
AI智能体|扣子(Coze)工作流搭建【火柴人心理视频】
AI智能体|扣子(Coze)工作流搭建【火柴人心理视频】1、领取100+工作流源码!复制到扣子即可直接使用2、AI认知+9节商业智能体拆解3、500+各行业高质量提示词4、超低价格使用即梦文生图图生视频和banana生图
用扣子Coze制作火柴人心理视频,五分钟一条!解放枯燥无趣的剪辑时间!(附教程+源码)
☀大家好,我是芝麻☀
AI智能体,AI副业搞米,AI实战案例分享
👇点击关注,每篇文章能给你带来一定的收获👇

你好,我是芝麻!
抖音最开始的口号是:记录美好生活。但是感觉现在抖音上很多视频最终的目的都是变现,要么卖课的,要么带货的,慢慢的已经失去了抖音最开始的样子.....
记录真实美好生活视频越来越少,就比如抖音上现在有很多情侣账号,每天记录自己生活中遇到的很多美好的事情,但是事实是什么?生活就是柴米油盐,哪有真实的情侣天天有时间记录生活,我不是说都是假的,但是很多都是同一个MCN下安排的CP,镜头前甜蜜,镜头后形如陌路,十分可悲。
像这种火柴人心理学类的账号,最后的目的也一定是指向心理付费咨询和收徒从而变现,这也没什么不好意思的,大家都是为了生活。但是在AI出现之前,就算你是老手,写文案,制作音频,找素材,剪辑,这一套下来剪一条这种视频至少得花1个小时左右,就算你是铁人,一天能做5条这样的视频不得了了,但是现在AI智能体可以5分钟制作一条,你只需要在此基础上微调即可,大大提高了你的产出效率!
我们来看看今天的智能体制作出来的视频效果如何
需求分析
这种工作流可以归属到视频类工作流,再细分一下就是静图视频,什么意思?
就是不需要使用到图生视频,视频的核心部分都是静态图片,将图片生成出来后,不需要再将其转化为视频了,因为图生视频是一个比较重的操作,所以需要和静态图片的区分开。
这个视频主要有四个部分组成:背景图、火柴人静态图、文案字幕、音频
背景图是由左上角水印、右上角水印组成的,如果想的话也可以在左上角加一个logo水印,可以把本文研究透了之后,研究一下怎么加logo上去
文案字幕、音频、火柴人静态图这三者都是紧密联系的,文案是由用户给出的关键词通过大模型生成出来的,音频和火柴人静态图是通过文案生成出来的
下面给出用户输入、工作流的实现步骤。
用户输入
-
左上角水印
-
右上角水印
-
文案标题
工作流步骤
-
定义用户输入
-
大模型根据关键词生成文案
-
切割文案
-
