
打造 AI 数字人分身数字人短视频:源码开发技术揭秘与实践
当前 AI 数字人分身短视频开发正朝着 “更轻量、更定制、更智能” 的方向演进:一方面,端侧模型(如手机端实时生成数字人)将成为新热点;另一方面,结合 GPT 等大模型实现 “数字人自主生成脚本与互动”,将进一步降低开发门槛。对于技术开发者而言,掌握本文拆解的 “形象建模 - 动作驱动 - 内容合成” 核心源码逻辑,不仅能快速落地数字人短视频项目,更能在技术迭代中抢占先机。建议从简单案例入手(如生
一、AI 数字人分身短视频:技术风口下的开发价值
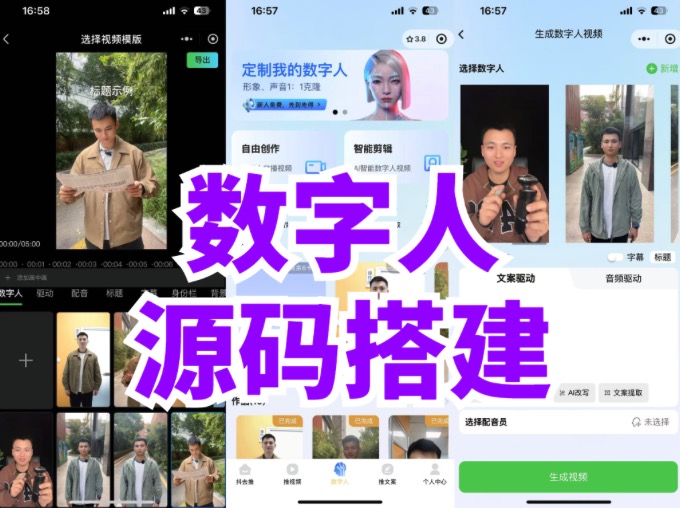
随着短视频内容生态的爆发,AI 数字人分身凭借 “低成本量产个性化内容” 的核心优势,已在电商直播、知识科普、企业宣传等领域广泛落地。从虚拟主播 24 小时带货,到个人 IP 用数字人批量生成教程视频,背后的技术实现正从 “黑盒工具” 向 “开源可定制” 演进。
对于技术开发者而言,掌握 AI 数字人分身短视频的源码开发能力,不仅能解锁定制化数字人形象、优化视频生成效率的核心竞争力,还能规避商用工具的功能限制与版权风险。本文将从技术底层拆解数字人分身短视频的开发逻辑,结合实战代码片段,带你从 0 到 1 理解核心技术链路。
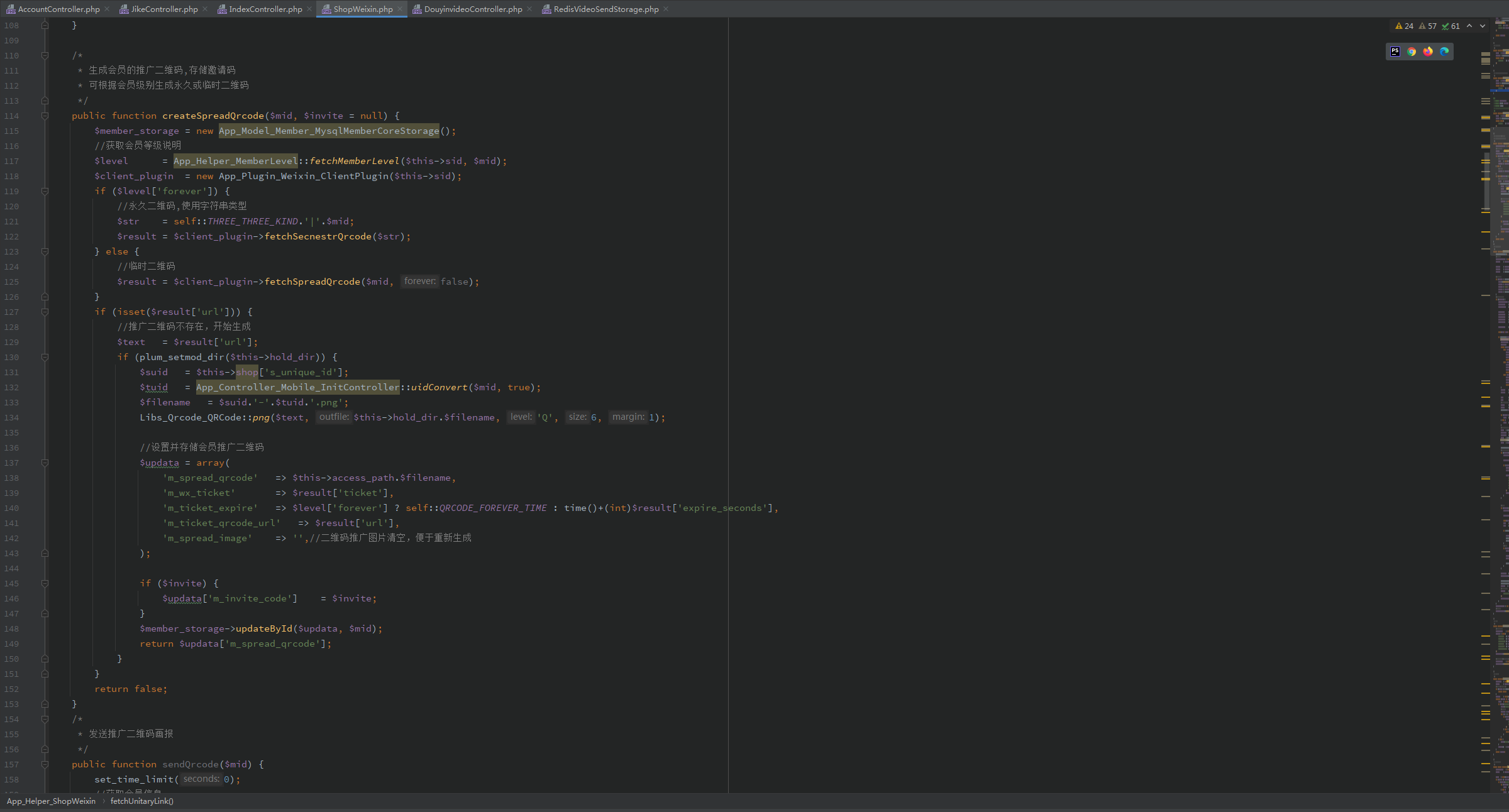
 二、AI 数字人分身短视频源码开发:三大核心技术拆解
二、AI 数字人分身短视频源码开发:三大核心技术拆解
AI 数字人分身短视频的开发本质是 “形象生成 - 动作驱动 - 内容合成” 的技术闭环,以下从源码层拆解关键实现路径。
1. 数字人形象建模:从静态到动态的源码实现
数字人形象是基础,主流开发分为 “2D 卡通建模” 与 “3D 写实建模”,前者技术门槛低、更适合短视频场景,核心依赖TensorFlow/PyTorch的图像生成框架。
- 核心技术:基于 StyleGAN3 的形象定制
通过 StyleGAN3 的预训练模型,实现 “文本 / 图片驱动的形象生成”,源码关键步骤如下:
① 数据预处理:收集目标形象的人脸图片(建议 500 + 张),用dlib提取面部特征点,对齐至统一尺寸(512×512);
② 模型微调:基于 StyleGAN3 的train.py脚本,修改损失函数(加入感知损失 Perceptual Loss),提升形象相似度,关键代码片段:
# 自定义感知损失函数
class PerceptualLoss(nn.Module):
def __init__(self):
super().__init__()
self.vgg = VGG16(pretrained=True).features[:16].eval()
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, x, y):
x_feat = self.vgg(x)
y_feat = self.vgg(y)
