
基于 Megatron 的多模态大模型训练加速技术解析
本文以 Qwen2-VL 为例,从易用性和训练性能优化两个方面介绍基于 Megatron 构建的 Pai-Megatron-Patch 多模态大模型训练的关键技术。在易用性方面,最新的 Pai-Megatron-Patch 实现了基于 Mcore 的多模态编码器和 LLM 解码器,同时实现了支持高精度低损耗的 Huggingface 和 MCore 多模态模型权重互转转换以及并行加载,极大简化了不
本文以 Qwen2-VL 为例,从易用性和训练性能优化两个方面介绍基于 Megatron 构建的 Pai-Megatron-Patch 多模态大模型训练的关键技术。在易用性方面,最新的 Pai-Megatron-Patch 实现了基于 Mcore 的多模态编码器和 LLM 解码器,同时实现了支持高精度低损耗的 Huggingface 和 MCore 多模态模型权重互转转换以及并行加载,极大简化了不同框架间迁移的学习成本和技术障碍。在性能方面,实现了支持高性能的文本 / 图像 / 视频数据统一加载,实现了高性能的流水并行切分,另外通过引入 CPU 卸载技术以及 Sequence Packing 技术,进一步支持多模态长序列训练的显存优化,有效缓解了 GPU 的显存压力,提升了大模型训练的效率与稳定性。这些改进共同作用,为用户提供更加流畅且高效的多模态大模型开发体验。
支持模型并行的权重转换
