
构建AI智能体:五十八、智能工作流引擎:基于LangGraph的模块化内容创作系统
本文介绍了一个基于LangGraph工作流引擎、Qwen大模型和Gradio界面的智能内容创作系统。该系统采用模块化设计,将内容创作过程分解为8个可配置节点(主题分析、大纲生成、内容创作等),通过工作流驱动实现从主题输入到完整内容(文字+配图)的全自动化生成。系统特点包括:1)灵活可配置的工作流模板;2)强类型状态管理确保数据安全;3)多重容错机制(重试/降级方案);4)实时可视化流程监控。该方案
一、系统概述
这是一个基于LangGraph工作流引擎、Qwen大模型和Gradio可视化界面的智能内容创作系统。系统深度集成先进的大语言模型服务,通过精心设计的提示词工程,确保生成内容的质量和相关性,并将传统的内容创作过程进行智能化重构,通过模块化设计和可视化交互,为用户提供从创意构思到完整内容产出的全流程解决方案,系统智能的将传统的内容创作过程分解为8个可配置的处理节点,通过模块化的工作流设计,实现了从主题输入到完整内容(包括文字和配图)的全自动化生成。
思路构想初步架构图:
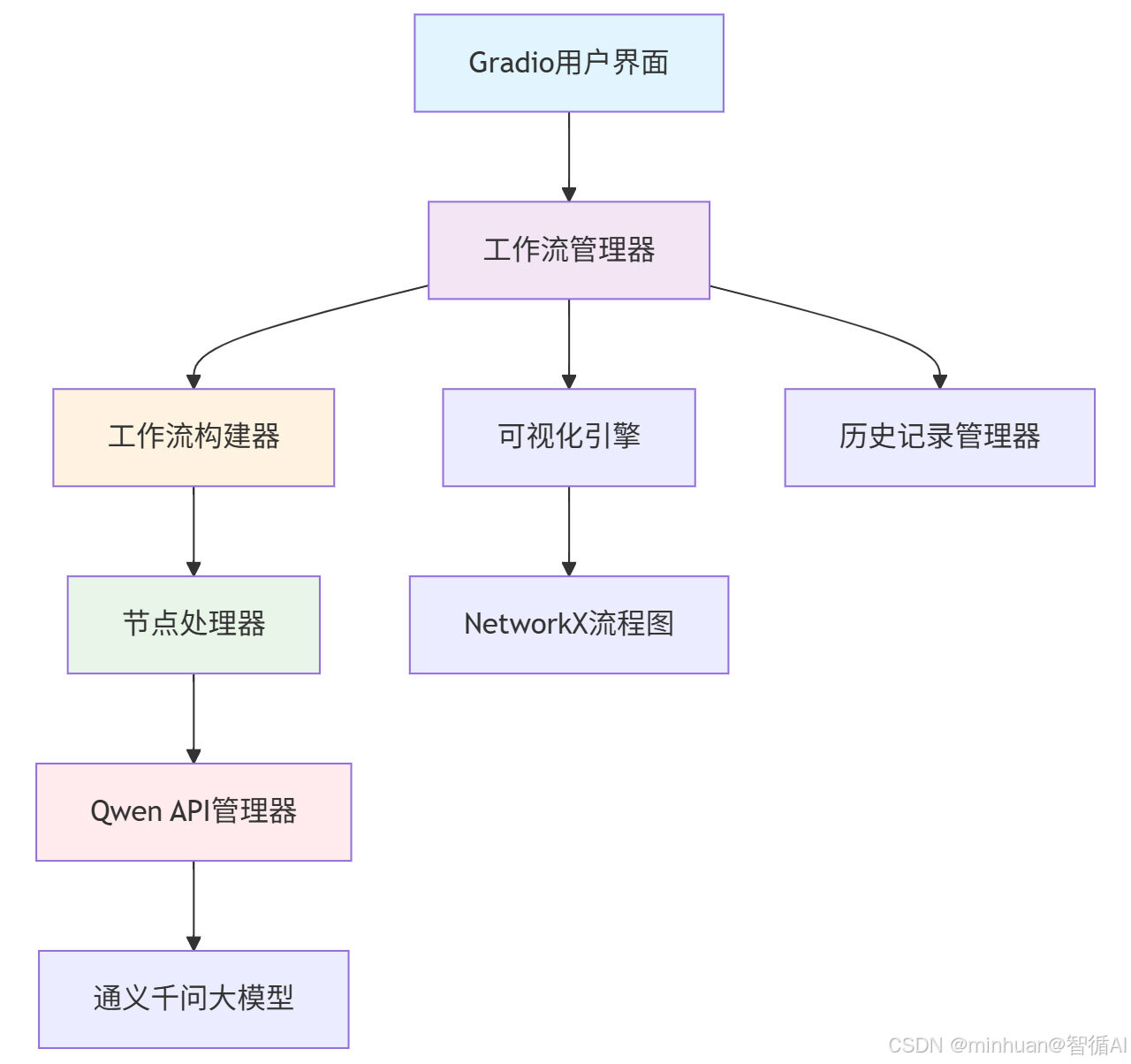
二、核心理念
1. 模块化处理流程
系统将复杂的内容创作任务分解为8个独立的处理节点,每个节点专注于特定的创作环节,传统的内容生成工具往往提供单一的"输入-输出"模式,缺乏灵活性和透明度。本系统的核心创新在于将内容创作过程解构为独立的处理单元,每个单元负责特定的创作任务,用户可以根据实际需求自由组合这些单元。
- 主题分析节点 - 深度理解用户输入的主题,分析内容方向和目标受众
- 大纲生成节点 - 构建逻辑清晰的内容结构框架
- 标题创作节点 - 生成吸引眼球且符合主题的文章标题
- 内容生成节点 - 基于大纲和标题产出详细的文章内容
- 摘要提炼节点 - 从长文中提取核心要点和精华摘要
- 标签提取节点 - 自动识别和生成内容关键词标签
- 图像提示词生成节点 - 为配图创作提供详细的视觉描述
- 图像生成节点 - 创建与内容主题相匹配的配图
设计优势:
- 灵活性:支持从简单的内容生成到完整的多媒体创作
- 透明度:每个处理步骤清晰可见,结果可追溯
- 可控性:用户可精确控制创作流程的每个环节
2. 工作流驱动架构
系统采用工作流引擎而非简单的函数调用链,这种架构带来了显著的工程优势:
- 状态管理:通过强类型的ContentState确保数据在节点间传递的类型安全和完整性
- 执行控制:支持条件分支、循环等复杂流程(当前为线性流程,具备扩展能力)
- 错误恢复:单个节点失败不影响整个工作流的健壮性
3. 动态流程构建
用户可以根据具体需求灵活配置处理流程:
- 预设模板:提供6种常用工作流模板,覆盖不同创作场景
- 自定义组合:支持任意节点的自由选择和排序
- 实时调整:在运行过程中动态调整节点启用状态
三、示例分解
1. 系统架构
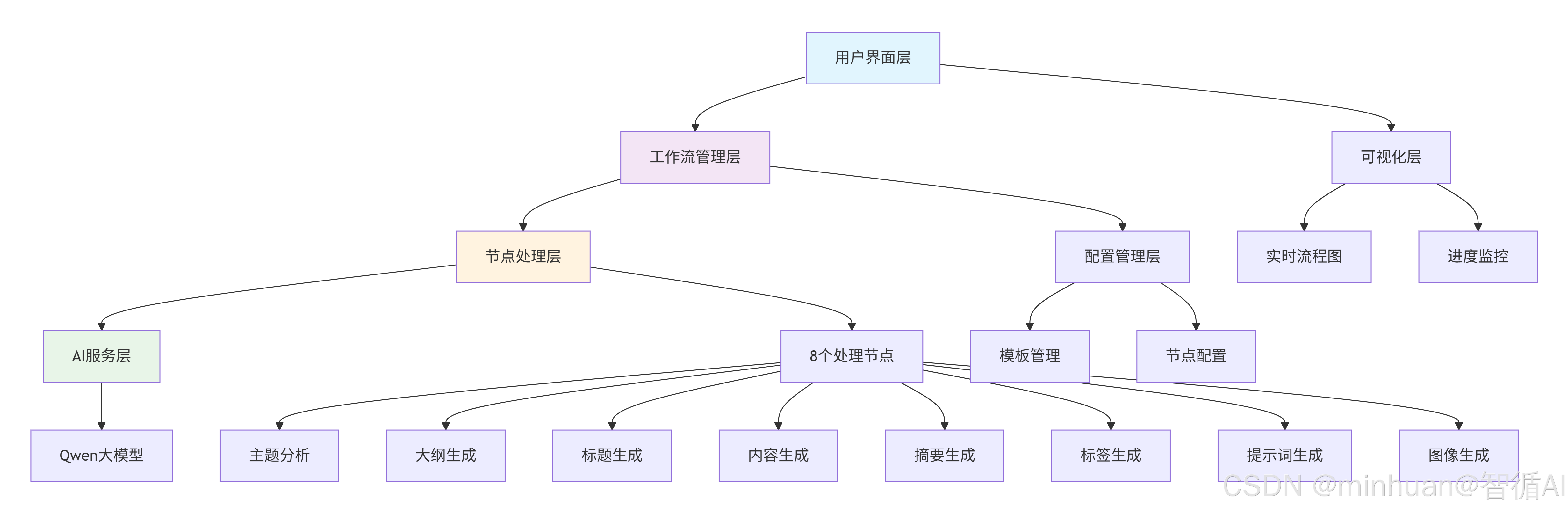
2. 核心解读
2.1 状态管理设计
# 定义工作流状态数据结构
# 使用TypedDict确保类型安全,便于IDE智能提示和类型检查
class ContentState(TypedDict):
topic: str # 用户输入的原始主题,作为工作流的起点
outline: List[str] # 生成的内容大纲,包含章节结构
title: str # 文章标题,用于吸引读者注意
content: str # 完整的文章内容,是核心输出
summary: str # 内容摘要,便于快速了解核心观点
tags: List[str] # 关键词标签,用于内容分类和SEO优化
image_prompt: str # 图像生成提示词,描述期望的视觉效果
generated_image: Optional[str] # 生成的图像文件路径,可为空
analysis: Dict # 主题分析结果,包含复杂度、受众等信息
current_step: str # 当前执行步骤,用于进度跟踪和状态显示设计说明:
- 强类型约束:使用TypedDict确保数据类型安全
- 状态完整性:涵盖内容创作全流程所需数据
- 步骤追踪:current_step字段实现执行状态跟踪
2. 2 节点配置管理
# 集中管理所有处理节点的配置信息
# 采用字典结构便于动态访问和配置管理
class NodeConfig:
NODES = {
"topic_analysis": {
"name": "主题分析", # 节点显示名称,用于UI展示
"description": "深度分析主题,确定内容方向和受众", # 功能描述
"enabled": True, # 默认启用状态,控制节点是否参与工作流
"icon": "🔍" # 可视化图标,增强用户体验
},
# 其他节点配置结构相同,确保一致性
# 这种配置驱动的设计便于后续添加新节点
}节点设计原则:
- 单一职责:每个节点只负责一个明确的功能
- 接口统一:所有节点接受相同状态参数,返回统一格式
- 可配置性:支持动态启用/禁用
节点执行流程:
主题分析 → 大纲生成 → 标题生成 → 内容生成 → 摘要生成 → 标签生成 → 提示词生成 → 图像生成
2.3 Qwen API管理器类
# 文本生成核心方法
# 实现重试机制、错误处理和降级方案的三重保障
class QwenAPIManager:
def __init__(self):
# 模型配置 - 使用Qwen Turbo版本平衡性能与成本
self.model_name = "qwen-turbo"
# 重试策略 - 提高服务可靠性
self.max_retries = 3 # 最大重试次数,避免无限循环
self.retry_delay = 1 # 重试间隔(秒),简单的固定延迟策略
def generate_text(self, prompt: str, max_length: int = 1500) -> str:
for attempt in range(self.max_retries):
try:
# API调用参数配置
response = Generation.call(
model=self.model_name, # 指定模型版本
prompt=prompt, # 用户输入的提示词
max_tokens=max_length, # 控制生成长度,避免过长响应
temperature=0.7, # 创造性控制:0-1,值越高越有创意
top_p=0.8, # 核采样参数:控制词汇选择范围
seed=1234 # 随机种子:确保结果可重现
)
# 响应状态检查
if response.status_code == HTTPStatus.OK:
return response.output.text # 成功返回生成文本
else:
# 错误处理:记录日志并决定是否重试
print(f"API调用失败: {response.code} - {response.message}")
if attempt < self.max_retries - 1:
time.sleep(self.retry_delay) # 延迟后重试
