
第三方大模型API的使用
第三方大模型API调用
不管使用哪种大模型的 API,都可以用 OpenAI 封装好的接口。
在 anaconda 的沙箱环境的黑窗口输入命令: pip3 install openai
一、Deepseek
1.1 基本了解
深度求索(DeepSeek),总部在杭州,成立于2023年,专注于研究世界领先的通用人工智能底层模型与技术,挑战人工智能前沿性难题。
基于自研训练框架、自建智算集群和万卡算力等资源,深度求索团队仅用半年时间便已发布并开源多个百亿级参数大模型,如DeepSeek-LLM通用大语言模型、DeepSeek-Coder代码大模型。
并在2024年1月率先开源国内首个MoE大模型(DeepSeek-MoE),各大模型在公开评测榜单及真实样本外的泛化效果均有超越同级别模型的出色表现。
注意:deepseek在以远低于 OpenAI 的 o1 的成本,开发了 DeepSeek-R1 后获得了国际关注。DeepSeek V3–0324 是对前代 DeepSeek V3(于2023年12月24日发布) 的一次重要更新。
Deepseek 主要分为 V 系列版本 和 R 系列版本:
● V 系列版本:更多是通用场景的简单任务的实现,更加日常一些。
● R 系列版本:R 指的是 Reasoning 推理,回去推理分析用户的输入,适合深度分析的任务。
关键时间点:
- 2024 年 1 月,发布 Deepseek LLM
