
我花1小时,AI用1分钟,全自动生成n8n工作流!这个新玩法爽爆了!
本文介绍了如何利用n8n-mcp开源项目解决n8n工作流搭建中的痛点。作者分析传统AI方案的不足后,重点讲解了n8n-mcp如何通过模型上下文协议实现AI与n8n的深度集成,提供详细的配置步骤和三种实战测试案例。文章强调该工具能显著提升复杂工作流的搭建效率,同时也提醒用户注意生产环境的安全使用规范。作为n8n进阶系列的开篇,作者旨在帮助读者提升自动化工作效率,并介绍了相关实践社区资源。
大家好,我是万涂幻象,一名专注商业 AI 智能体开发与企业系统落地的实践者。 致力于为各行各业打造能创造增长、构筑优势的AI落地解决方案。
我有个习惯,会定期把社群的聊天记录从头到尾捋一遍。
主要是为了看看,大家最近在琢磨什么,高频讨论的技术点有哪些,或者哪些问题被反复提起,值得沉淀下来,做成一篇正式的教程或FAQ。
就在上周,我整理第二季度的热门提问时,又翻到了那条熟悉的对话记录。那是很早之前,一个群友问我:“我们之前发过一篇n8n的入门,后面还会更新更进阶的教程吗?”
看到这条记录,我下了个决心,这个关于“进阶教程”的坑,不能再拖了,必须得填上。
既然决定要重启这个系列,那第一篇讲什么,就得想清楚。我首先想到的,还是那个所有n8n深度用户都绕不过去的问题:搭建复杂流程时,那没完没了、极其耗费心神的“体力活”。如果不能让大家从这种重复劳动中解放出来,任何花里胡哨的“进阶”技巧都是空中楼阁。
正是在我研究如何从根上解决这个核心痛点的过程中,我发现了 n8n-mcp 这个开源项目。它本身不是一篇教程,但它比任何教程都更能解决这个根本问题。它通过AI,恰好能把搭建复杂工作流时最繁琐、最劝退的部分给自动化了。
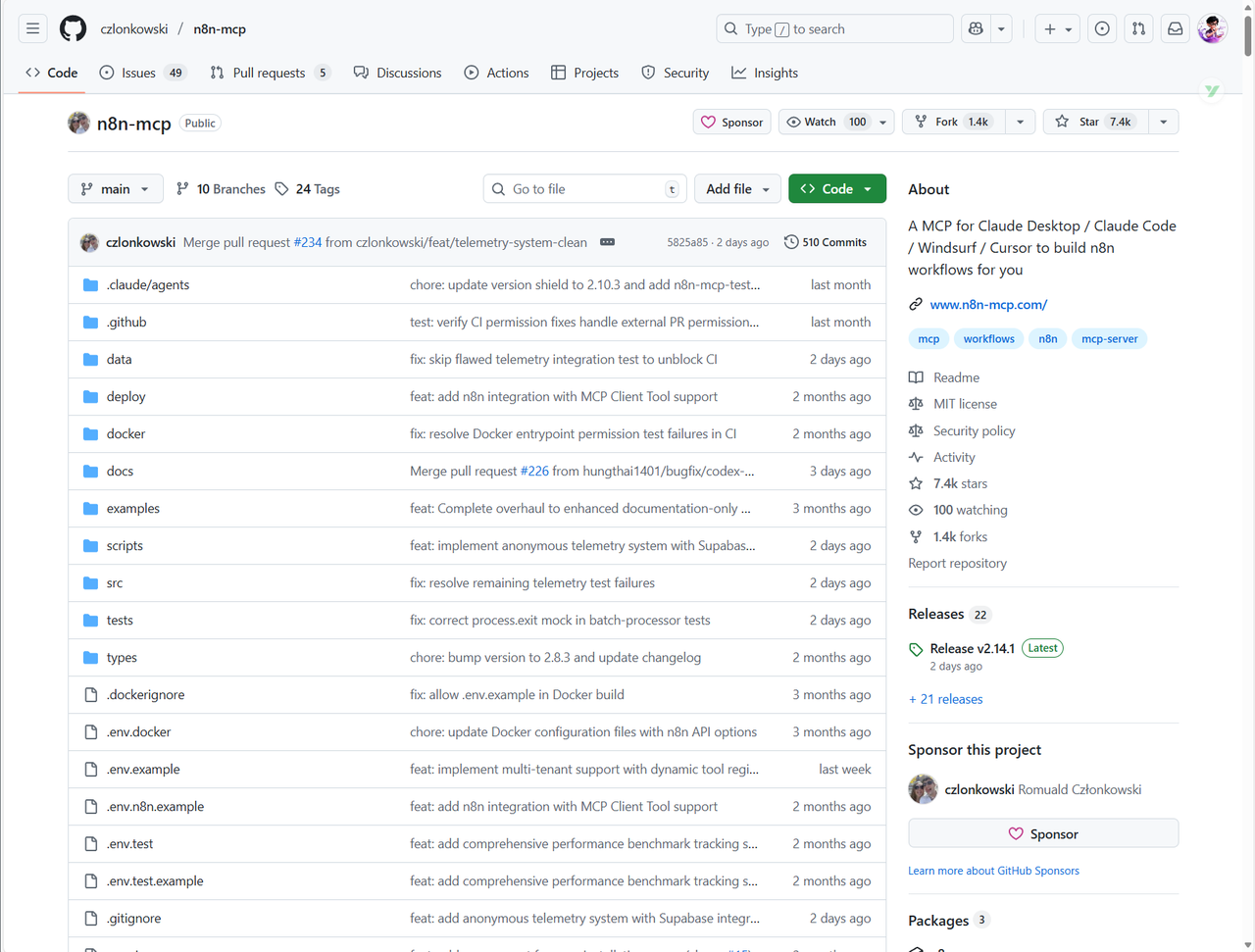
所以,我决定把对这个工具的深度实践,作为我们n8n进阶系列重启的“第0课”。先把大家的生产工具变利索了,我们再聊后面的招式。今天,就把这份“破冰”教程交出来,
01|症结所在:为什么AI写不好n8n的“代码”?