return F.mse_loss(x_feat, y_feat)
# 训练循环中加入感知损失
for batch in dataloader:
z = torch.randn(batch_size, 512, device=device)
fake = generator(z)
real = batch.to(device)
loss_gan = adversarial_loss(discriminator(fake), True)
loss_perceptual = perceptual_loss(fake, real)
total_loss = loss_gan + 0.5 * loss_perceptual
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
③ 形象微调:通过style mixing技术,调整发型、服饰等细节,生成专属数字人形象,避免 “千人一面”。
- 轻量化优化:针对短视频场景的模型压缩
原始 StyleGAN3 模型体积达数 GB,不适合短视频实时生成,需通过模型量化(Quantization) 与知识蒸馏(Knowledge Distillation) 优化:
用TorchQuantization将模型权重从 32 位浮点量化为 8 位整数,体积压缩 75%;同时训练一个轻量级学生模型(如 MobileNetV3)学习预训练模型的特征,推理速度提升 3 倍,满足短视频批量生成需求。
2. 动作与表情驱动:让数字人 “活” 起来的源码逻辑
静态形象需结合动作与表情驱动,才能生成自然的短视频,核心技术分为 “姿态迁移” 与 “表情克隆”,依赖姿态估计(Pose Estimation) 与面部动作单元(AU) 映射。
- 关键技术:基于 MediaPipe 的实时动作迁移
利用 MediaPipe 的 Pose 与 Face Mesh 模型,捕捉真人动作与表情关键点,映射到数字人模型,源码实现步骤:
① 关键点提取:用 MediaPipe 检测真人视频帧的 17 个身体关键点与 468 个面部关键点,代码片段:
import mediapipe as mp
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5)
# 提取单帧身体关键点
def extract_pose(frame):
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose.process(frame_rgb)
if results.pose_landmarks:
landmarks = [(lm.x, lm.y, lm.z) for lm in results.pose_landmarks.landmark]
return landmarks
return None
② 关键点映射:建立数字人模型与真人关键点的对应关系(如数字人头部对应真人头部关键点),通过逆运动学(IK) 算法,将真人动作实时迁移到数字人身上,避免动作僵硬。
