
硬核:分布式推理优化思路分享
摘要:本文探讨了大模型推理应用中的并行策略优化思路,针对不同场景和模型层特点提出针对性优化方案。文章分析了主流的并行策略(DP/TP/SP/EP/CP/PP/ZeRO)及其组合应用,特别讨论了MoE模型、Attention模块和FFN层的优化策略。在MoE模型方面,建议采用DP/TP/EP组合并行;Attention模块优化包括通信调整、DP间SP并行和显存优化;FFN层则推荐EP转AFD等策略。
InfraTech申明:本文作者 kaiyuan, 未经允许不得转载!
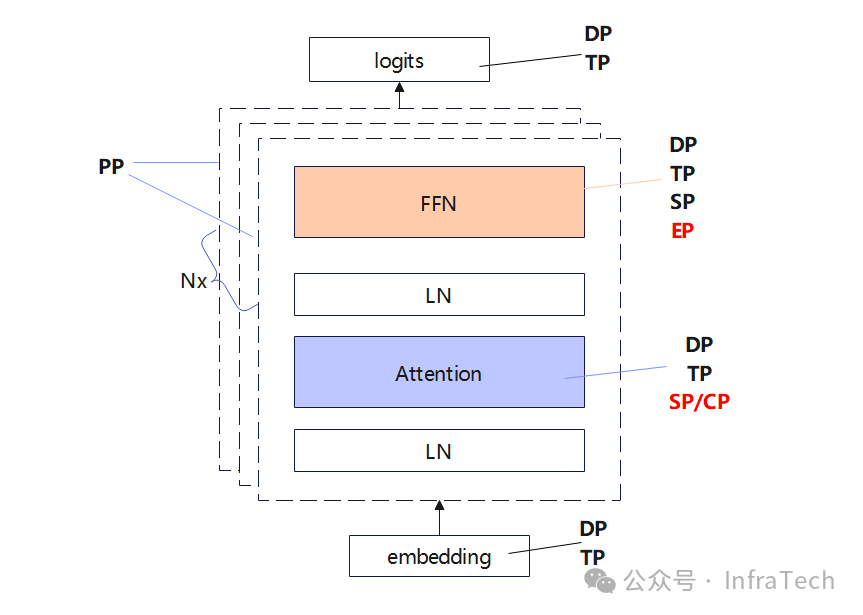
大模型推理应用中,不同的场景、模型层有着不同的计算特点,并行策略需要根据这些特点进行调整,不但要消除冗余存储、冗余计算,还要最大限度地降低通信开销对计算的影响,保证推理的SLA(如TTFT/TPOT)。本文主要讨论推理并行策略的优化思路,希望能给在做性能优化的读者一点启发。
相关基础知识参看:
https://zhuanlan.zhihu.com/p/1937449564509545940
主流的并行策略包括:DP/TP/SP/EP/CP/PP/ZeRO,当前的MoE模型中,比较常用的是DP/TP/SP和EP。这些策略一般会组合使用,e.g.:
-
在Attention层中采用TP、SP,也可以开始CP;
-
FFN层如果是dense结构用TP+SP,如果是sparse结构(MoE)常用EP;
-
DP是所有层都适用。
ZeRO策略(参数分片/shard)、PP层间的流水线并行相对而言当前的使用频率较低,在一些特定场景中可考虑开启。
训练与推理的原理相同,推理中有个场景需要单独讨论---PD分离:目前推理部署中,会把P(Prefill)和D(Decode)阶段进行分离部署以解决compute-bond、memory-bond场景问题,而且会配置xPxD(多P多D)。P和D的并行策略可以不一样,比如,P实例处理请求数一般较少,DP设置小;而decode需将并发打上去,DP数量设置大; P实例的MoE层可使用TP并行,D实例则一般使用EP并行。
