
零基础学AI大模型之大模型私有化部署全指南
摘要 本文系统介绍了AI大模型私有化部署的两种核心方式:源码部署(技术门槛高但灵活)和应用部署(低门槛快速上手)。重点分析了DeepSeek系列大模型从1.5B到671B不同参数规模的硬件配置要求、性能表现及适用场景,涵盖个人开发到企业级应用的完整选型建议。特别针对Ollama工具提供了详细实操指南,包括模型下载、参数配置等关键步骤,为技术团队提供从理论到实践的完整参考框架。
| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之AI大模型常见概念 |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
本文章目录
零基础学AI大模型之大模型私有化部署全指南:方式、硬件配置与Ollama实操
在大模型技术落地过程中,私有化部署因数据隐私保护、定制化需求适配、离线场景支持等优势,成为企业级应用的核心选择。作为“国运级”开源大模型,DeepSeek覆盖从1.5B到671B的全参数谱系,可满足个人开发、企业业务、科研攻关等不同场景需求。本文将系统梳理开源大模型私有化部署的常见方式,详解DeepSeek各参数模型的硬件配置与适用场景,并聚焦Ollama工具的实操落地,为技术团队提供从选型到部署的完整参考。
一、开源大模型私有化部署:2种核心方式对比
开源大模型的私有化部署无“统一方案”,需根据技术门槛、团队能力、场景需求选择。目前主流分为源码部署(灵活但复杂)和应用部署(低门槛快速上手)两类,具体差异如下:
1.1 源码部署:技术门槛高,灵活度拉满
源码部署是直接基于大模型开源代码(如GitHub仓库),通过依赖配置、环境搭建实现本地化运行,核心优势是支持深度定制(如修改模型结构、优化推理逻辑),但对工程师的技术栈要求较高。
主流工具与适用场景
| 部署工具 | 核心依赖 | 优势 | 适用场景 |
|---|---|---|---|
| Transformers | Python、PyTorch、CUDA | 生态完善,支持多模型格式 | 需定制模型输出、适配业务逻辑的场景 |
| vLLM | PyTorch、CUDA、C++ | 高吞吐量,推理速度比Transformers快5-10倍 | 高并发推理场景(如客服机器人、API服务) |
| llama.cpp | C/C++、OpenBLAS | 支持CPU推理,轻量无GPU依赖 | 无显卡环境、轻量化测试场景 |
关键特点
- 依赖复杂:需处理版本兼容性(如PyTorch与CUDA版本匹配、第三方库依赖冲突),类似“源码安装K8s”,适合有AI工程化经验的团队;
- 算力平台适配:通常需在Linux服务器或云算力平台(如阿里云PAI、AWS SageMaker)操作,本地PC部署难度较高;