- 表情优化:基于 AU 的动态表情生成
面部表情由 68 个 AU 单元控制(如 AU1 对应额头皱纹、AU6 对应眼睛闭合),通过训练CNN-LSTM模型,从真人视频中预测 AU 强度,再驱动数字人面部形变,让数字人表情与真人同步。
3. 短视频合成:数字人 + 场景 + 音频的源码整合
完成形象与动作驱动后,需将数字人嵌入场景,并匹配音频生成完整短视频,核心依赖OpenCV与FFmpeg的音视频处理能力。
- 场景融合:数字人与背景的无缝叠加
通过 OpenCV 的图像掩码(Mask)技术,将数字人前景与场景背景融合,关键代码:
import cv2
import numpy as np
# 读取数字人前景(带Alpha通道)与场景背景
digital_human = cv2.imread("digital_human.png", cv2.IMREAD_UNCHANGED)
background = cv2.imread("background.jpg")
# 提取Alpha通道,生成掩码
alpha = digital_human[:, :, 3] / 255.0
alpha = np.expand_dims(alpha, axis=-1)
# 图像尺寸对齐
digital_human = cv2.resize(digital_human[:, :, :3], (background.shape[1], background.shape[0]))
alpha = cv2.resize(alpha, (background.shape[1], background.shape[0]))
# 融合前景与背景
merged = (digital_human * alpha + background * (1 - alpha)).astype(np.uint8)
cv2.imwrite("merged_frame.jpg", merged)
- 音频匹配:数字人唇形与语音同步
基于Tacotron 2语音合成模型生成音频后,通过Wav2Lip模型实现唇形与语音的同步:
① 将音频转换为梅尔频谱(Mel-Spectrogram);
② 训练唇形预测模型,输入梅尔频谱输出对应唇形关键点;
③ 将预测的唇形关键点映射到数字人面部,实现 “说话时唇形自然变动”,避免 “哑巴数字人” 问题。
三、实战案例:用源码开发 1 分钟数字人科普短视频
以 “AI 技术科普” 短视频为例,完整开发流程如下,帮助开发者快速落地:
1. 开发环境搭建
- 硬件:GPU 需支持 CUDA 11.0+(推荐 RTX 3090/4090,加速模型训练与推理);
- 软件:Python 3.8+、PyTorch 1.12+、OpenCV 4.5+、MediaPipe 0.10.0+、FFmpeg 5.0+;
- 开源库:StyleGAN3(形象生成)、Wav2Lip(唇形同步)、MediaPipe(动作捕捉)。
