
Claude Sonnet 4.5:一次面向落地的常规升级(性能、安全、开发者工具)
Anthropic推出ClaudeSonnet4.5,主打长时任务处理与安全性升级。性能方面,30小时持续编码能力(SWE-bench)、OSWorld任务成功率提升至61.4%,代码修复准确率82%。安全维度强化欺骗防御与内容过滤(ASL-3/CBRN过滤器)。开发者支持上,集成Cursor/Windsurf工具链,提供AgentSDK和自然语言开发实验功能,API价格不变。
Anthropic 发布了 Claude Sonnet 4.5。官方把它定位为目前最强的编码模型之一,并给出了具体改动点。下面把公开信息按三类梳理:性能、安全、开发者支持。数据均来自官方口径与对外说明,实际效果仍需结合你的项目场景自行验证。
一、性能变化(面向复杂任务与长流程)

长时任务
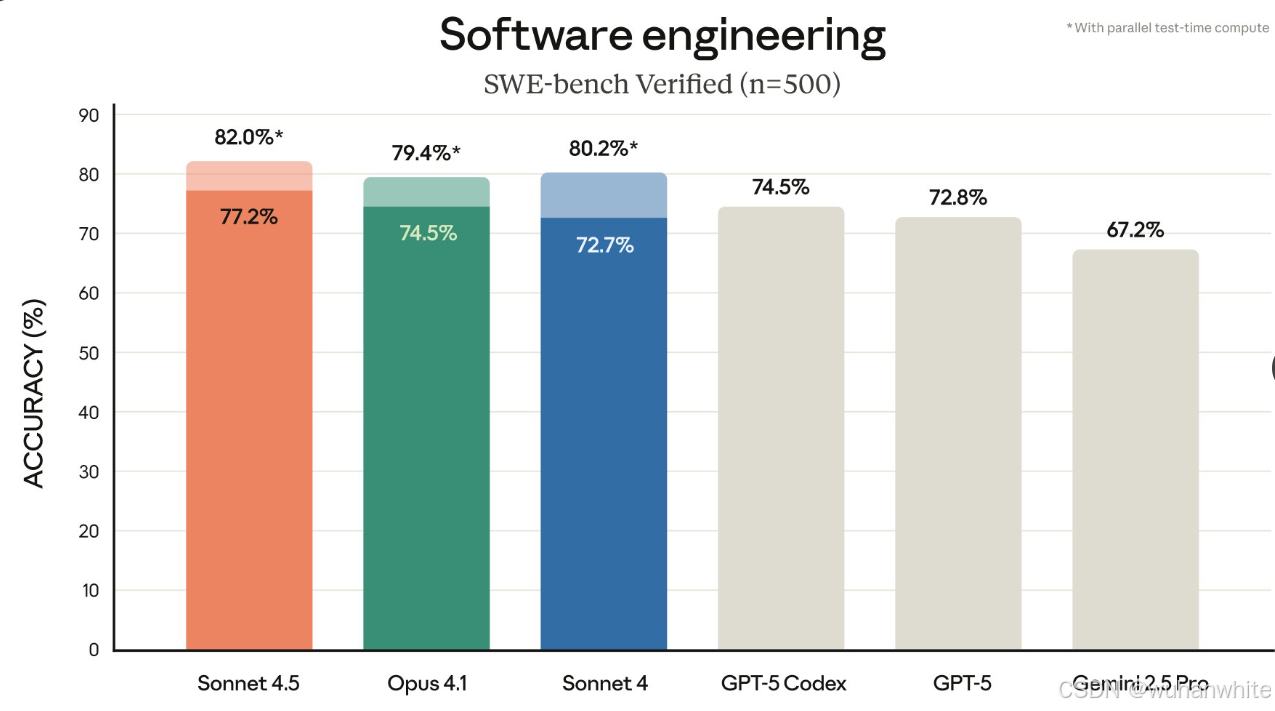