循环生成文案音频
-
批量生成图片
-
制作背景图
-
准备剪辑元数据
-
组装剪辑素材
-
返回草稿地址
工作流缩略图
本次使用了两个工作流,子工作流是需要嵌套在主工作流中的,具体为何请看后文分解,到底是为了炫技多此一举,还是内有玄机?
子工作流
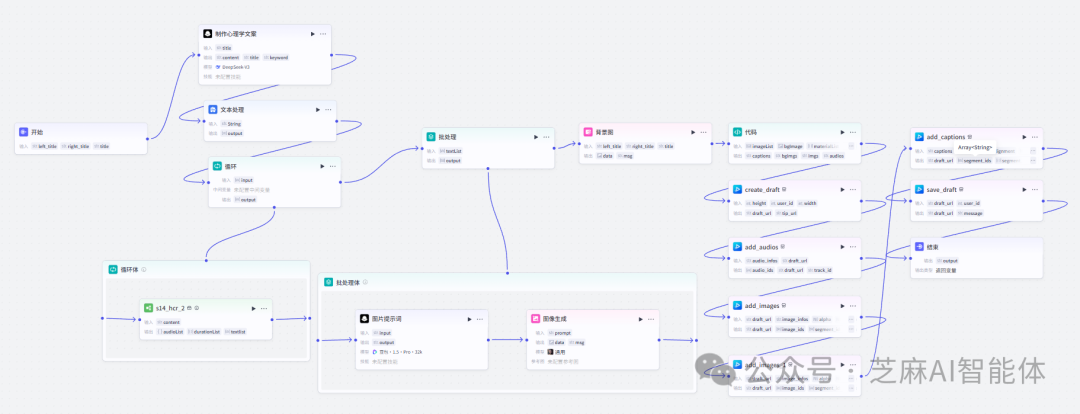
主工作流
工作流拆解
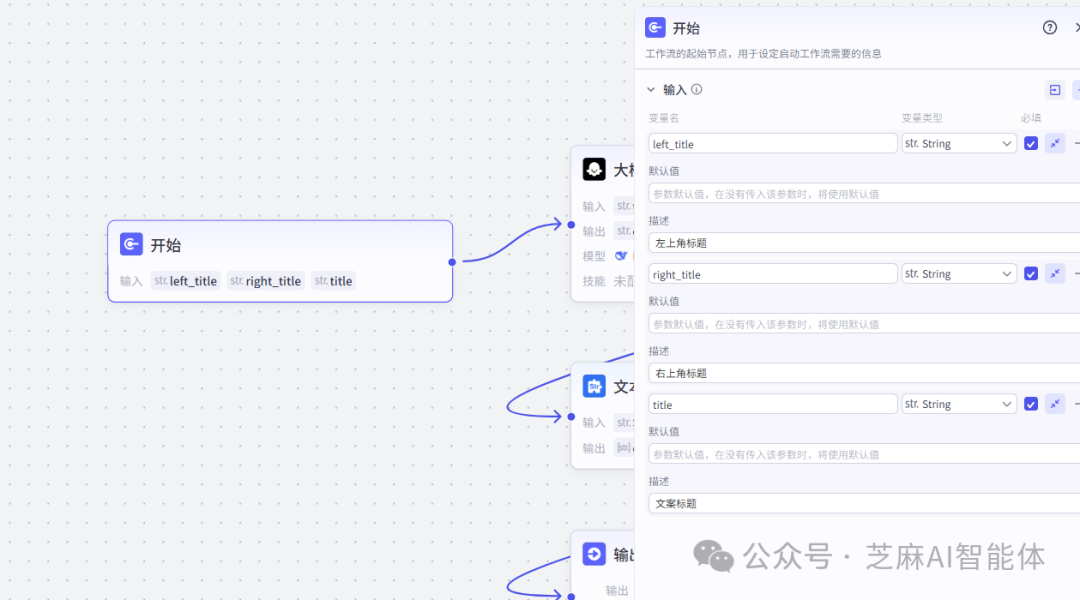
第一步,定义用户输入
开始节点定义3个参数
left_title是视频左上角的文案
right_title是视频右上角的文案
title是视频文案的标题,整篇文案是围绕这个标题来的
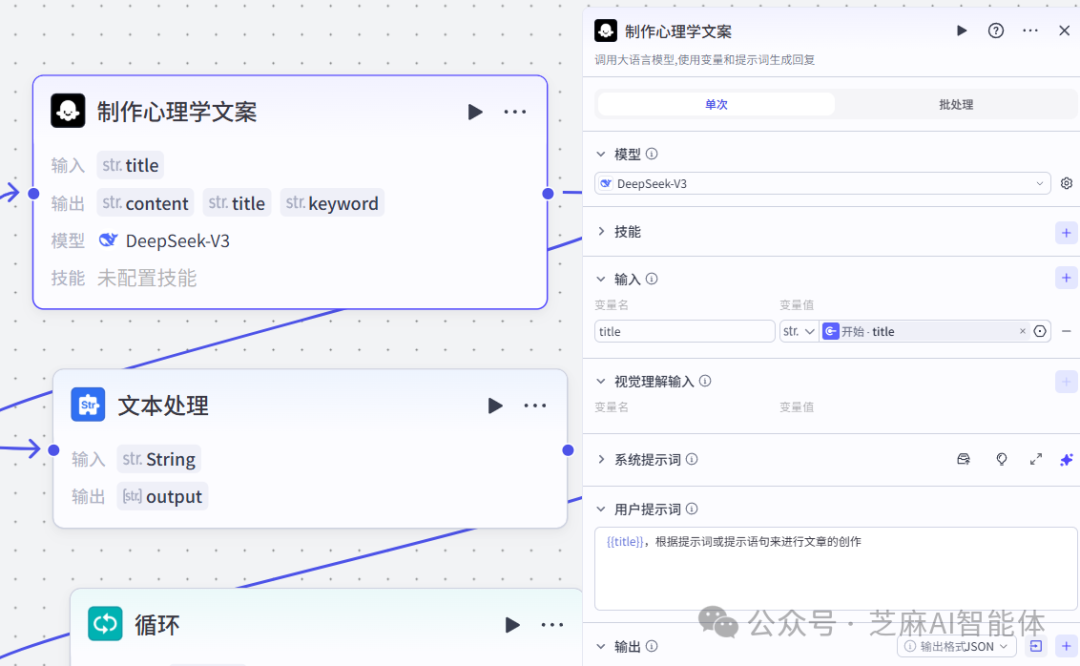
第二步,大模型根据关键词生成文案
使用大模型节点通过用户提供的标题生成精美的文案,大家有没有发现涉及到长文生成的都会使用deepseek大模型,因为这个模型有深度思考,生成出来的文案会更有“人味”
第三步,切割文案
大模型给出的文案是一大段的,需要将其切割成一个个的分镜句子,也就是每一幕展示的文案,这里使用换行、制表符、句号、分号还有一些特殊符号切割文案