在说新方案之前,我们得先用最直白的话弄清楚,老路子为什么走不通。
✅ 版本对不上,一切都白费
-
n8n是个非常活跃的开源项目,迭代速度飞快。这意味着,一个节点的功能、名称、甚至参数,在这个版本和下个版本里可能完全不同。
-
以前我们喂给AI的JSON模板,都是基于某个特定版本的。AI学到的知识,从一开始就“过时”了。这就导致它给你生成的方案,很可能根本没法在你当前最新版的n8n里运行。这是个硬伤,没法解决。
✅ 只知其然,不知其所以然
-
AI通过看大量的JSON文件,能学会“格式”,但学不会“逻辑”。它知道一个HTTP Request节点大概长什么样,但它不明白这个节点拿到的数据,要如何被下一个节点正确地引用。
-
所以,它生成的简单流程可能还凑合。一旦涉及到IF判断、数据合并、循环这些需要传递和处理数据的复杂逻辑,就一定会出问题。因为它是在做“文本生成”,而不是“流程设计”。它只是个“格式翻译工”,不是“流程架构师”。
因为这两个根本性的缺陷,导致之前的方案都停留在“玩具”阶段,没法在实际工作中堪当大任。
02|另辟蹊径:让AI直接“读取”和“操作”n8n
n8n-mcp这个项目,就聪明在它完全绕开了上面的坑。它通过一种叫模型上下文协议(MCP)的技术,给AI和n8n之间搭了一座桥。
✅ 给AI一本“活”的官方使用手册
-
你可以把它理解成,给AI助手(比如Claude)提供了一本n8n的完整“使用手册”。这本手册不是几篇文档抄抄写写,而是硬核的数据支撑:它覆盖了n8n全生态的535个以上的节点,其中99%的节点属性和90%的官方文档都被结构化地收录了进来。
-
AI有了这个,就从一个啥都懂点的“通才”,摇身一变成了专业的“n8n专家”。它对每个节点的理解,不再是模糊的猜测,而是精确的查询。
✅ 两种模式:从“只读”到“完全控制”
n8n-mcp很灵活,它主要有两种运行模式:
-
文档模式(基础): 这是只读模式,AI可以查询所有节点的用法、参数、示例,但不能操作你的n8n。非常适合学习和规划工作流。
-