作为开源主流高效大模型训练工具,用户在尝试使用 Megatron 训练开源模型时首先遇到的障碍是 Huggingface 与 Megatron 模型权重格式的差异。下面将以 Qwen2-VL 为例,详解从 Huggingface 到 Megatron 的模型权重转换技术。如下图所示,Qwen2-VL [2] 主要由多模态编码器和 LLM 解码器两个模块组成。Qwen2-VL 采用了专门设计的多模态编码器架构,可以同时接受文本 / 图像 / 视频作为输入,并将它们转换成统一形式的表示向量后送入 LLM 解码器。这种设计使得模型能够在同一个空间内有效地捕捉到跨模态的信息关联。与 LLaVA 等多模态模型不同,Qwen2-VL 的视觉输入不需要缩放到固定分辨率大小,而是根据图像 / 视频数据的原始分辨率,动态生成不同长度的视觉表示向量,这一特性被称为动态分辨率。
通过将 Huggingface 模型转换到 Megatron 格式,用户可在已经充分训练好的 Qwen2-VL 基础大模型或者微调大模型上进行二次训练。所谓支持模型并行的权重转换,其核心原理是在转换时将大型模型权重分割成多个部分,并分配给不同的 GPU 进行并行加载。通过这种方式可以显著减少单个设备上的显存占用量,加快训练速度。然而,在实际应用中这一技术面临着若干挑战。在开发过程中,我们遇到的最常见问题之一是在完成权重转换后重新加载进行训练时,step 0 loss 比预期高。造成这种情况的原因主要有两个方面:一方面是模型实现风格不一致,结构映射关系十分复杂;另一方面是模型权重并行切分算法实现容易出错。因此,针对上述两种原因,Pai-Megatron-Patch 分别进行了优化。