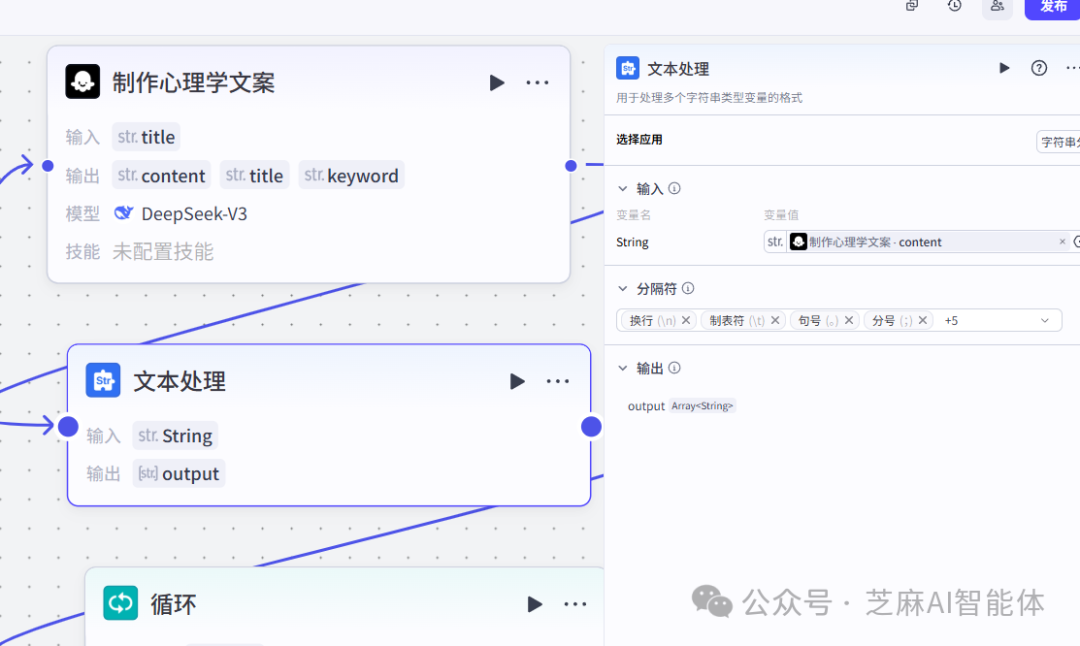
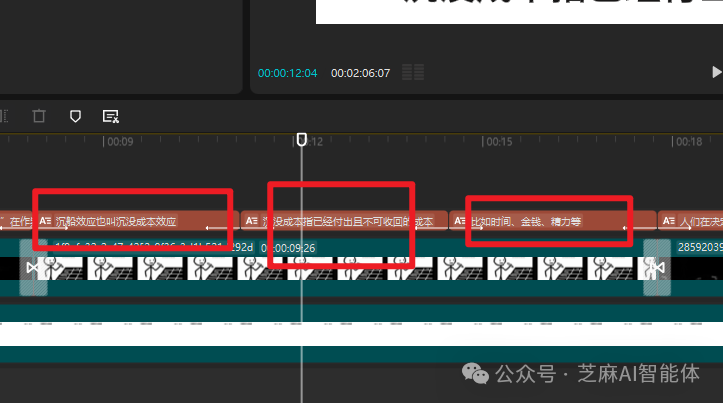
这里的切割是将文案拆成一个一个的句子,因为我们每一个单独的分镜都需要将一个完整的句子,然后后续再根据完整句子拆分成一个个的子句
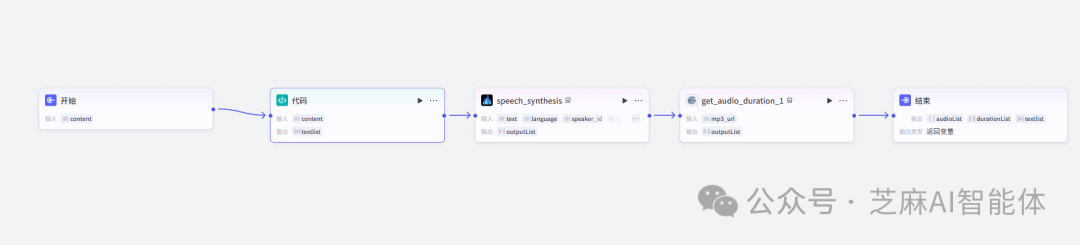
第四步,循环生成文案音频
循环使用子工作流对各个切割的文案制作音频,循环数组选择切割文案后的输出,输出选择子工作流的结果
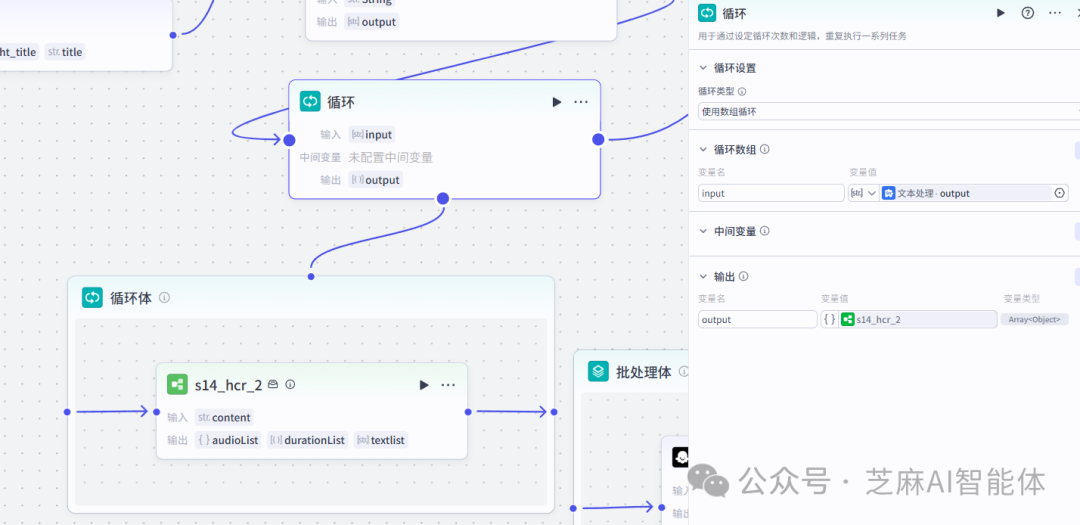
接下来看看子工作流干了啥工作
首先开始节点定义了本次要制作音频的一句文案
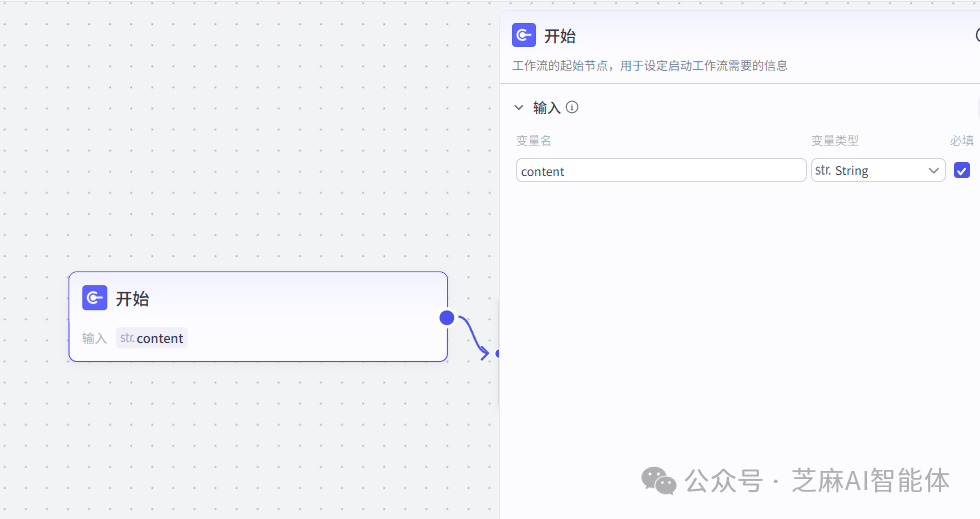
上文提到第三步的拆分是将一大段文案拆分成一个个的句子,这里需要将句子再拆分成一个个的子句,换种方法,使用代码节点来帮我们做这个拆分
代码(python):
import re
asyncdefmain( args: Args) -> Output:
params = args.params