continue
# 所有重试失败后降级到模拟生成
return self._mock_text_generation(prompt)
except Exception as e:
# 异常处理:网络问题或其他运行时错误
print(f"API调用异常: {e}")
if attempt < self.max_retries - 1:
time.sleep(self.retry_delay)
continue
return self._mock_text_generation(prompt)
# 最终保障:确保总有返回值
return self._mock_text_generation(prompt)- 重试机制:采用指数退避策略,在遇到临时性网络问题时自动重试
- 降级方案:当API完全不可用时,切换到模拟生成模式保证基本功能
- 错误隔离:单个API调用失败不会导致整个系统崩溃
2.4 模拟生成方法
def _mock_text_generation(self, prompt: str) -> str:
# 预定义的响应模板,覆盖主要节点类型
mock_responses = {
"大纲": "1. 引言和背景介绍\n2. 核心概念解析\n3. 实际应用场景...",
"标题": "精彩主题的全面解析与实战指南",
"内容": "本文将深入探讨这一重要主题...",
"摘要": "本文系统性地介绍了相关知识点...",
"标签": "技术,创新,实践,指南,分析",
"分析": "主题复杂度: 中等\n受众群体: 技术人员..."
}
# 关键词匹配:根据提示词内容选择合适响应
for key, response in mock_responses.items():
if key in prompt:
return response
# 默认响应:确保始终有返回值
return "这是基于您提供主题的生成内容..."- 模拟文本生成 - 降级方案
- 在API服务不可用时提供基本功能,保证系统可用性
2.5 主题分析节点
def topic_analysis_node(self, state: ContentState) -> Dict:
topic = state["topic"] # 从状态中提取用户输入的主题
# 精心设计的提示词模板,引导模型进行结构化分析
prompt = f"""
请分析以下主题,并提供详细的分析报告:
主题:{topic}
请从以下维度进行分析:
1. 主题复杂程度评估
2. 目标受众群体分析
3. 建议的内容深度
4. 核心关键词提取
5. 内容结构建议
请用清晰的结构化格式回复。
"""
# 调用AI服务生成分析结果
analysis_result = self.api_manager.generate_text(prompt)
# 返回状态更新,包含分析结果和步骤标记
return {
"analysis": {
"topic_complexity": self._extract_complexity(analysis_result),
"target_audience": self._extract_audience(analysis_result),
"content_depth": self._extract_depth(analysis_result),
"keywords": self._extract_keywords(analysis_result),
"structure_suggestions": self._extract_structure(analysis_result)
},
"current_step": "主题分析完成" # 步骤标记,用于进度跟踪
}- 主题分析节点 - 工作流的第一步
- 深度理解创作主题,为后续节点提供分析基础
2.6 信息提取工具方法
def _extract_keywords(self, text: str) -> List[str]:
# 正则表达式模式:匹配"关键词:"后面的内容
keywords = re.findall(r'[关键|核心].*?[词|字]:([^\n,。]+)', text)
if keywords:
# 处理提取结果:分割、清理、过滤
return [kw.strip() for kw in keywords[0].split(',') if kw.strip()]
# 默认关键词:确保始终有返回值
return ["技术", "应用", "发展"]
def _parse_outline(self, outline_text: str) -> List[str]:
lines = outline_text.split('\n')
outline_items = []
for line in lines:
clean_line = line.strip()
# 识别各种列表格式:
# - 数字编号:1, 2, 3...
# - 中文编号:一、二、三...
# - 符号编号:-, •, ·, ■, □
# - 长文本行(排除说明性文字)
if (clean_line and
(clean_line.startswith(('1', '2', '3', '4', '5',
'一', '二', '三', '四', '五',
'-', '•', '·', '■', '□')) or
len(clean_line) > 10 and not clean_line.startswith('要求'))):
outline_items.append(clean_line)
# 默认大纲结构:确保解析失败时也有基本结构
return outline_items if outline_items else [
"一、引言与背景",
"二、核心概念解析",
"三、应用场景分析",
"四、优势特点总结",
"五、未来展望"
]- 从分析文本中提取关键词
- 使用正则表达式匹配特定模式,确保提取准确性
- 解析大纲文本 - 将模型返回的文本转换为结构化列表
- 支持多种列表格式,提高兼容性
2.7 工作流动态构建引擎
def build_workflow(self, enabled_nodes: List[str]):
# 动态构建工作流 - 核心引擎
# 根据用户选择的节点实时创建执行流程
# 创建LangGraph状态图实例
workflow = StateGraph(ContentState)
# 节点映射表:将节点ID映射到处理方法
node_mapping = {
"topic_analysis": self.nodes.topic_analysis_node,
"outline_generation": self.nodes.outline_generation_node,
# ... 其他节点映射
# 这种映射设计便于动态添加新节点
}
# 动态添加启用的节点
for node_id in enabled_nodes:
if node_id in node_mapping:
# 将节点添加到工作流图中
workflow.add_node(node_id, node_mapping[node_id])
# 输入验证:确保至少有一个节点被启用
if not enabled_nodes:
