
Google 智能体设计模式:推理技术
本文探讨了智能体(Agent)的高级推理方法,重点介绍了多步骤逻辑推理、问题分解与逐步求解等核心目标,旨在提升准确性、连贯性和鲁棒性。文章列举了复杂问答、数学问题、代码调试等典型应用场景,并详细阐述了思维链(CoT)、思维树(ToT)、自我纠正、程序辅助语言模型(PALMs)等核心推理技术。此外,还介绍了推理扩展定律、Deep Research应用、Agent的思考循环以及未来发展方向,强调AI正
·
1. 核心目标
- 本章探讨 智能体(Agent)高级推理方法,重点在于:
- 多步骤逻辑推理
- 问题分解与逐步求解
- 在推理过程中分配更多计算资源(时间/步骤)
- 目的:提升 准确性、连贯性、鲁棒性,尤其适合复杂任务。
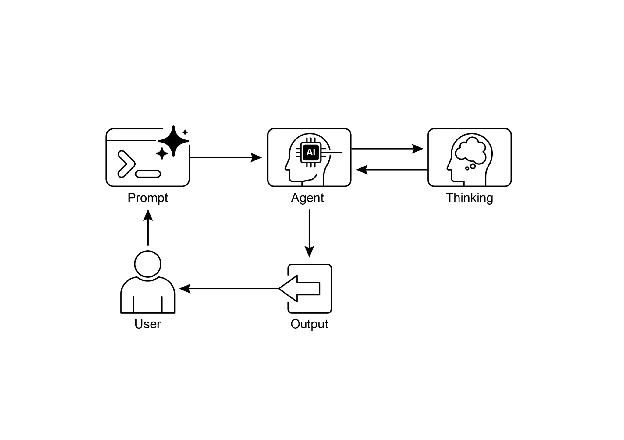
2. 典型应用场景
- 复杂问答:多跳查询、跨来源信息整合
- 数学问题:逐步分解、代码执行验证
- 代码调试与生成:迭代改进、自我纠错
- 战略规划:多方案权衡、动态调整
- 医疗诊断:系统性分析、外部工具辅助
- 法律分析:逐步推理、逻辑一致性验证
3. 核心推理技术
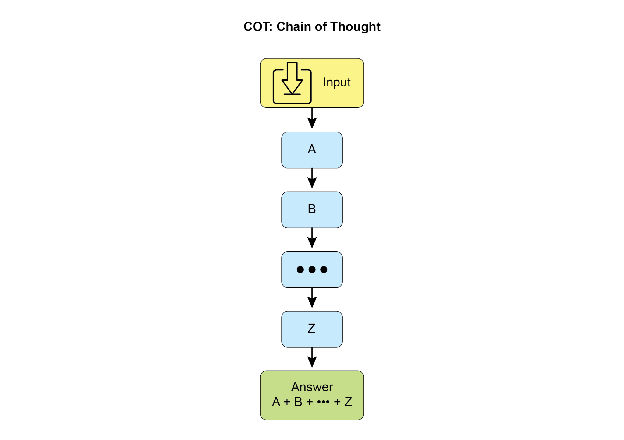
思维链(Chain-of-Thought, CoT)
- 逐步推理,分解复杂问题 → 子问题
- 提升透明度、准确性,可调试
- 适合算术、常识推理、符号操作
- 方法:少样本示例、显式提示“逐步思考”
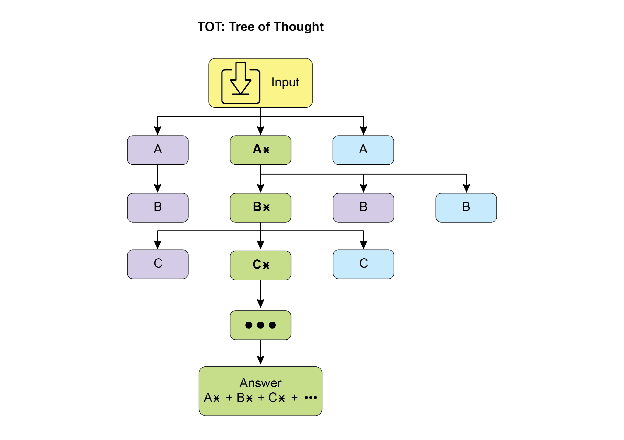
思维树(Tree-of-Thought, ToT)
- 在 CoT 基础上扩展 → 多分支探索
- 允许回溯、自我纠正、比较不同路径
- 适合战略规划与复杂决策
自我纠正(Self-Correction)
- Agent 内部批判性审查 → 识别错误、改进输出
- 迭代循环:起草 → 审查 → 修订
- 提升结果的可靠性与质量
程序辅助语言模型(PALMs)
- LLM + 符号推理(代码执行)
- 将复杂计算卸载到编程环境(如 Python)
- 结合自然语言理解与精确计算
可验证奖励强化学习(RLVR)
- 针对数学/代码等有标准答案的任务
- 通过试错学习生成长篇推理轨迹
- 发展出规划、监控、评估等高级技能
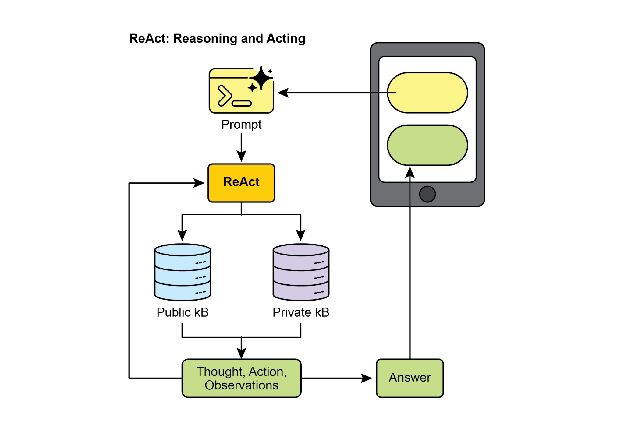
