
学习日记1
1.学习streamlit数据探索库的使用2.学习pandas的初级使用3.巩固python语法1.完成多邻国的每日练习1.AE、PS、PR各学习半个小时1.重新对数据进行分析,探索出相关性较高的变量完成高度类人仿生人工智能的开发,与真人思维无异的人工智能。
今日预计完成以下任务:
编程方面(120min):
1.学习streamlit数据探索库的使用
2.学习pandas的初级使用
3.巩固python语法
英语方面(15min):
1.完成多邻国的每日练习
其他技术方面(90min):
1.AE、PS、PR各学习半个小时
科研方面:
1.重新对数据进行分析,探索出相关性较高的变量
长线目标:
完成高度类人仿生人工智能的开发,与真人思维无异的人工智能
一、编程方面
1 streamlit学习
参考中文streamlit开发文档:streamlit中文开发手册(详细版)-CSDN博客
官方开发文档:Streamlit documentation
在终端运行:
streamlit hello即可打开官方的入门教程:
(1) streamlit的运行:
我使用的是vscode完成各种代码的开发,streamlit文件的运行不像以往其他文件,直接通过终端运行就可以了,需要在终端手动输入以下代码才可以运行,或许与其是浏览器应用有关?
streamlit run "你的script路径"库导入:
import streamlit as st
import pandas as pd加载数据集(二维):
本次使用scikitlearn提供的鸢尾花数据集:
# 加载数据集
Input_dir_CSV = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
COLUMN_NAMES= ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
df = pd.read_csv(Input_dir_CSV, names=COLUMN_NAMES)原数据集形状:
archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
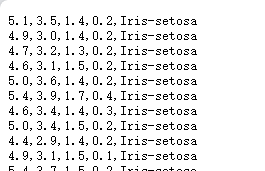
可以看到是没有列明的,所以我们在用pandas导入的时候要用names=['A','B','C']传入参数,原数据集总共5列,我们就定义5列的名称。
但问题来了,如果我数据集有5列,但我定义了4列,或者是我数据集有5列,但我定义了6列会发生什么?接下来进行实验。
CSV读取实验(pandas)
实验1:正常列名一一对应
import pandas as pd
data = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'
data_col = ['sepal_length','sepal_with','petal_lenth','petal_with','species']
df = pd.read_csv(data,names=data_col)
print(df)输出结果:
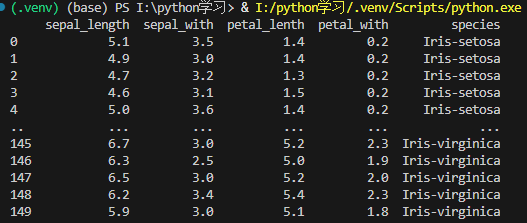
实验2:传入列名大于实际列名
import pandas as pd
data = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'
data_col = ['sepal_length','sepal_with','petal_lenth','petal_with','species','other']
df = pd.read_csv(data,names=data_col)
print(df)在原来代码的基础上,我给传输列名的list,添加了一个原数据集不存在的other名称
输出结果: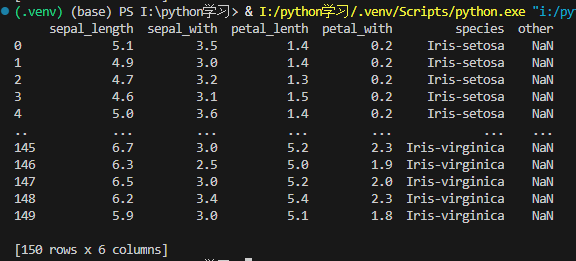
可见,pandas会再创建一个新的列,其中的数值都是NaN(Not a Number)
实验3:传入列名小于实际列名
import pandas as pd
data = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'
data_col = ['sepal_length','sepal_with','petal_lenth','petal_with']
df = pd.read_csv(data,names=data_col)
print(df)输出结果: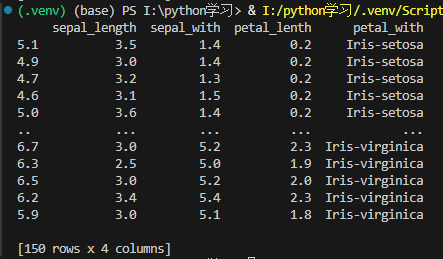
可见,数据仍然成功读取了,但可以发现,pandas会顺序读取各个列,并且顺序为各个列进行命名。
补充:
既然都研究到这里了,今天就来初步了解下pandas的read_csv函数的使用方法。
read_csv学习(pandas)
基础介绍
使用pandas的dataframe定义二维数据其中使用了:
# 读取 CSV 文件,并自定义列名和分隔符
df = pd.read_csv('data.csv', sep=';', header=0, names=['A', 'B', 'C'], dtype={'A': int, 'B': float})
print(df)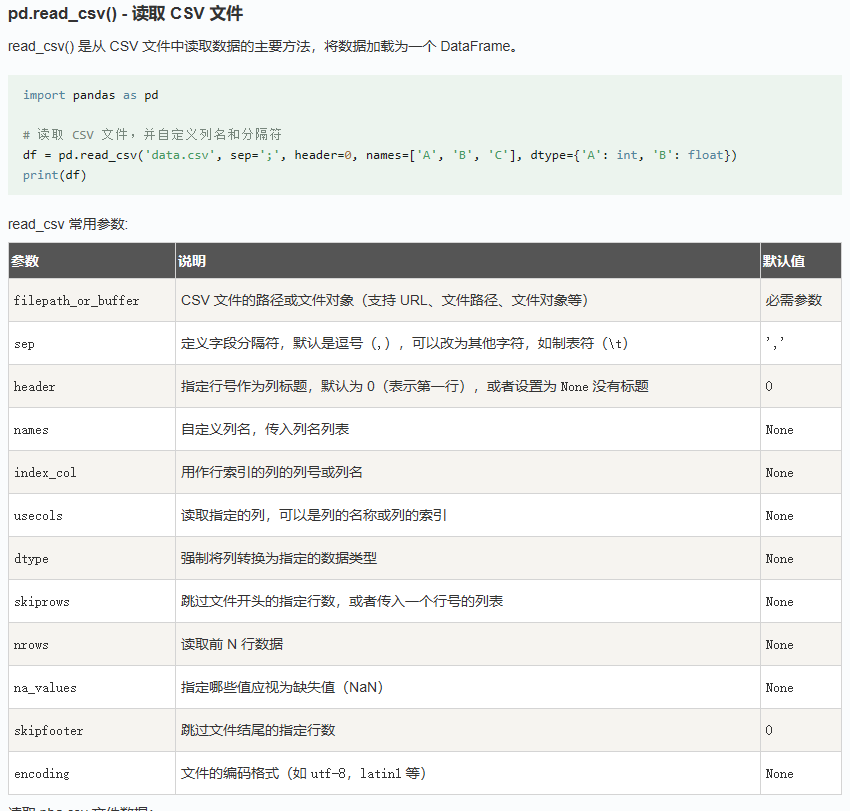
1 filepath_or_buffer(必须)
文件路径,可以是:
-
本地路径字符串(如
"data.csv") -
Path对象 -
URL(如
"https://...") -
类文件对象(支持
.read()方法)
什么是Path对象?
是利用pathlib中的Path,创建的path对象,其中'data'是CWD(Current Working Directory)下的文件。主要是相对路径使用的。
from pathlib import Path
# 创建 Path 对象
p = Path("data") / "data.csv"
# 检查文件是否存在
print(p.exists()) # True / False
# 获取绝对路径
print(p.resolve())
# 读取文件
import pandas as pd
df = pd.read_csv(p) # 直接传 Path 对象
更多关于该部分的详细教程:Pandas CSV 文件 | 菜鸟教程,现在了解了read_csv的初步使用,待后续有需求了进行更进一步的了解。
(2) 查看数据集操作:
首先要了解streamlit中的两个常用方法:
# 查看数据集
st.header("步骤 1:加载 Iris 数据集!")