return None
# 设置工作流入口点(第一个启用的节点)
workflow.set_entry_point(enabled_nodes[0])
# 构建线性执行路径:节点1 → 节点2 → ... → 节点N
for i in range(len(enabled_nodes) - 1):
workflow.add_edge(enabled_nodes[i], enabled_nodes[i + 1])
# 连接结束节点:最后一个节点连接到END
workflow.add_edge(enabled_nodes[-1], END)
# 编译工作流为可执行对象
return workflow.compile()- 动态组合:支持任意节点组合的工作流
- 线性流程:确保执行顺序的确定性
- 灵活扩展:易于添加新的处理节点
2.8 流程图生成器
@staticmethod
def generate_workflow_diagram(enabled_steps: List[str], current_step: str = None):
try:
# 设置图形尺寸和创建有向图
plt.figure(figsize=(14, 6))
G = nx.DiGraph()
# 定义节点位置(水平排列布局)
pos = {}
node_colors = [] # 节点颜色数组
node_sizes = [] # 节点大小数组
# 添加开始节点(固定位置)
G.add_node("开始")
pos["开始"] = (0, 0)
node_colors.append('#4ECDC4') # 青色
node_sizes.append(3000)
# 添加启用的处理节点
for i, step in enumerate(enabled_steps):
# 获取节点显示名称
display_name = NodeConfig.NODES[step]["name"]
G.add_node(display_name)
# 水平排列:每个节点间隔2个单位
pos[display_name] = ((i + 1) * 2, 0)
# 设置节点样式:当前节点高亮显示
if step == current_step:
node_colors.append('#FF6B6B') # 红色高亮
node_sizes.append(4000) # 更大尺寸
else:
node_colors.append('#4ECDC4') # 青色
node_sizes.append(3000)
# 添加完成节点
G.add_node("完成")
pos["完成"] = ((len(enabled_steps) + 1) * 2, 0)
node_colors.append('#4ECDC4')
node_sizes.append(3000)
# 构建节点连接关系
if enabled_steps:
# 开始 → 第一个节点
G.add_edge("开始", NodeConfig.NODES[enabled_steps[0]]["name"])
# 中间节点连接
for i in range(len(enabled_steps) - 1):
current_display = NodeConfig.NODES[enabled_steps[i]]["name"]
next_display = NodeConfig.NODES[enabled_steps[i+1]]["name"]
G.add_edge(current_display, next_display)
# 最后一个节点 → 完成
G.add_edge(NodeConfig.NODES[enabled_steps[-1]]["name"], "完成")
# 图形绘制设置
plt.clf()
plt.figure(figsize=(14, 6))
# 绘制节点
nx.draw_networkx_nodes(G, pos,
node_color=node_colors,
node_size=node_sizes,
alpha=0.9,
edgecolors='black', # 黑色边框
linewidths=2)
# 绘制连接边
nx.draw_networkx_edges(G, pos,
edge_color='#666666', # 灰色边
arrows=True, # 显示方向箭头
arrowsize=25,
width=2,
alpha=0.7,
arrowstyle='->') # 箭头样式
# 添加节点标签
nx.draw_networkx_labels(G, pos,
font_size=9,
font_weight='bold')
# 图形美化
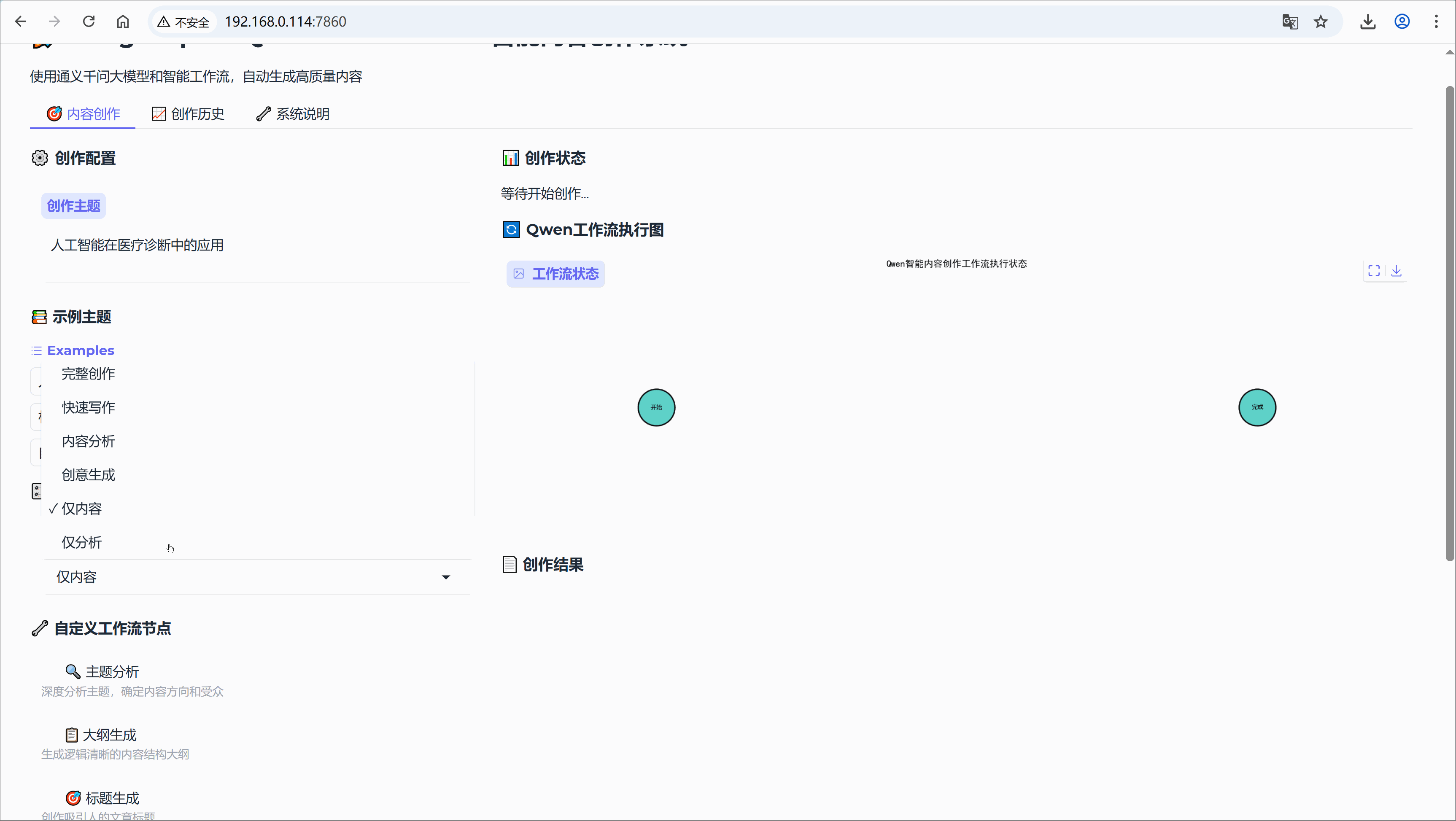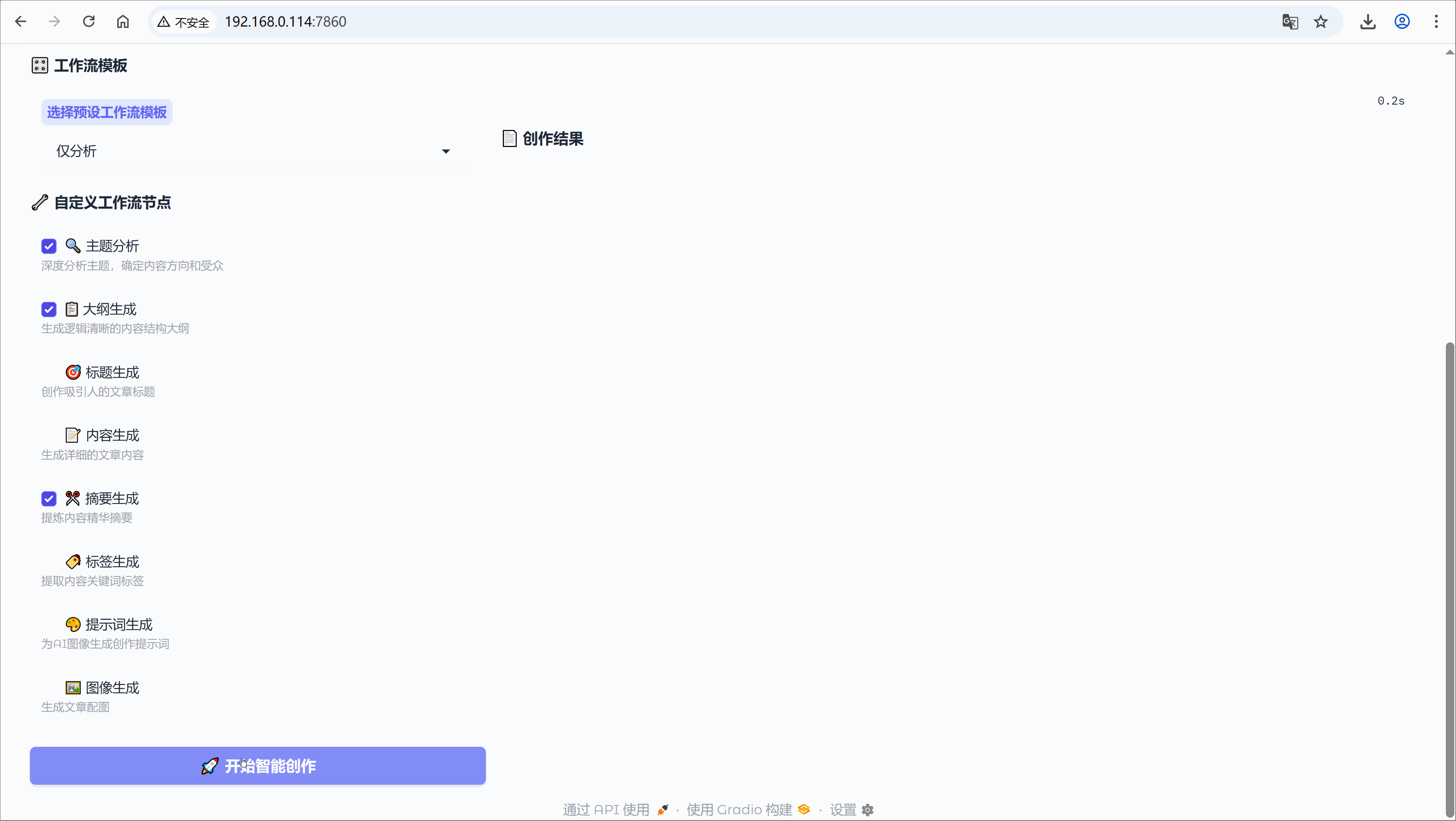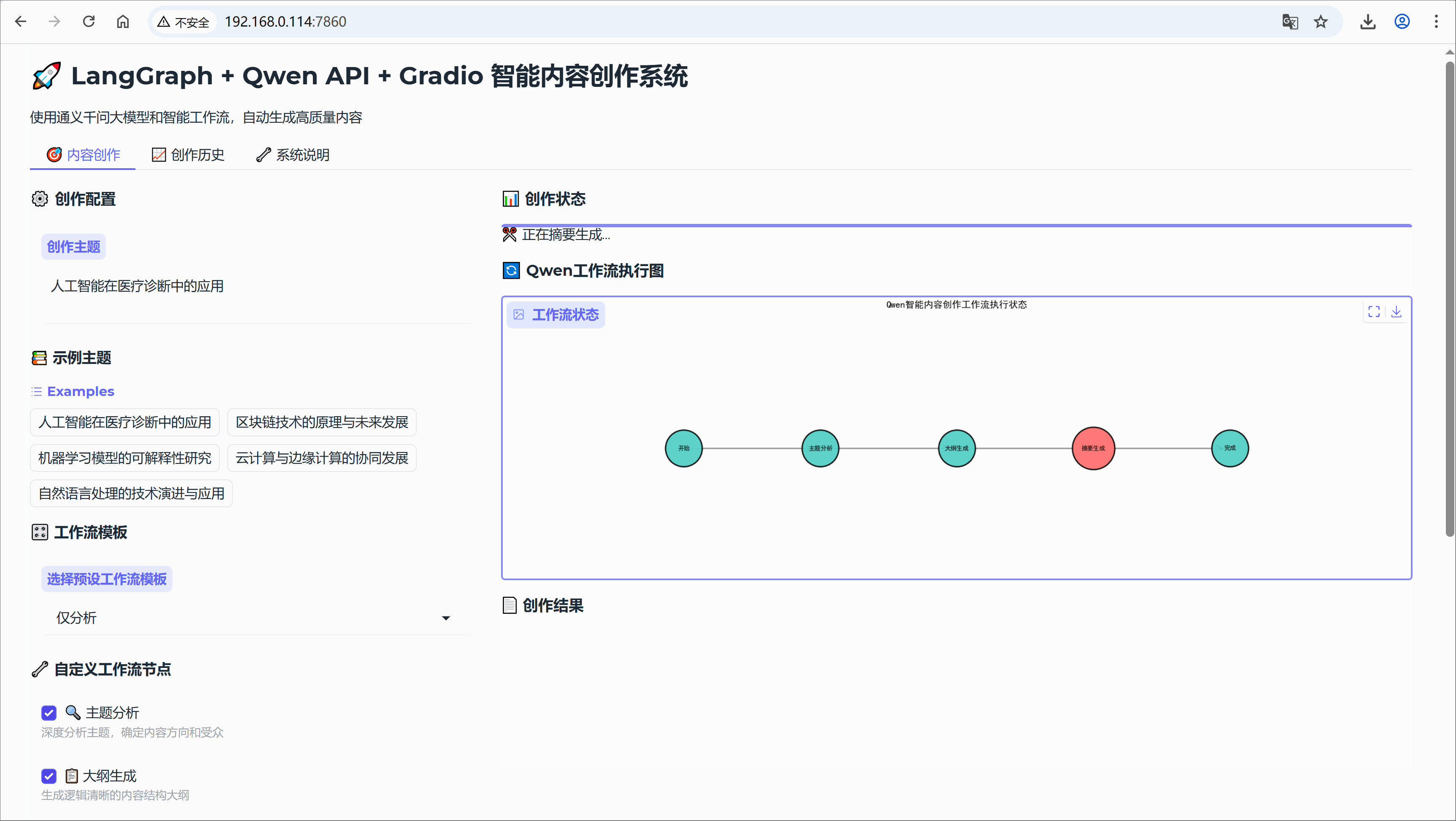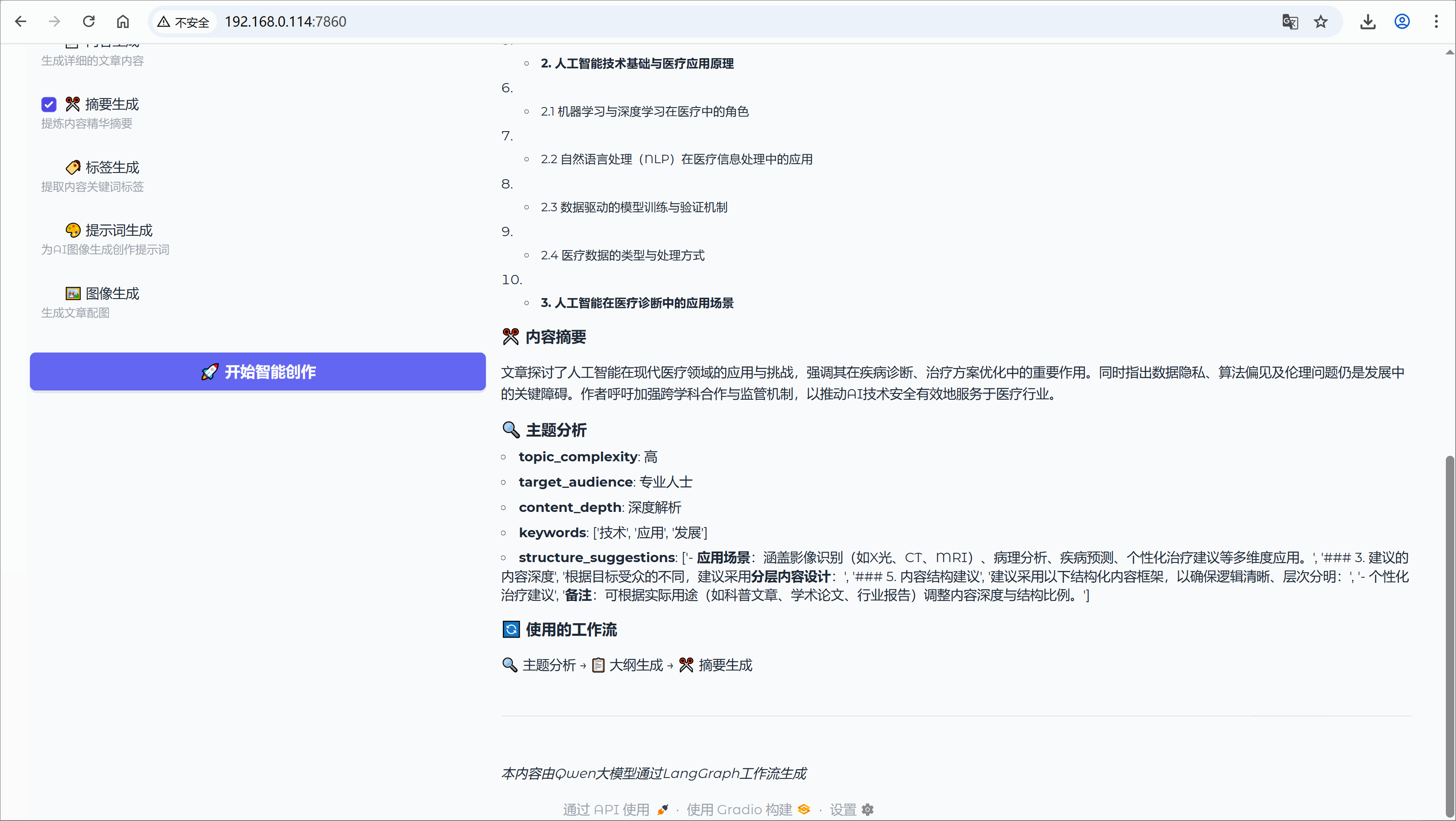
plt.title("Qwen智能内容创作工作流执行状态",
fontsize=14, fontweight='bold', pad=20)
plt.axis('off') # 隐藏坐标轴
plt.tight_layout() # 自动调整布局
# 保存为临时图片文件
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as tmp_file:
plt.savefig(tmp_file.name, format='png', dpi=100,
bbox_inches='tight', facecolor='white', edgecolor='none')
plt.close()
return tmp_file.name
except Exception as e:
# 错误处理:生成占位图
print(f"流程图生成错误: {e}")
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as tmp_file:
plt.figure(figsize=(10, 2))
plt.text(0.5, 0.5, "流程图生成中...",
ha='center', va='center', fontsize=16)
plt.axis('off')
plt.savefig(tmp_file.name, bbox_inches='tight', facecolor='white')
plt.close()
return tmp_file.name- 生成工作流执行流程图
- 使用NetworkX创建动态可视化,实时反映执行状态
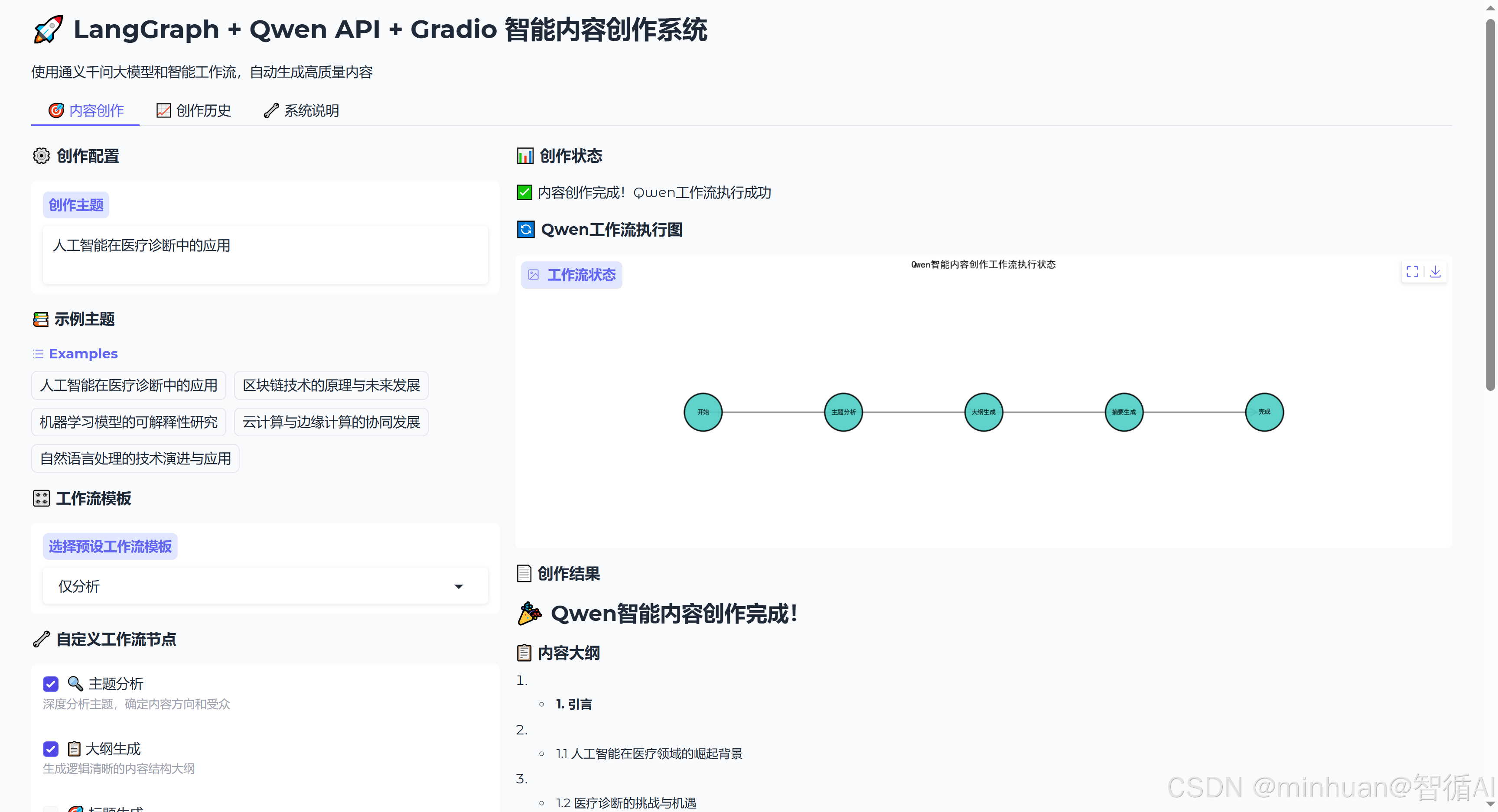
2.9 Gradio界面设计
with gr.Blocks(theme=gr.themes.Soft()) as interface:
gr.Markdown("# 🚀 LangGraph + Qwen API + Gradio 智能内容创作系统")
with gr.Tab("🎯 内容创作"):