管理模式(完整): 当你把自己的n8n API密钥配置进去后,就开启了完全体模式。AI可以直接上手,帮你创建、修改甚至执行工作流。
03|上手配置:三步让AI连上你的n8n
介绍完它是什么,我们马上动手,把它配置起来。整个过程,我们拆解成清晰的三步,跟着走就行。
✅ 第一步:准备一个AI助手(如果你还没装的话)
-
你需要先在你的电脑上安装一个支持模型上下文协议(MCP)的AI工具。
-
市面上这种工具不少,比如 Claude Desktop、Cursor、OpenAI的CodeX 等等。它们本质上都是能和你用自然语言对话,并帮你操作电脑的AI助手。你得先有这么一个“主程序”。
✅ 第二步:找到AI助手的配置文件
-
我们的核心任务,就是把
n8n-mcp的配置信息,写到你上一步安装的那个AI助手的“配置文件”里去。 -
这个文件通常藏得比较深,不同工具、不同操作系统位置都不一样。
-
比如,如果你用的是 Claude Desktop:
-
macOS:
~/Library/Application Support/Claude/claude_desktop_config.json -
Windows:
%APPDATA%\Claude\claude_desktop_config.json -
Linux:
~/.config/Claude/claude_desktop_config.json
-
-
其他工具的配置文件位置,可以去它们的官网查询。总之,你得先找到那个用来“设定”这个AI助手的文件,通常是
.json或.toml结尾。
-
✅ 第三步:粘贴并修改配置代码
-
找到配置文件后,用记事本或者任何代码编辑器打开它,把下面这段代码完整地复制进去。
-
我强烈推荐用Docker方式来配置。 我自己实践时,踩过本地环境的各种坑(比如Node版本冲突),最后发现Docker是最干净、最省心、几乎不会出错的办法。
-
在粘贴配置代码之前,先打开你电脑的终端(Terminal)或者命令行工具,提前把Docker镜像给拉取下来。这样能避免第一次运行时因为网络问题卡住。就执行下面这一行命令:
