
【RAG】整体流程
英文简称:RAG中文翻译:检索增强生成存在的问题:1.大模型训练成本高,不可能实时更新,存储的知识仅限于训练截止日期之前(比如2023年训练出来的模型,询问2025年发生的事件,大模型不了解)2.用于训练大模型的知识,来源于网络上各种公开文件,并不了解私域的信息(比如询问大模型我的公司有多少人,员工手册有什么内容,大模型并不知道)由此衍生出了RAG的概念RAG存在的意义:针对性的解答专业问题,即用
Retrieval-Augmented Generation
英文简称:RAG
中文翻译:检索增强生成
传统的对话方式: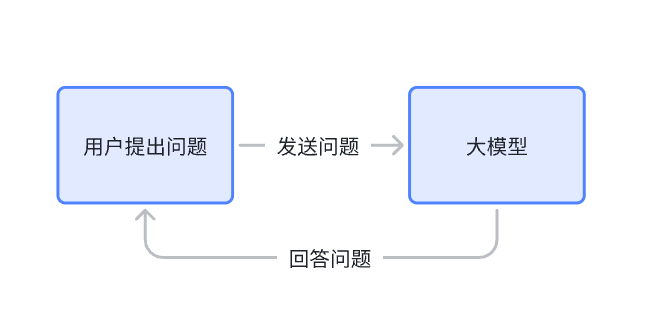
存在的问题:
1.大模型训练成本高,不可能实时更新,存储的知识仅限于训练截止日期之前
(比如2023年训练出来的模型,询问2025年发生的事件,大模型不了解)
2.用于训练大模型的知识,来源于网络上各种公开文件,并不了解私域的信息
(比如询问大模型我的公司有多少人,员工手册有什么内容,大模型并不知道)
由此衍生出了RAG的概念
RAG存在的意义:针对性的解答专业问题,即用户提问时,结合了专业知识库+大模型的方式回答问题
(比如想要个智能客服,那知识库中就存储客服常用话术表,尺码推荐表,商品数据表等等)