- 2025 年 1 月,发布 Deepseek-R1,爆火
- 2025 年 8 月,发布最新的 DeepSeek-V3.1 ,支持思考和非思考的混合推理模型。
1.2、初步 API 使用
第一步:进入 api 开发者平台
deepseek 的官网地址:https://www.deepseek.com
点击页面上的 API 开放平台可以进入对应的 api 使用网址。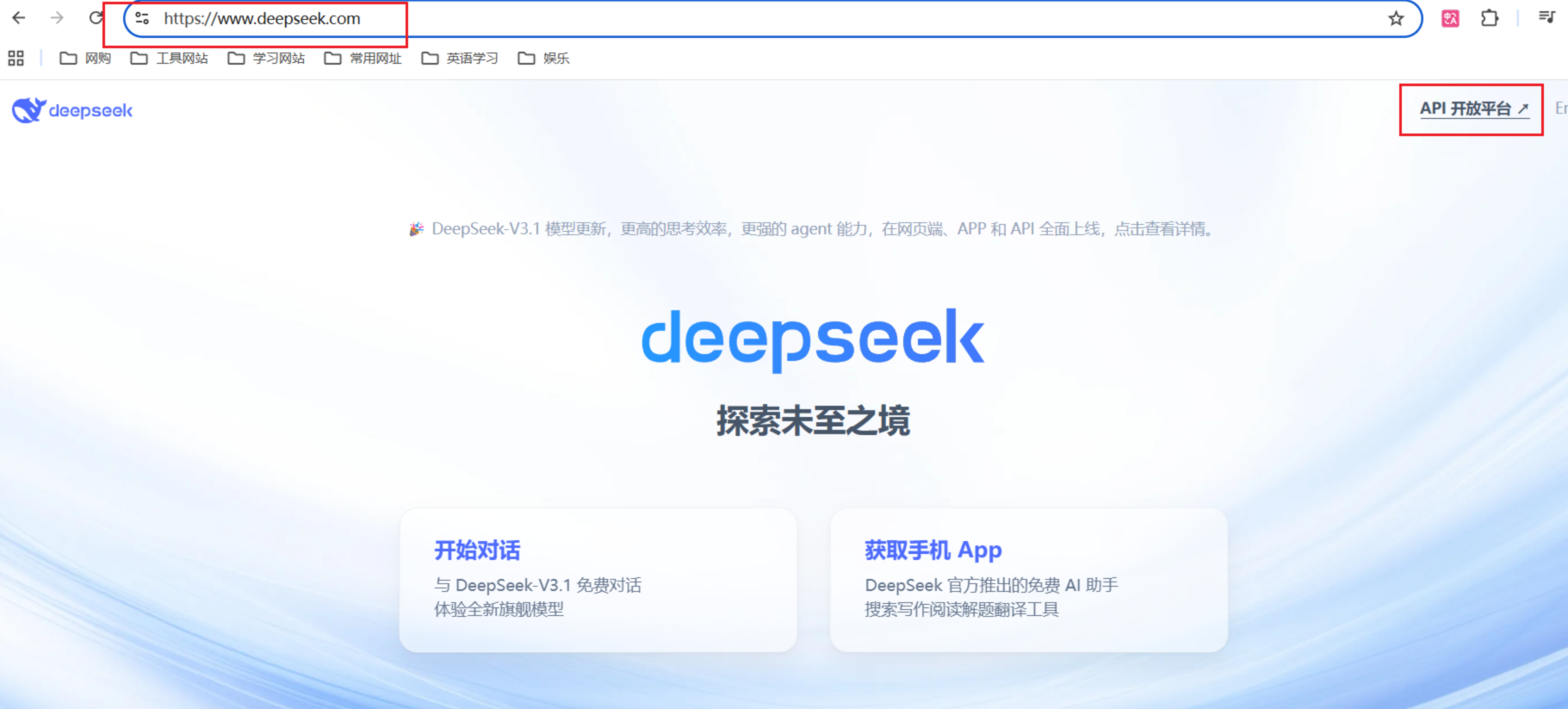
第二步:创建 api_key
进入 deepseek 的开放平台后点击 API keys 的导航栏。
点击创建 API key 的按钮,在弹窗中输入自定义的秘钥名词(英文)即可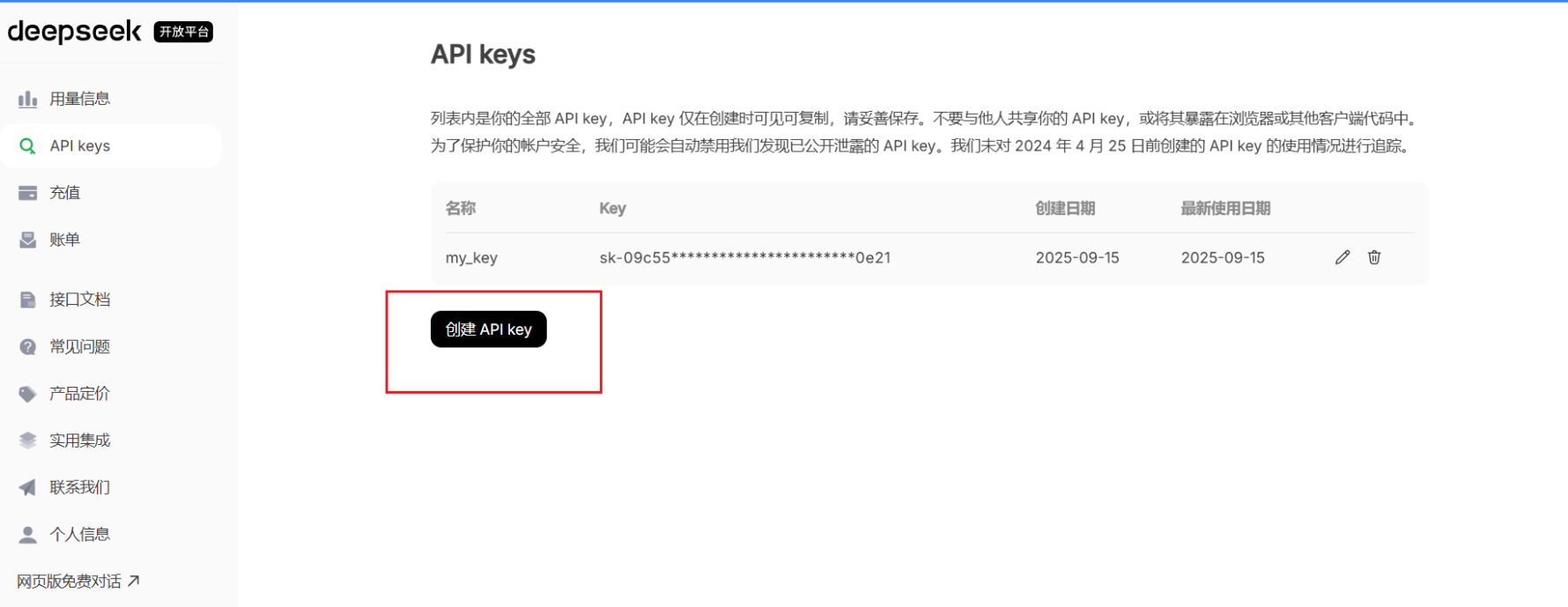
最后得到 API key,但是要注意,一定要复制出来,要不然后面是无法看到这个 key 的。
第三步:API
点击导航栏的’接口文档’,就会进入 DeepSeek API 文档页面: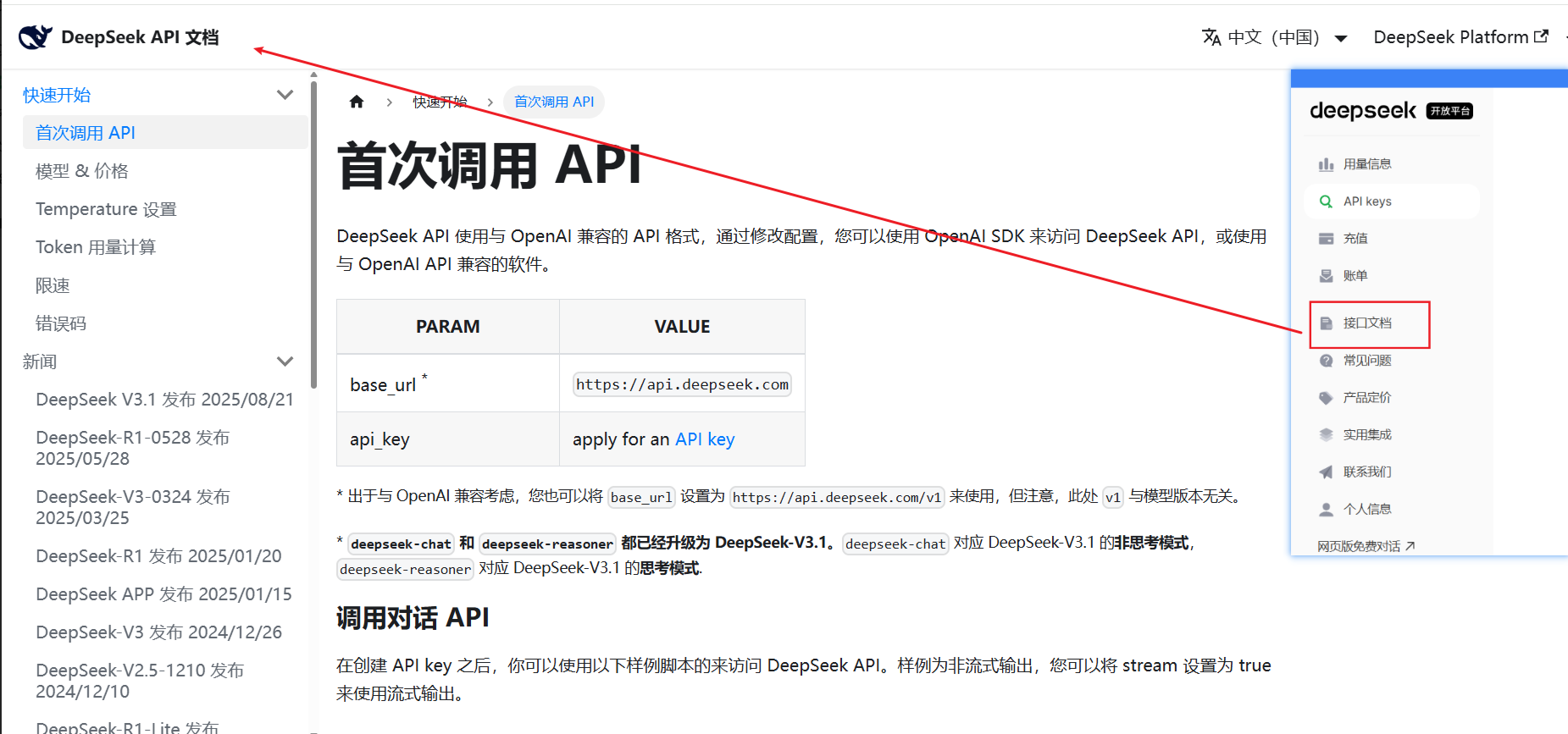
这里有一个简单的调用 API 的方式介绍,可以知道有
● 两个参数,base_url(api 对应的 url) , api_key(前面创建的秘钥)。
● 客户端对象请求时的入参
○ message 中的 role 消息的发送者角色