docker pull ghcr.io/czlonkowski/n8n-mcp:latest-
拉取成功后,再把下面这段JSON代码完整地复制到你打开的配置文件里:
{
"mcpServers": {
"n8n-mcp": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"--init",
"-e", "MCP_MODE=stdio",
"-e", "LOG_LEVEL=error",
"-e", "DISABLE_CONSOLE_OUTPUT=true",
"-e", "N8N_API_URL=http://host.docker.internal:5678",
"-e", "N8N_API_KEY=your-api-key",
"ghcr.io/czlonkowski/n8n-mcp:latest"
]
}
}
}-
代码粘贴进去后,就差最后一步,也是最关键的一步:替换掉里面的两个占位信息。当然,这事儿的前提是你已经有一个正在运行的n8n实例了。如果你是纯新手,还没在自己电脑或服务器上部署过n8n,可以先停一下,去看我们之前写的这篇保姆级教程把基础环境搭好:《N8N 私有化部署实战教程:企业 AI 工作流引擎从 0 到 1 搭建指南》。
-
对于已经有n8n环境的朋友,我们要替换的第一个是
N8N_API_URL。这玩意儿说白了,就是你访问自己n8n的那个网址,比如http://localhost:5678。不过这里有个小坑要注意:因为我们推荐的n8n-mcp也是在Docker里跑,所以当它要找同样在你电脑上的n8n时,你得用一个特殊的地址http://host.docker.internal:5678,直接用localhost它会找不到。
-
第二个要替换的是
N8N_API_KEY。这个就得去n8n界面里手动拿了。你登录进去,顺着左下角的头像点进Settings,再找到n8n API,就能看到Create API key的按钮。我建议顺手给它起个名,比如n8n-mcp-key,省得以后忘了是干啥的。点完生成,把那串长长的字符复制出来,替换掉代码里your-api-key那部分就行。