1 MoE模型的并行策略
当前主流的模型采用的FFN是独立专家(MoE)+共享专家(Dense),这类MoE模型的并行策略一般使用DP/TP/EP,如下所示是一个DP=2/TP=2/EP=4的例子(假设word_size=4)。
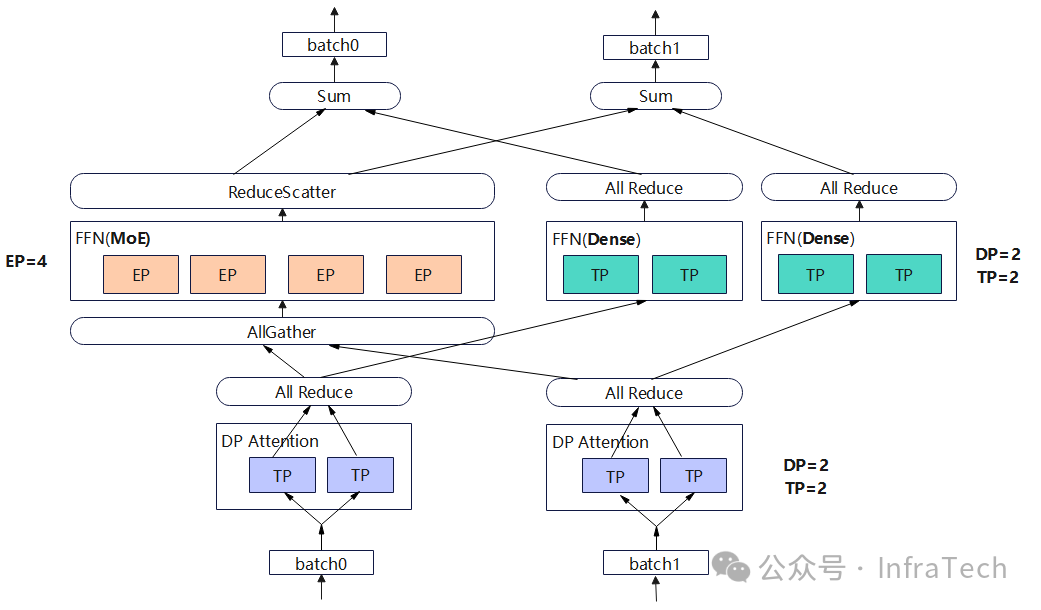
Attention层采用TP并行,每个DP需要一个allreduce操作。数据进行FFN层计算,在MoE采用了EP并行,会将数据跨DP域进行allgather然后再进行route分发,计算完成后进行reduce scatter操作。Dense层则采用TP并行,计算完成后需要allreduce操作。
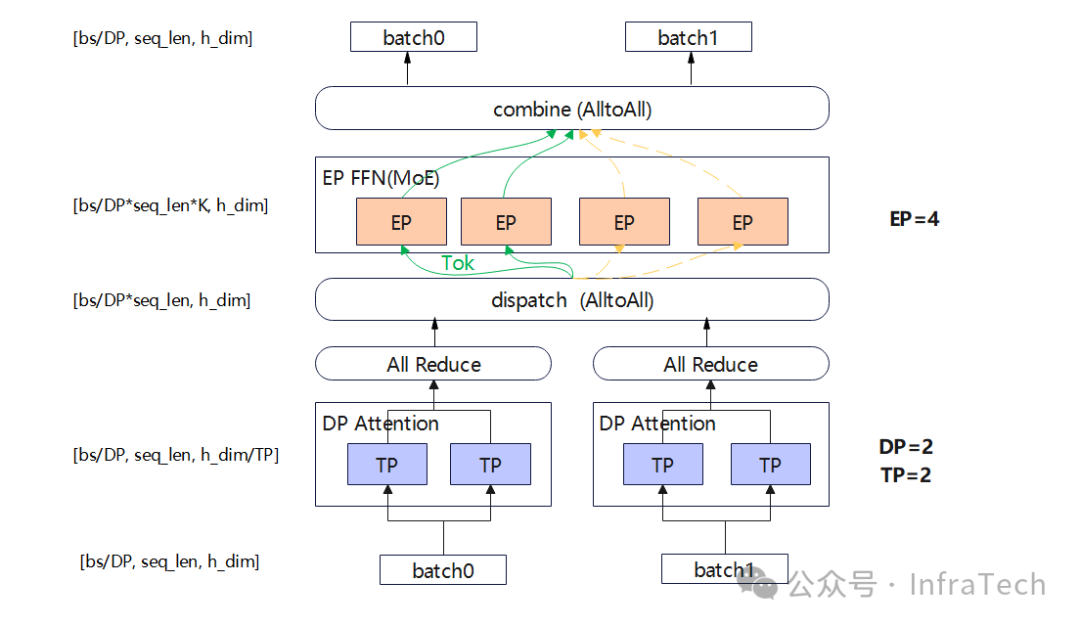
可以尝试对局部进行调整优化,比如decode中:把MoE的allgather换成alltoall,数据量大时能够提升整体效率。
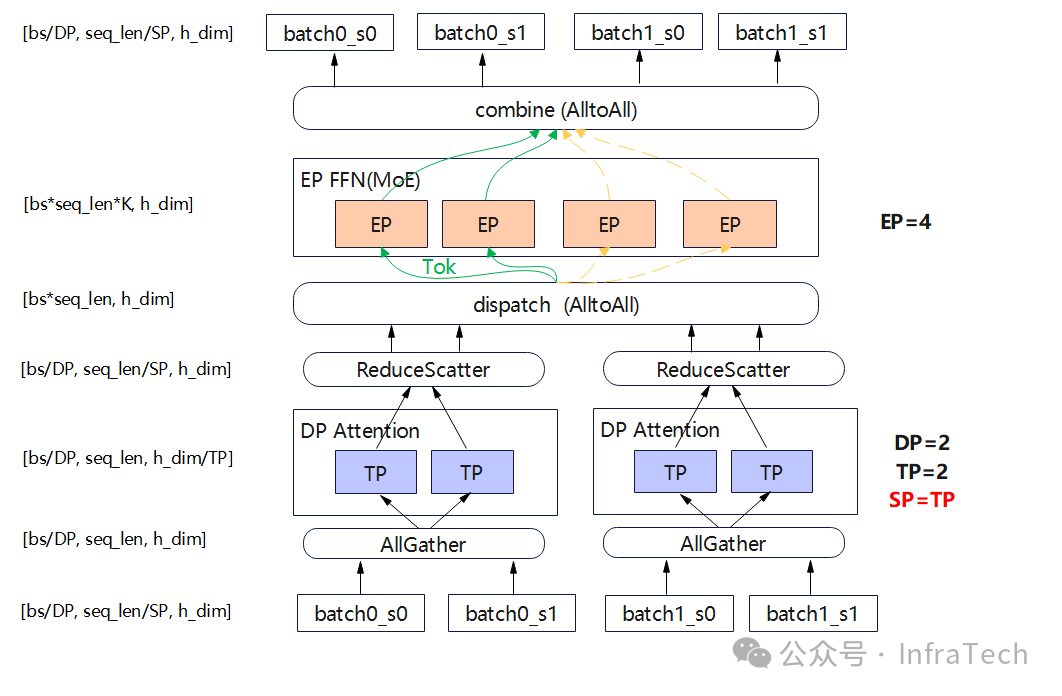
进一步优化调整:增加SP并行。Attention计算后的allreduce换成reduce scatter操作,这能够消除部分冗余计算。
2 Attention模块优化
2.1 通信的调整
Attention模块MHA目前有多种变体如GQA/MLA,以MLA为例,其运算流程如下所示。
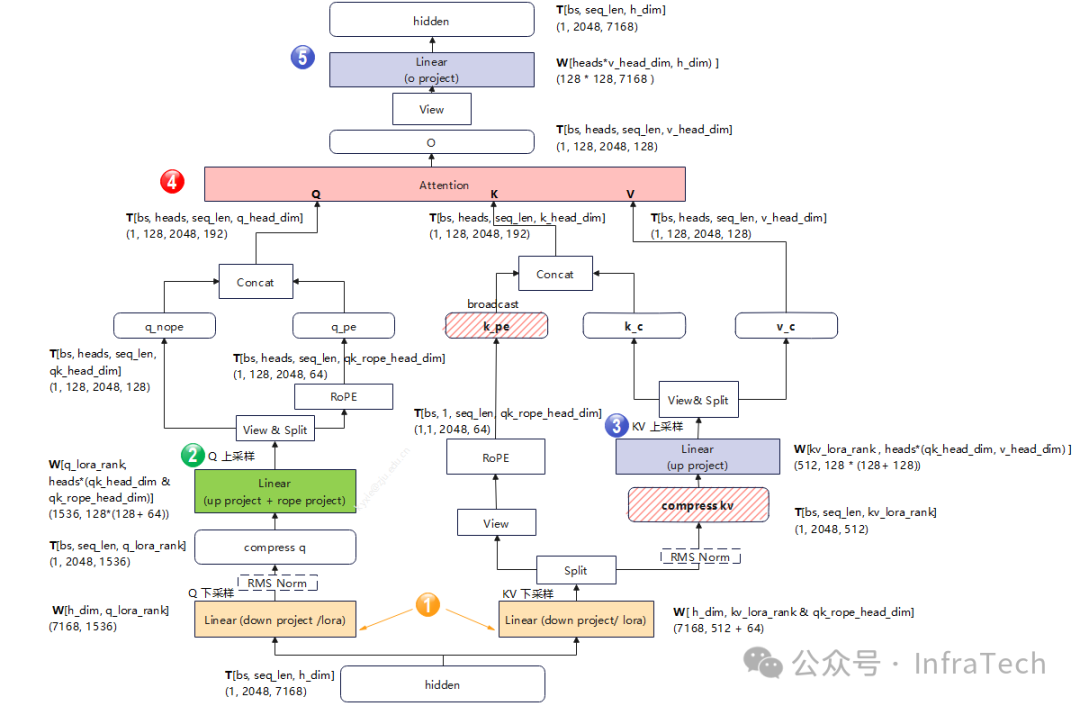
在进入attention模块前,若上一层MoE后有allgather运算或者allreduce计算(可以将allreduce其拆分成reduce scatter和allgather),将allgather操作移动到RMS Norm、下采样计算之后,运算结果不变,且可减少计算量。以deepseekV3为例(2K输入):
第一个RMSNorm的变化:
4 * bs * seq_len/SP * h_dim= 1 * 2048 * 7168 / SP
Q计算的量的变化:
-