■ system 系统提示角色,用于预先设定模型的行为模式(如风格,身份,约束)
■ user 用户角色,代表用户的输入
■ assistant 助手角色,代表模型之前的回复内容,用于对轮对话中历史交互的记录
○ message 中的 content,对应角色发出的具体文本信息
○ 为什么 messages 要多个元素,本质是构建对话上下文
下面是 messages 的内容的推荐(其他部分除了 model 根据具体业务变动以外,其他基本不动):
# 第一种:系统设定+用户提问
messages = [
{"role": "system", "content": "用简洁的语言回答技术问题"}, # 系统设定
{"role": "user", "content": "什么是LLM?"} # 用户提问
]
# 第二种:系统设定 + 历史回复+当前问题
messages = [
{"role": "user", "content": "推荐一本Python入门书"}, # 历史问题
{"role": "assistant", "content": "《Python编程:从入门到实践》"}, # 历史回复
{"role": "user", "content": "这本书适合零基础吗?"} # 当前问题
]
常见的 model:
● deepseek-chat 通用对话模型
● deepseek-coder-base 基于代码模型,支持代码生成、补全、解释等基础任务
● deepseek-coder-pro 增强版黛米模型,对于算法实现、多语言转换等复杂逻辑任务
第四步:下载沙箱依赖
第三步使用的是 SDK (已经封装好的工具包)的方式,需要下载依赖。
在 anaconda 的沙箱环境的黑窗口输入命令: pip3 install openai
第五步:正式代码
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI # pip3 install openai
# 初始化api的客户端,后续发送api请求
# 秘钥,url
client = OpenAI(api_key="sk-xxxxx", base_url="https://api.deepseek.com")
# 构建并发送聊天请求
response = client.chat.completions.create(
model="deepseek-chat", # 模型名称
messages=[ # 聊天内容
{"role": "system", "content": "你是一个ai助手"}, # role是系统角色,content是角色内容
{"role": "user", "content": "给我讲一个关于笑话的笑话"},
],
stream=False # 是否流式返回结果,false 可以把结果拼接到一起了,默认true 是流式返回结果逐行打印
)