st.write("数据长这样:")
st.write(df.head())
# df.head()函数用于打印前五行数据(默认前五行)感觉这样子做笔记效率有点低,所以我决定还是以简洁的文字记录学习笔记。
Rewrite:
标题:
st.title()
st.header()
st.subheader()
显示文本(支持Markdown):
st.markdown("支持markdown语法")
st.text("""
支持多行注释的用法
2行
3行
""")
显示代码片段:
st.code("""
此处是你的要显示的代码,默认使用python语法的颜色方案
""")
通用显示代码:
import streamlit as st
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 字符串
st.write("这是一段文本。")
# 数字
st.write(42)
# 列表
st.write([1, 2, 3])
# 字典
st.write({"key": "value"})
# 数据框(DataFrame)
df = pd.DataFrame({"Column 1": [1, 2, 3], "Column 2": ["A", "B", "C"]})
st.write(df)
#多参数用法
st.write("这是一个字符串", 42, [1, 2, 3], {"key": "value"})
#自定义渲染
fig, ax = plt.subplots()
x = np.linspace(0, 10, 100)
y = np.sin(x)
ax.plot(x, y)
st.write(fig)
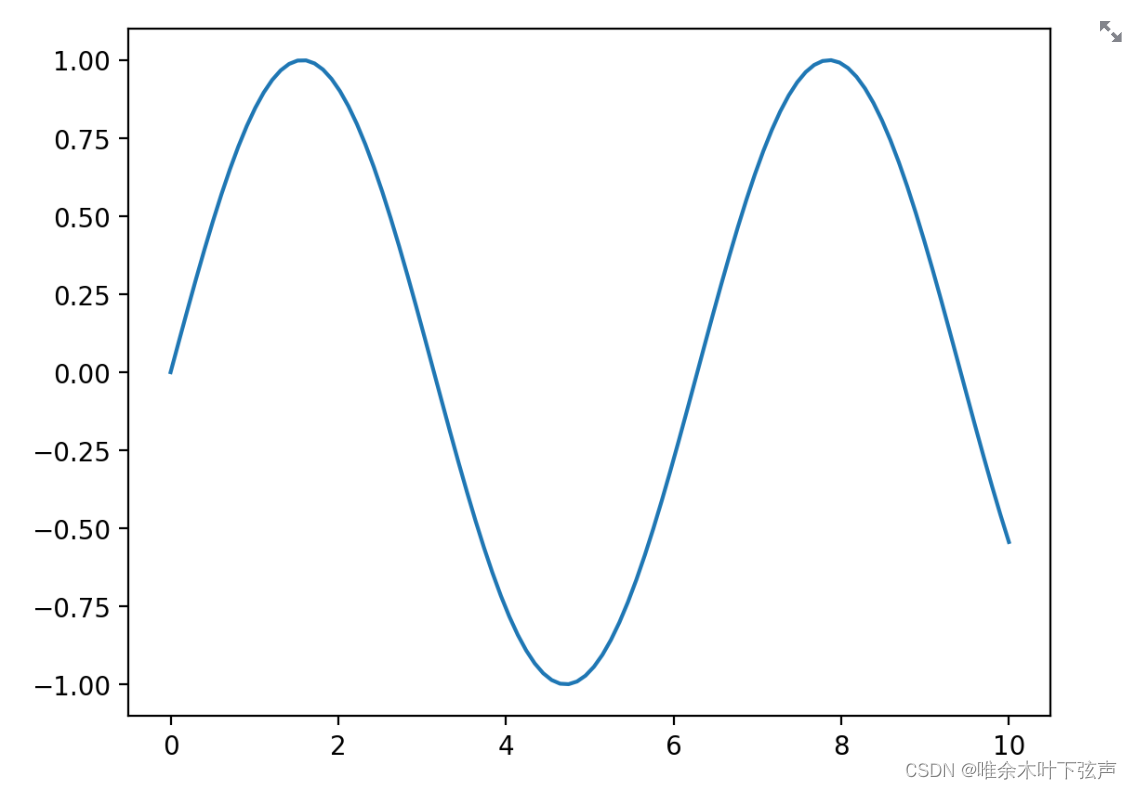
补充:此处的python知识点
# 在刚刚的代码中
fig, ax = plt.subplots()
x = np.linspace(0, 10, 100)
y = np.sin(x) ax.plot(x, y)
st.write(fig)出现了一个等号同时赋值给了两个变量,更困惑的是右边是一个“变量”。


到这对streamlit已经有了一个大概的认知,已经可以进行初步的开发,今日的编程方面的学习到此算是比较充实的了。
二、科研方面
我想要建立一个标准的机器学习工作流,昨天听了孙根云老师的报告,受益匪浅。他们课题组主要是利用机器学习工具完成各种数据集的制作,预测、分类、识别等工作。一二区对他们来说算是非常平常的事情,真的是太厉害了。