- 定制化强:可集成业务数据微调、修改模型上下文窗口、优化量化精度(如INT4/INT8),满足个性化需求。
1.2 应用部署:低门槛快速落地,小白友好
应用部署基于封装好的工具链,无需关注底层源码,通过“下载-安装-启动”三步即可完成部署,核心目标是“降低使用门槛”,适合非资深AI工程师或快速验证场景。
主流工具与核心能力
| 部署工具 | 支持系统 | 核心优势 | 操作复杂度 |
|---|---|---|---|
| Ollama | Windows/Mac/Linux | 类Docker命令管理,支持OpenAI兼容API | ★☆☆☆☆ |
| LM Studio | Windows/Mac/Linux | 可视化界面,模型搜索/切换更直观 | ★★☆☆☆ |
关键特点
- 零环境配置:工具自动处理依赖(如GPU驱动、模型缓存),Mac用户甚至可直接用M1/M2芯片加速;
- 隐私安全:完全离线运行,数据不上传第三方服务器,适合处理医疗记录、金融数据等敏感信息;
- 轻量化管理:支持多模型并行运行(如同时启动DeepSeek-7B和Qwen-14B),通过命令行或界面快速切换。
二、DeepSeek大模型私有化部署:全参数硬件配置与场景选型
DeepSeek-R1系列覆盖1.5B到671B参数,不同规模模型的硬件需求、推理性能、适用场景差异极大。以下按“轻量级→企业级→科研级”分级梳理,帮你精准匹配需求。
2.1 轻量级模型(1.5B-8B):个人/小团队入门首选
适合个人开发者学习、中小团队轻量级NLP任务(如客服回复、文本摘要),无需高端显卡,成本可控。
| 模型版本 | DeepSeek-R1-1.5B | DeepSeek-R1-7B | DeepSeek-R1-8B |
|---|---|---|---|
| CPU要求 | 4核+ | 8核+ | 8核+ |
| 内存要求 | 8GB | 16GB | 16GB |
| 存储要求 | 256GB(模型占2GB) | 256GB(模型占5GB) | 256GB(含量化缓存) |
| 显卡要求 | 非必需(纯CPU推理) | RTX 3070/4060(8GB显存) | RTX 3070 Ti(支持FP16) |
| 推理速度 | CPU:~5 tokens/s | GPU:~25 tokens/s | GPU:~30 tokens/s |
| 显存占用 | - | 6GB(FP16) | 5GB(INT8量化) |
| 核心用途 | 本地快速测试、Ollama演示 | 文本摘要、多语言翻译 | 代码补全、数学推理 |
| 典型案例 | 个人学习助手 | 电商客服自动回复 | Python脚本生成 |
| 成本范围 | ¥2,000-5,000 | ¥5,000-10,000 | ¥6,000-12,000 |
