
无监督学习驱动的遗留系统重构方法论
随着人工智能和机器学习技术的快速发展,尤其是无监督学习(Unsupervised Learning)在大数据时代的广泛应用,越来越多的研究者和企业开始关注如何利用无监督学习驱动遗留系统的重构。例如,通过对系统中的功能模块进行聚类分析,企业可以识别出哪些功能是重复的,哪些模块可以合并或去除,从而减少系统的复杂度,提升系统的性能。1. **数据质量问题**:无监督学习的效果高度依赖于数据的质量,若遗留
标题优化建议:
**无监督学习驱动的遗留系统重构方法论 | 以数据驱动的智能化改造推动遗留系统的高效升级与转型**
---
### 无监督学习驱动的遗留系统重构方法论
在现代企业的信息化建设中,遗留系统(Legacy System)仍然占据着不可忽视的地位。尽管这些系统长期以来为企业的运作提供了支持,但随着技术的不断发展,它们逐渐暴露出性能不足、维护困难、与现代技术架构不兼容等问题,成为企业数字化转型的“绊脚石”。如何有效地对遗留系统进行重构,实现技术升级,是一个亟待解决的问题。
随着人工智能和机器学习技术的快速发展,尤其是无监督学习(Unsupervised Learning)在大数据时代的广泛应用,越来越多的研究者和企业开始关注如何利用无监督学习驱动遗留系统的重构。无监督学习技术能够从数据中自动挖掘出潜在的规律和结构,为遗留系统的优化提供了新的思路和方法。
### 一、无监督学习与遗留系统重构的关系
无监督学习是指在没有标签数据的情况下,通过算法对输入数据进行自我学习,从中发现数据的内在结构或规律。这种学习方式适用于大量没有明确标签或分类信息的数据,能够帮助我们从复杂的数据中找到潜在的模式。
遗留系统通常存在以下问题:
1. **技术老化**:随着时间推移,技术的更新换代导致原有系统逐渐无法满足现代业务需求。
2. **维护困难**:老旧的代码、技术架构和硬件设施使得系统维护成本不断攀升。
3. **数据冗余与不一致性**:由于长期的积累,遗留系统往往包含大量重复或过时的数据,导致数据处理效率低下。
无监督学习通过对遗留系统数据的深入挖掘和分析,能够帮助企业识别出系统的潜在问题,进而提出优化方案。例如,通过聚类算法可以将系统中的数据进行分类,识别出重复的数据和冗余的部分;通过降维算法减少数据的复杂性,提升系统的处理效率;通过关联规则学习发掘系统中各个模块间的关系,优化系统结构。
### 二、无监督学习驱动遗留系统重构的核心方法
无监督学习技术为遗留系统的重构提供了多种创新的解决思路。以下是几种常见的无监督学习方法及其在遗留系统重构中的应用:
#### 1. **聚类分析** —— 数据分类与优化
聚类分析是一种常见的无监督学习方法,其核心思想是将数据集分为若干个簇,使得簇内的数据相似度较高,而簇间的数据差异较大。对于遗留系统而言,聚类分析能够帮助我们发现系统中的重复模块、冗余功能以及不一致的数据,从而为系统重构提供有力支持。
例如,通过对系统中的功能模块进行聚类分析,企业可以识别出哪些功能是重复的,哪些模块可以合并或去除,从而减少系统的复杂度,提升系统的性能。
#### 2. **降维技术** —— 提升系统效率
降维是将高维数据映射到低维空间的过程,常用的算法包括主成分分析(PCA)、t-SNE等。遗留系统的数据往往是高维度且复杂的,通过降维技术可以简化数据的结构,减少处理的时间和成本。