content = params['content']
pattern = r'[,.,。!?:“”]\s*'
# 使用re.split()函数根据正则表达式切割文本
# re.split()函数会将匹配的分隔符从结果中移除
texts = re.split(pattern,content)
#移除数组中可能存在的空字符串元素
texts = [t for t in texts if t]
#构建输出对象
ret:Output = {
"textlist":texts
}
return ret有了文案之后就可以批量生成音频了,使用官方插件音频生成批处理生成音频
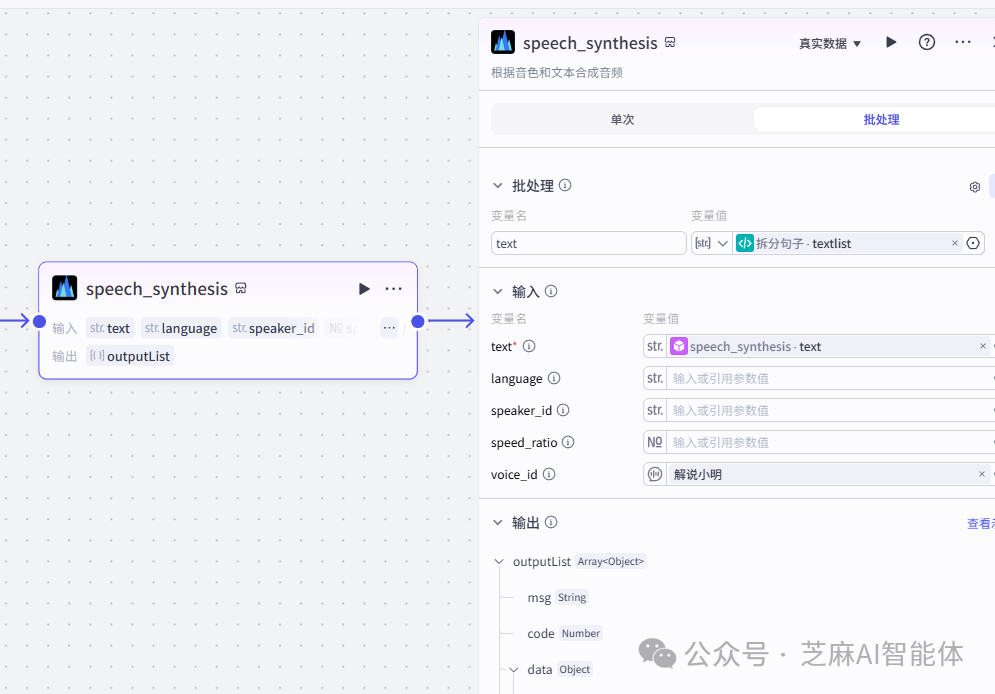
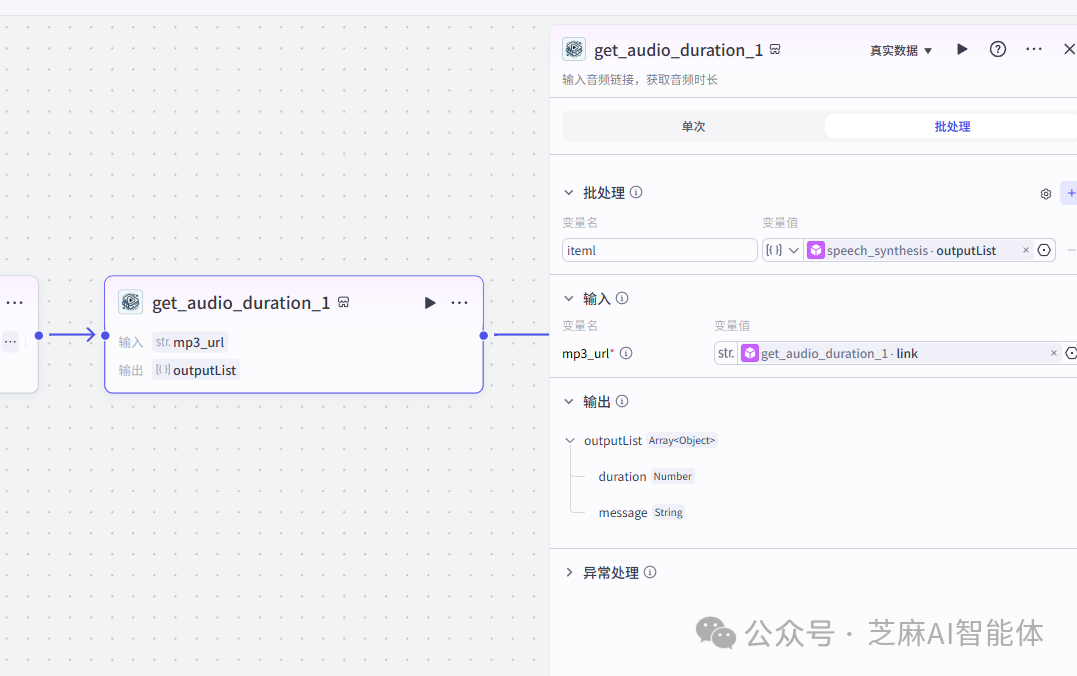
接着需要使用插件获取每一段音频的时长,也是一样的使用批处理,输入选择刚刚音频生成的输出
最后将音频数组、音频时长数组、文案数组返回
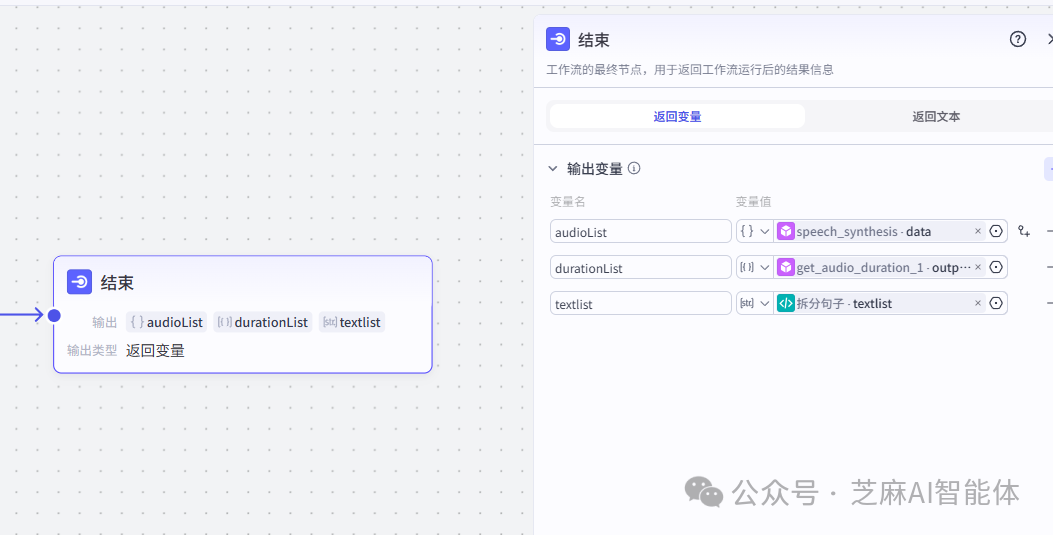
好了,子工作流就是这么简单,那揭晓下为什么这里为什么要使用子工作流,不能直接写在主工作流里吗?
