
提示设计中用户数据保护的技术细节:提示工程架构师的拆解
在当今数字化时代,随着人工智能技术的飞速发展,提示设计在各类应用中扮演着越来越重要的角色。无论是智能语音助手、聊天机器人,还是各种基于机器学习的推荐系统,提示设计的优劣直接影响用户体验。然而,与此同时,用户数据的安全与隐私保护问题也日益凸显。想象一下,用户就像一个个小心翼翼地捧着自己珍贵宝藏(个人数据)的人,走进了一个充满各种神奇机器(AI应用)的大房间。这些机器需要用户提供一些宝藏(数据)作为“
提示设计中用户数据保护的技术细节:提示工程架构师的拆解
关键词:提示设计、用户数据保护、提示工程架构、加密技术、数据匿名化、访问控制
摘要:本文深入探讨在提示设计过程中,提示工程架构师如何拆解并落实用户数据保护的技术细节。通过生动易懂的比喻,阐述关键技术概念,以清晰的逻辑解析技术原理与实现方式。同时,结合实际应用案例,说明保护用户数据在提示设计中的重要性及有效策略。还对未来技术发展趋势进行展望,为相关从业者和对该领域感兴趣的读者提供全面且有价值的技术知识,助力更好地平衡提示设计的功能与用户数据安全之间的关系。
一、背景介绍
(一)主题背景和重要性
在当今数字化时代,随着人工智能技术的飞速发展,提示设计在各类应用中扮演着越来越重要的角色。无论是智能语音助手、聊天机器人,还是各种基于机器学习的推荐系统,提示设计的优劣直接影响用户体验。然而,与此同时,用户数据的安全与隐私保护问题也日益凸显。
想象一下,用户就像一个个小心翼翼地捧着自己珍贵宝藏(个人数据)的人,走进了一个充满各种神奇机器(AI应用)的大房间。这些机器需要用户提供一些宝藏(数据)作为“燃料”,才能为用户提供神奇的服务(如精准的推荐、智能的对话)。但如果这些机器不能妥善保管用户的宝藏,一旦宝藏丢失或被坏人偷走,用户就会遭受巨大损失。同样,在提示设计中,如果不能有效保护用户数据,用户的隐私可能会被泄露,导致垃圾邮件骚扰、身份被盗用等严重后果。因此,确保提示设计中的用户数据安全,不仅关乎用户的切身利益,也是维持用户对AI应用信任的关键所在。
(二)目标读者
本文主要面向提示工程架构师、AI开发人员以及对AI技术中数据安全与隐私保护感兴趣的技术爱好者。无论你是刚刚踏入这个领域,对用户数据保护仅有模糊概念的新手,还是已经有一定经验,希望深入了解相关技术细节的从业者,都能从本文中获取有价值的信息。
(三)核心问题或挑战
- 数据收集阶段:如何在收集用户数据用于提示设计时,确保用户明确知晓数据的用途,并且收集过程合法合规,不侵犯用户隐私?这就好比在向用户借东西时,要清楚地告诉用户借这个东西用来做什么,而且借的方式要符合大家都认可的规则。
- 数据存储阶段:海量的用户数据在存储过程中,如何防止被非法访问和窃取?想象一下这些数据就像存放在仓库里的珍贵货物,仓库必须有坚固的门锁和严密的安保措施,才能保证货物的安全。
- 数据使用阶段:在利用用户数据进行提示优化时,如何在保证提示效果的同时,不泄露用户敏感信息?这就如同厨师在做菜时,既要用到各种食材(用户数据)做出美味的菜肴(优质提示),又不能让别人通过菜肴就猜出食材的具体来源。
- 数据共享与传输阶段:当与第三方合作或者在不同系统组件间传输数据时,如何保证数据的安全性和隐私性?这就像是把重要文件从一个地方寄到另一个地方,要确保文件在运输过程中不被偷看、篡改。
二、核心概念解析
(一)使用生活化比喻解释关键概念
- 加密技术:加密就像是给用户数据穿上了一层密不透风的“铠甲”。假设用户数据是一封信件,加密技术就是把这封信放进一个特制的盒子里,只有用特定的钥匙(解密密钥)才能打开这个盒子,看到信件的内容。即使信件在传输过程中或者存储时被别人拿到了,没有钥匙,他们也无法知道信件里写了什么。
- 数据匿名化:可以把数据匿名化想象成给用户数据戴上了一副“面具”。比如,我们有一份用户信息表,上面有用户的姓名、年龄、地址等信息。通过数据匿名化,我们把姓名替换成一个随机的编号,年龄范围化(如20 - 30岁),地址模糊化(只保留城市名称)。这样,即使数据泄露了,别人也很难通过这些“戴了面具”的数据识别出具体的用户是谁。
- 访问控制:访问控制就像是大楼的门禁系统。大楼里存放着很多重要的东西(用户数据),只有持有相应门禁卡(权限)的人才能进入相应的楼层(访问特定数据)。不同的人有不同的门禁卡权限,比如保洁人员只能进入公共区域打扫卫生,而公司高层管理人员才能进入机密会议室查看重要文件。同样,在数据系统中,不同的用户或程序对用户数据有不同的访问权限,以此来保护数据的安全。