-
最后,保存配置文件。 我这次测试用的Trae,保存后当显示对勾时,这样,
n8n-mcp这个“翻译官”就算正式上岗了。
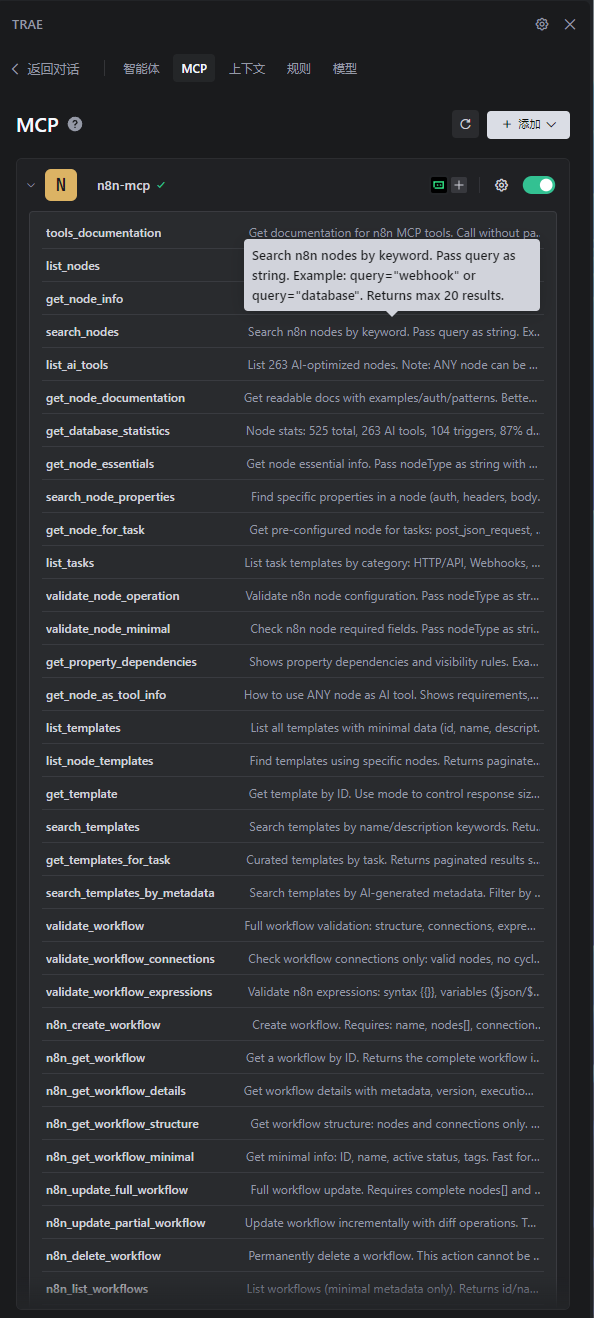
04|是骡子是马,拉出来遛遛
环境配通了,就到了交作业的环节。我设计了三个更贴近我们日常运营工作的场景,来测试它的真实能力。
✅ 第一关:社群运营自动化
-
这是一个非常基础的社群拉新动作,但手动操作很繁琐。
-
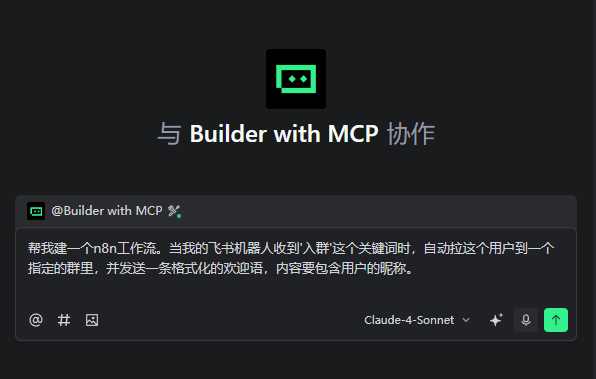
我的指令: “帮我建一个n8n工作流。当我的飞书机器人收到'入群'这个关键词时,自动拉这个用户到一个指定的群里,并发送一条格式化的欢迎语,内容要包含用户的昵称。”
-
结果: 整个流程框架——飞书触发器、添加到群聊、发送消息这三个核心节点,它都给我搭出来了,并且正确地连在了一起。我只需要进去把具体的群ID和欢迎语模板填一下就行。对于这种固定流程的自动化,它完成得相当不错。
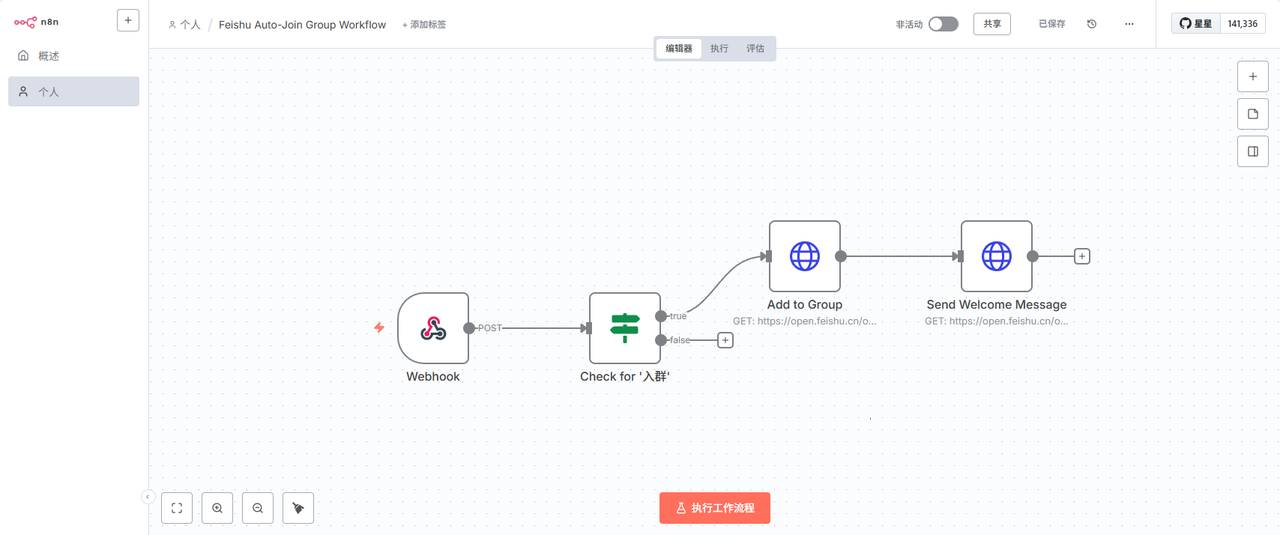
✅ 第二关:市场活动数据清洗
-
做运营的都懂,从各种渠道收集上来的用户信息,格式乱七八糟,处理起来头疼。
-
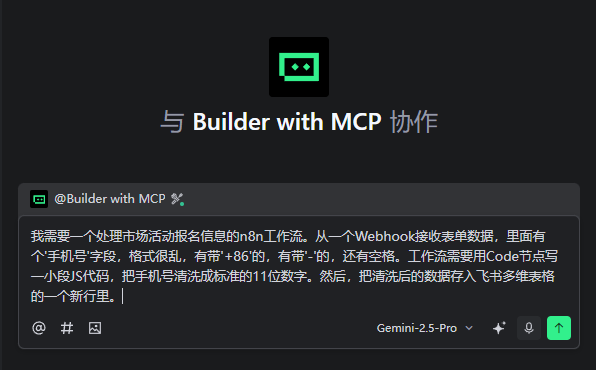
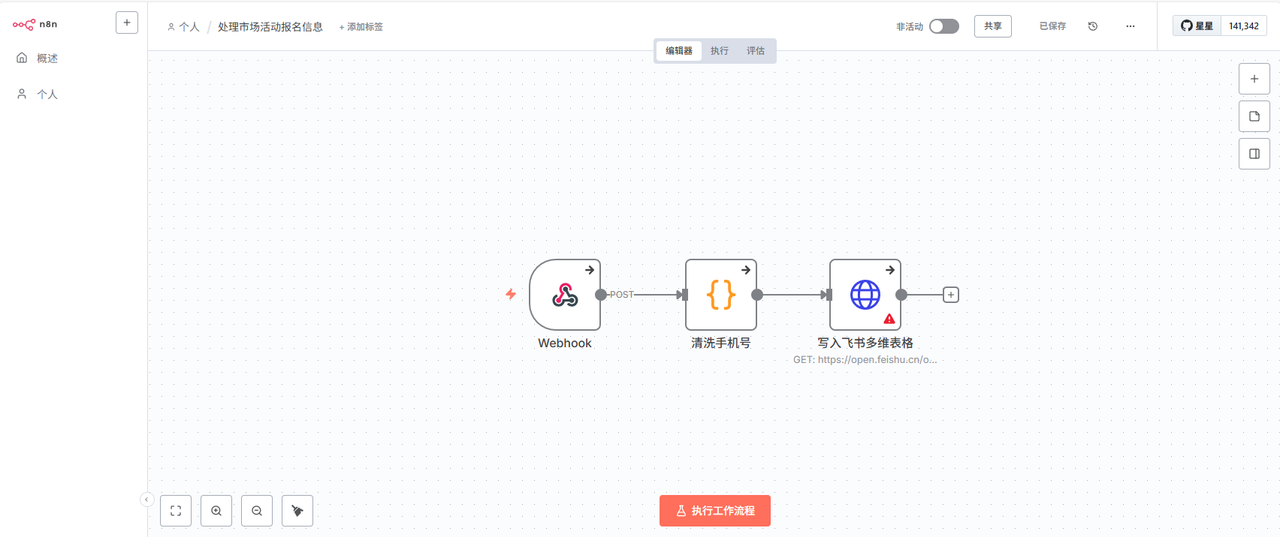
我的指令: “我需要一个处理市场活动报名信息的n8n工作流。从一个Webhook接收表单数据,里面有个'手机号'字段,格式很乱,有带'+86'的,有带'-'的,还有空格。工作流需要用Code节点写一小段JS代码,把手机号清洗成标准的11位数字。然后,把清洗后的数据存入飞书多维表格的一个新行里。”
-
结果: 这次让我有点惊喜。它不仅把Webhook和飞书多维表格的节点放好了,中间还真的给我加了一个Code节点,并且里面已经写好了一个基础的、用于替换特殊字符的JS脚本框架。 虽然脚本不一定100%完美,但它理解了“需要用代码处理数据”这个核心,这已经能节省我不少查资料的时间了。