with gr.Row():
# 左侧:配置面板
with gr.Column(scale=1):
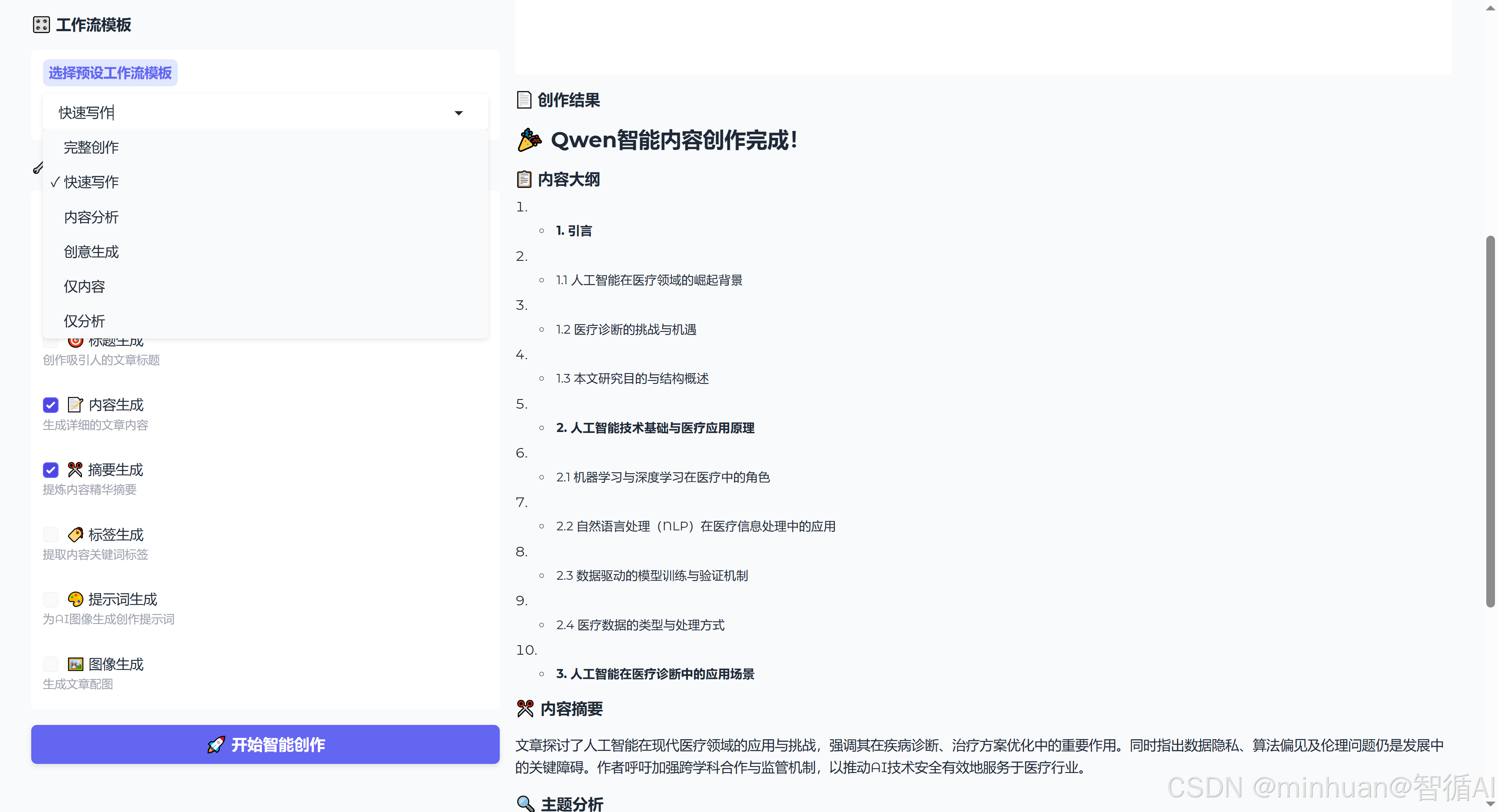
topic_input = gr.Textbox(label="创作主题")
template_selector = gr.Dropdown(label="工作流模板")
# 动态生成节点选择器
node_checkboxes = []
for node_id, node_info in NodeConfig.NODES.items():
checkbox = gr.Checkbox(
label=f"{node_info['icon']} {node_info['name']}",
value=node_info["enabled"],
info=node_info["description"]
)
node_checkboxes.append(checkbox)
# 右侧:结果显示
with gr.Column(scale=2):
status_display = gr.Markdown()
diagram_display = gr.Image(height=300)
output_display = gr.Markdown()2.10 工作流模板系统
# 预设工作流模板配置
# 提供常用场景的快速配置,降低用户使用门槛
WORKFLOW_TEMPLATES = {
"完整创作": [
"topic_analysis", "outline_generation", "title_generation",
"content_generation", "summary_generation", "tags_generation",
"image_prompt_generation", "image_generation"
], # 全功能模式:适合正式内容发布
"快速写作": [
"topic_analysis", "outline_generation", "content_generation", "summary_generation"
], # 核心流程:平衡质量与效率
"内容分析": [
"topic_analysis", "outline_generation", "summary_generation", "tags_generation"
], # 分析模式:专注于内容理解和总结
"创意生成": [
"topic_analysis", "title_generation", "content_generation", "image_prompt_generation"
], # 创意模式:强调标题和视觉元素
"仅内容": [
"content_generation"
], # 极简模式:快速获得文本内容
"仅分析": [
"topic_analysis", "outline_generation", "summary_generation"
] # 调研模式:深度理解主题
}系统提供了6种预设模板,覆盖了常见的使用场景:
- 完整创作:适合正式的、需要完整内容资产的场景
- 快速写作:适合日常内容产出,平衡质量和效率
- 内容分析:适合调研和分析类任务
- 创意生成:适合需要视觉元素的内容创作
- 仅内容:最简模式,快速获得文本内容
- 仅分析:专注于主题理解和结构规划
2.11 完整执行序列
def execute_content_workflow(topic, *node_checkboxes, progress=gr.Progress()):
# 1. 输入验证
if not topic.strip():
yield "❌ 请输入主题内容", None, None
return
# 2. 获取启用的节点
node_ids = list(NodeConfig.NODES.keys())
enabled_nodes = [node_ids[i] for i, checked in enumerate(node_checkboxes) if checked]
# 3. 逐步执行显示
for i, step in enumerate(enabled_nodes):
# 更新进度条
progress((i, len(enabled_nodes)), desc=f"执行 {NodeConfig.NODES[step]['name']}...")
# 生成实时流程图
diagram_path = WorkflowVisualizer.generate_workflow_diagram(enabled_nodes, step)
# 显示执行状态
status_text = f"{NodeConfig.NODES[step]['icon']} 正在{NodeConfig.NODES[step]['name']}..."
yield status_text, diagram_path, None
time.sleep(1.5) # 进度显示延迟
# 4. 实际执行工作流
final_result = workflow_manager.execute_workflow(topic, enabled_nodes)
# 5. 生成最终结果
final_diagram = WorkflowVisualizer.generate_workflow_diagram(enabled_nodes, "完成")
output_content = format_output(final_result, enabled_nodes)
yield "✅ 内容创作完成!", final_diagram, output_content2.12 结果格式化
def format_output(result, enabled_nodes):
output = "## 🎉 Qwen智能内容创作完成!\n\n"
# 动态显示启用的节点结果
if "title_generation" in enabled_nodes and "title" in result:
output += f"### 📝 生成标题\n**{result['title']}**\n\n"
if "outline_generation" in enabled_nodes and "outline" in result:
output += "### 📋 内容大纲\n"
for i, item in enumerate(result['outline'][:10], 1):
output += f"{i}. {item}\n"
output += "\n"
# ... 其他节点结果格式化
# 显示工作流路径
used_nodes = [NodeConfig.NODES[node_id]["icon"] + " " + NodeConfig.NODES[node_id]["name"]
for node_id in enabled_nodes]
output += f"### 🔄 使用的工作流\n{' → '.join(used_nodes)}\n\n"
return output2.13 添加新节点流程
# 1. 在NodeConfig中注册新节点
"new_node": {
