
学习华为昇腾AI教材人工智能部分Day1
01人工智能概述
一、人工智能的定义
较早、比较流行的一次定义:约翰麦卡锡在1956年的达特矛斯会议提出,即人工智能就是要让机器的行为看起来像人所表现出来的一样。该定义忽略了强人工智能的可能。
另一定义:人工智能是人造机器所表现出来的智能性即弱人工智能,也就是目前所处智能时代仍然是弱人工智能。
Howard Gardner教授提出多元智能理论, 指出了体现多元智能的八种能力: 语言、逻辑 、空间 、肢体动觉、音乐、人际、内省 、 自然。
美国教育学家和心理学家加德纳则指出智能的四个方面在于语言智能 、数学逻辑智能 、空间智能 、身体运动智能。
到底什么是人工智能(Artificial Intelligence,英文简称为AI)呢?
人工智能是研究、 开发用于模拟、 延伸和扩展人的智能的理论、 方法、 技术及应用系统的一门新的技术科学。 1956年由约翰·麦卡锡首次提出, 当时的定义为“制造智能机器的科学与工程” 。 人工智能的目的就是让机器能够像人一样思考, 让机器拥有智能。
二、人工智能与机器学习、深度学习的关系

人工智能:是研究、 开发用于模拟、 延伸和扩展人的智能的理论、 方法及应用系统的一 门新的技术科学。
机器学习:研究计算机怎样模拟或实现人类的学习行为, 以获取新的知识或技能, 重新组织已有的知识结构使之不断改善自身的性能,机器学习基于训练数据从而构造模型。
深度学习:深度学习的概念源于人工神经网络的研究, 是机器学习研究中的一个领域, 它模仿人脑的机制来解释数据。机器学习包含深度学习,因此机器学习是实现人工智能的必经路径。
三、人工智能的三大学派
人工智能三大学派分别是符号主义(人工智能源于数理逻辑,符号主义仍为主流派别)、连接主义(人工智能源于仿生学)、行为主义(人工智能源于控制论,偏向于应用实践)。
四、人工智能发展三要素
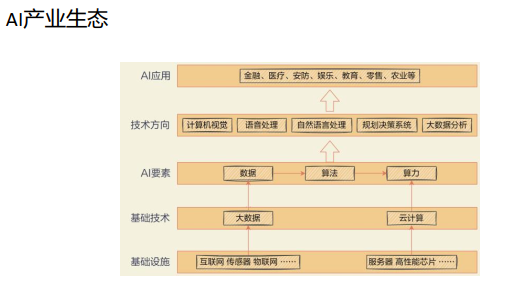
AI发展三要素:算力(人工智能的发动机,人工智能系统的动力源泉)、数据(人工智能的能源,人工智能系统的 “燃料”)、算法(人工智能的大脑,人工智能系统的决策中心)。
人工智能四要素:数据、算力、算法、场景
五、人工智能的分类
强人工智能: 强人工智能观点认为有可能制造出真正能推理和解决问题的智能机器,并且,这样的机器将被认为是有知觉的,有自我意识的。可以独立思考问题并制定 解决问题的最优方案,有自己的价值观和世界观体系。有和生物一样的各种本能,比如生存和 安全需求。在某种意义上可以看作一种新的文明。强人工智能是指在各方面都能和人类比肩的人工智能, 因此强人工智能不是仅限于某 一领域, 而是让机器人全方位实现类人的能力。 强人工智能能够进行思考、 计划、 解决问题、 抽象思维、 理解复杂理念、 快速学习和从经验中学习。 目前有一种认为 是, 如果能够模拟出人脑, 并把其中的神经元、 神经突触等全部同规模地仿制出来, 那么强人工智能就会自然产生。
弱人工智能: 弱人工智能是指不能制造出真正地推理和解决问题的智能机 器,这些机器只不过看起来像是智能的,但是并不真正拥有智能,也不会有自主意识。弱人工智能的产生减轻了人类智力劳动, 类似于高级仿生学。 AI的能力仅在某些方面超过了人类。
02人工智能技术领域
一、AI技术领域介绍
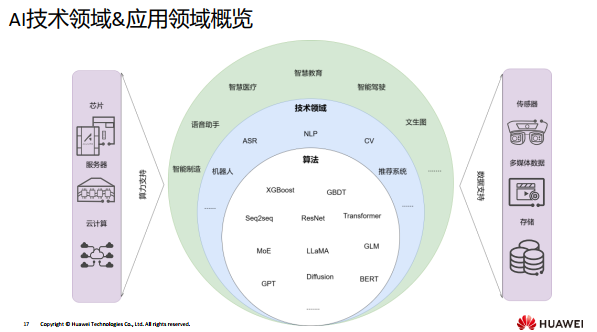
国内目前AI的通用技术方向主要为:计算机视觉即是研究如何让计算机“看”并“看”地,更快更精确 ;自然语言处理即研究让计算机来理解并运用自然语言;多模态......
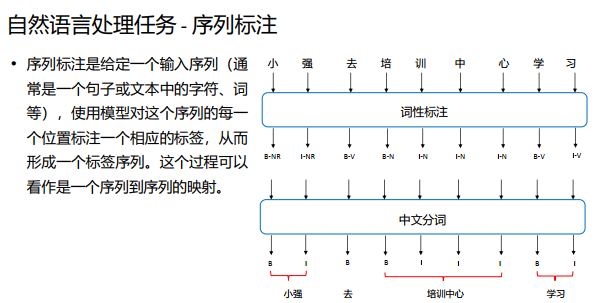
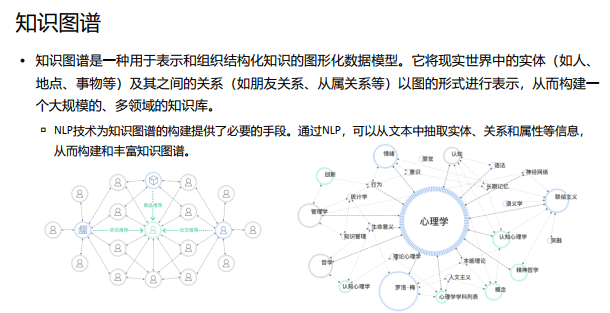
二、自然语言处理NLP
自然语言处理是一门计算机科学领域与人工智能的一个分支, 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
NLP的目标是让计算机理解和生成人类的语言。
NLP经历了从基于规则和语言学理论的起步阶段,再到经过机器学习和深度学习的崛起,最后到如今大语言模型阶段。
应用场景: 情感分类;文本挖掘;机器翻译;智能问答。