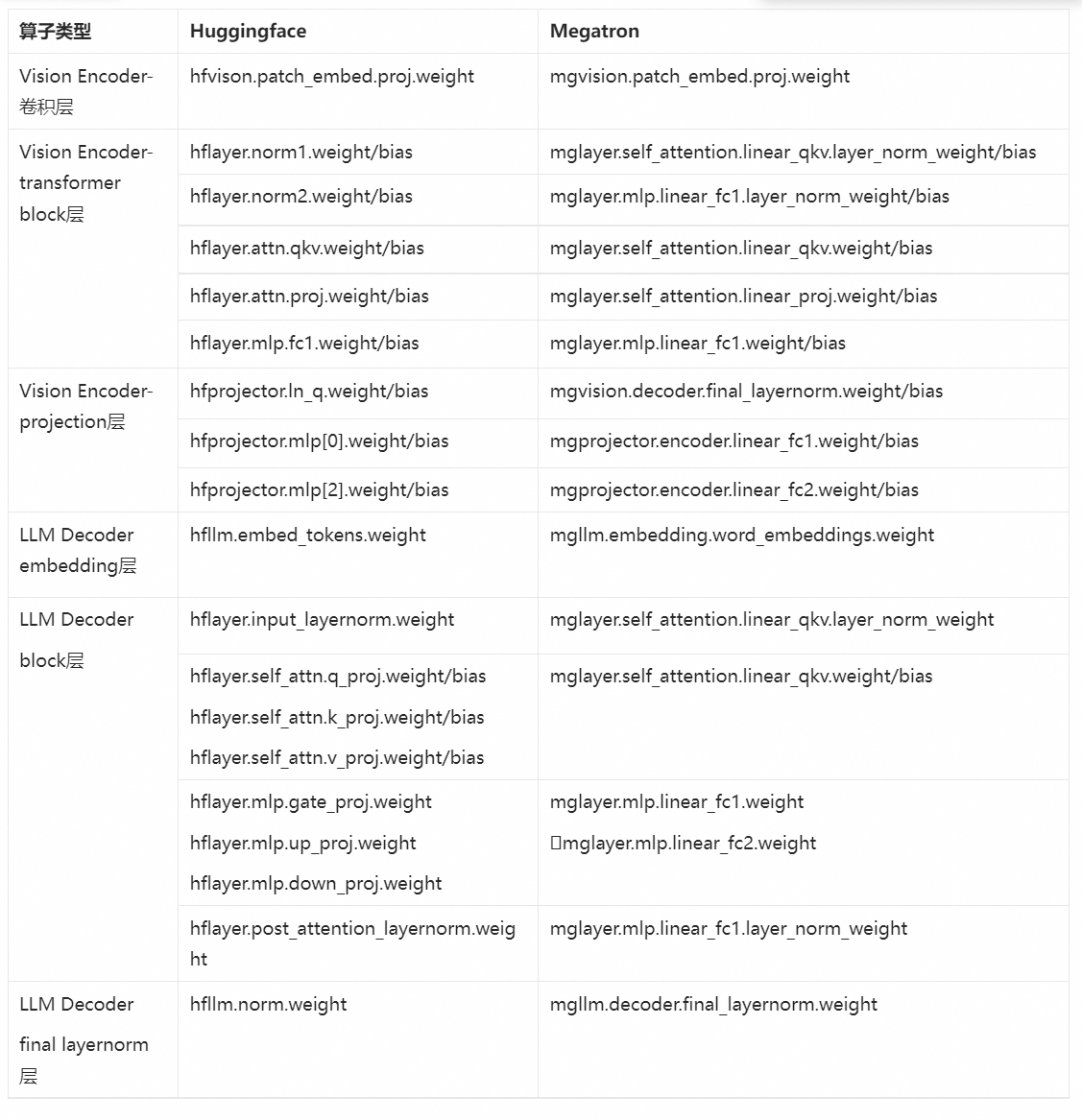
在 Pai-Megatron-Patch 的模型转换中,针对模型结构映射关系十分复杂的问题,建模分析并构建映射表能有效对比 Huggingface 模型与 Megatron 实现的联系。下表总结了两者分别在各个算子类型上的命名对应关系。在支持模型并行的权重转换实现过程中,我们首先将 Huggingface 模型的 ckpt 赋值给 Megatron 模型,然后再在 Megatron 模型上进行 TP/PP 切分。这种先转换再切分的好处是可以提升代码的可维护性,减少转换出错的概率。
除了模块层面的实现差异,在算子层,由于 3D 并行的存在,Megatron 与 Huggingface 的权重及计算方式也存在很大区别,需要根据实际情况进行转换。针对模型权重并行切分算法实现容易出错的问题,逐算子精细化切分保证了自底向上的准确转换。
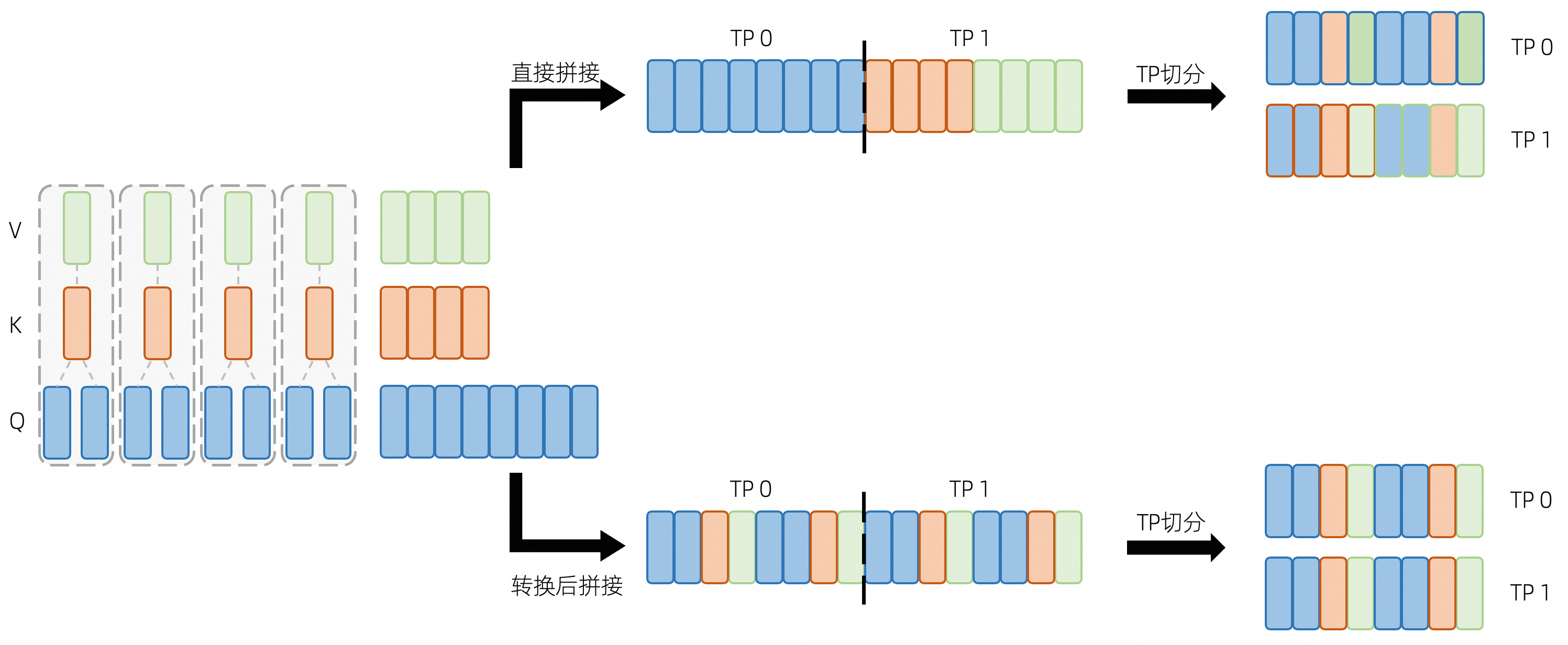
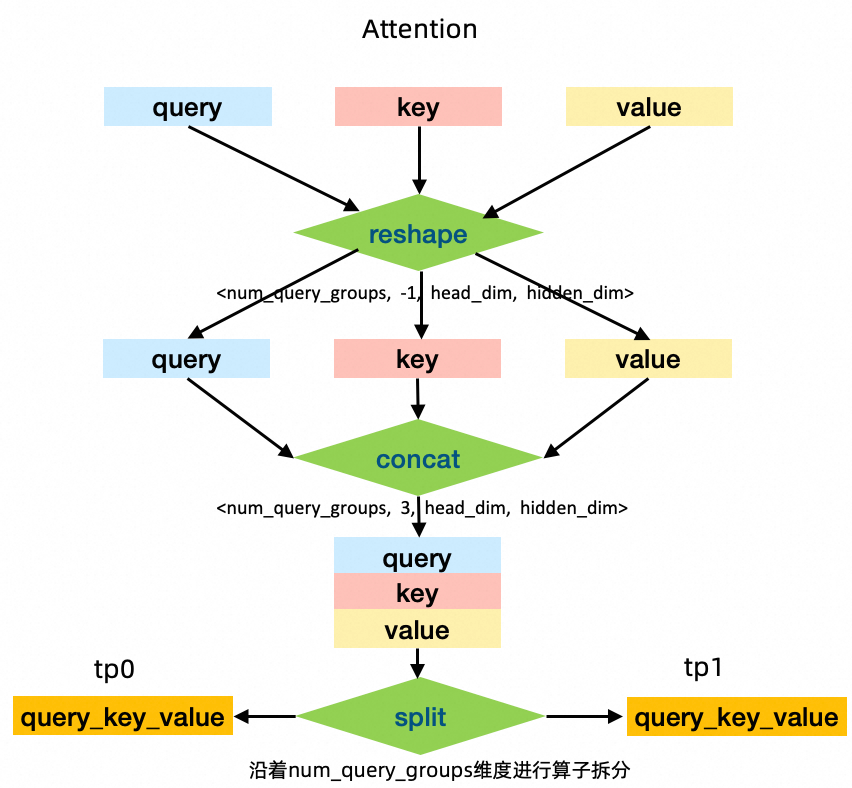
上图表示了一个 Huggingface 实现的 GQA 权重转换到 Megatron 的正确 / 错误流程,其中每个块表示一个 head 的权重,边框和内部的颜色分别代表这个 head 对应的类型及被理解成的类型。在 transformers 库中,Huggingface 采用 q_proj, k_proj, v_proj 这三个算子来计算 QKV status, 随后再调用 repeat_kv() 函数将同一个 Query Group 内的 KV status 数量与 Query 对齐,进而调用 attention 函数。