Lora:2 * batch_size * seq_len * hidden_size1 * hidden_size2 = 2 * 1 * 2048 * 7168 * 1536 / SP
-
RMSNorm: 4 * bs * seq_len/SP * h_dim= 4 * 1 * 2048 * 1563/ SP
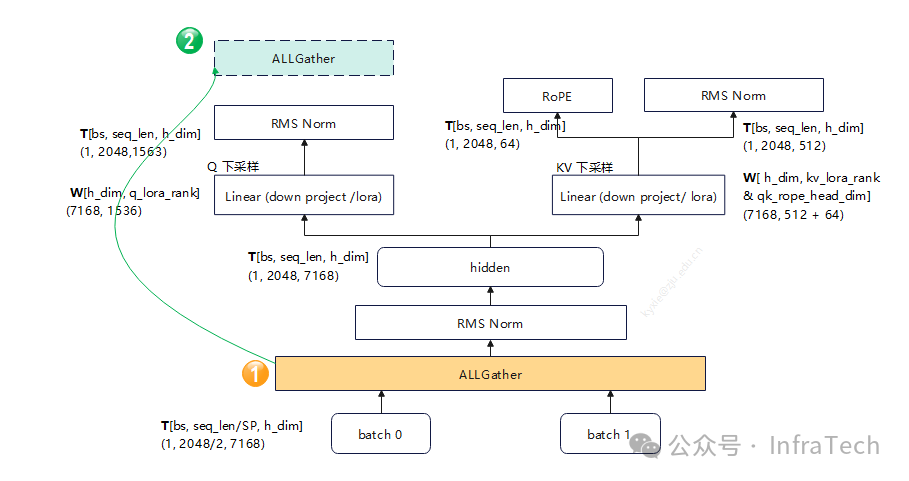
如果KV计算也做对应调整,也能带来性能提升。
2.2 DP之间的SP并行
MoE模型结构在prefill阶段,易遇到两类负载不均的问题:专家负载不均和DP负载不均。专家负载不均由专家热度不一致造成,目前可通过EPLB解决。Attention计算时长与序列长度正相关,变长度请求会导致DP实例之间的计算负载不均衡。
如下所示,假设MoE用的AllGather方案,则DP组之间会有一个阻塞等待,从而产生资源浪费。
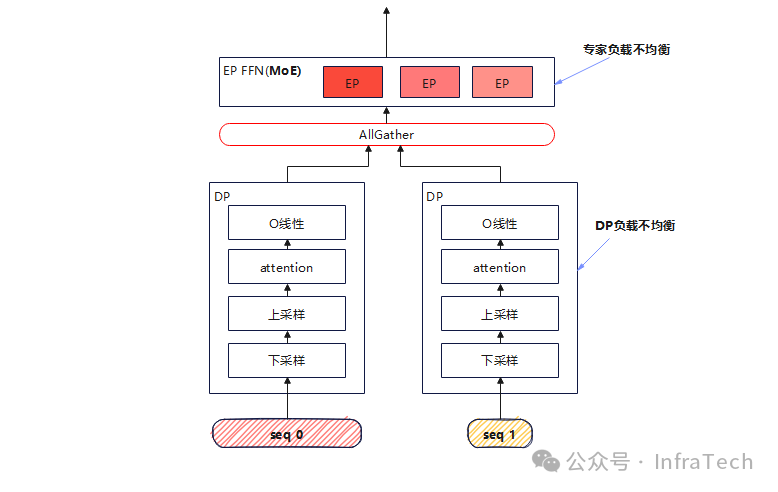
这里讨论一种优化方式:将DP之间的序列进行重新划分,保证每个DP计算序列长度基本一致。
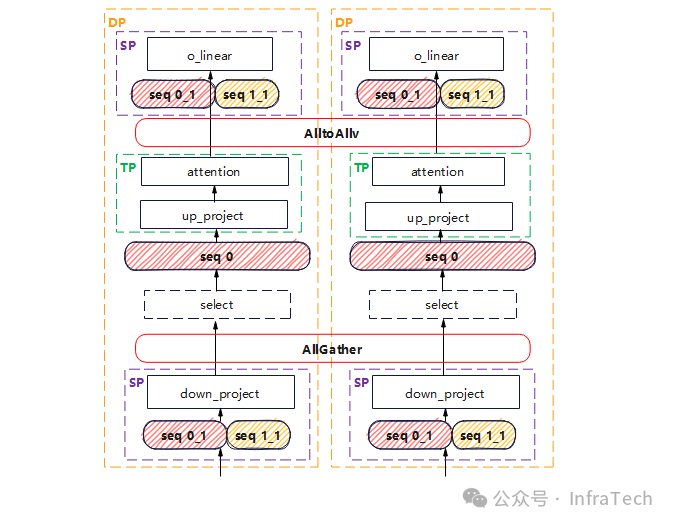
具体实施:在请求进入模型计算前先进行一次序列的allgather操作,将所有的请求序列进行均匀切分,让每个DP实例拿到的切分序列计算量相等,计算完成后将序列按照切分前的size还原回去,保证输出一致。如下图所示是两个长度不一致的请求,其序列组合后进行重新分配在处理的过程示意。
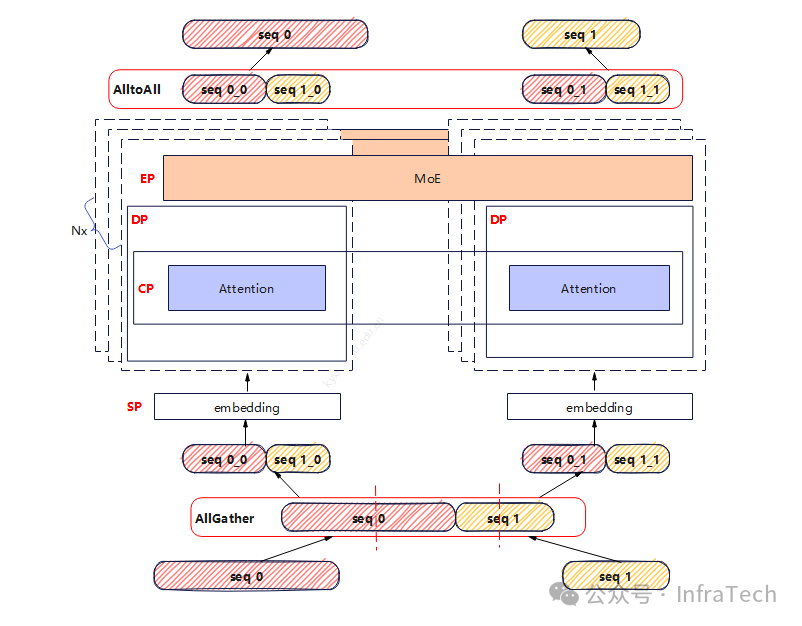
这种优化方式的MoE层采用大EP,Attention层采用CP方式,其它层均采用SP。
工程实践中还涉及两个关键的问题:
-
Attention-CP并行功能的实现方式;
-
如何分配KV空间,prefix cache兼容;
这两个问题可以暂时规避:在self-attention阶段,将SP还原为DP、TP并行,仅解决MLA前后的线性运算的负载不均衡问题。操作如下:
-