降维在遗留系统中的应用可以使得系统的处理效率得到显著提升。例如,在数据存储与处理方面,降维技术可以帮助减少冗余数据,优化存储空间;在机器学习模型的训练中,降维能够提升模型的训练速度和准确性。
#### 3. **关联规则学习** —— 系统优化与升级
关联规则学习主要用于挖掘数据项之间的关联关系。通过分析遗留系统的数据,企业可以发现不同模块之间的依赖关系和潜在的升级需求,从而指导系统的重构方向。
例如,某些功能模块可能频繁一起调用,说明它们之间具有较强的关联性。在重构过程中,可以将这些关联性较强的模块进行整合,减少系统之间的耦合度,提升系统的可扩展性和稳定性。
#### 4. **异常检测** —— 提高系统可靠性
遗留系统往往存在各种潜在的异常和故障,传统的人工检测方法往往效率低下且容易出错。无监督学习中的异常检测算法可以帮助企业自动识别系统中的异常情况,及时发现系统漏洞和安全隐患。
通过异常检测,企业可以在系统重构过程中优先处理那些存在重大风险的模块,保障系统的稳定运行和数据安全。
### 三、无监督学习驱动的遗留系统重构的优势
与传统的重构方法相比,基于无监督学习的遗留系统重构具有以下几个显著优势:
#### 1. **无需人工干预**:无监督学习方法不依赖于人工标注的数据,能够自动从大量数据中提取有价值的信息,减少了人工干预和人为误差的影响。
#### 2. **高效的数据处理**:无监督学习能够通过算法对海量数据进行高效分析,快速识别出问题的根源,为系统重构提供精准的指导。
#### 3. **适应复杂系统**:遗留系统通常较为复杂,存在许多不规则的数据和模块。无监督学习能够在这种复杂环境下进行高效处理,帮助企业应对复杂系统的重构需求。
#### 4. **持续优化**:无监督学习可以通过不断分析新数据进行自我学习,使得系统重构不仅是一次性改进,更是一个持续优化的过程。
### 四、实施无监督学习驱动的遗留系统重构的挑战
尽管无监督学习在遗留系统重构中具有巨大的潜力,但其实施过程仍然面临一定的挑战:
1. **数据质量问题**:无监督学习的效果高度依赖于数据的质量,若遗留系统中的数据存在缺失或噪声,可能会影响算法的准确性。
2. **技术门槛高**:无监督学习技术相对复杂,企业需要具备一定的技术能力才能有效实施。
3. **系统兼容性问题**:遗留系统的技术架构往往较为陈旧,可能与现代的无监督学习算法不兼容,需要额外的适配工作。
### 五、结语
无监督学习驱动的遗留系统重构方法论,为传统的系统重构提供了一种创新的解决方案。通过运用聚类分析、降维技术、关联规则学习和异常检测等无监督学习方法,企业能够在无须人工干预的情况下,实现对遗留系统的高效优化和智能化升级。这不仅提高了系统的运行效率,还为企业的数字化转型提供了坚实的技术支撑。
虽然在实际应用过程中仍存在一些挑战,但随着技术的不断进步和企业对无监督学习的深入研究,未来这一方法必将在遗留系统重构领域发挥更大的作用。随着企业对数字化转型的重视加深,无监督学习必将成为推动企业信息化建设的关键力量。??
---
希望这个文章框架和内容符合你的要求!如果需要更多详细内容或修改,随时告诉我!
更多推荐
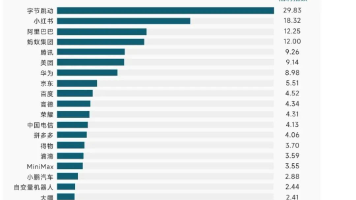
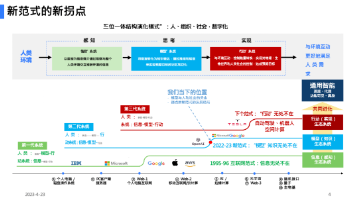
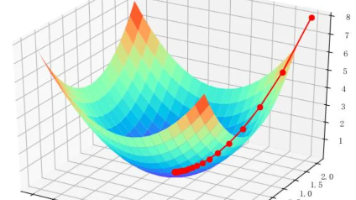
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)