在报告中,展现了他们课题组在机器学习工作流里面的高效、标准、严谨的研究流程,不像是我这种收集数据、调参、分析这种rubbish文章创作。所以我想以他们为榜样,优化我在机器学习这方面的认知。争取在这次科研活动里面,完成较为拿得出手的成绩。

所以我在机器学习的各个流程上面进行了探索。
在数据选取与分析上面我选择了streamlit也就是前文提到的强大工具,通过streamlit能够很好地完成初步的数据探索,找到与标签更相关的数据。
在机器学习实验跟踪方面,我尝试了swanlab(虽然不是很熟练,而且做出来的效果一坨),但它在这方面潜力还是值得我去挖掘和探索的。
然后最主要的就是数据管理与转换方面,这个 过程往往会占据70%的时间,所以找到一个高效的工具与解决方案,就是一个很重要的行动方向。
了解了许多工作,一个国产团队的工具吸引了我的注意:
JZFS: 用于机器学习数据集管理的版本控制文件系统 - 知乎
现在对他进行了解,我需要关注以下几个问题:
1.在处理遥感数据的时候,往往会有不同空间参考、元数据的遥感数据,要检查这个软件对这方面的支持。
2.遥感数据格式不尽相同,要检查其数据组织能力是否达标,能否管理多个不同类型的数据,对于大小较大的数据,能否完成组织与管理。