在 Megatron 中,由于张量并行的存在,Attention Module 采用了 ColumnLinear (linear_qkv) 对 QKV 统一计算,为了降低节点间通信量,这个并行 Linear 将 Query Group 均匀切分到各个 Node 上,使每个节点内就能计算一部分 attention 结果,不需要对 QKV status 进行同步。在这个 case 下,如果直接拼接 QKV 的权重张量(如图上半部分)再进行 TP 切分,可以明显看到大部分 head 位置出现问题,因此,我们需要将 QKV 权重进行一定转换,按 Query Group 的顺序进行拼接(如图下半部分)后再切分才能保证 Attention 的正确性。具体地说,在进行 TP=2 切分时,Pai-Megatron-Patch 先将 query,key 和 value 这三个 tensor 分别 reshape 成一个 4D 的 tensor,reshape 后的 shape 是 < num_query_groups, -1, head_dim, hidden_dim>。接着沿着第二个维度拼接在一起,然后沿着 num_query_groups 维度进行算子拆分。才能确保并行加载 ckpt 后的起步 loss 值误差偏移在合理范围内。
用户友好的多模态数据加载
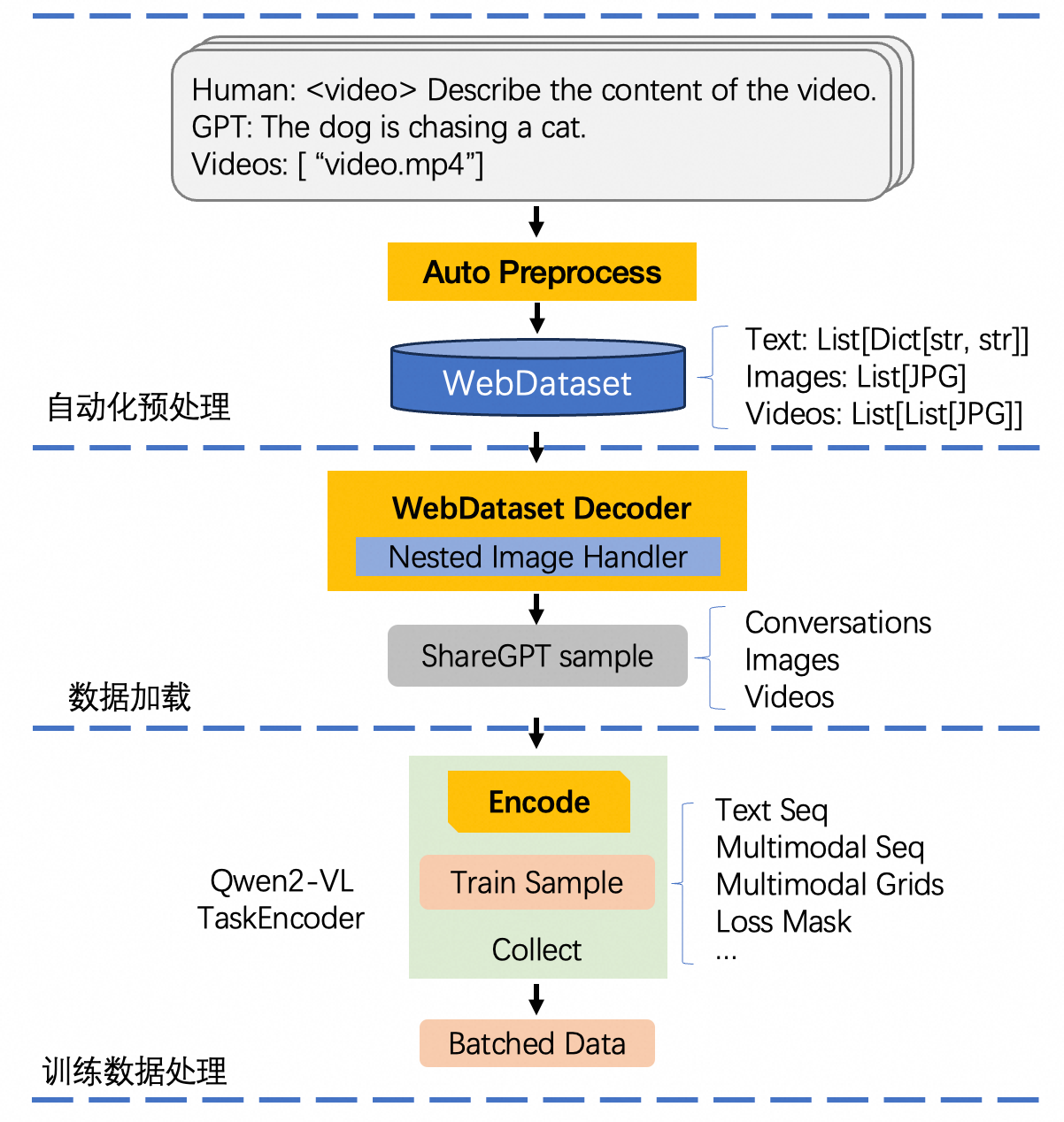