✅ 第三关:销售线索智能分发
-
这是一个相对完整的业务闭环,考验它连接多个系统和执行复杂逻辑的能力。
-
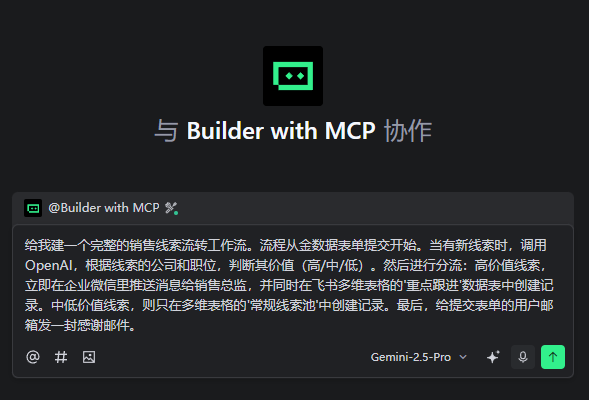
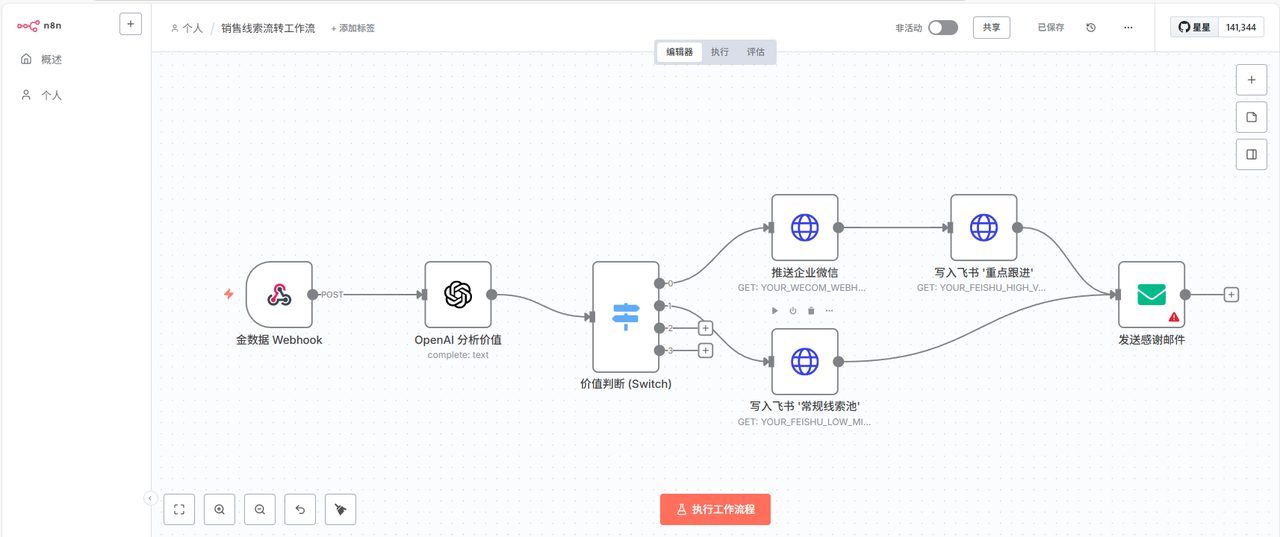
我的指令: “给我建一个完整的销售线索流转工作流。流程从金数据表单提交开始。当有新线索时,调用OpenAI,根据线索的公司和职位,判断其价值(高/中/低)。然后进行分流:高价值线索,立即在企业微信里推送消息给销售总监,并同时在飞书多维表格的'重点跟进'数据表中创建记录。中低价值线索,则只在多维表格的'常规线索池'中创建记录。最后,给提交表单的用户邮箱发一封感谢邮件。”
-
结果: 这次生成的工作流明显复杂多了。金数据触发器、OpenAI、IF条件判断、企业微信、两个不同的飞书多维表格节点、邮件节点,全都安排上了。最关键的IF分支逻辑也搭对了。主干流程的完成度我估摸着有个七八成,但各个节点之间的参数传递、数据引用还需要我手动进去精修。 不过,即便如此,它也已经把最耗费时间的“搭架子”工作给干完了。
05|刨根问底:这玩意儿到底是怎么做到的?
作为开发者,我光知道它好用还不行,还得弄明白它底层的原理。它之所以比简单的“投喂文档”要聪明得多,核心在于它的“智能工具集”。
✅ 高效的get_node_essentials工具
这点是我觉得最牛的设计。对于一个复杂的节点,比如HTTP Request,可能有上百个参数,一股脑全丢给AI,AI也得懵。
n8n-mcp有个核心工具叫get_node_essentials(获取节点精华),它不会这么干。它会智能地从这上百个参数里,只挑出10-20个最核心、最常用的返回给AI。官方说这一下就减少了95%的无关信息干扰,让AI可以更专注于核心配置,大大提高了生成工作流的准确性。
✅ 预构建的本地数据库,快得飞起