"name": "新功能",
"description": "新功能描述",
"enabled": True,
"icon": "⭐"
}
# 2. 实现节点处理方法
def new_node_function(self, state: ContentState) -> Dict:
# 节点处理逻辑
return {"new_data": result, "current_step": "新功能完成"}
# 3. 更新节点映射
node_mapping = {
# ... 现有映射
"new_node": self.nodes.new_node_function
}3. 执行流程图
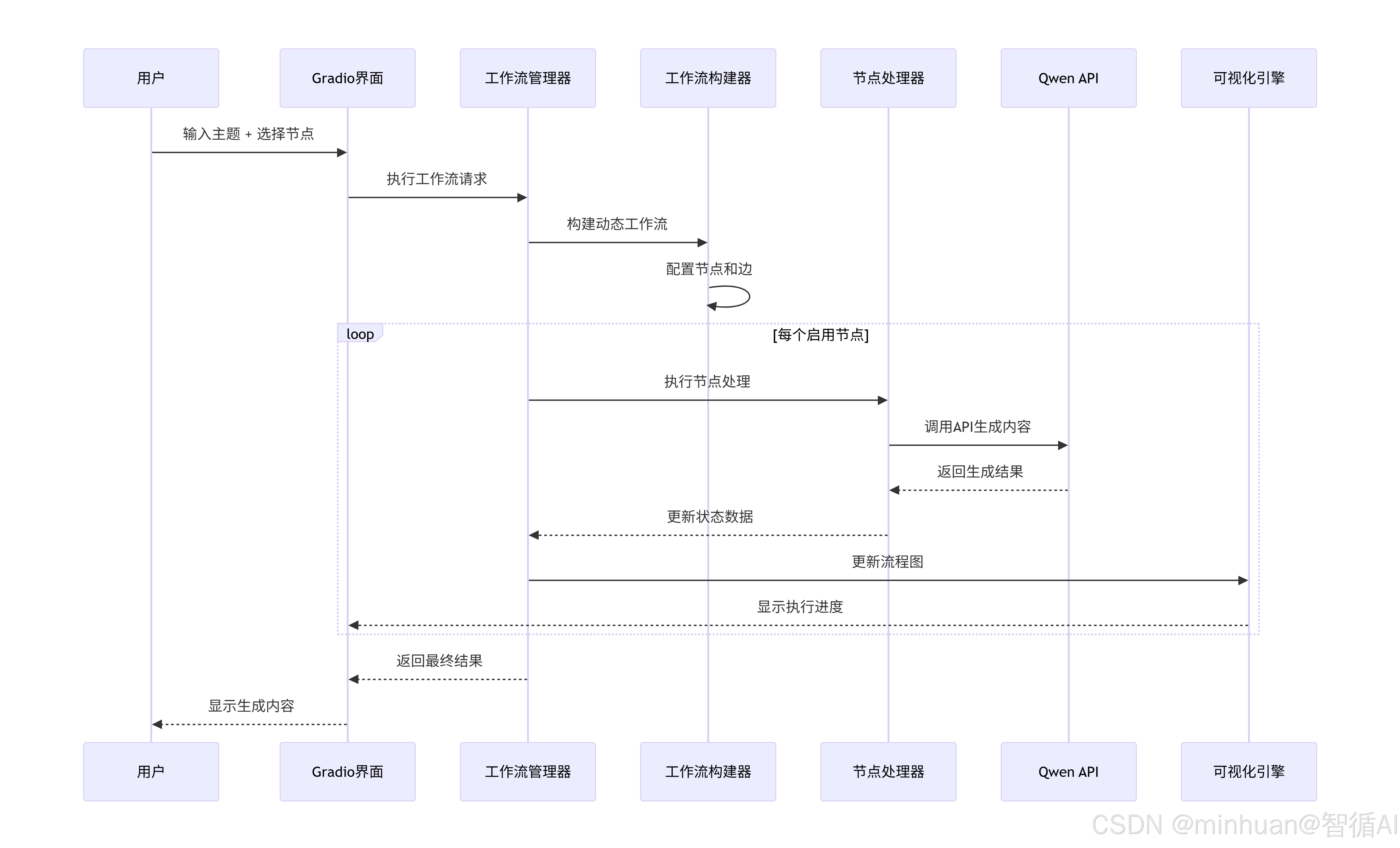
四、应用场景
- 内容营销团队:营销团队可以使用"完整创作"模板快速生成博客文章、社交媒体内容等,大幅提升内容产出效率。
- 教育机构:教师可以使用"内容分析"模板生成课程大纲和学习材料,确保内容的专业性和结构性。
- 个人创作者:自由创作者可以根据具体需求选择不同的模板,在质量、速度和创意之间找到最佳平衡。
- 企业知识管理:企业可以使用系统生成内部培训材料、技术文档等,确保内容风格的一致性。
五、总结
通过构思这个内容创作系统,感叹到作为程序员需要构建的多维能力模型:
- 架构思维 - 从微观代码到宏观系统的设计能力
- 工程思维 - 健壮性、可维护性、扩展性的平衡
- AI思维 - 理解并驾驭非确定性系统的能力
- 用户体验思维 - 技术实现与用户需求的完美结合
- 业务思维 - 将领域知识转化为技术方案的能力
- 产品思维 - 从用户价值角度思考技术决策
这个系统不仅是一个技术实现的范例,更是现代软件开发理念的集中体现。它告诉我们,优秀的程序员不再是单纯的代码编写者,而是复杂系统的设计师、用户体验的塑造者和业务价值的创造者。
在AI技术快速发展的今天,程序员的核心竞争力正在从编写代码转向设计智能系统,从实现功能转向创造价值。这种思维转变不仅影响个人的职业发展,更将决定整个行业的发展方向。
附录:完整实例代码
from langgraph.graph import StateGraph, END
from typing import Dict, TypedDict, List, Optional
import gradio as gr
import matplotlib.pyplot as plt
import networkx as nx
import tempfile
import os
import json
import re
import time
from http import HTTPStatus
import dashscope
from dashscope import Generation
from PIL import Image, ImageDraw, ImageFont
# 配置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 配置 Qwen API
dashscope.api_key = "your-api-key-here" # 请替换为您的实际 API Key
# 定义工作流状态
class ContentState(TypedDict):
topic: str
outline: List[str]
title: str
content: str
summary: str
tags: List[str]
image_prompt: str
generated_image: Optional[str]
analysis: Dict
current_step: str
# 节点配置类
class NodeConfig:
NODES = {
"topic_analysis": {
"name": "主题分析",
"description": "深度分析主题,确定内容方向和受众",
"enabled": True,
"icon": "🔍"
},
"outline_generation": {
"name": "大纲生成",
"description": "生成逻辑清晰的内容结构大纲",
"enabled": True,
"icon": "📋"
},
"title_generation": {
"name": "标题生成",
"description": "创作吸引人的文章标题",
"enabled": True,
"icon": "🎯"
},
"content_generation": {
"name": "内容生成",
"description": "生成详细的文章内容",
"enabled": True,
"icon": "📝"
},
"summary_generation": {
"name": "摘要生成",
"description": "提炼内容精华摘要",
"enabled": True,
"icon": "✂️"
},
"tags_generation": {
"name": "标签生成",
"description": "提取内容关键词标签",
"enabled": True,
"icon": "🏷️"
},
"image_prompt_generation": {
"name": "提示词生成",
"description": "为AI图像生成创作提示词",
"enabled": True,
"icon": "🎨"
},
"image_generation": {
"name": "图像生成",
"description": "生成文章配图",
"enabled": True,
"icon": "🖼️"
}
}
# Qwen API 管理器
class QwenAPIManager:
def __init__(self):
self.model_name = "qwen-turbo"
self.max_retries = 3
self.retry_delay = 1
def generate_text(self, prompt: str, max_length: int = 1500) -> str:
"""使用 Qwen API 生成文本"""
for attempt in range(self.max_retries):
try:
response = Generation.call(
model=self.model_name,
prompt=prompt,
max_tokens=max_length,
temperature=0.7,
top_p=0.8,
seed=1234
)
if response.status_code == HTTPStatus.OK:
return response.output.text
else:
print(f"API调用失败: {response.code} - {response.message}")
if attempt < self.max_retries - 1:
time.sleep(self.retry_delay)
continue
return self._mock_text_generation(prompt)