ReAct(Reason + Act)
- 将推理(CoT)与行动(工具调用)结合
- 循环:思考 → 行动 → 观察 → 思考…
- 动态调整计划,适合交互性强的任务
辩论链(CoD)
- 多个模型协作、互相批判 → 类似“AI 委员会”
- 提升准确性、减少偏见、增强透明度
辩论图(GoD)
- 非线性、多线程辩论网络
- 结论来自“最稳健的论点集群”
- 结合事实验证、模型共识
MASS(多智能体系统搜索)
- 自动化优化多智能体系统设计
- 三阶段优化:
- 块级提示词优化(单Agent角色优化)
- 工作流拓扑优化(Agent交互结构优化)
- 全局提示词优化(整体系统微调)
- 原则:高质量提示词 → 有影响力拓扑 → 全局优化
4. 推理扩展定律(Inference Scaling Law)
- 核心思想:性能随推理阶段的计算资源增加而提升
- 小模型 + 更多“思考时间” → 可超越大模型
- 关键平衡:
- 模型大小
- 响应延迟
- 运营成本
- 方法:多候选生成、自一致性、迭代改进
5. Deep Research 应用
- 代表性平台:Perplexity、Gemini、ChatGPT 高级功能
- 特点:
- 给 AI 一个“时间预算”
- AI 自主执行多轮搜索、推理、综合
- 输出结构化、全面的研究报告
- 流程:初始探索 → 推理改进 → 后续查询 → 最终综合
6. Agent 的思考循环
- 思考:分解问题、制定计划
- 行动:调用工具、执行任务
- 观察:接收反馈、修正计划
- 重复循环,直到完成任务
7. 关键要点总结
- 透明推理:多步骤计划 + 可审计性
- ReAct 框架:思考-行动-观察循环
- 推理扩展定律:性能依赖“思考时间”而非仅模型大小
- 协作推理:CoD、GoD → 多Agent协作减少偏见
- MASS 框架:自动化优化多Agent系统
- Deep Research:AI 作为自主研究助手
8. 结论
- AI 正在从“工具”进化为“自主Agent”
- 核心能力:
- 内部独白(CoT)
- 审议与自我纠正(ToT、自我纠正)
- 行动能力(ReAct)
- 协作推理(CoD、GoD)
- 未来方向:
- 多Agent协作
- 更透明、更可靠的自主系统
- 平衡性能、成本与延迟的推理扩展
更多推荐



 5
5 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)