但大模型输出:
{“name”:“张三”,“age”:25 // 少了闭合括号
这时候parse()方法会抛出OutputParserException异常。怎么解决?
方案1:加强Prompt格式约束(从源头避免)
在Prompt里明确“格式错误的后果”,比如:
template="请生成用户信息,必须严格按JSON格式输出,缺少括号/逗号会导致系统报错!包含name、age字段。{format_instructions}"
方案2:用“带重试的解析器”(自动修复小错误)
LangChain提供了RetryWithErrorOutputParser,如果解析失败,会自动把“错误原因”反馈给LLM,让LLM重新生成:
# 带重试的解析器示例
from langchain_core.output_parsers import JsonOutputParser, RetryWithErrorOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# 1. 创建基础JSON解析器
base_parser = JsonOutputParser()
# 2. 创建带重试的解析器(传入基础解析器和模型)
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=base_parser,
llm=model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.3
)
)
# 3. 构建Prompt
prompt = PromptTemplate(
template="生成用户信息,包含name、age。{format_instructions}",
input_variables=[],
partial_variables={"format_instructions": base_parser.get_format_instructions()}
)
# 4. 构建链(注意:这里用retry_parser)
chain = prompt | model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.3
) | retry_parser
# 5. 调用(即使第一次格式错,也会自动重试)
result = chain.invoke({})
print(result)
七、总结:Output Parser的核心价值
- 降低开发成本:不用自己写文本处理代码,直接拿结构化数据;
- 提高稳定性:统一输出格式,避免大模型“随心所欲”的输出风格;
- 易扩展:支持列表、JSON、自定义格式,满足不同业务需求。
最后:关注我,一起学AI大模型!
我是工藤学编程,正在持续更新「零基础学AI大模型」系列实战文章,从“理论”到“代码”,从“组件”到“项目”,带你一步步入门AI开发。
如果这篇文章对你有帮助,欢迎点赞、收藏、关注,你的支持是我更新的最大动力~ 我们下一篇再见!

更多推荐

 56
56 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)