(二)概念间的关系和相互作用
加密技术主要用于确保数据在传输和存储过程中的保密性,让即使被窃取的数据也无法被理解。数据匿名化则侧重于在数据使用和共享阶段,通过改变数据的可识别性来保护用户隐私。访问控制则是从源头把控,决定谁能够访问哪些数据,限制非法访问。
这三者相互配合,如同一个紧密协作的团队。访问控制就像是团队的“守门员”,先拦住那些没有权限的人;数据匿名化是“伪装者”,对数据进行处理,降低其敏感性;加密技术则是“护盾”,在数据流转的各个环节提供保护。例如,当一份用户数据需要从服务器A传输到服务器B时,首先通过访问控制确定发起传输的程序有权限进行操作,然后对数据进行加密,在服务器B接收后,即使数据在传输过程中被截获,由于加密的存在,攻击者无法读取内容。而在服务器B对数据进行分析使用时,数据匿名化可以进一步降低因分析而导致用户隐私泄露的风险。
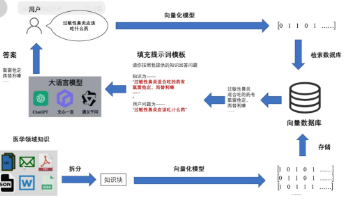
(三)文本示意图和流程图(Mermaid格式)
这个流程图展示了用户数据从收集到使用、共享与传输的整个过程,以及加密、数据匿名化和访问控制在各个环节的作用。
三、技术原理与实现
(一)算法或系统工作原理
- 加密技术原理:常见的加密算法有对称加密和非对称加密。
- 对称加密:对称加密就像是两个人共用一把钥匙来锁和开锁。发送方使用这把钥匙对数据进行加密,接收方使用相同的钥匙进行解密。例如,在古代,两个秘密通信的人会事先约定一个替换规则(相当于钥匙),比如把字母A替换成D,B替换成E,以此类推。发送方按照这个规则对信件内容进行替换加密后送出,接收方收到后按照相同规则还原信件内容。在现代计算机领域,AES(高级加密标准)就是一种常用的对称加密算法。
- 非对称加密:非对称加密则像是一把锁有两把钥匙,一把公钥用来锁,一把私钥用来开。公钥可以公开给任何人,就像你家门的锁芯可以给很多人看,大家都能用这个锁芯对应的钥匙(公钥)把东西锁进箱子里。但是只有拥有私钥的人才能打开箱子。比如,在网络通信中,客户端向服务器请求数据,服务器会把自己的公钥发送给客户端,客户端用公钥对请求数据加密后发送给服务器,服务器再用自己的私钥解密。RSA算法就是一种经典的非对称加密算法。
- 数据匿名化原理:数据匿名化主要通过数据泛化、抑制和置换等方法实现。
- 数据泛化:例如,对于用户的出生日期,我们可以把具体日期泛化为年份或者年份范围,如“1990 - 1995年”。这样虽然丢失了一些精确信息,但可以有效保护用户的隐私。
- 抑制:对于一些非常敏感的信息,如身份证号码、信用卡号等,可以直接删除或者用特殊符号替代,如用“******”代替信用卡号后几位。
- 置换:将数据中的某些值用其他值替换,比如把用户的真实姓名替换成随机生成的假名。
- 访问控制原理:访问控制基于主体(用户、程序等)、客体(数据资源)和权限的关系。系统会维护一个访问控制列表(ACL),记录着哪些主体对哪些客体有什么样的访问权限。例如,在一个数据库系统中,数据库管理员(主体)对整个数据库(客体)有完全控制权限,而普通用户(主体)可能只能对某些特定表(客体)有查询权限。
(二)代码实现(使用Python语言示例)
- 加密示例(使用PyCryptodome库实现AES对称加密):
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
import os
# 生成一个16字节的密钥(实际应用中应妥善保存密钥)
key = os.urandom(16)
cipher = AES.new(key, AES.MODE_CBC)
# 要加密的数据
data = b"Hello, this is user data"
padded_data = pad(data, AES.block_size)
# 加密数据
encrypted_data = cipher.encrypt(padded_data)
# 解密数据
decipher = AES.new(key, AES.MODE_CBC, iv=cipher.iv)
decrypted_data = unpad(decipher.decrypt(encrypted_data), AES.block_size)
print("Original data:", data)