RAG工作流程:当用户提出一个问题时,系统不再直接把问题丢给大模型,而是先去一个外部知识库里边检索出与这个问题最相关的相关参考内容,然后把这些内容连同用户的问题一起打包发送给大模型,让大模型基于这些增强的信息,最终生成一个更加贴切和准确的答案
RAG使用意义:RAG技术通过完美结合检索的准确性和生成的流畅性,使得AI系统不再受限于预训练的静态知识(大模型),而是能够动态的实时的从海量数据中(专业知识库)寻找答案,从而为用户提供更加精准,更加可靠,更加个性化的服务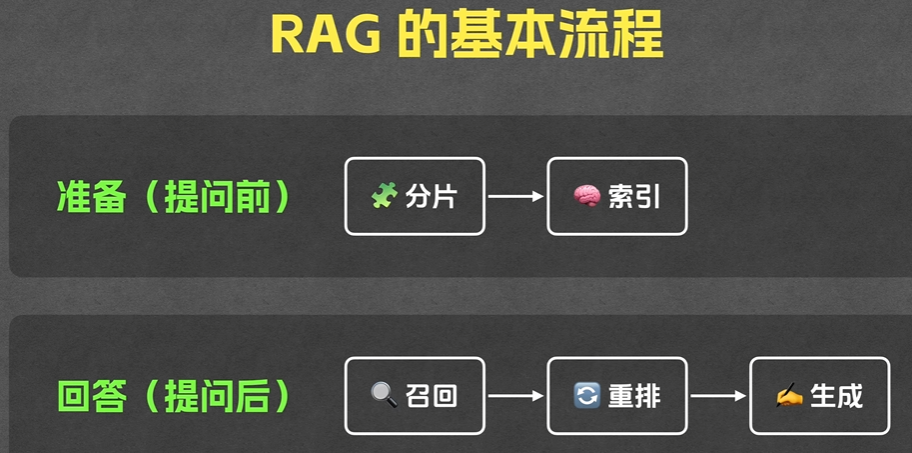
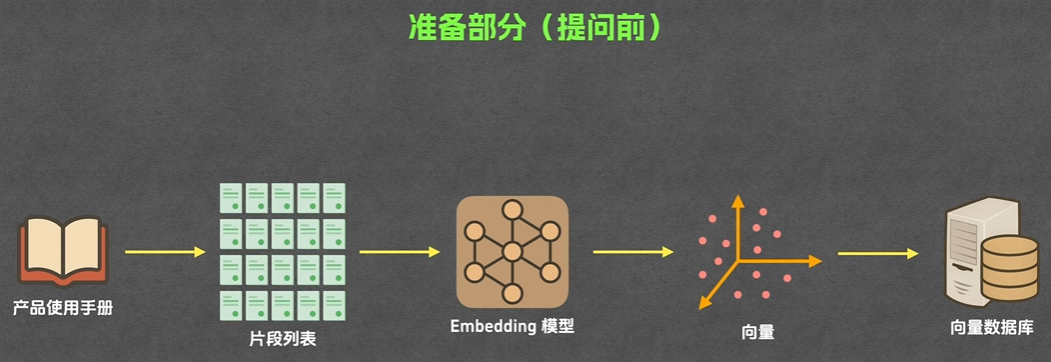
RAG准备工作:准备知识库
遇到的问题:直接把知识库内容放入大模型输入框内容太多
1.模型无法读取所有内容,因为上下文token数量有限
2.消耗的token数量太多,成本高
3.内容太多模型推理慢,且会降低模型对真正相关信息的关注度,增加幻觉风险
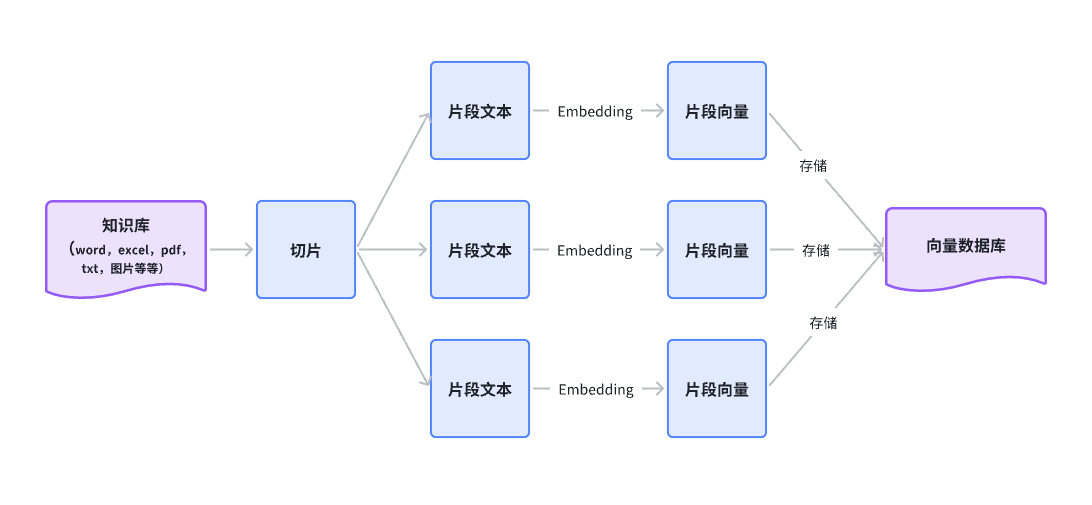
解决方法:将所有知识库切片,将所有切片通过Embedding的方式转换为向量,存储在向量数据库中
1.切片:(也叫分块,分片)
RAG会把上传的知识库中的文件切分成多个片段
切片的方式:根据字数,段落,章节,页码等等方式
2.Embedding:
将片段文本转换为片段向量
(比如,我爱吃豆腐,会转换为 [1,5,9,10,-30,20]的这个向量)
索引:
1.通过 Embedding 将片段文本转换为片段向量
2.将片段文本和片段向量存入向量数据库中
向量数据库:用于存储和查询向量的数据库
比如,向量数据库中存储着n个一一对应的文本和向量
RAG执行工作:
用户提问,根据知识库+大模型回答问题的过程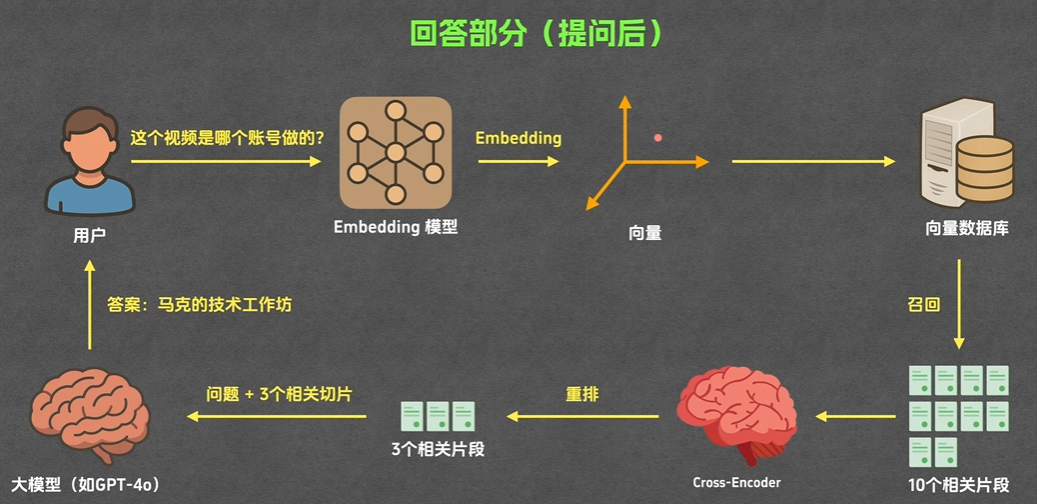
召回:根据用户提问的问题,搜索与之相关的多个片段
方法:向量相似度
特点:成本低,耗时短,准确率低
适合场景:粗略筛选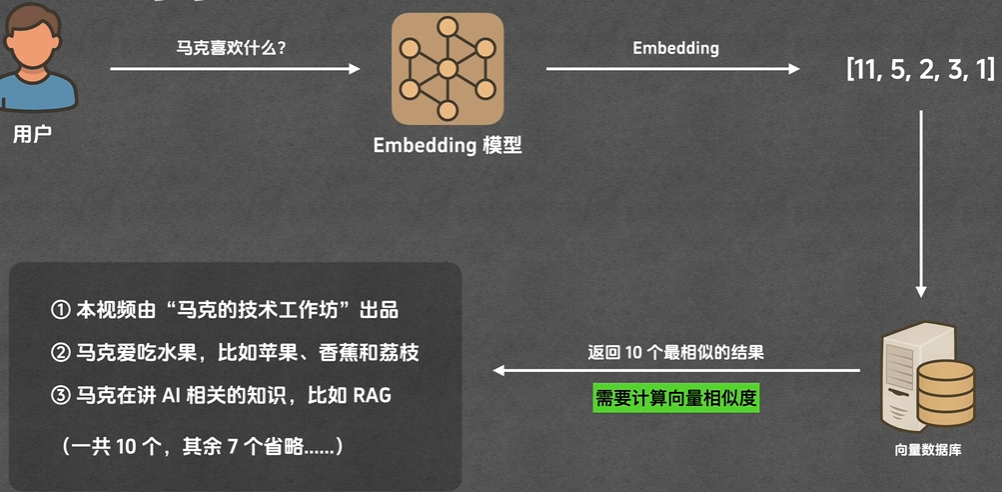

向量相似度计算方法:(提问的片段向量,与向量数据库里的每一个片段向量做计算)
1.余弦相似度:计算两个向量的夹角cos值,根据cos值判断夹角大小
2.欧氏距离:计算两个向量之间的距离
3.点积:第一个向量在第二个向量上的投影长度,乘第二个向量的长度,得到的数值(根据正负得到两个向量是否在同一方向上,根据数值的大小得到相似的程度有多大)
重排:召回的多个片段中,挑选出相似度最高的几个片段
方法:cross-encoder
特点:成本高,耗时长,准确率高
适合场景:精挑细选
为什么要召回再重排,不在召回中一次性解决了?
答:召回+重排效果更好,召回和重排的文本相似度计算逻辑不一样

更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)