3.其似乎包含对数据集的一系列操作,我需要检查其能否满足我对科研的需要,主要是数据格式转换(HDF to TIF等)、数据重采样、数据值清洗、栅格计算之类的。
4.是否便于我操作,学习成本如何?因为似乎看到是“git”语言之类的。
该软件分为几个部分:
1.JZFS:交子文件系统,集成了数据集管理(版本控制、访问控制等)和数据集转换(ETL)机制,但目前数据转换机制作为一个单独项目JZFlow独立发展
2.JZFlow:JZFLow可以支持不同的工作流、管道或数据编排需求,是生成不同用途的数据集(快照)的关键部分。
3.JZLab:是JZFS的可视化UI界面。
三、软件学习方面
1 AE
今天学习的是线性动画和非线性动画
(1)对位移动画设置缓动
选中对象的关键帧,点击F9,即可设置缓动。
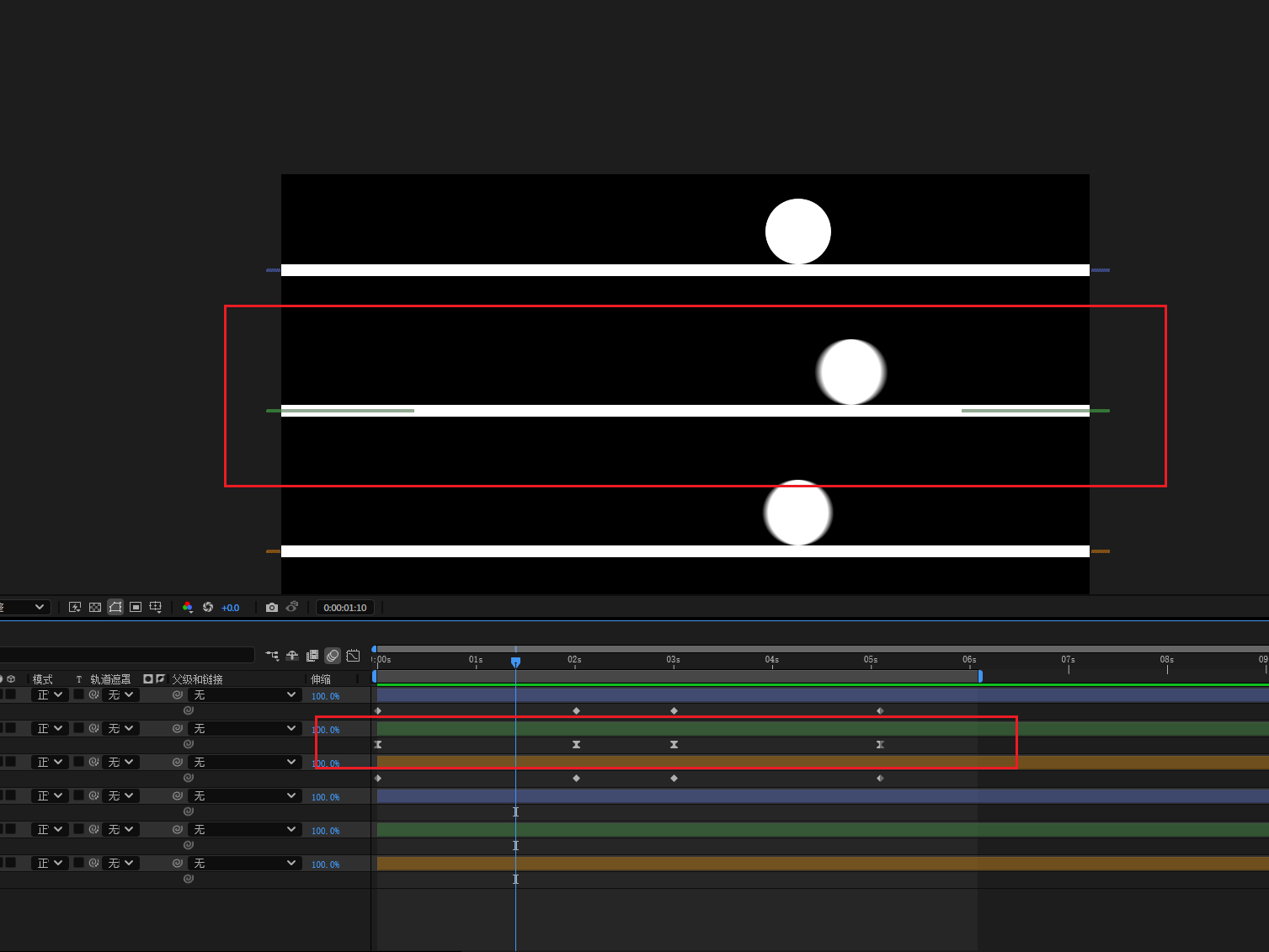
(2)利用图标编辑器编辑运动曲线
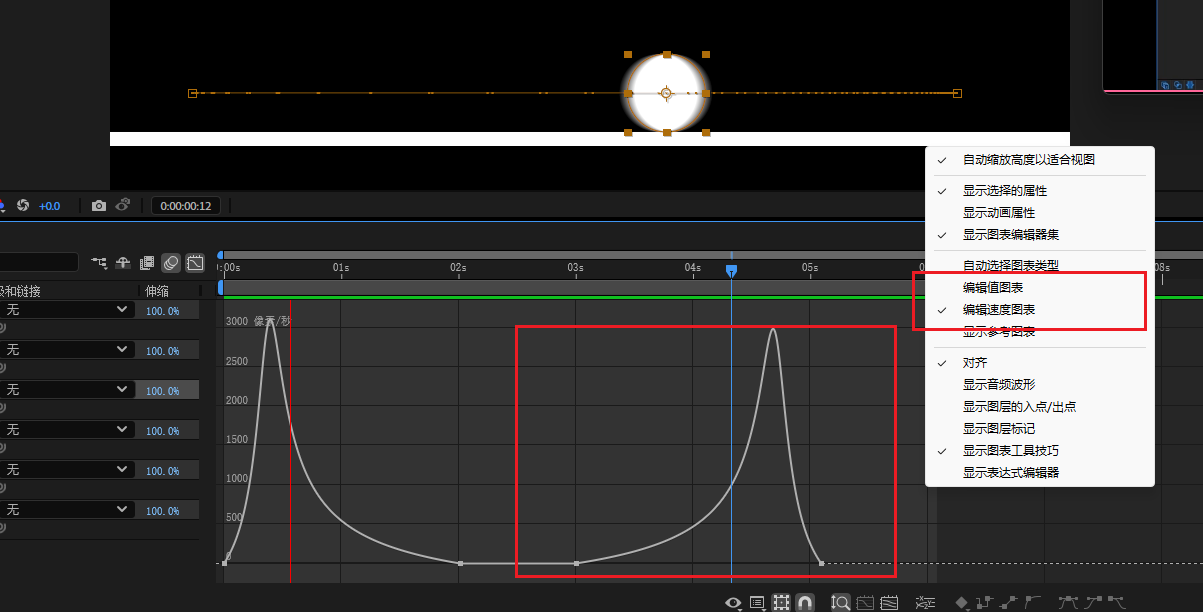
(3)启用运动模糊
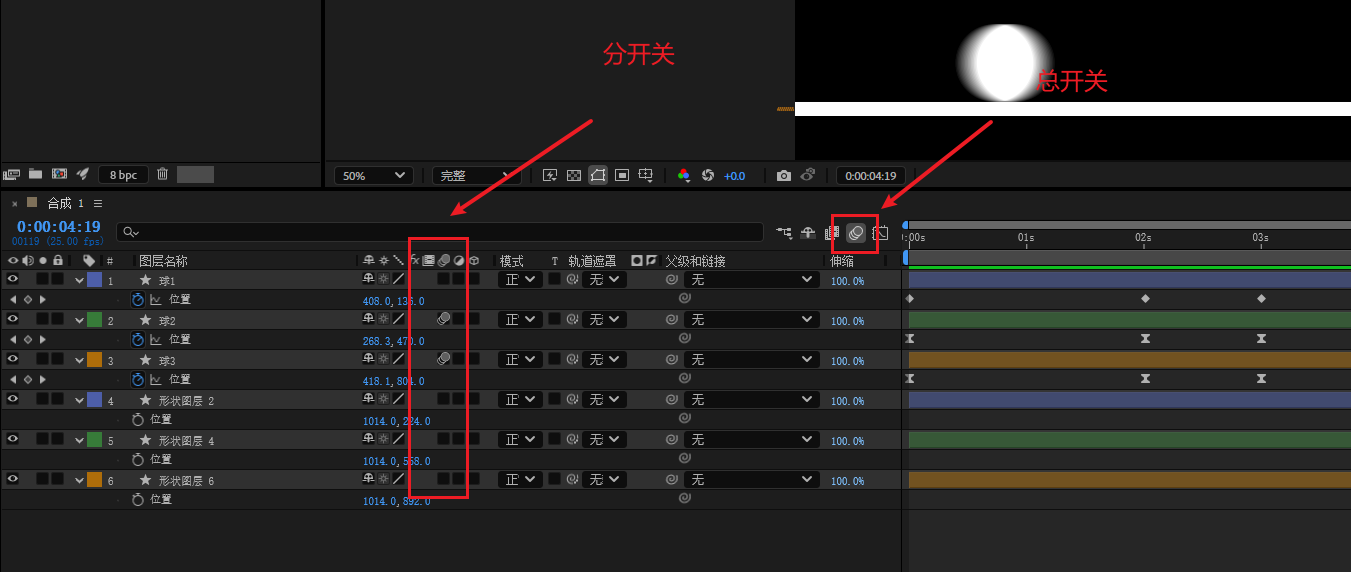
小结:

更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)