所有解析好的信息,会被整合成一个轻量级的SQLite数据库文件(大约15MB)。当你运行 n8n-mcp 时,你下载的包里就已经包含了这个数据库。
所以,当AI Agent向它查询信息时,它实际上只是在本地查询这个现成的数据库,完全不依赖网络,响应速度极快,平均也就十几毫秒。
06|安全第一:几句掏心窝子的话
在你兴冲冲地准备让你公司的生产环境也用上这玩意儿之前,我得凭着一个一线实践者的良心,多说几句。
✅ 切记!永远不要让AI直接编辑你的生产工作流!
-
这东西是“辅助”,是“副驾驶”,而不是“代驾”。AI可能会犯错,可能会误解,可能会因为一个参数没配对就搞出大问题。
-
正确的做法是:
-
复制一份工作流到你的开发或测试环境。
-
让AI在这个副本上进行操作和修改。
-
你自己,作为一个有经验的人,必须亲自审查、验证AI做的每一处修改。
-
测试跑通,确认无误后,再手动部署到你的生产环境。
-
这套流程,一步都不能省。不然出了问题,锅还得是咱自己背,对吧。
写在最后:有了锤子,更要懂如何盖房子
折腾完这一切,我长出了一口气。我们n8n进阶系列重启的“第0课”算是完成了。通过 n8n-mcp 这个强大的工具,希望能先把大家从搭建复杂流程的重复劳动中解放出来,让工具回归其“提升效率”的本质。
但每当一个强大的工具诞生时,我总会思考另一个问题:工具越是锋利,我们越应该反思,打算用它来创造什么?
n8n-mcp 就像一台高效的“制砖机”,它能帮你源源不断地造出标准、可靠的“自动化模块”。但这并不意味着,我们自动成为了一位优秀的“建筑师”。
真正拉开差距的,永远是如何将一块块独立的砖,设计、搭建成一座宏伟而坚固的大厦。如何让你构建的每一个独立的自动化流程,不再是零散的“点”,而是能够相互连接、彼此协同,最终服务于一个更大目标的“系统”。
从关注“术”的实现,到思考“道”的架构,这或许才是“进阶”二字真正的含义。当你的工具足够好用时,请把更多的精力,留给蓝图的设计。
感谢您的阅读,我们下次再见👋!
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)