step1:down_project阶段:,采用混合序列的SP。
-
step2:进行allgather还原请求序列,并行选择与DP相关的序列进行下一步计算;
-
step3:up_project和attention计算,使用DP+TP并行。
-
step4:通过alltoall将序列继续按照之前切分好的方式还原,
-
step5:O线性运算,采用混合序列的SP。
2.3 O线性层的显存优化
Self-Attention 计算之后的O_project线性运算使用的Wo权重值较大(heads * v_head_dim * h_dim),计算公式:
mem= layer_num * heads * v_head_dim * h_dim * data_type_factor / (1024 * 1024 * 1024) GB
# 示例 deepseekV3 671B FP8格式:61 * 128 * 128 * 7168 * 1 / (1024 * 1024 * 1024) 约 6.67GB Qwen3 32B BF16格式:64 * 64 * 128 * 5120 * 2 / (1024 * 1024 * 1024) 5.0 GB
通过TP并行可降低这个显存占用量,如MLP中,QKV上采样采用列切、O就可以采用行切,显存值变为:mem/TP;在prefill阶段sequence大时(计算量较大),TP能够降低单卡的计算量:1/TP。
在decode阶段,为增加吞吐一般是采用大DP,小TP设置。O线性层的算力需求相对较小(因为sequence=1),此时Wo的优化可以考虑消除冗余的方式,如,Zero的分片存储(参看并行优化基础2.3节)。 假设Wo shard用DP域、并配合TP切分,则单卡的Wo需求变为:mem/TP/DP
2.4 CP并行
CP并行针对是self-attention,因要修正softmax的计算结果,每个KV分片都需与Q分片进行计算。在推理场景中要解决的关键问题(参考并行优化基础3.1节):
-
分片KV cache的管理问题?
-
与prefix cache如何配合?