except Exception as e:
print(f"API调用异常: {e}")
if attempt < self.max_retries - 1:
time.sleep(self.retry_delay)
continue
return self._mock_text_generation(prompt)
return self._mock_text_generation(prompt)
def generate_image(self, prompt: str) -> str:
"""使用 Qwen 生成图像(模拟)"""
return self._mock_image_generation(prompt)
def _mock_text_generation(self, prompt: str) -> str:
"""模拟文本生成(备用方案)"""
mock_responses = {
"大纲": "1. 引言和背景介绍\n2. 核心概念解析\n3. 实际应用场景\n4. 优势特点分析\n5. 未来发展趋势\n6. 总结与展望",
"标题": "精彩主题的全面解析与实战指南",
"内容": "本文将深入探讨这一重要主题。首先介绍基本概念和发展历程,然后分析核心特性和应用价值。通过实际案例展示在不同场景下的应用效果,最后总结未来发展方向和对行业的影响。",
"摘要": "本文系统性地介绍了相关知识点,涵盖基础概念、核心特性、应用场景和发展趋势,为读者提供全面的理解和实践指导。",
"标签": "技术,创新,实践,指南,分析",
"分析": "主题复杂度: 中等\n受众群体: 技术人员和爱好者\n内容深度: 深入浅出\n关键词: 技术,发展,应用\n结构建议: 总分总结构"
}
for key, response in mock_responses.items():
if key in prompt:
return response
return f"这是基于您提供主题的生成内容。Qwen大模型已经理解了您的需求,并生成了相关的内容。"
def _mock_image_generation(self, prompt: str) -> str:
"""模拟图像生成"""
width, height = 400, 300
image = Image.new('RGB', (width, height), color='lightblue')
draw = ImageDraw.Draw(image)
# 画一个矩形边框
draw.rectangle([50, 50, 350, 250], outline='blue', width=3)
# 添加文字
try:
font = ImageFont.truetype("arial.ttf", 20)
except:
try:
font = ImageFont.load_default()
except:
font = None
text_x, text_y = width//2, height//2
if font:
draw.text((text_x-100, text_y-30), "AI生成配图", fill='darkblue', font=font)
draw.text((text_x-80, text_y), "Qwen工作流", fill='darkred', font=font)
else:
draw.text((text_x-100, text_y-30), "AI生成配图", fill='darkblue')
draw.text((text_x-80, text_y), "Qwen工作流", fill='darkred')
# 保存到临时文件
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as tmp_file:
image.save(tmp_file.name)
return tmp_file.name
# 工作流节点处理器
class ContentWorkflowNodes:
def __init__(self):
self.api_manager = QwenAPIManager()
def topic_analysis_node(self, state: ContentState) -> Dict:
"""主题分析节点"""
topic = state["topic"]
prompt = f"""
请分析以下主题,并提供详细的分析报告:
主题:{topic}
请从以下维度进行分析:
1. 主题复杂程度评估
2. 目标受众群体分析
3. 建议的内容深度
4. 核心关键词提取
5. 内容结构建议
请用清晰的结构化格式回复。
"""
analysis_result = self.api_manager.generate_text(prompt)
return {
"analysis": {
"topic_complexity": self._extract_complexity(analysis_result),
"target_audience": self._extract_audience(analysis_result),
"content_depth": self._extract_depth(analysis_result),
"keywords": self._extract_keywords(analysis_result),
"structure_suggestions": self._extract_structure(analysis_result)
},
"current_step": "主题分析完成"
}
def outline_generation_node(self, state: ContentState) -> Dict:
"""大纲生成节点"""
topic = state["topic"]
analysis = state.get("analysis", {})
prompt = f"""
请为以下主题生成一个详细的内容大纲:
主题:{topic}
分析信息:{json.dumps(analysis, ensure_ascii=False)}
要求:
1. 结构完整,逻辑清晰
2. 包含主要章节和子章节
3. 层次分明,便于后续内容展开
4. 至少包含5个主要部分
请用清晰的列表格式回复。
"""
outline_text = self.api_manager.generate_text(prompt)
outline_items = self._parse_outline(outline_text)
return {
"outline": outline_items,
"current_step": "大纲生成完成"
}
def title_generation_node(self, state: ContentState) -> Dict:
"""标题生成节点"""
topic = state["topic"]
outline = state.get("outline", [])
prompt = f"""
基于以下主题和大纲,生成3个吸引人的文章标题:
主题:{topic}
大纲要点:{outline[:3]}...