| 性价比建议 | 个人开发者入门首选 | 中小团队轻量NLP项目首选 | 技术团队效率工具开发 |
2.2 企业级模型(14B-32B):业务场景深度适配
适合企业级核心任务(如法律分析、医疗报告生成),需中端显卡支持,具备8K-16K上下文窗口,可处理长文本。
| 模型版本 | DeepSeek-R1-14B | DeepSeek-R1-32B |
|---|---|---|
| CPU要求 | 12核+ | 16核+ |
| 内存要求 | 32GB | 64GB |
| 存储要求 | 512GB | 1TB |
| 显卡要求 | RTX 4090(24GB显存) | 双卡RTX 3090/A100(40GB) |
| 推理速度 | 45 tokens/s(FP16) | 60 tokens/s(张量并行) |
| 上下文窗口 | 8K | 16K |
| 核心用途 | 法律合同分析、医疗报告生成 | 多模态数据预处理、科研仿真 |
| 典型案例 | 金融风险报告自动化 | 蛋白质结构预测、3D建模辅助 |
| 成本范围 | ¥20,000-30,000 | ¥40,000-100,000 |
| 部署建议 | 单卡部署,适配中小企业核心业务 | 多卡张量并行,需Linux服务器支持 |
2.3 科研级模型(70B-671B):超大规模任务攻坚
面向科研攻关(如气候模拟、AGI算法)或国家级基础设施,需高端GPU集群、高速网络支持,成本极高。
| 模型版本 | DeepSeek-R1-70B | DeepSeek-R1-671B |
|---|---|---|
| 计算节点 | 2×A100 80GB(¥15万/张) | 8×H100(¥220万/张) |
| 内存要求 | 256GB | 512GB |
| 存储要求 | 1TB | 10TB |
| 网络要求 | 100Gbps(高速互联) | 400Gbps(RDMA网络) |
| 适用场景 | 科研:气候模拟、材料科学;商业:城市交通数字孪生 | 科研:AGI算法探索、超大规模预训练;商业:国家级AI基础设施 |
| 成本范围 | ¥400,000+ | ¥20,000,000+ |
| 生态支持 | HuggingFace加速库优化 | 定制化CUDA内核+混合精度训练 |
| 部署说明 | 需专业AI运维团队,支持多卡数据并行 | 需超算中心级基础设施,适配分布式训练框架 |
三、Ollama实操:3步实现DeepSeek本地部署
Ollama是目前最火的大模型本地化部署工具,被誉为“大模型领域的Docker+Maven”——既支持类Docker的容器化模型管理,又能像Maven一样拉取“中央仓库”的模型。以下从“原理→安装→命令实战”完整拆解。
3.1 为什么选Ollama?核心优势解析