对于问题1,因为在vLLM中的KV cache有一层逻辑管理(请求会关联KV cache逻辑地址、逻辑地址与物理地址还有层映射),所以适配CP需要调整。可以考虑逻辑与物理的映射table重新构建。如果序列分散在DP之间,还需考虑跨DP之间数据传递。
对于问题2,目前prefix cache的存储位置有GPU的显存、内存、磁盘、云存储形态,若要满足KV cache分片需求,prefix cache的save&load逻辑需要做相应调整。
一种可行的解决方案:构建跨GPU的KV值存储管理,即扩大page-attention的逻辑管理范围,比如CP采用Q-pass的方式,统一table(跨DP域),如下所示,这种方式模糊了DP数据并行的边界(认为DP=1)。
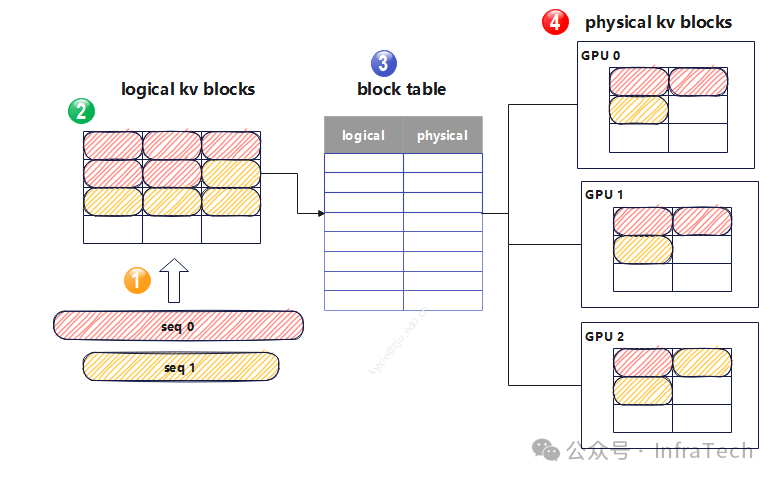
注意:CP并行时还需设计好CP并行的粒度与chunk粒度的对应关系。
3 FFN层并行优化
3.1 MoE策略
MoE层可采用TP并行,即将每个专家都进行切分。当TP不跨节点时,这种方式是能够解决计算均衡、显存不足的问题。当TP切分需要跨节点时,出现通信瓶颈,会导致计算效率下降。
另一种方式:独立专家按照卡分配,即EP并行。将expert计算分配到EP域的各个rank上,最后的加法运算替换成allreduce即可。
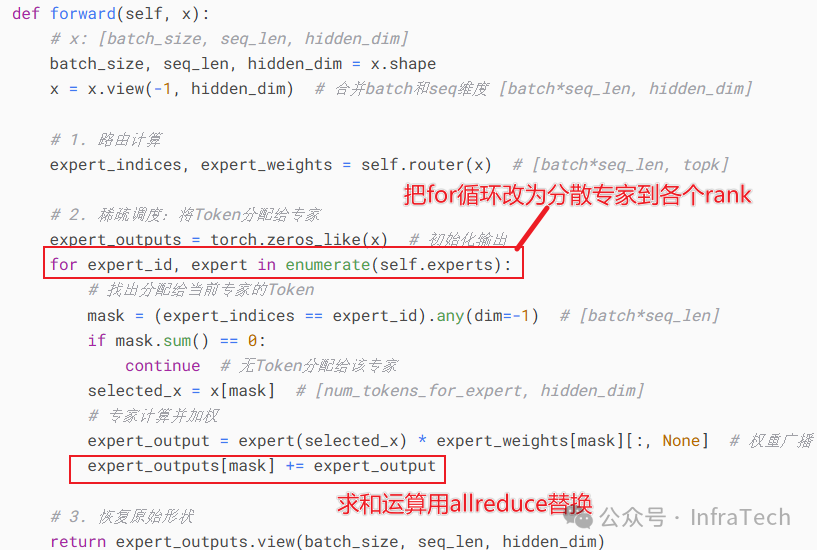
EP实践中多数用dispatch&combine两个动作进行数据分发与回收。dispatch负责数据统一分发,combine是把专家运算完的结果进行合并,数据格式一般是发送用FP8格式,回收用BF16格式。
计算流:Dispatch(init_routing & alltoall)-> Expert -> Combine(alltoall & weights)
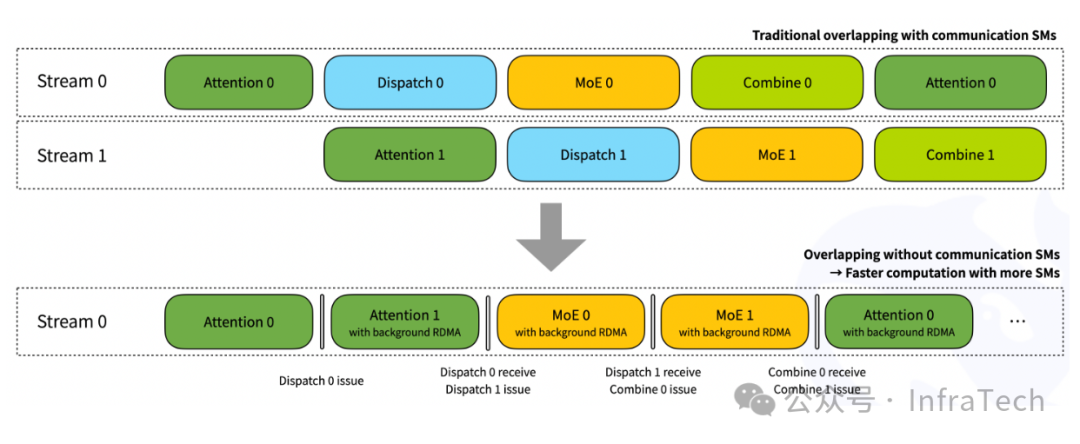
方法有两次alltoall通信,通信量跟数据大小正相关(tokens per batch * hidden_dim * topk * data_type),虽然相比allgather方案性能更优,但在prefill中依然需要考虑通信对性能影响。在DeepEP中提供了一种TBO(two-micro-batch overlapping)的方法来优化性能:
3.2 MoE与Dense通信的调整
MoE结构中,模型并行会让独立专家/共享专家产生额外的集群通信。考虑通信方面的优化调整,通信位置的移动通常在不会改变计算情况下,可能会降低计算量、通信量。最
场景一:专家计算前的allgather位置移动,这种场景在prefill中可能常见。把Attention后的allreduce计算拆成reduce scatter + all gather。调整的位置需要结合模型+并行策略,如在dsV3中MoE还涉及到FP8量化计算,这里列举两种:
-
allgather在 RMSNorm之后;
-
独立专家allgather在第一个FP8量化后、第一个矩阵计算前,共享专家allgather在quant后、或者allreduce之后;
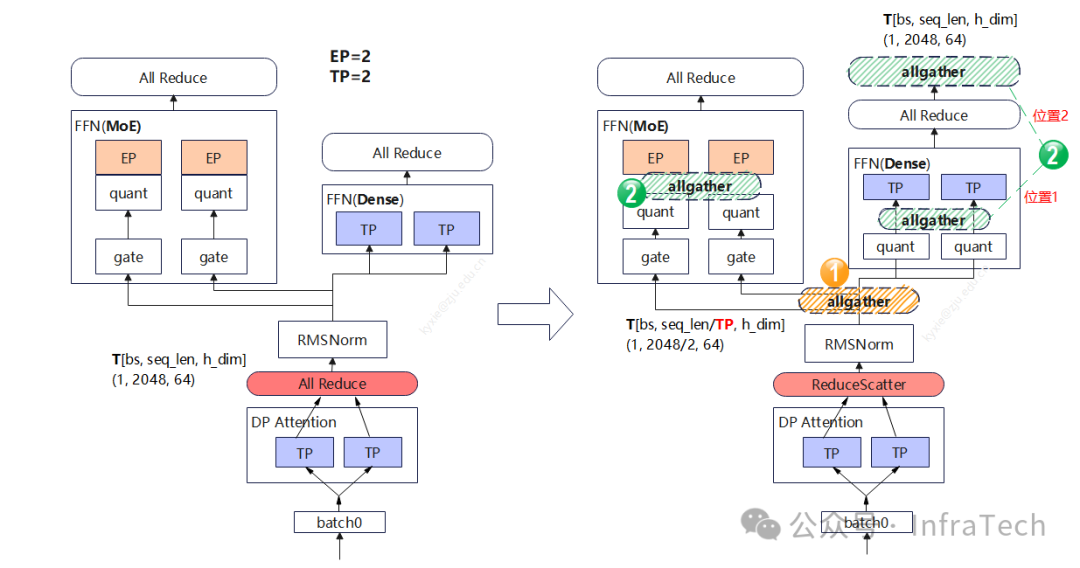
第1种方式将RMSNorm的计算量变为1/TP;第2种方式,allgather还能降低独立专家的gate计算量,但会多一个allgather操作,若共享专家allgather在位置1,通信总量变为1/2 * bs * seq_len * (h_dim + num_experts * 2),由于h_dim > num_experts,所以总量降低;
若共享专家allgather在位置2:通信总量多了gate+quant之后的allgather:bs * seq_len * num_experts,独立专家的计算量(相当于叠加了个SP)
场景二:MoE计算完后所有分支都用allreduce时,让allreduce合并,如下所示将共享专家与独立专家的结果相加后再进行一次集群通信。
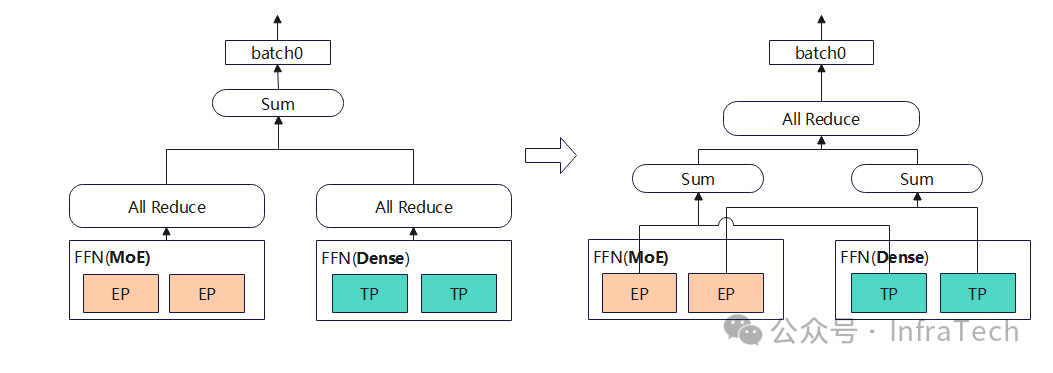
场景三:另一种方式当显存压力较小时dense层不做TP切分,即每个EP上面存一个冗余的独立专家,也可以减少一次集群通信:
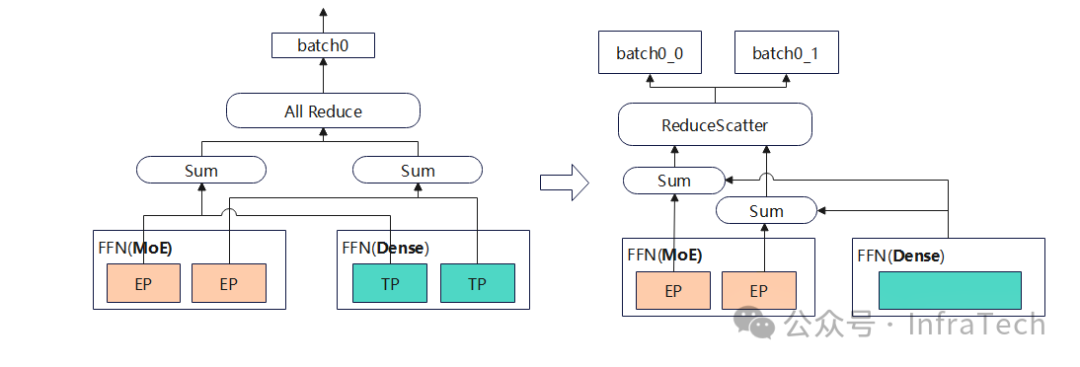
上述方式不一定在每个场景下都能带来性能提升,工程实践中需要进行测试比对。
3.3 EP转AFD
PD分离的decode阶段,如果面临请求量/序列长度变化大时,考虑把大EP并行(DeepEP)转成AFD(Attention FFN Disaggregation)。DeepEP这种大EP的场景中,为了提升decode的吞吐,单个实例规模会做得比较大,比如在deepseekV3中单卡部署一个独立专家,整体采用了320GPU方案。
Attention与MoE的计算特点:在QKV计算中,KV计算与存储跟序列长度正相关,处理的数据[bs, seq_len, h_dim/TP],随着计算进行KV的seq_len逐步增加。MoE层计算跟序列长度无关,处理数据[bs*seq_len*K, h_dim],seq_len=1。
根据这个计算特点,AFD部署能让序列的变化敏感的attention模块能与MoE模块异构搭配,可以根据场景设置attention与FFN部署实例的比例。
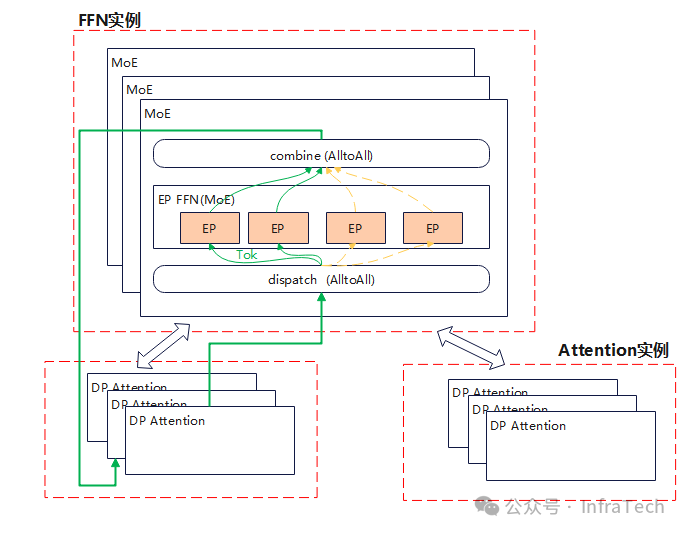
跟PD分离一样,AFD也有不同实例的调度问题,即如何把一个请求运算下发到A+F实例里面,而且AFD拆了模型,所以还需要进一步考虑:
-
多个实例之间的通信如何构建?
-
多个attention对应单个FFN时数据处理的流如何控制?
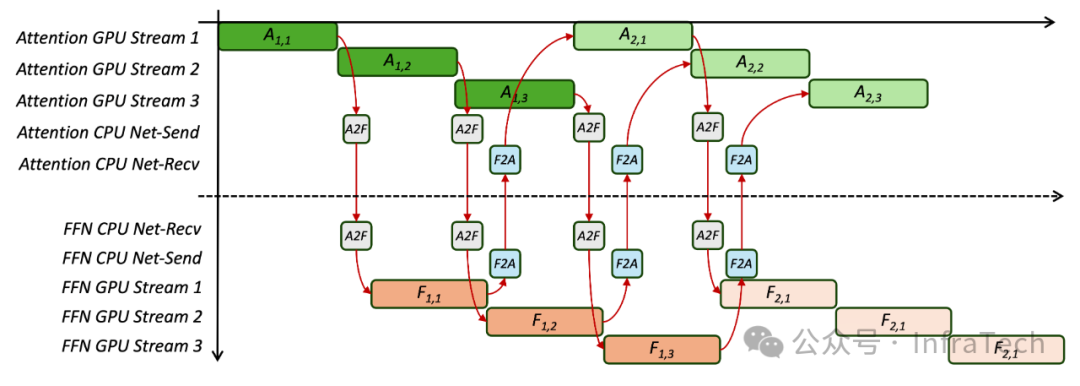