print(response.choices[0].message.content)
二、智普 - GLM(BigModel)
2.1 基本了解
网址:https://open.bigmodel.cn/
进入开发文档平台,可以看到支持多种调用以及 LangChain 集成。我们一般是使用 OpenAi 调用方式
创建 API Key 是(这个平台的是可以复制出来的,不用怕忘记了)
2.2 初步 API 使用
注意先下载 OpenAI 的依赖
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI # pip3 install openai
def GLM_method(): # 智普AI
# 创建智谱AI 客户端
client = OpenAI(
api_key="xxxx",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4.5",
messages=[
{"role": "system", "content": "你是一个聪明且富有创造力的小说作家"},
{"role": "user", "content": "请你作为童话故事大王,写一篇短篇童话故事"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message.content)
三、阿里云 通义千文
3.1 基本了解
通义千问是阿里云的核心 AI 模型能力底座,而百炼是承载该能力并向企业用户提供全流程服务的平台。
百炼官网:https://www.aliyun.com/product/bailian/getting-started
创建 API Key:(这个平台的 key 也是可以复制的)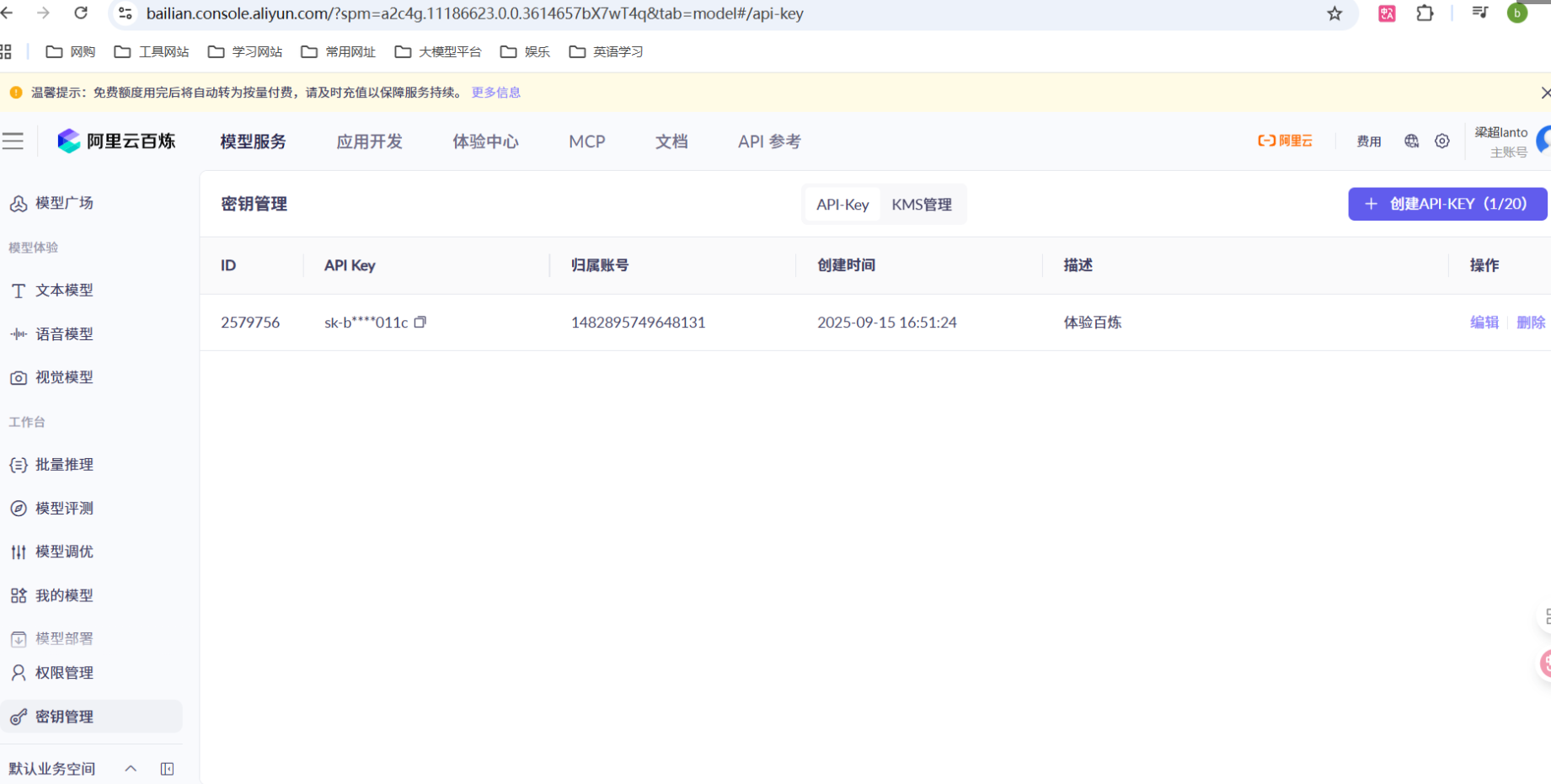
在模型广场选择要使用的模型,可以查看如何调用和免费 token 额度: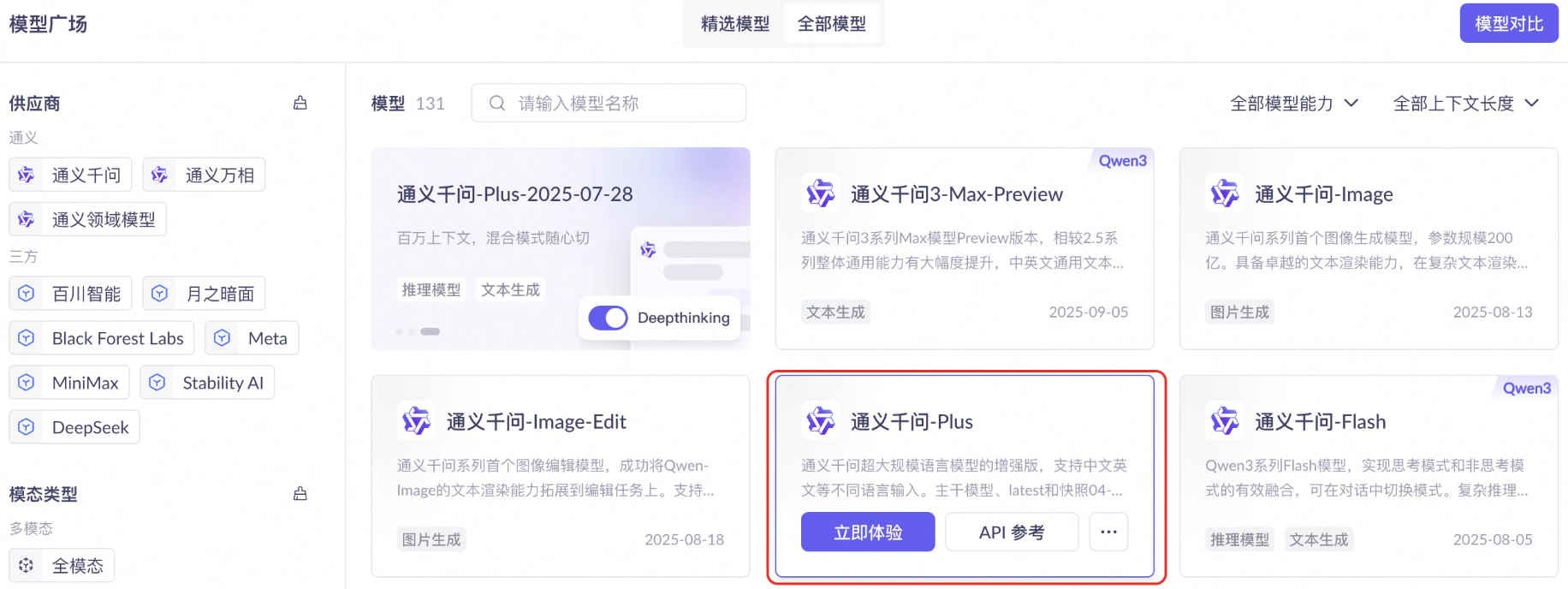
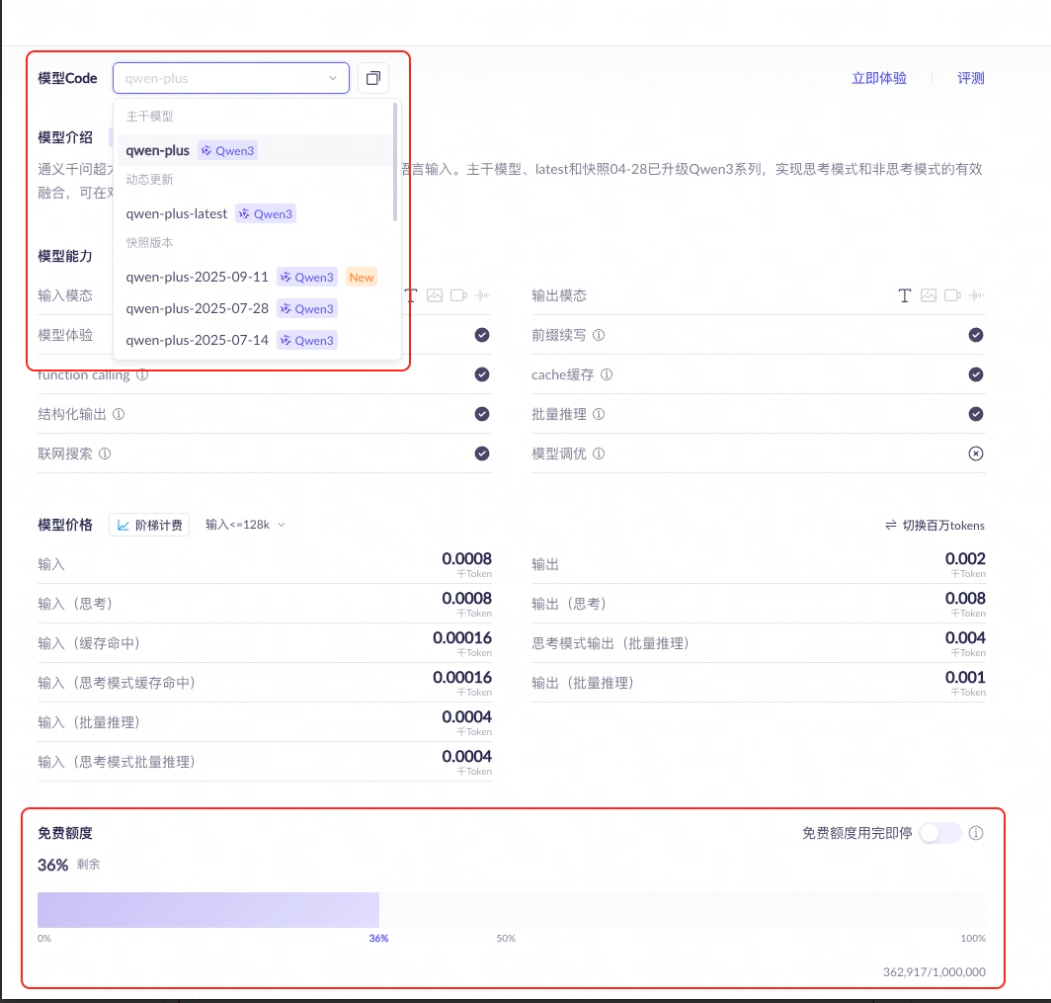
3.2 初步 API 使用
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI # pip3 install openai
def qwen_method():
client = OpenAI(
# 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx"
api_key="sk-xxxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
messages = [{"role": "user", "content": "你是谁"}]
completion = client.chat.completions.create(
model="qwen-plus", # 您可以按需更换为其它深度思考模型
messages=messages,
extra_body={"enable_thinking": True},
stream=True
)
is_answering = False # 是否进入回复阶段
print("\n" + "=" * 20 + "思考过程" + "=" * 20)
for chunk in completion:
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning_content") and delta.reasoning_content is not None:
if not is_answering:
print(delta.reasoning_content, end="", flush=True)
if hasattr(delta, "content") and delta.content:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20)
is_answering = True
print(delta.content, end="", flush=True)
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)