相对于 LLM 预训练,在数据加载方面,由于引入了多个类型的数据,多模态模型的 DataLoader 尤其复杂。为了支持 LLaVA 等模型,英伟达的 Megatron 进一步推出了 Energon 来实现多模态数据的加载逻辑。尽管如此,由于目前多模态输入并无统一的格式,在目前的 Megatron 中,对于多模态数据的支持仍比较有限,具体表现在 (1) 仅支持部分格式简单的数据加载,例如每个样本至多包含一张图像或一个视频,应用场景有限;(2) 现有 TaskEncoder 输出格式固定,灵活性不大,难以高效支持模型训练。在实际开发中,Qwen2-VL 同时遇到了上述两类障碍:与已有的 LLaVA 相比,Qwen2-VL 基于 ChatML 格式设计输入,应当支持单个样本中多张图片视频、多轮对话等复杂功能,但这类数据无法使用当前 energon 的代码进行读取;此外,现有 TaskEncoder 仅支持将图片缩放到固定大小,再传入模型训练,因此难以支持 Qwen2-VL 独有的动态分辨率特性。
为了解决上述功能性问题,我们首先对内置的 DataLoader 代码做了大量扩展,使其能基于输入的原始多模态数据构造用于动态分辨率训练的图像切片序列以及位置信息,同时支持可自定义 prompt、多轮、包含任意数量图像或视频的对话样本的数据处理。在此基础上,我们设计了一套自动化脚本,能基于用户给定的 sharegpt 格式数据集路径自动转换成 energon 可读取的 webdataset 数据集,绕过当前 energon 数据集准备的交互流程,加快数据转换效率,同时降低用户学习成本。