一种解决方案:单个attention实例与FFN实例通信时采用同步锁定,即当一个attention实例与FFN通信时,另一个attention实例无法与FFN实例交互,数据流水与PP并行类似,都是需要逐层串行运算,也存在空泡问题。
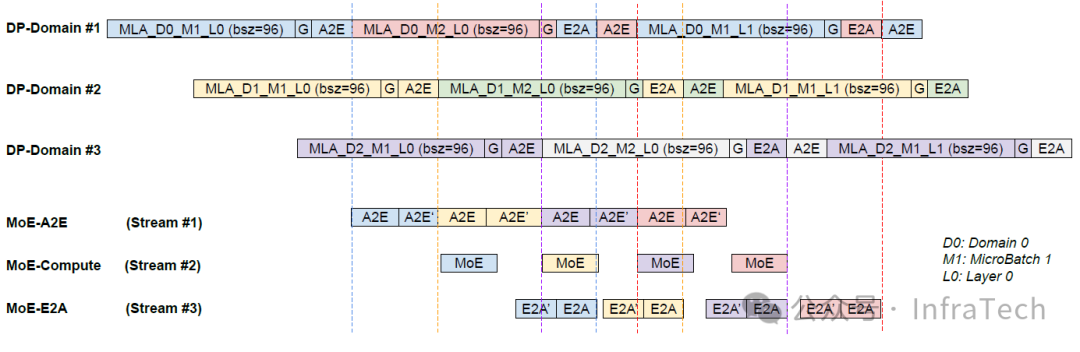
另一种是StepMesh的解决方案,不同计算之间全部用多流也能实现计算与通信掩盖
Step3论文中进行了DeepEP与AFD性能对比。在一些特定模型结构下,相比DeepEP,AFD有资源需求更少、部署灵活性更高(支持异构部署)、长序列处理更优、专家部署密度更高(负载均衡更简单)等特点。DeepEP策略可考虑优化成AFD策略。
4 Embedding(LM Head)层优化
Embedding(LM Head)层在模型结构中虽然计算量占比不大(首层和尾层),但其vocab_size值较大,使得mnk尺寸差值大(维度不匹配),导致矩阵的乘法运算效率低。同时还要考虑L2/L1 cache的大小,避免访存影响性能。除了在算法库侧进行优化改进以外,在并行策略上面也可以优化。
例如,deepseekV3的vocab_size是129280,而sequence(1K/2K/4K等)、hidden_dim 7168 ,在logits运算的时候,若采用DP并行,每个数据将独立进行计算,K轴是长度较大的vocab_size,M轴为长度较小bs * seq_len,这种尺寸在某些硬件上面不友好。优化如下:
-
为了降低K轴长度采用W矩阵列切,
-
为了提升M轴长度采用DP之间的数据拼接。
矩阵的计算过程变为如下所示:
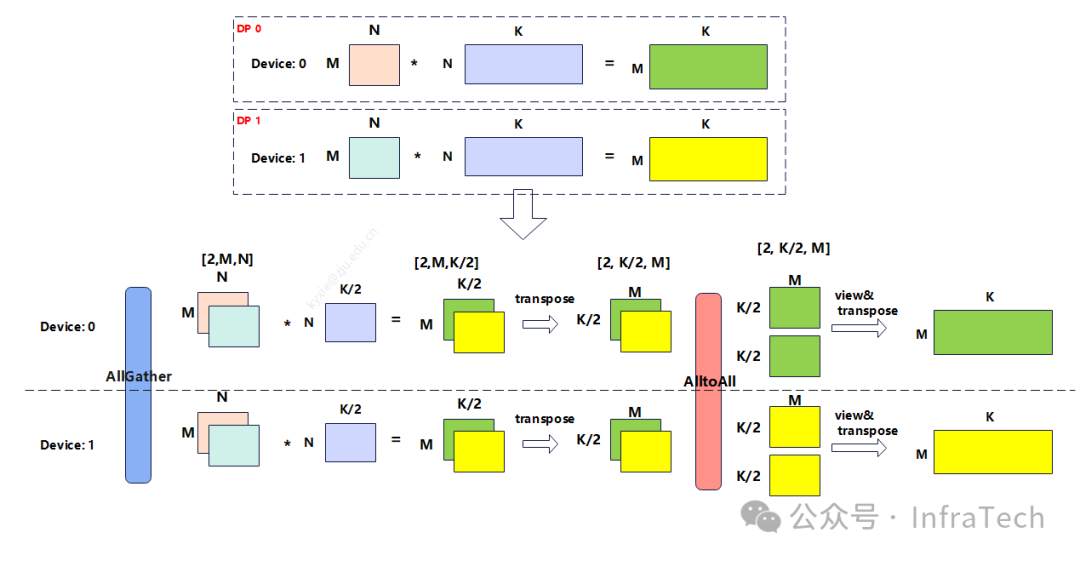
因为引入了两次通信操作allgather + alltoall,以及转置变换操作,这些额外操作可导致性能下降,可根据场景进行对比测试。
附1:
EP中init_routing操作:init_routing 是构造一个适合分散专家处理的数据格式,能够提升运算密度,代码:
# -*- coding: utf-8 -*-
import torch
import torch_npu
x = torch.tensor([[0.0, 0.0, 0.0, 0.0], [0.1, 0.1, 0.1, 0.1], [0.2, 0.2, 0.2, 0.2]], dtype=torch.float32).to("npu")
row_idx = torch.tensor([[0, 3], [1, 4], [2, 5]], dtype=torch.int32).to("npu")
expert_idx = torch.tensor([[1, 2], [0, 1], [1, 2]], dtype=torch.int32).to("npu")
active_num = 3