print("Encrypted data:", encrypted_data.hex())
print("Decrypted data:", decrypted_data)
- 数据匿名化示例(对姓名进行匿名化处理):
import hashlib
def anonymize_name(name):
# 使用哈希函数对姓名进行处理,得到一个固定长度的哈希值,作为匿名化后的标识
hash_object = hashlib.sha256(name.encode())
anonymized_name = hash_object.hexdigest()
return anonymized_name
name = "John Doe"
anonymized_name = anonymize_name(name)
print("Original name:", name)
print("Anonymized name:", anonymized_name)
- 访问控制示例(简单模拟基于角色的访问控制):
class User:
def __init__(self, role):
self.role = role
class DataResource:
def __init__(self, access_rules):
self.access_rules = access_rules
def check_access(self, user):
if user.role in self.access_rules:
return True
return False
# 定义访问规则,例如管理员角色有访问权限,普通用户没有
access_rules = {'admin': True, 'user': False}
data_resource = DataResource(access_rules)
admin_user = User('admin')
regular_user = User('user')
print("Admin can access:", data_resource.check_access(admin_user))
print("Regular user can access:", data_resource.check_access(regular_user))
(三)数学模型解释(使用LaTeX格式)
- 对称加密的数学模型:设明文为PPP,密钥为KKK,加密函数为EEE,解密函数为DDD。则加密过程可表示为C=E(K,P)C = E(K, P)C=E(K,P),其中CCC为密文。解密过程为P=D(K,C)P = D(K, C)P=D(K,C)。在AES算法中,其核心是通过一系列的轮变换对明文进行处理,每一轮变换包括字节替换、行移位、列混淆和密钥加等操作。这些操作基于有限域上的数学运算,如伽罗瓦域(GF(28)GF(2^8)GF(28))上的乘法和加法运算。
- 非对称加密(以RSA为例)的数学模型:RSA算法基于大整数分解的困难性。首先选择两个大质数ppp和qqq,计算n=p×qn = p \times qn=p×q。然后计算欧拉函数φ(n)=(p−1)(q−1)\varphi(n) = (p - 1)(q - 1)φ(n)=(p−1)(q−1)。选择一个整数eee,使得1<e<φ(n)1 < e < \varphi(n)1<e<φ(n)且gcd(e,φ(n))=1gcd(e, \varphi(n)) = 1gcd(e,φ(n))=1,eee作为公钥。再计算私钥ddd,使得ed≡1(modφ(n))ed \equiv 1 \pmod{\varphi(n)}ed≡1(modφ(n))。加密时,明文mmm(0≤m<n0 \leq m < n0≤m<n),密文c=me(modn)c = m^e \pmod{n}c=me(modn)。解密时,m=cd(modn)m = c^d \pmod{n}m=cd(modn)。
- 数据匿名化中的泛化模型:以数值数据泛化为例,假设原始数据为xxx,其取值范围为[a,b][a, b][a,b]。我们要将其泛化为[A,B][A, B][A,B]范围。可以定义一个泛化函数f(x)f(x)f(x),使得f(x)f(x)f(x)将xxx映射到[A,B][A, B][A,B]内。例如,线性泛化函数f(x)=(x−a)(b−a)(B−A)+Af(x)=\frac{(x - a)}{(b - a)}(B - A)+Af(x)=(b−a)(x−a)(B−A)+A。