此外,对于数量不定的图像,为了能在 energon 侧自动解码,webdataset 支持将其以 numpy array 的形式保存,然而,由于 jpg 到 ndarray 间的数据格式差异,在实际测试中,我们发现这将造成最终数据集文件体积出现几倍到几十倍的增加。为了解决这个问题,我们在运行时向 webdataset 的编解码模块增加钩子函数,使其支持图像文件列表的自动编解码,实现在按原始二进制数据保存的同时能被 energon 自动转换为图像张量的需求。通过上述优化,在 Pai-Megatron-Patch 中,经过转换的 sharegpt 格式数据相对于其原始总大小几乎没有变化。
视觉特征处理流程优化
与 LLM 相比,多模态模型先对视觉数据进行编码,再与文本特征拼接后送入 LLM 进行推理。与基于静态分辨率的多模态大模型不同,复杂的多模态数据格式以及动态分辨率共同使得 Qwen2-VL 的这一过程更加复杂,不仅显著影响训练效率,也与能否应用 TP Comm Overlap 等技术相关。
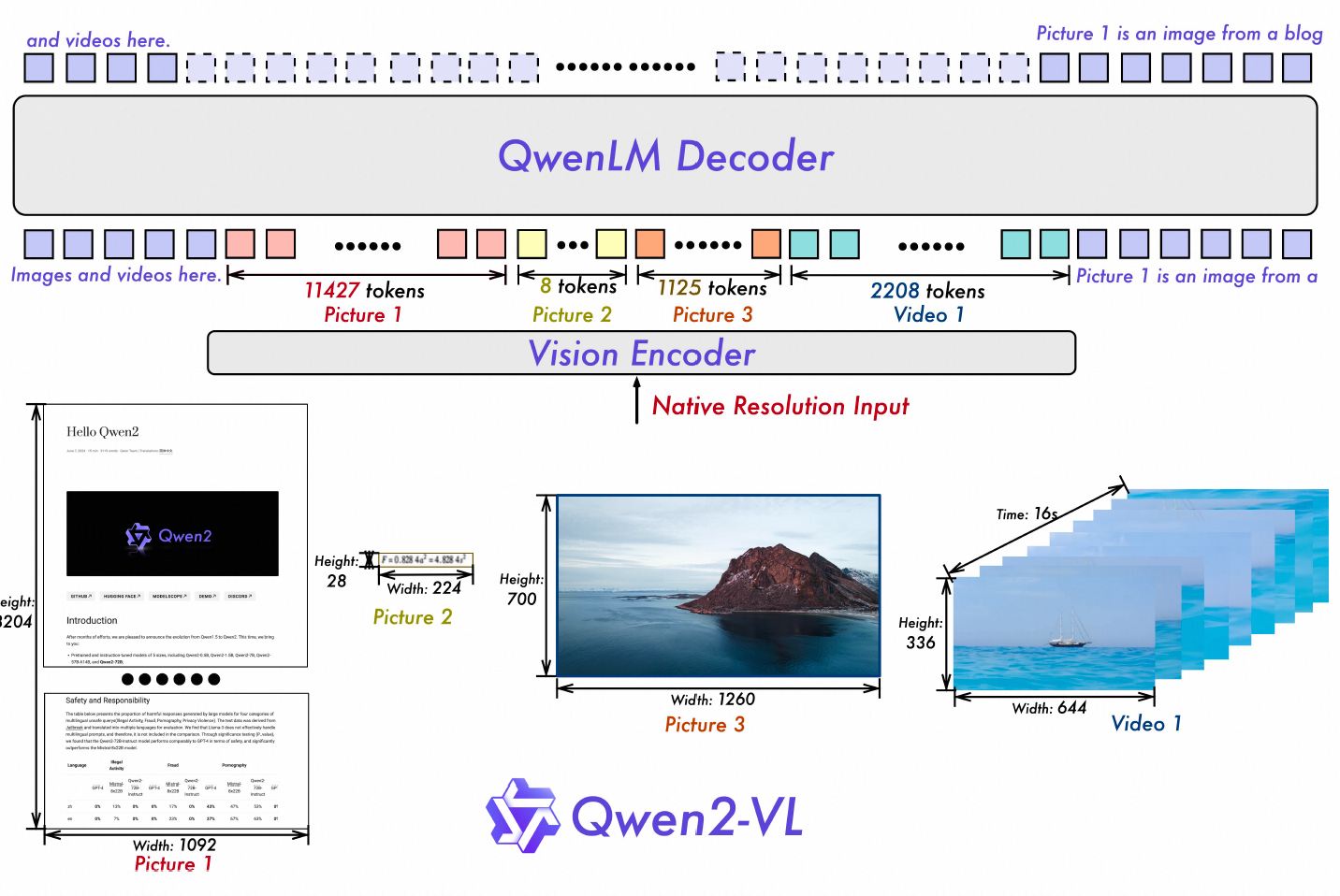
与静态分辨率使用固定数量视觉 token 不同,动态分辨率技术允许模型依据输入图像大小,将其编码成不定数量的视觉特征。这一改进使模型对于高分辨率图像的细节捕捉能力获得显著提升,同时也优化了低分辨率图像的推理性能。下图是 Qwen2-VL 的训练数据的简单示例,针对不同长度的视觉
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)