expanded_x, expanded_row_idx, expanded_expert_idx = torch_npu.npu_moe_init_routing(x, row_idx, expert_idx, active_num)
print(expanded_x)
print(expanded_row_idx)
print(expanded_expert_idx)输出内容如下,可以看到它将原始的x(输入的激活值) 进行扩充,方便AlltoAll转发后expert处理。
# expanded_x
tensor([[0.1000, 0.1000, 0.1000, 0.1000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.1000, 0.1000, 0.1000, 0.1000],
[0.2000, 0.2000, 0.2000, 0.2000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.2000, 0.2000, 0.2000, 0.2000]], device='npu:0')
tensor([1, 0, 3, 4, 2, 5], device='npu:0', dtype=torch.int32)
tensor([0, 1, 1, 1, 2, 2], device='npu:0', dtype=torch.int32)资料:
-
LLM推理并行优化的必备知识
-
vLLM V1 Scheduler的调度逻辑&优先级分析 - 知乎
-
[deepseekV3]https://arxiv.org/html/2412.19437v1
-
https://github.com/deepseek-ai/DeepEP
-
https://arxiv.org/pdf/2508.02520
-
https://github.com/stepfun-ai/StepMesh/blob/main/Introduction.md
-
Step3https://github.com/stepfun-ai/Step3/blob/main/Step3-Sys-Tech-Report.pd
-
https://www.hiascend.com/document/detail/zh/Pytorch/600/apiref/apilist/ptaoplist_000857.html
更多推理框架分析知识:
https://www.zhihu.com/column/c_1916901019268391457
欢迎点赞、收藏、关注!
<扫码关注="https://i-blog.csdnimg.cn/direct/23bba2d4b261452c929c68a8ecc3b2d7.jpeg" />
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)