四、实际应用
(一)案例分析
- 聊天机器人中的应用:假设我们开发一个智能聊天机器人,用于客服服务。在与用户交互过程中,会收集用户的问题、相关订单信息等数据,用于优化提示回复。
- 数据收集:在聊天界面明确告知用户数据将被收集用于改善服务,并获得用户同意。
- 数据存储:将收集到的数据进行加密存储。例如,使用AES加密算法对用户订单信息中的敏感部分(如支付金额、收货地址)进行加密后存储到数据库中。
- 数据使用:在分析用户问题以优化提示时,先对用户身份相关信息进行匿名化处理。比如,将用户姓名用哈希值替代。然后利用匿名化后的数据进行自然语言处理和机器学习模型训练,以生成更精准的提示回复。
- 数据共享与传输:如果聊天机器人与第三方知识库进行数据交互,在传输过程中对数据进行加密。例如,使用SSL/TLS协议进行加密传输,确保数据在传输过程中的安全性。
- 推荐系统中的应用:以音乐推荐系统为例,它会收集用户的听歌历史、收藏歌曲、搜索记录等数据,为用户提供个性化的音乐推荐提示。
- 数据收集:通过用户协议明确告知用户数据收集目的,并获得用户授权。
- 数据存储:采用分布式存储系统存储大量用户数据,同时对敏感数据(如用户的登录密码)进行加密存储。
- 数据使用:在分析用户听歌习惯时,对用户的地理位置信息进行匿名化处理,如只保留城市级别信息。然后运用机器学习算法对匿名化后的数据进行分析,构建用户画像,从而生成个性化推荐提示。
- 数据共享与传输:如果推荐系统与音乐版权方共享部分用户听歌趋势数据,在共享前对数据进行匿名化和加密处理,确保用户隐私不被泄露。
(二)实现步骤
- 聊天机器人实现步骤:
- 数据收集:在聊天界面添加提示框,显示数据收集声明,用户点击“同意”按钮后开始收集数据。
- 数据加密存储:在数据收集后,调用加密函数(如上述Python中的AES加密代码)对敏感数据进行加密,然后将加密后的数据存储到数据库中。
- 数据匿名化与使用:在从数据库读取数据进行分析时,先对用户身份相关信息进行匿名化处理(如使用哈希函数)。然后将匿名化后的数据输入到自然语言处理模型和机器学习模型中进行训练和优化,生成提示回复。
- 数据加密传输:当与第三方知识库交互时,使用SSL/TLS库对传输的数据进行加密,确保数据安全传输。
- 推荐系统实现步骤:
- 数据收集:在用户注册和使用过程中,弹出提示框告知用户数据收集目的,用户确认后开始收集数据。
- 数据加密存储:将收集到的数据进行分类,对敏感数据(如登录密码)使用加密算法进行加密,然后存储到分布式存储系统中。
- 数据匿名化与使用:在读取数据进行分析时,对地理位置等敏感信息进行匿名化处理(如使用数据泛化方法)。接着利用匿名化后的数据训练机器学习模型,生成个性化推荐提示。
- 数据匿名化与加密共享:在与音乐版权方共享数据前,对数据进行匿名化处理(如替换用户标识),然后使用加密算法对共享数据进行加密,确保数据安全共享。
(三)常见问题及解决方案
- 加密性能问题:加密和解密过程可能会消耗较多的计算资源,导致系统性能下降。
- 解决方案:可以采用硬件加速的方式,如使用支持加密加速的CPU或专用加密芯片。另外,根据数据的敏感性和使用频率,合理选择加密算法,对于一些非关键且频繁使用的数据,可以选择相对简单、计算量小的加密算法。
- 数据匿名化后可用性问题:过度的匿名化可能导致数据失去分析价值。
- 解决方案:在进行数据匿名化之前,先对数据进行分析,确定哪些信息是必须保留以保证数据可用性的。采用分层匿名化的方法,根据不同的应用场景和需求,对数据进行不同程度的匿名化处理。
- 访问控制误判问题:由于权限设置错误或者系统漏洞,可能导致访问控制出现误判,让没有权限的主体访问到数据。
- 解决方案:建立严格的权限管理流程,对权限设置进行定期审核和审计。采用多因素认证的方式,增加访问控制的安全性,如除了用户名和密码外,还使用短信验证码或者指纹识别等方式进行身份验证。
五、未来展望
(一)技术发展趋势
- 同态加密技术的发展:同态加密是一种新兴的加密技术,它允许在加密数据上进行计算,而无需先解密数据。这就好比在一个密封的盒子里对物品进行操作,操作完成后打开盒子,得到的结果就像直接对物品进行操作一样。例如,在数据分析场景中,可以直接对加密的用户数据进行统计分析,而无需解密数据,从而极大地提高数据的安全性。未来,同态加密技术有望在提示设计等领域得到更广泛的应用,进一步提升用户数据保护水平。