当然不是故弄玄虚!因为子工作流使用到了批处理,需要对一个完整的句子进行拆分后对子句进行批处理,主工作流需要对完整文案拆分后的句子进行循环,这就构成了双重循环,目前coze是不支持循环/批量节点嵌套的
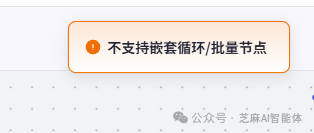
但是工作流是允许循环调用的,所以这里需要使用子工作流来规避这个不支持嵌套节点的限制,具体也可看看文末的讲解视频哦
第五步,批量生成图片
为每一个句子制作对应的中间火柴人的图片,将生成的火柴人图片数组返回
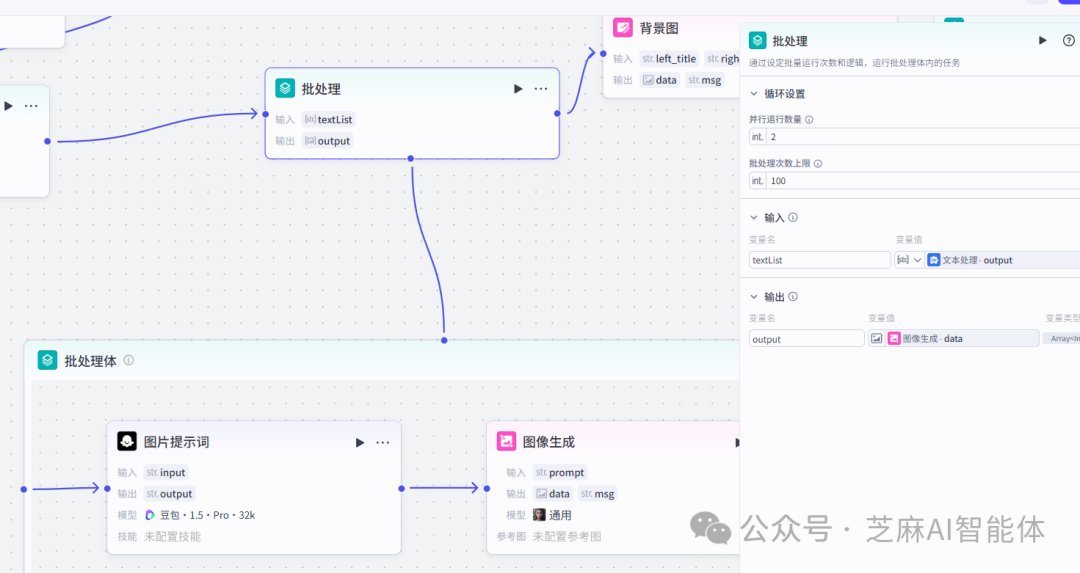
一张图对应的是一个完整的句子,所以输入的数组是完整句子的数组
使用大模型节点制作图片提示词,选择批量处理的元素,即每个句子
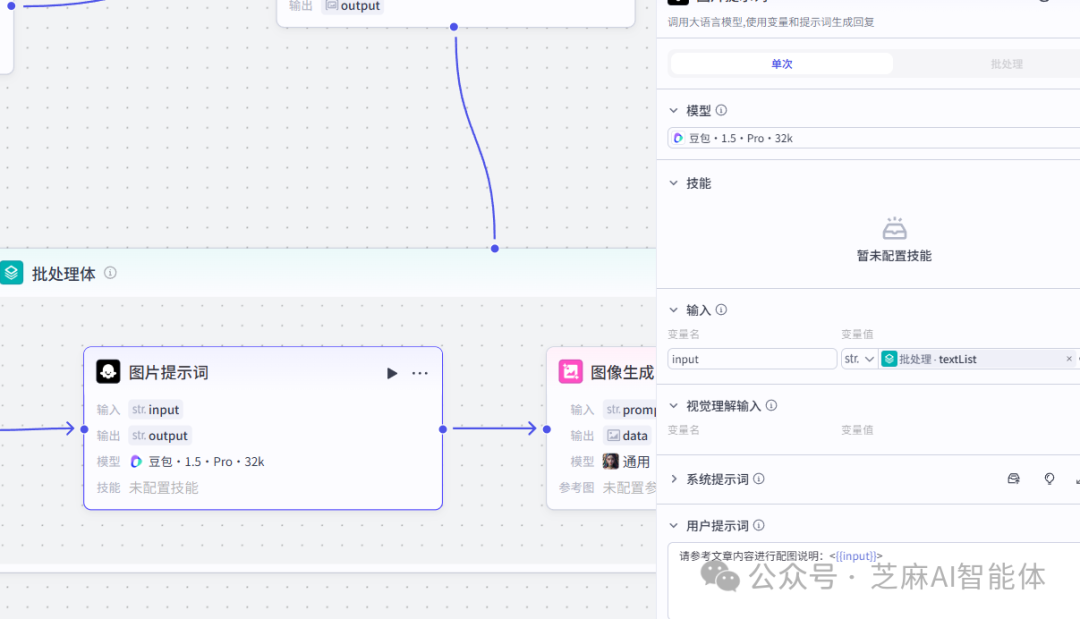
使用图像生成节点生成火柴人图像,本次的提示词较短,直接贴图给出
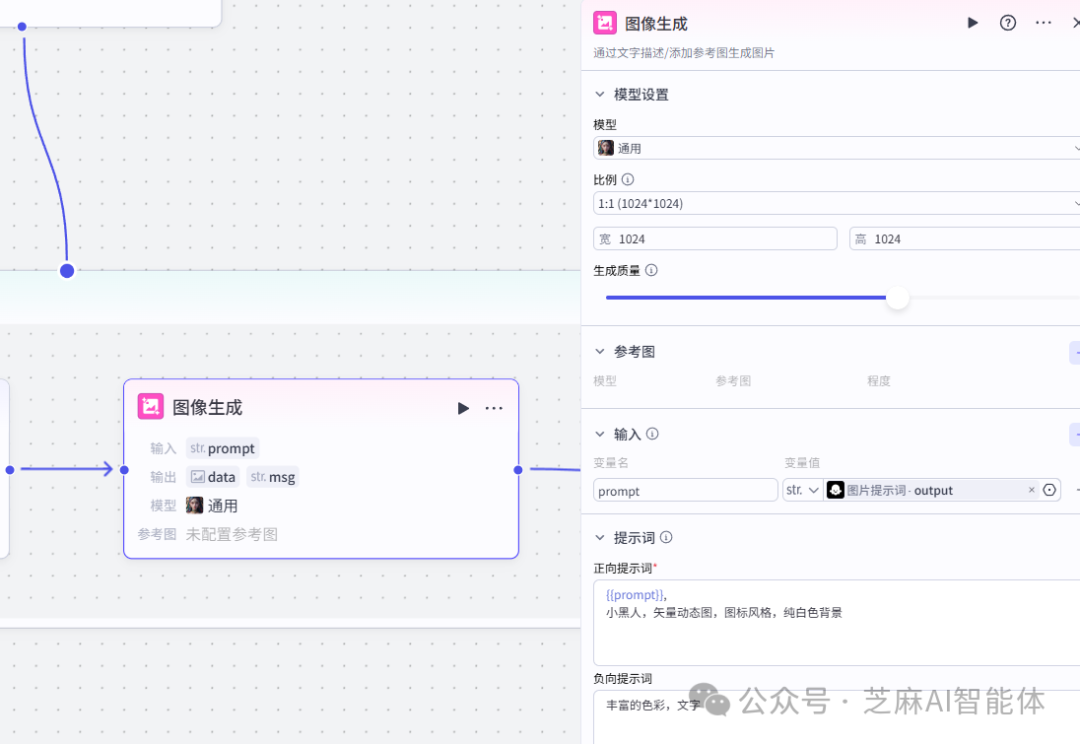