要求:
1. 标题要吸引人且专业
2. 包含核心关键词
3. 长度在15-25字之间
4. 风格要符合主题性质
请提供3个不同的标题选项。
"""
titles_text = self.api_manager.generate_text(prompt)
best_title = self._select_best_title(titles_text, topic)
return {
"title": best_title,
"current_step": "标题生成完成"
}
def content_generation_node(self, state: ContentState) -> Dict:
"""内容生成节点"""
topic = state["topic"]
outline = state.get("outline", [])
title = state.get("title", "")
prompt = f"""
请根据以下信息生成一篇完整的文章内容:
主题:{topic}
标题:{title}
大纲结构:{outline}
写作要求:
1. 内容详实丰富,信息准确
2. 结构清晰,逻辑连贯
3. 语言生动专业,可读性强
4. 包含具体案例或数据支持
5. 字数控制在800-1200字
请直接生成完整的文章内容。
"""
content = self.api_manager.generate_text(prompt, max_length=2000)
return {
"content": content,
"current_step": "内容生成完成"
}
def summary_generation_node(self, state: ContentState) -> Dict:
"""摘要生成节点"""
content = state.get("content", "")
title = state.get("title", "")
prompt = f"""
请为以下文章生成一个简洁的摘要:
文章标题:{title}
文章内容(部分):{content[:300]}...
摘要要求:
1. 准确概括文章核心内容
2. 突出关键信息和观点
3. 语言精炼,长度在100-150字
4. 保持专业性和可读性
请直接生成摘要内容。
"""
summary = self.api_manager.generate_text(prompt, max_length=200)
return {
"summary": summary,
"current_step": "摘要生成完成"
}
def tags_generation_node(self, state: ContentState) -> Dict:
"""标签生成节点"""
content = state.get("content", "")
title = state.get("title", "")
prompt = f"""
请为以下内容生成5-8个相关标签:
标题:{title}
内容摘要:{content[:200]}...
标签要求:
1. 准确反映内容主题
2. 涵盖不同维度和方面
3. 简洁明了,便于分类
4. 用中文逗号分隔
请直接提供标签列表。
"""
tags_text = self.api_manager.generate_text(prompt)
tags = self._parse_tags(tags_text)
return {
"tags": tags,
"current_step": "标签生成完成"
}
def image_prompt_generation_node(self, state: ContentState) -> Dict:
"""图像提示词生成节点"""
title = state.get("title", "")
content = state.get("content", "")
tags = state.get("tags", [])
prompt = f"""
请为以下文章生成一个适合AI图像生成的提示词:
文章标题:{title}
内容关键词:{tags}
内容摘要:{content[:150]}...
提示词要求:
1. 描述具体、生动、有画面感
2. 包含主要的视觉元素
3. 适合文本到图像的AI生成
4. 体现文章的核心主题
5. 长度在50-100字
请直接生成图像提示词。
"""
image_prompt = self.api_manager.generate_text(prompt)
return {
"image_prompt": image_prompt,
"current_step": "图像提示词生成完成"
}
def image_generation_node(self, state: ContentState) -> Dict:
"""图像生成节点"""
image_prompt = state.get("image_prompt", "")
title = state.get("title", "")
if not image_prompt:
image_prompt = f"文章配图:{title}"
image_path = self.api_manager.generate_image(image_prompt)
return {
"generated_image": image_path,
"current_step": "图像生成完成"
}
def _extract_complexity(self, text: str) -> str:
"""提取复杂度"""
if "复杂" in text or "难" in text:
return "高"
elif "简单" in text or "基础" in text:
return "低"
return "中等"
def _extract_audience(self, text: str) -> str:
"""提取受众群体"""
if "专业" in text or "技术" in text:
return "专业人士"
elif "初学" in text or "入门" in text:
return "初学者"
return "普通读者"
def _extract_depth(self, text: str) -> str:
"""提取内容深度"""
if "深入" in text or "深度" in text:
return "深度解析"
elif "基础" in text or "入门" in text:
return "基础介绍"
return "全面介绍"
def _extract_keywords(self, text: str) -> List[str]:
"""提取关键词"""
keywords = re.findall(r'[关键|核心].*?[词|字]:([^\n,。]+)', text)
if keywords:
return [kw.strip() for kw in keywords[0].split(',') if kw.strip()]
return ["技术", "应用", "发展"]
def _extract_structure(self, text: str) -> List[str]:
"""提取结构建议"""
suggestions = []
lines = text.split('\n')
for line in lines:
if any(word in line for word in ['建议', '结构', '应该', '推荐']):
clean_line = re.sub(r'^\d+[\.、]?\s*', '', line.strip())
if clean_line and len(clean_line) > 8:
suggestions.append(clean_line)
return suggestions if suggestions else ["采用总分总结构", "包含案例分析", "添加实践指导"]
def _parse_outline(self, outline_text: str) -> List[str]:
"""解析大纲文本"""
lines = outline_text.split('\n')
outline_items = []
for line in lines:
clean_line = line.strip()
if (clean_line and
(clean_line.startswith(('1', '2', '3', '4', '5', '6', '7', '8', '9',
'一', '二', '三', '四', '五',
'-', '•', '·', '■', '□')) or
len(clean_line) > 10 and not clean_line.startswith('要求'))):
outline_items.append(clean_line)
return outline_items if outline_items else [
"一、引言与背景",
"二、核心概念解析",
"三、应用场景分析",
"四、优势特点总结",
"五、未来展望"
]
def _select_best_title(self, titles_text: str, topic: str) -> str:
"""选择最佳标题"""
lines = titles_text.split('\n')
for line in lines:
clean_line = line.strip()
if (clean_line and
not clean_line.startswith(('1', '2', '3', '要求', '标题', '选项', '##')) and
len(clean_line) > 8 and len(clean_line) < 50):
return clean_line
return f"{topic}的全面解析与实践指南"
def _parse_tags(self, tags_text: str) -> List[str]:
"""解析标签文本"""
clean_text = re.sub(r'[标签|关键词].*?[::]', '', tags_text)
tags = []
for part in clean_text.split(','):
tag = part.strip()
if tag and len(tag) < 10:
tags.append(tag)
return tags[:8] if tags else ["技术", "创新", "应用", "发展"]
# 工作流构建器
class ContentWorkflowBuilder:
def __init__(self):
self.nodes = ContentWorkflowNodes()
def build_workflow(self, enabled_nodes: List[str]):
"""构建内容创作工作流"""
workflow = StateGraph(ContentState)
# 添加启用的节点
node_mapping = {
"topic_analysis": self.nodes.topic_analysis_node,
"outline_generation": self.nodes.outline_generation_node,
"title_generation": self.nodes.title_generation_node,
"content_generation": self.nodes.content_generation_node,
"summary_generation": self.nodes.summary_generation_node,
"tags_generation": self.nodes.tags_generation_node,
"image_prompt_generation": self.nodes.image_prompt_generation_node,
"image_generation": self.nodes.image_generation_node
}
# 添加启用的节点
for node_id in enabled_nodes:
if node_id in node_mapping:
workflow.add_node(node_id, node_mapping[node_id])
if not enabled_nodes:
return None
# 设置入口点
workflow.set_entry_point(enabled_nodes[0])
# 定义工作流路径
for i in range(len(enabled_nodes) - 1):
workflow.add_edge(enabled_nodes[i], enabled_nodes[i + 1])
workflow.add_edge(enabled_nodes[-1], END)
return workflow.compile()
# 可视化工具
class WorkflowVisualizer:
@staticmethod
def generate_workflow_diagram(enabled_steps: List[str], current_step: str = None) -> str:
"""生成工作流执行流程图"""
try:
plt.figure(figsize=(14, 6))
G = nx.DiGraph()
# 定义节点位置
pos = {}
node_colors = []
node_sizes = []
# 添加开始节点
G.add_node("开始")
pos["开始"] = (0, 0)
node_colors.append('#4ECDC4')
node_sizes.append(3000)
# 添加启用的节点
for i, step in enumerate(enabled_steps):
display_name = NodeConfig.NODES[step]["name"]
G.add_node(display_name)
pos[display_name] = ((i + 1) * 2, 0)
# 设置节点颜色和大小
if step == current_step:
node_colors.append('#FF6B6B') # 当前步骤红色
node_sizes.append(4000)
else:
node_colors.append('#4ECDC4') # 其他步骤青色
node_sizes.append(3000)
# 添加结束节点
G.add_node("完成")
pos["完成"] = ((len(enabled_steps) + 1) * 2, 0)
node_colors.append('#4ECDC4')
node_sizes.append(3000)
# 添加边
if enabled_steps:
G.add_edge("开始", NodeConfig.NODES[enabled_steps[0]]["name"])
for i in range(len(enabled_steps) - 1):
current_display = NodeConfig.NODES[enabled_steps[i]]["name"]
next_display = NodeConfig.NODES[enabled_steps[i+1]]["name"]
G.add_edge(current_display, next_display)
G.add_edge(NodeConfig.NODES[enabled_steps[-1]]["name"], "完成")
# 绘制图形
plt.clf()
plt.figure(figsize=(14, 6))
nx.draw_networkx_nodes(G, pos,
node_color=node_colors,
node_size=node_sizes,
alpha=0.9,
edgecolors='black',
linewidths=2)
nx.draw_networkx_edges(G, pos,
edge_color='#666666',
arrows=True,
arrowsize=25,
width=2,
alpha=0.7,
arrowstyle='->')
nx.draw_networkx_labels(G, pos,
font_size=9,
font_weight='bold')
plt.title("Qwen智能内容创作工作流执行状态", fontsize=14, fontweight='bold', pad=20)
plt.axis('off')
plt.tight_layout()
# 保存到临时文件
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as tmp_file:
plt.savefig(tmp_file.name, format='png', dpi=100, bbox_inches='tight',
facecolor='white', edgecolor='none')
plt.close()
return tmp_file.name
except Exception as e:
print(f"流程图生成错误: {e}")
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as tmp_file:
plt.figure(figsize=(10, 2))
plt.text(0.5, 0.5, "流程图生成中...", ha='center', va='center', fontsize=16)
plt.axis('off')
plt.savefig(tmp_file.name, bbox_inches='tight', facecolor='white')
plt.close()
return tmp_file.name
# 工作流管理器
class WorkflowManager:
def __init__(self):
self.workflow_builder = ContentWorkflowBuilder()
self.execution_history = []
def execute_workflow(self, topic: str, enabled_nodes: List[str]):
"""执行完整工作流"""
try:
print(f"开始执行工作流,主题: {topic}, 启用节点: {enabled_nodes}")
# 构建工作流
workflow = self.workflow_builder.build_workflow(enabled_nodes)
if not workflow:
return {"error": "没有启用任何节点", "current_step": "执行失败"}
initial_state = {"topic": topic, "current_step": "开始"}
result = workflow.invoke(initial_state)
# 记录执行历史
self.execution_history.append({
"topic": topic,
"enabled_nodes": enabled_nodes,
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
"result": result
})
print("工作流执行完成")
return result
except Exception as e:
print(f"工作流执行错误: {e}")
return {"error": str(e), "current_step": "执行失败"}
def get_execution_history(self):
"""获取执行历史"""
return self.execution_history
# Gradio 界面
def create_workflow_interface():
"""创建工作流界面"""
workflow_manager = WorkflowManager()
# 示例数据
EXAMPLES = [
["人工智能在医疗诊断中的应用"],
["区块链技术的原理与未来发展"],
["机器学习模型的可解释性研究"],
["云计算与边缘计算的协同发展"],
["自然语言处理的技术演进与应用"]
]
# 预设工作流模板
WORKFLOW_TEMPLATES = {
"完整创作": ["topic_analysis", "outline_generation", "title_generation", "content_generation", "summary_generation", "tags_generation", "image_prompt_generation", "image_generation"],
"快速写作": ["topic_analysis", "outline_generation", "content_generation", "summary_generation"],
"内容分析": ["topic_analysis", "outline_generation", "summary_generation", "tags_generation"],
"创意生成": ["topic_analysis", "title_generation", "content_generation", "image_prompt_generation"],
"仅内容": ["content_generation"],
"仅分析": ["topic_analysis", "outline_generation", "summary_generation"]
}
def load_template(template_name):
"""加载工作流模板"""
if template_name in WORKFLOW_TEMPLATES:
enabled_nodes = WORKFLOW_TEMPLATES[template_name]
# 更新复选框状态
checkbox_states = []
for node_id in NodeConfig.NODES.keys():
checkbox_states.append(node_id in enabled_nodes)
return checkbox_states
return [True] * len(NodeConfig.NODES)
def execute_content_workflow(topic, *node_checkboxes, progress=gr.Progress()):
"""执行内容创作工作流"""
if not topic.strip():
yield "❌ 请输入主题内容", None, None
return
# 获取启用的节点
node_ids = list(NodeConfig.NODES.keys())
enabled_nodes = [node_ids[i] for i, checked in enumerate(node_checkboxes) if checked]
if not enabled_nodes:
yield "❌ 请至少选择一个处理节点", None, None
return
try:
# 逐步执行工作流
for i, step in enumerate(enabled_nodes):
progress((i, len(enabled_nodes)), desc=f"执行 {NodeConfig.NODES[step]['name']}...")