- 零门槛部署:无需配置PyTorch/CUDA,下载安装包后直接用命令启动模型;
- OpenAI兼容API:默认提供
http://localhost:11434/v1/chat/completions接口,可直接对接LangChain、LlamaIndex等框架; - 资源优化:自动适配GPU/CPU,支持设置
OLLAMA_CUDA_DEVICE=0指定显卡,INT8量化减少显存占用; - 隐私安全:模型缓存、推理过程全在本地,无数据上传风险;
- 跨平台支持:Windows、Mac(含M1/M2)、Linux全兼容,Mac用户可利用Metal框架加速。
3.2 安装Ollama:分系统操作指南
1. 下载安装包(官网直达)
- 官网:https://ollama.com/
- 对应系统选择包:
- Windows:下载
.exe文件,双击安装(需管理员权限); - Mac:下载
.dmg文件,拖入应用程序即可; - Linux:执行命令
curl -fsSL https://ollama.com/install.sh | sh自动安装。
- Windows:下载
2. 验证安装
下载完成之后,以windos为例,我们在所在exe路径打开终端:
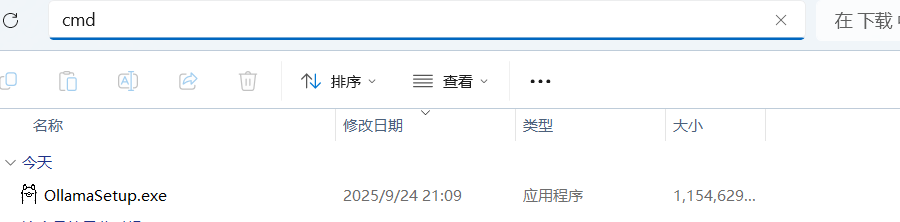
输入命令:
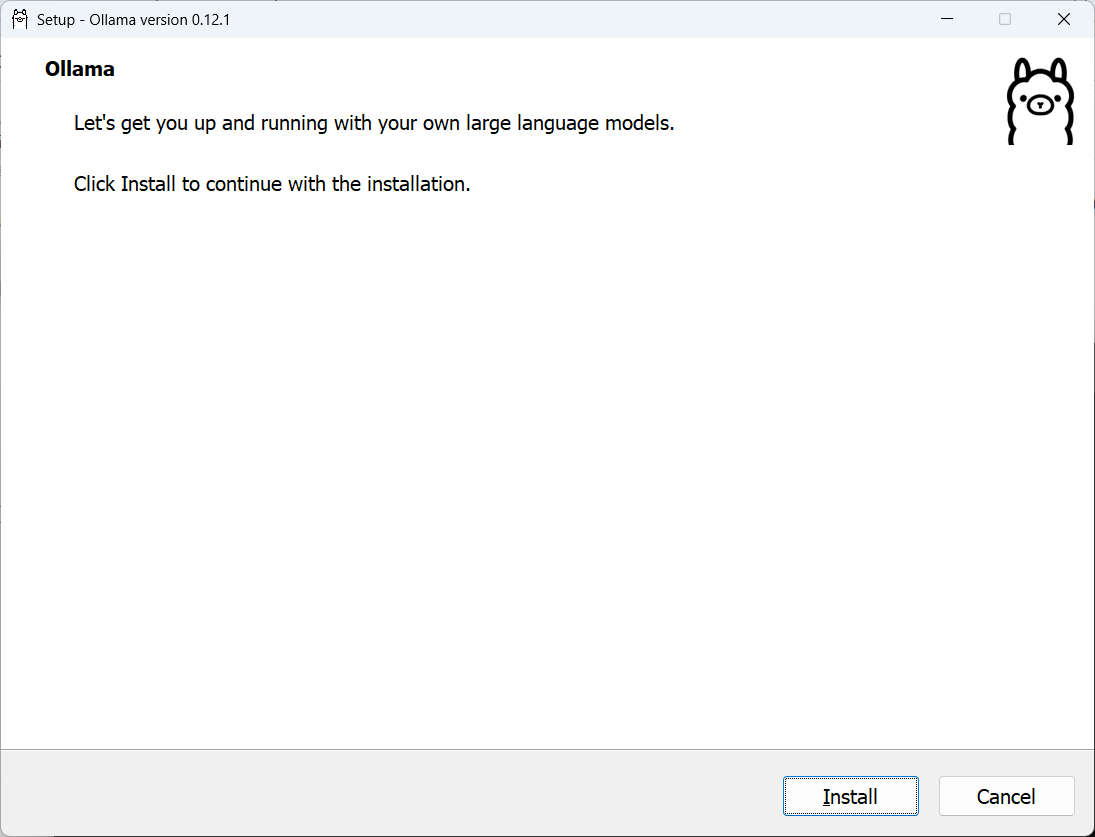
OllamaSetup.exe /DIR=D:\ollama
其中E:\ai\Ollama为我们要安装的路径,也可以直接双击exe安装,默认路径为C盘
回车后,点击Install,等待安装完毕即可
打开终端(Windows用PowerShell,Mac/Linux用Terminal),输入:
ollama --version
若输出版本号(如ollama version 0.1.38),则安装成功。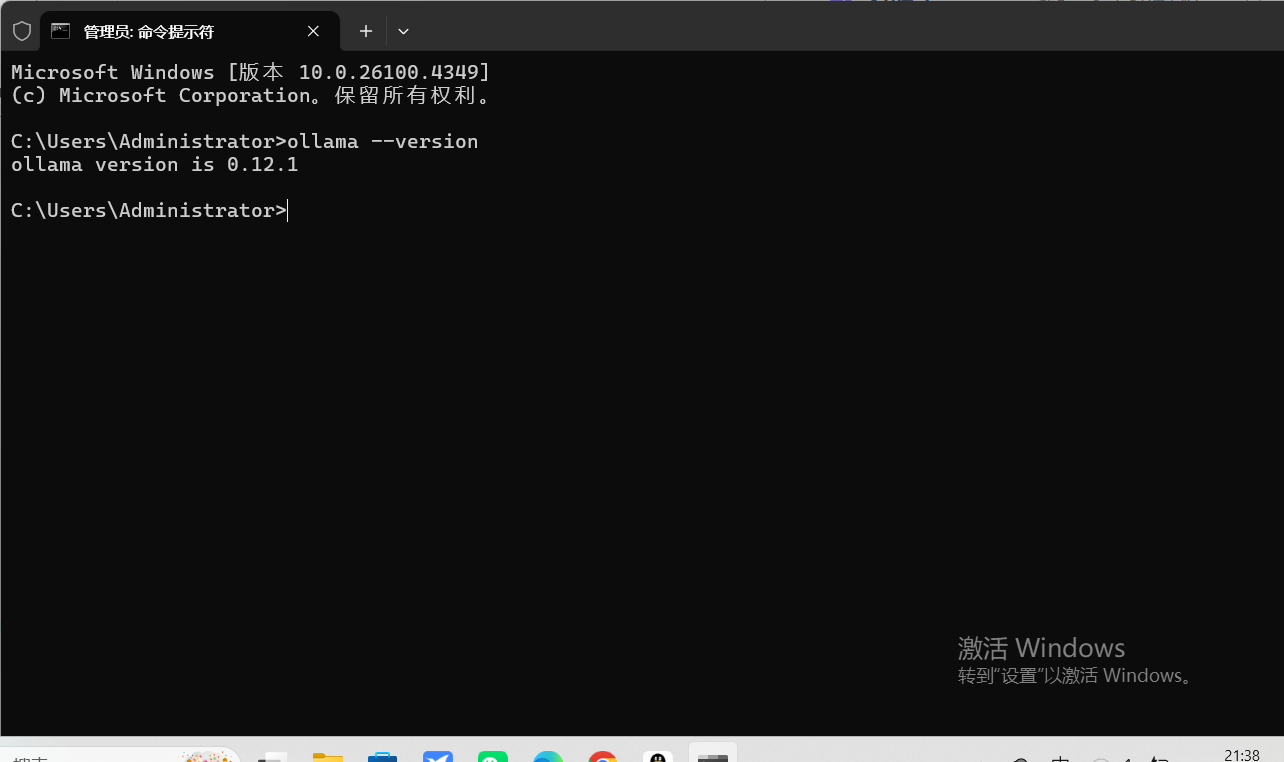
3.3 Ollama常用命令:模型管理与服务控制
Ollama的命令设计极简洁,核心围绕“模型拉取-运行-管理”和“服务启动”,以下是高频命令实战(以DeepSeek-7B为例)。
1. 模型管理:拉取、查看、删除
| 命令 | 功能说明 | 示例(DeepSeek-7B) |
|---|---|---|
ollama pull <模型名> |
从官方仓库下载模型(支持版本标签) | ollama pull deepseek:7b-instruct |
ollama list |
查看本地已安装的所有模型 | ollama list(输出模型名、大小、哈希) |
ollama rm <模型名> |
删除本地模型(释放存储) | ollama rm deepseek:7b-instruct |