三、计算机视觉CV
计算机视觉是一种利用计算机和相应的算法来模拟人类视觉的过程的技术。 它涉及从图 像或视频中提取信息、 分析和理解内容, 并做出相应的决策。
应用场景: 自动驾驶;身份验证;智慧城市;字符识别
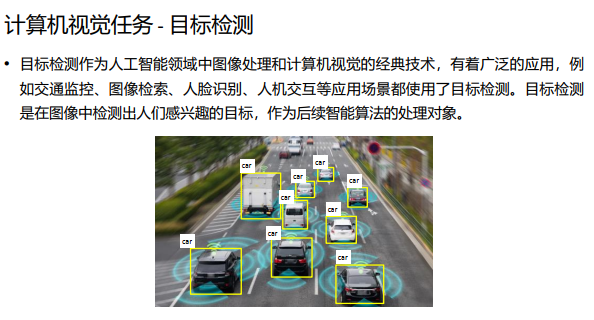
目标识别与目标检测略有不同,尽管它们使用类似的技术。给出一个特定对象,目标识别的目标是在图像中找出该对象的实例。这并不是分类,而是确定该对象是否出现 在图像中,如果出现,则执行定位。例如,监控安防摄像头拍摄的实时图像以识别某 个人的面部。

目标分割分为语义分割和实例分割。语义分割是指像素级的识别图像,即标注出图像中每个像素所属的对象类别,而实例分割是指从图像中识别物体的各个实例,并逐个将实例进行像素级标注的任务。



四、大模型
在大规模数据上训练、 具有海量参数、 功能强大的模型统称为大模型。
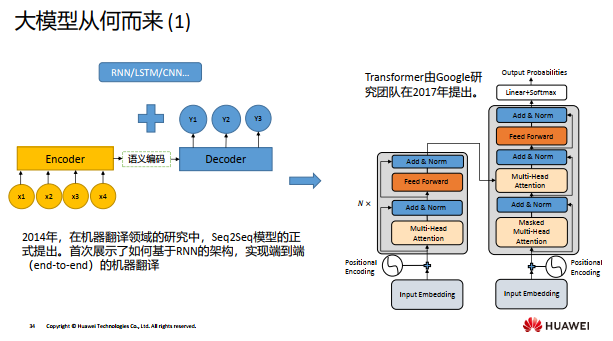
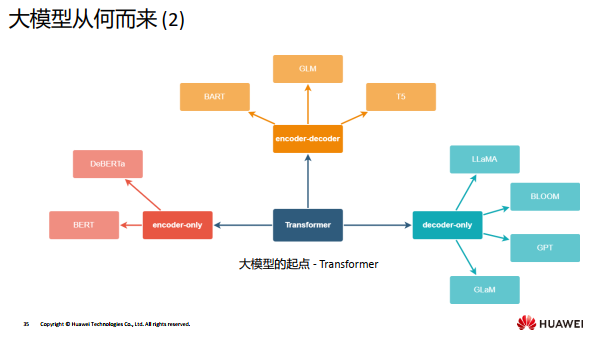
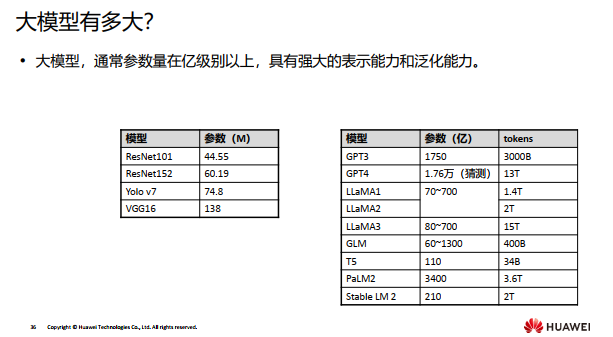
我们如何进行大模型的学习呢?
大模型需要海量的数据进行学习,对每个行业和场景从零开始训练是需要耗费巨大成本的,因此,当前大模型的学习是基于一个事先在大型数据上训练好的基础模型,然后在一些行业数据上进行微调。
当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在 宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。
目前大模型有两大类任务被认为具有涌现能力:上下文学习(ICL, In-Context Learning)。上下文学习可以帮助算法更好地理解一个句子中的词语含义和 关系,或者帮助算法更好地识别图像中不同物体之间的关系。 思维链(CoT, Chain-of-thought)。用户把一步一步的推导过程写出来,并提供给大语言模型,这样大模型就能做一些相对复杂的推理任务。CoT没有像In-Context Learning那样简单地用输入输出对构建提示, 而是结合了中间推理步骤, 这些步骤可以将最终输出引入提示即一步一步地思考。
更多推荐

 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)