在 SWE-bench 编码评测中,官方称该模型可持续工作 30 小时;作为参照,他们给出的 GPT-5-Codex 能力为 7 小时。

桌面/环境操作任务
OSWorld 任务成功率由 42.2% 提升至 61.4%。
代码修复
给出的准确率为 82%。
推理与专业领域
- • 数学推理进入"第一梯队"
- • 在金融、法律、医学等专业任务上的表现有提升
以上数据表明它更偏向能处理跨多步、上下文较长的任务。是否对你的代码库有帮助,取决于:仓库规模、依赖复杂度、测试覆盖率和你给到的上下文质量。
二、安全相关(更稳的默认策略)
失调行为评分
在"欺骗、权力欲"等维度上,官方称新模型得分更低,整体安全性优于 GPT-5。
提示注入防御
对提示注入攻击的抵御能力加强,误报率降低约 10 倍。
安全等级与内容过滤
- • 达到 ASL-3 等级
- • 新增 CBRN(化学/生物/放射/核)相关风险内容过滤器
这些调整意味着默认安全边界更靠前,但不代表可以忽略你侧的日志审计、权限最小化和人审兜底。
三、开发者支持(把模型放进工作流)
Cursor已支持调用Claude 4.5 Sonnet模型
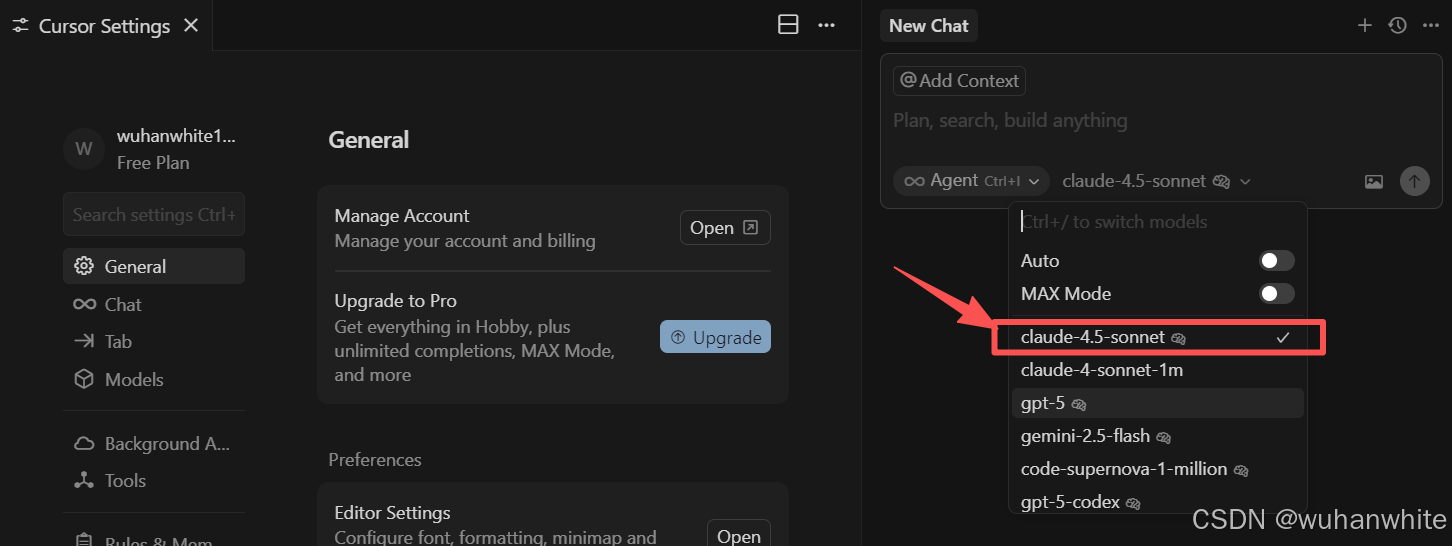
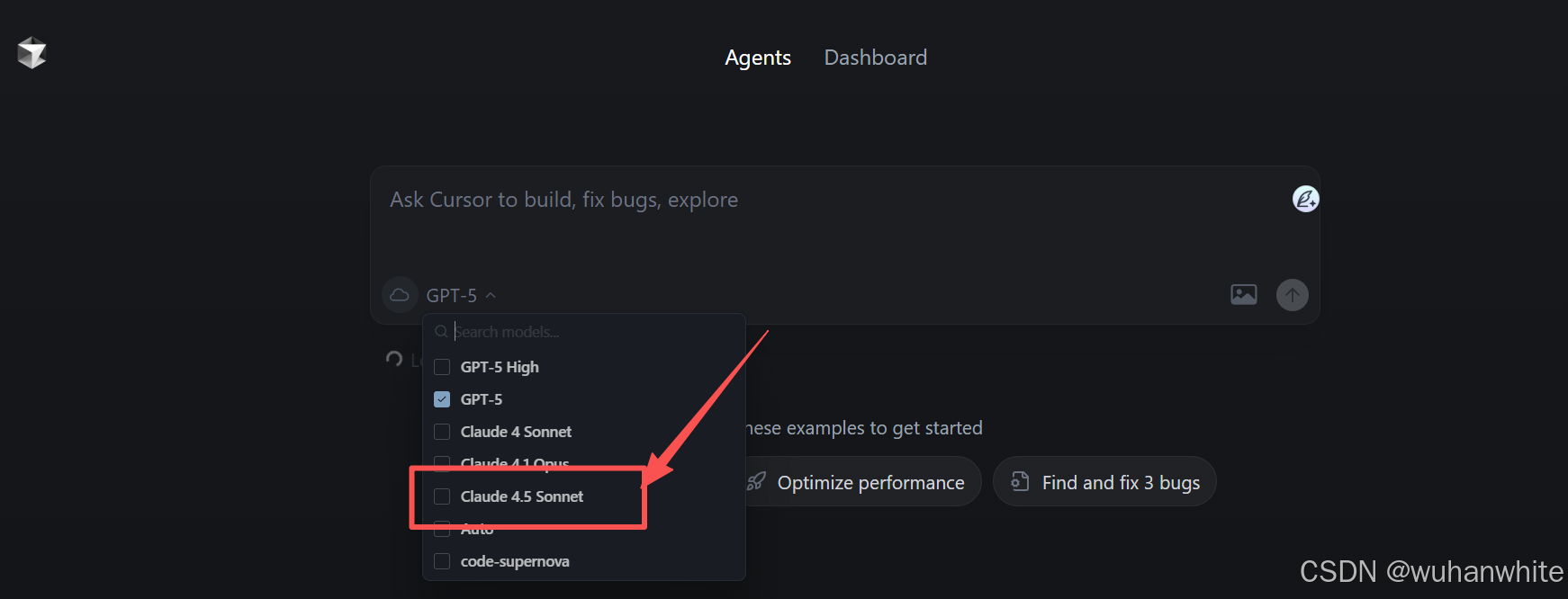
Windsurf也已支持调用Claude 4.5 Sonnet模型
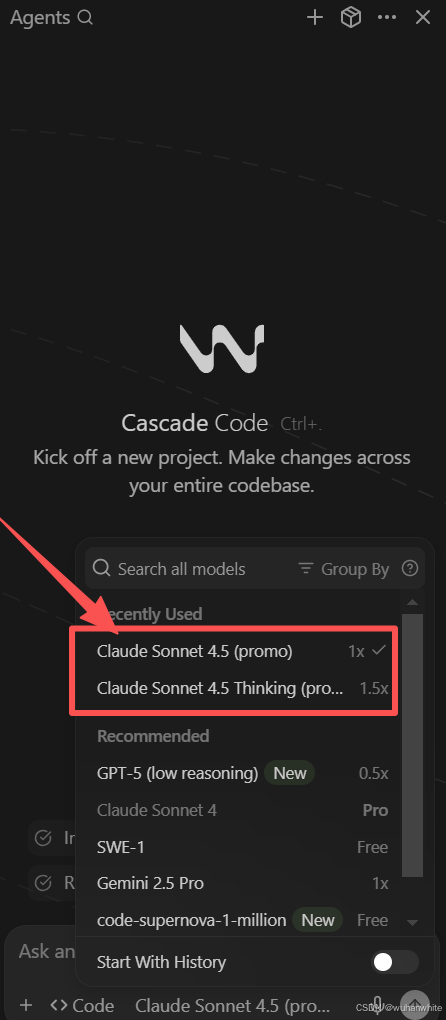
Claude Agent SDK
面向"长任务、可授权、可追溯"的代理开发,重点在长时记忆与权限管理。
"Imagine with Claude" 实验功能
支持以自然语言进行交互式的软件开发。
API 价格
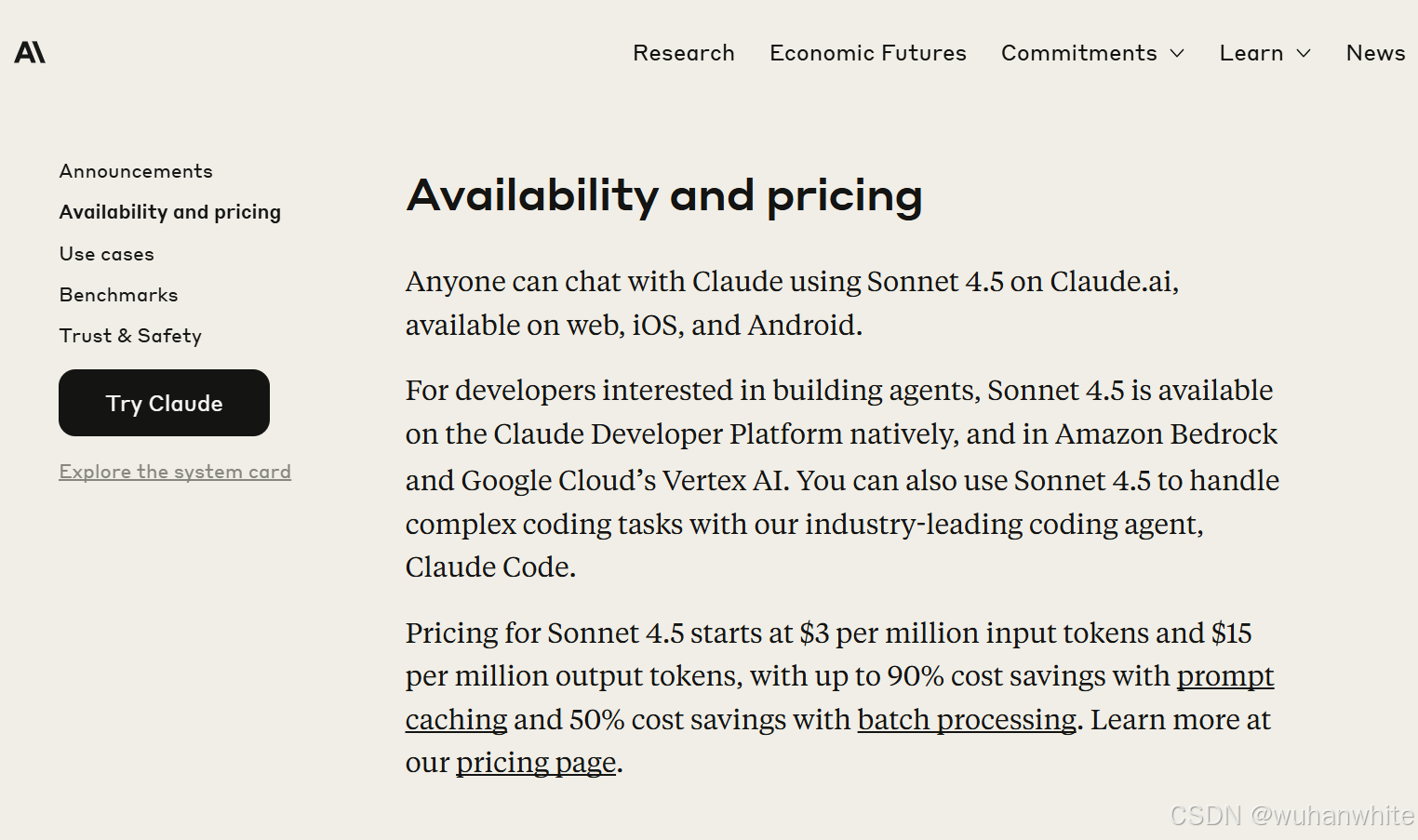
保持不变——输入 $3/百万 tokens,输出 $15/百万 tokens。
这一部分更像"把模型嵌入工程流程"的工具化升级,适合需要把 AI 挂到流水线、工单、代码审查或日常脚本里的团队。
适用场景与落地建议
样板用法
前端
用提示词生成最小可运行骨架(如移动端商城:路由、状态、Mock、接口封装),再由人补齐细节与验收。
后端/平台
用 Agent SDK 做长任务(巡检、报表拼装、脚本生成),前置权限与审计。
度量优先
建议记录修复成功率、回滚率、平均完成时间、误报/漏报等指标,结合你的代码库做对比评估。
安全前置
即便模型侧更"稳",仍需要在网关/中间层落签名校验、幂等、审计留痕和必要的人审。
小结
Claude Sonnet 4.5 的变化点比较清晰:更长的连续工作能力、更保守的安全默认值、以及更实用的开发者工具。它并不意味着"自动完成所有开发",但在需要长链路、跨步骤处理的任务上,可能比上一代更省事。是否能带来实质收益,仍取决于你给它的上下文质量、团队流程和度量方式。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)