提示:DeepSeek模型在Ollama的标签格式为
deepseek:<参数>-<类型>,如deepseek:14b-chat(14B对话模型)、deepseek:coder-7b(7B代码模型)。
2. 模型运行:交互与API服务
| 命令 | 功能说明 | 操作步骤 |
|---|---|---|
ollama run <模型名> |
启动模型并进入交互模式(类似ChatGPT对话) | 1. 输入ollama run deepseek:7b-instruct;2. 直接输入问题(如“写一个Python排序脚本”); 3. 按 Ctrl+D或/bye退出交互。 |
ollama serve |
启动API服务(供外部程序调用) | 1. 输入ollama serve(默认端口11434);2. 用Postman调用接口: POST http://localhost:11434/v1/chat/completions Body: {"model":"deepseek:7b-instruct","messages":[{"role":"user","content":"解释什么是大模型"}]} |
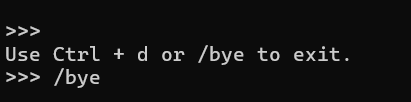
直接输入 ollama run deepseek-r1:7b 会先自动下载

部署完成后提问

四、总结:DeepSeek私有化部署选型指南
-
按团队规模选型:
- 个人开发者:优先DeepSeek-1.5B + Ollama,成本¥2k-5k,快速入门;
- 中小团队:选择DeepSeek-7B/8B,搭配RTX 3070,满足客服、摘要等需求;
- 企业级业务:DeepSeek-14B/32B + RTX 4090/A100,处理法律、医疗等核心任务;
- 科研机构:DeepSeek-70B/671B + A100/H100集群,攻坚超大规模任务。
-
按部署门槛选型:
- 小白/快速验证:Ollama/LM Studio,10分钟完成部署;
- 需定制化:源码部署(vLLM/Transformers),适配业务逻辑;
- 无GPU环境:llama.cpp + DeepSeek-1.5B,纯CPU推理。
-
关键注意点:
- 显存:INT8量化可减少50%显存占用(如7B模型从6GB→3GB),但精度略有损失;
- 网络:多卡部署(如32B/70B)需100Gbps以上网络,避免数据传输瓶颈;
- 隐私:敏感数据场景必须选择离线部署(如Ollama),禁止使用云端API。
觉得有用请点赞收藏!
如果有相关问题,欢迎评论区留言讨论~
更多推荐
 68
68 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)