- 基于区块链的用户数据保护:区块链具有去中心化、不可篡改等特性。可以将用户数据以加密的形式存储在区块链上,通过智能合约来管理数据的访问和使用。这就像是把数据放在一个由众多节点共同守护的保险箱里,只有通过特定的智能合约规则才能打开保险箱获取数据。这种方式可以增强数据的透明度和安全性,减少数据被篡改和泄露的风险。在提示设计中,区块链技术可以用于记录数据的使用历史和权限变更,确保数据的使用符合用户的授权。
- 人工智能与数据保护的深度融合:未来,人工智能不仅会用于优化提示设计,还会在数据保护方面发挥更大作用。例如,利用人工智能算法自动检测数据中的敏感信息,实时监控数据访问行为,发现异常访问及时预警。同时,人工智能可以根据用户的行为模式和数据使用场景,动态调整加密和匿名化策略,实现更加智能化、个性化的数据保护。
(二)潜在挑战和机遇
- 挑战:
- 技术复杂性:新的技术如同比态加密、区块链等,其技术原理和实现都比较复杂,对提示工程架构师和开发人员的技术能力要求更高。在实际应用中,可能会面临技术选型、集成和维护等方面的困难。
- 标准和规范缺失:随着新技术的不断涌现,相关的数据保护标准和规范还不完善。这可能导致不同系统之间的数据保护措施不统一,增加数据共享和交互的难度。
- 用户意识和教育:即使有先进的数据保护技术,用户如果缺乏对数据安全和隐私的认识,随意泄露个人信息,也会降低数据保护的效果。因此,如何提高用户的安全意识,加强用户教育,是一个重要挑战。
- 机遇:
- 创新应用场景:新的技术为提示设计带来了更多创新的应用场景。例如,基于同态加密的数据分析可以实现更精准的个性化提示,同时保护用户隐私。这为企业提供了差异化竞争的机会,能够吸引更多注重隐私的用户。
- 市场需求增长:随着用户对数据隐私的关注度不断提高,对具备良好数据保护能力的提示设计应用的需求也在增长。企业如果能够在数据保护方面做得更好,将获得更大的市场份额和商业机会。
- 跨行业合作机会:为了解决数据保护的技术和标准问题,不同行业之间需要加强合作。这为提示工程架构师提供了更多与其他行业专家交流合作的机会,促进技术的融合和创新。
(三)行业影响
- 用户信任增强:随着数据保护技术的不断发展和完善,用户对AI应用的信任度将得到显著提高。用户更愿意使用那些能够有效保护其数据隐私的提示设计应用,从而推动整个行业的健康发展。
- 行业规范完善:新技术的应用将促使行业制定更加严格和完善的数据保护标准和规范。这将有助于规范市场秩序,淘汰那些数据保护措施不力的企业,提高整个行业的质量和竞争力。
- 业务模式创新:数据保护技术的创新将引发业务模式的变革。例如,基于区块链的数据共享模式可能会改变企业之间的数据合作方式,创造新的商业价值。
六、结尾部分
(一)总结要点
本文围绕提示设计中用户数据保护这一主题,首先阐述了其背景和重要性,明确了目标读者以及面临的核心问题。接着通过生动的比喻解析了加密技术、数据匿名化和访问控制等关键概念及其相互关系,并借助流程图直观展示了它们在用户数据处理流程中的作用。在技术原理与实现部分,详细介绍了相关技术的工作原理、代码实现示例以及数学模型解释。通过聊天机器人和推荐系统的案例分析,说明了在实际应用中的实现步骤和常见问题的解决方案。最后对未来技术发展趋势、潜在挑战和机遇以及行业影响进行了展望。
(二)思考问题(鼓励读者进一步探索)
- 在实际应用中,如何根据不同的提示设计场景,选择最合适的加密算法和数据匿名化方法?
- 随着人工智能与数据保护的深度融合,如何确保人工智能算法本身不会成为数据泄露的风险点?
- 面对日益复杂的网络环境和不断变化的攻击手段,如何构建一个动态、自适应的数据保护体系?
(三)参考资源
- 《密码编码学与网络安全:原理与实践》,作者:William Stallings,这本书详细介绍了各种加密算法的原理和应用。
- 《数据隐私工程:构建安全可靠的系统》,作者:Viktor Mayer - Schönberger等,书中探讨了数据隐私保护的工程实践方法。
- 相关技术文档和开源项目,如PyCryptodome库的官方文档(https://pycryptodome.readthedocs.io/en/latest/),为加密技术的实现提供了详细指导。
更多推荐
 7
7 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)