# 更新流程图
diagram_path = WorkflowVisualizer.generate_workflow_diagram(
enabled_nodes, step
)
# 显示执行状态
status_text = f"{NodeConfig.NODES[step]['icon']} 正在{NodeConfig.NODES[step]['name']}..."
yield status_text, diagram_path, None
# 添加延迟以显示进度
time.sleep(1.5)
# 执行实际工作流
progress((len(enabled_nodes), len(enabled_nodes)), desc="完成最终处理...")
final_result = workflow_manager.execute_workflow(topic, enabled_nodes)
# 生成最终流程图
final_diagram = WorkflowVisualizer.generate_workflow_diagram(enabled_nodes, "完成")
# 格式化输出结果
output_content = format_output(final_result, enabled_nodes)
yield "✅ 内容创作完成!Qwen工作流执行成功", final_diagram, output_content
except Exception as e:
error_msg = f"❌ 执行错误: {str(e)}"
yield error_msg, None, None
def format_output(result, enabled_nodes):
"""格式化输出结果"""
if "error" in result:
return f"## ❌ 执行出错\n\n错误信息: {result['error']}"
output = "## 🎉 Qwen智能内容创作完成!\n\n"
# 根据启用的节点显示相应内容
if "title_generation" in enabled_nodes and "title" in result:
output += f"### 📝 生成标题\n**{result['title']}**\n\n"
if "outline_generation" in enabled_nodes and "outline" in result:
output += "### 📋 内容大纲\n"
for i, item in enumerate(result['outline'][:10], 1):
output += f"{i}. {item}\n"
output += "\n"
if "content_generation" in enabled_nodes and "content" in result:
output += f"### 📖 文章内容\n{result['content']}\n\n"
if "summary_generation" in enabled_nodes and "summary" in result:
output += f"### ✂️ 内容摘要\n{result['summary']}\n\n"
if "tags_generation" in enabled_nodes and "tags" in result:
output += "### 🏷️ 内容标签\n"
output += " ".join([f"`{tag}`" for tag in result['tags']])
output += "\n\n"
if "topic_analysis" in enabled_nodes and "analysis" in result:
output += "### 🔍 主题分析\n"
analysis = result['analysis']
for key, value in analysis.items():
output += f"- **{key}**: {value}\n"
output += "\n"
if "image_prompt_generation" in enabled_nodes and "image_prompt" in result:
output += f"### 🎨 图像提示词\n{result['image_prompt']}\n\n"
if "image_generation" in enabled_nodes and "generated_image" in result:
output += "### 🖼️ 生成配图\n"
output += f"\n\n"
# 显示使用的节点
used_nodes = [NodeConfig.NODES[node_id]["icon"] + " " + NodeConfig.NODES[node_id]["name"]
for node_id in enabled_nodes]
output += f"### 🔄 使用的工作流\n{' → '.join(used_nodes)}\n\n"
output += "---\n*本内容由Qwen大模型通过LangGraph工作流生成*"
return output
def show_execution_history():
"""显示执行历史"""
history = workflow_manager.get_execution_history()
if not history:
return "📊 暂无执行历史"
history_text = "## 📊 Qwen工作流执行历史\n\n"
for i, record in enumerate(history[-5:], 1):
history_text += f"### 记录 {i}\n"
history_text += f"**主题**: {record['topic']}\n\n"
history_text += f"**时间**: {record['timestamp']}\n\n"
history_text += f"**使用节点**: {len(record['enabled_nodes'])}个\n\n"
if 'result' in record and 'title' in record['result']:
history_text += f"**生成标题**: {record['result']['title']}\n\n"
history_text += "---\n\n"
return history_text
# 创建界面
with gr.Blocks(theme=gr.themes.Soft(), title="Qwen智能内容创作") as interface:
gr.Markdown("# 🚀 LangGraph + Qwen API + Gradio 智能内容创作系统")
gr.Markdown("使用通义千问大模型和智能工作流,自动生成高质量内容")
with gr.Tab("🎯 内容创作"):
with gr.Row():
with gr.Column(scale=1):
gr.Markdown("### ⚙️ 创作配置")
topic_input = gr.Textbox(
label="创作主题",
placeholder="请输入您想要创作的内容主题...",
lines=2,
max_lines=3
)
gr.Markdown("#### 📚 示例主题")
gr.Examples(
examples=EXAMPLES,
inputs=topic_input
)
gr.Markdown("#### 🎛️ 工作流模板")
template_selector = gr.Dropdown(
choices=list(WORKFLOW_TEMPLATES.keys()),
label="选择预设工作流模板",
value="完整创作",
interactive=True
)
gr.Markdown("#### 🔧 自定义工作流节点")
# 动态创建节点选择复选框
node_checkboxes = []
for node_id, node_info in NodeConfig.NODES.items():
checkbox = gr.Checkbox(
label=f"{node_info['icon']} {node_info['name']}",
value=node_info["enabled"],
info=node_info["description"]
)
node_checkboxes.append(checkbox)
execute_btn = gr.Button("🚀 开始智能创作", variant="primary", size="lg")
with gr.Column(scale=2):
gr.Markdown("### 📊 创作状态")
status_display = gr.Markdown("等待开始创作...")
gr.Markdown("### 🔄 Qwen工作流执行图")
diagram_display = gr.Image(
label="工作流状态",
value=WorkflowVisualizer.generate_workflow_diagram([]),
height=300
)
gr.Markdown("### 📄 创作结果")
output_display = gr.Markdown()
with gr.Tab("📈 创作历史"):
history_display = gr.Markdown()
with gr.Row():
refresh_btn = gr.Button("🔄 刷新历史")
clear_btn = gr.Button("🗑️ 清空历史", variant="stop")
with gr.Tab("🔧 系统说明"):
gr.Markdown("""
## 🎯 系统介绍
### ✨ 核心功能
- **智能主题分析** - 使用Qwen深度理解创作主题
- **自动大纲生成** - 构建逻辑清晰的内容结构
- **高质量内容创作** - Qwen生成专业流畅的文章
- **智能摘要提取** - 自动生成内容精华摘要
- **标签自动生成** - 提取内容关键标签
- **配图提示词生成** - 为AI图像生成创作提示词
### 🎛️ 工作流模板
- **完整创作**: 包含所有8个节点的完整流程
- **快速写作**: 核心写作流程,适合快速产出
- **内容分析**: 专注于内容分析和总结
- **创意生成**: 强调创意和视觉内容
- **仅内容**: 只生成文章内容
- **仅分析**: 只进行主题分析
### 🔧 自定义配置
您可以根据需求自由选择启用的处理节点,创建个性化的工作流。
### ⚠️ 注意事项
- 请确保已配置正确的Qwen API Key
- 建议主题明确具体,便于生成高质量内容
- 可根据需要调整工作流节点组合
""")
# 事件绑定
template_selector.change(
fn=load_template,
inputs=[template_selector],
outputs=node_checkboxes
)
execute_btn.click(
fn=execute_content_workflow,
inputs=[topic_input] + node_checkboxes,
outputs=[status_display, diagram_display, output_display]
)
refresh_btn.click(
fn=show_execution_history,
outputs=history_display
)
clear_btn.click(
fn=lambda: "🗑️ 历史记录已清空",
outputs=history_display
)
# 初始化
interface.load(
fn=show_execution_history,
outputs=history_display
)
return interface
# 启动应用
if __name__ == "__main__":
print("🚀 启动 LangGraph + Qwen API + Gradio 智能内容创作系统...")
print("📝 请确保已正确配置 dashscope.api_key")
# 检查API Key
if dashscope.api_key == "your-api-key-here":
print("❌ 请先配置您的 Qwen API Key")
print("💡 在代码中修改: dashscope.api_key = '您的实际API Key'")
else:
print("✅ API Key 已配置")
interface = create_workflow_interface()
interface.launch(
server_name="0.0.0.0",
server_port=7860,
share=True
)更多推荐
 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)