第六步,制作背景图
背景图制作十分简单,使用一个画板即可,设置大小为1080*1920,背景颜色设置成白色,将视频背景需要的元素都设置上去并且和输入元素绑定
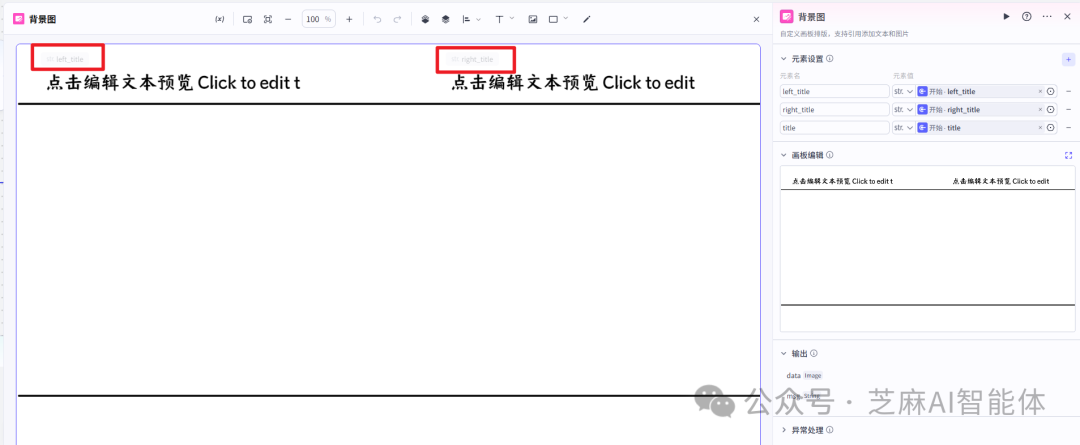
第七步,准备剪辑元数据
代码节点主要是对之前的音频数组、图片数组、文案数组进行一个处理,给出剪辑需要使用到的元数据,这里的代码有点长,大家直接拿去用吧
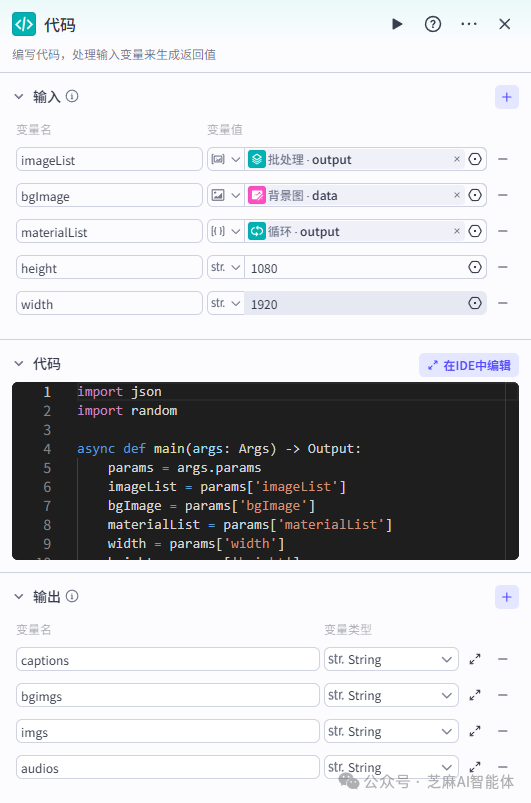
第六步,组装剪辑素材
好,有了这些剪辑元数据就可以进行剪辑了
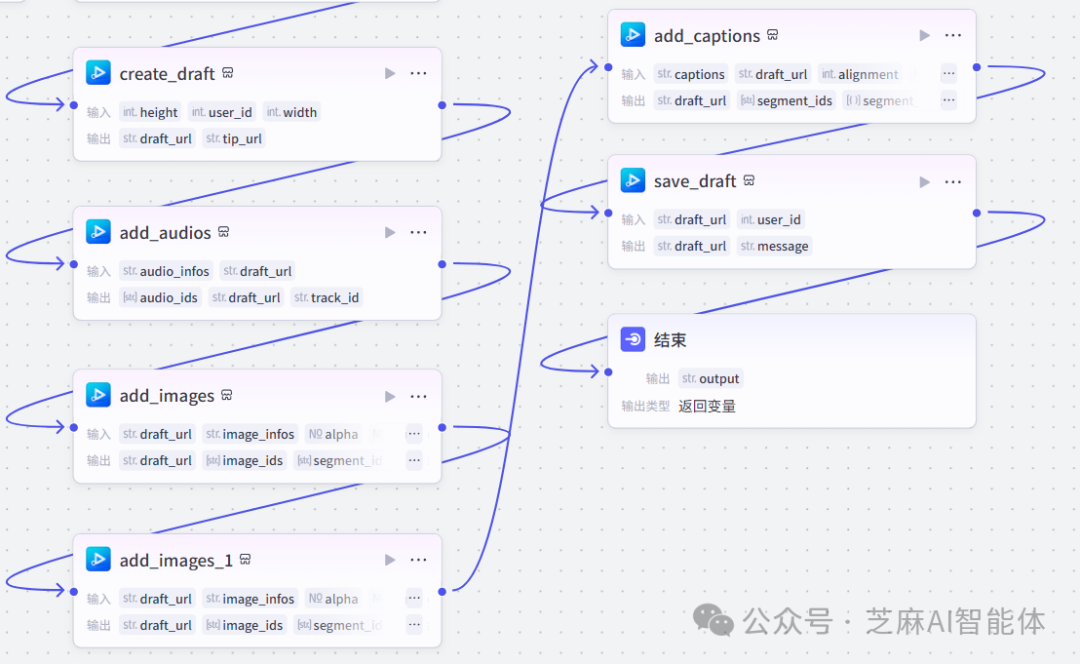
create_draft:创建空白草稿
add_audios:添加音频到草稿中
add_images:添加火柴人图片到草稿中
add_images_1:添加背景图到草稿中
add_captions:添加文案字幕到草稿中
save_draft:保存草稿
第六步,返回草稿地址