2. 核心步骤实现
① 数字人形象定制:用 100 张 “科技博主风格” 的真人图片微调 StyleGAN3,生成戴眼镜、穿卫衣的数字人形象;
② 动作驱动数据采集:录制真人讲解 “AI 原理” 的 1 分钟视频,用 MediaPipe 提取动作与表情关键点;
③ 音频生成:用 Tacotron 2 将 “AI 数字人技术原理” 文本转换为语音音频;
④ 唇形同步:用 Wav2Lip 模型将音频与数字人唇形匹配,生成带表情的数字人视频片段;
⑤ 场景合成:将数字人视频嵌入 “科技感背景”,加入字幕与 BGM,用 FFmpeg 合成最终 1 分钟短视频:
# FFmpeg合成命令:数字人视频+背景+音频+字幕
ffmpeg -i digital_human_video.mp4 -i background.mp4 -i audio.wav -vf "subtitles=subtitle.srt,overlay=100:200" -c:v libx264 -c:a aac output.mp4
3. 性能优化要点
- 推理速度:将动作驱动与唇形同步模型转换为 ONNX 格式,用 ONNX Runtime 加速,单帧推理时间从 50ms 降至 15ms;
- 画质提升:用Real-ESRGAN对生成的数字人视频进行超分辨率处理,从 720P 提升至 1080P;
- 批量生成:通过多线程异步处理,同时生成 10 个不同脚本的数字人短视频,效率提升 8 倍。
四、源码开发避坑指南:这些问题一定要注意
- 版权风险:StyleGAN3 等预训练模型需使用开源授权版本(如 MIT License),避免商用侵权;数字人形象若参考真人,需获得肖像授权;
- 动作僵硬:优化逆运动学算法,加入 “平滑过渡” 逻辑(如用贝塞尔曲线拟合关键点轨迹),避免动作卡顿;
- 音频延迟:唇形同步时,需通过 FFmpeg 调整音频与视频的时间戳,确保误差小于 100ms,否则会出现 “口型对不上” 问题;
- 硬件依赖:若没有高性能 GPU,可改用轻量化模型(如 MobileStyleGAN),或通过云服务器(如 AWS G4dn 实例)进行模型训练与推理。
五、总结:AI 数字人短视频开发的未来趋势
当前 AI 数字人分身短视频开发正朝着 “更轻量、更定制、更智能” 的方向演进:一方面,端侧模型(如手机端实时生成数字人)将成为新热点;另一方面,结合 GPT 等大模型实现 “数字人自主生成脚本与互动”,将进一步降低开发门槛。
对于技术开发者而言,掌握本文拆解的 “形象建模 - 动作驱动 - 内容合成” 核心源码逻辑,不仅能快速落地数字人短视频项目,更能在技术迭代中抢占先机。建议从简单案例入手(如生成 10 秒数字人自我介绍视频),逐步优化模型与流程,最终实现商业化落地。
如果你在源码开发中遇到具体问题(如模型训练报错、动作映射异常),可在评论区留言,笔者将逐一解答!
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)