将上一步save_draft的返回值返回,是一段json草稿地址
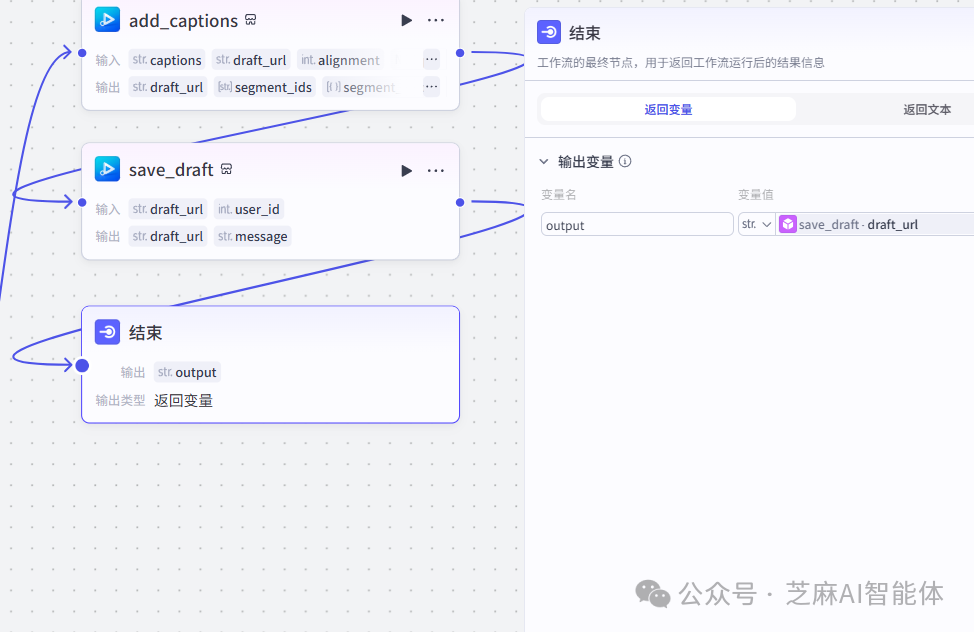
总结
本次的工作流涉及到的东西还是比较多的,文生文、文生音频、文生图、代码,希望大家取其精华,而不是工作流本身,工作流只是一个工具,现在随便一个程序员转工作流开发都是分分钟的事情,重要的是学会思路。
AI能在这些流程中扮演什么样的角色, 可以完成哪些人类完成不了或者可以替代人类完成的工作,这才是重中之重。
本期的内容就到这里了,感谢你的耐心。
如果你有智能体定制,合作,学习智能体,学习智能体变现等需求,也可以找我。
跟着文章的步骤实操,实现了这次的工作流,可以把结果放在评论区和大家分享!
做的过程中遇到了问题也可以评论区留言,我会为大家解答!
看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!
更多推荐

 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)