
大模型压缩-篇一
大模型压缩分类
主要分为如下几类:
-
剪枝(Pruning)
-
知识蒸馏(Knowledge Distillation)
-
量化(Quantization)
-
低秩分解(Low-Rank Factorization)
大模型剪枝
参考:大语言模型的深度裁剪法
论文:Shortened LLaMA: A Simple Depth Pruning for Large Language Models
概念
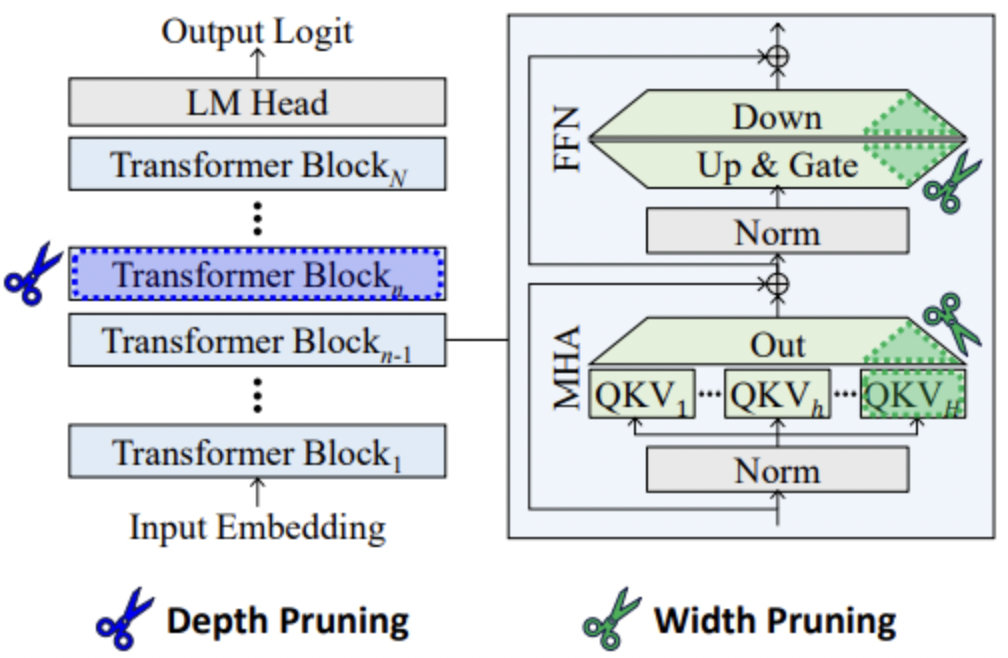
剪枝分为两种:深度剪枝、宽度剪枝
-
宽度剪枝:它通过减少投影权重矩阵的大小(例如,移除注意力头)来缩小网络宽度,同时保持层数不变。这种方法在受限批处理大小的条件下,对于提高LLMs的自回归生成速度并不有效。
-
深度剪枝:移除整个层或块,同时保持剩余权重的大小不变。深度剪枝通常被认为与宽度剪枝相比,在性能上不那么有效,因为它涉及到更大和更粗糙的单元的消除。但是,再结合LoRA重训练阶段,可以与最近的宽度剪枝方法相媲美,特别是在硬件限制下需要运行小批量LLMs的情况下,深度剪枝显著提高了推理速度。
论文贡献
-
在受限批量大小的场景中,深度剪枝方法能够有效提升LLMs的自回归生成速度,这一点在以往的研究中鲜有探讨。
-
该研究提出了一种简单且有效的LLMs深度剪枝策略,并探索了多种设计因素,包括可剪枝单元的选择、重要性评估标准以及重训练频率。
-
通过排除若干Transformer块获得的紧凑型LLMs,在零样本任务中的表现与精细宽度剪枝模型相当,同时实现了推理加速。该方法通过一次性移除整个Transformer块,并结合LoRA重训练阶段,展现了与最新宽度剪枝技术相匹敌的零样本任务性能。
剪枝评估准则
论文中采用了Taylor+与PPL方法对比:
-
Taylor+方法:侧重于评估权重参数移除对训练损失的影响,通过计算输出神经元级别的权重重要性分数,并将这些分数相加以评估块级别的重要性。这种方法在常识推理任务的准确性方面表现出色,但它需要计算反向传播梯度,这可能会增加计算成本。
-
PPL方法:通过物理地移除每个块并监控其对PPL的影响来评估块的重要性。PPL反映了模型的行为,因为它是从下一个令牌预测损失中得出的,只需要前向传递,避免了计算反向传播梯度和Hessian逆的需要。PPL方法在生成性能方面表现更好,而且不依赖于启发式选择剪枝候选。
大模型知识蒸馏
大模型量化
量化的目标
降低运存(包括模型本身运行时所需参数本身的大小和模型稳定运行后占用的运算资源)
量化的概念
是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程
量化的对象
-
embedding : 词嵌入向量相关权重的量化
-
权重(weight): weight的量化是最常规也是最常见的。量化weight可达到减少模型大小内存和占用空间
-
输入(input):x
-
输出(output):y
量化的形式
分为线性量化、非线性量化,通常是线性量化:假设r表示量化前的浮点数,量化后的整数q可以表示为:
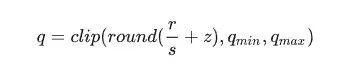
上式中,round(·)和clip(·)分别表示取整和截断操作,qmin和qmax是量化后的最小值和最大值。s是数据量化的间隔(也可以叫标量),z是表示数据偏移的偏置,z为0的量化被称为对称(Symmetric)量化,不为0的量化称为非对称(Asymmetric)量化。通常z为0。
量化的分类
按照应用量化压缩模型的阶段划分:
|
划分 |
阶段 |
|
量化感知训练(Quantization Aware Training,QAT) |
训练阶段 |
|
量化感知微调(Quantization-Aware Fine-tuning,QAF) |
训练后微调阶段 |
|
训练后量化(Post Training Quantization,PTQ) |
训练后直接量化 |
QAT详细介绍
参考论文:Training with Quantization Noise for Extreme Model Compression。
具体实现:fairseq框架
实现的具体流程如下:
-
初始化:设置权重和激活值的范围qmin和qmaz的初始值;
-
构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子;
-
量化训练:重复执行以下步骤直到网络收敛,计算量化网络层的权重和激活值的范围qmin和qmax,并根据该范围将量化损失带入到前向推理和后向参数更新的过程中;
-
导出量化网络:获取qmin和qmax,并计算量化参数s和z;将量化参数代入量化公式中,转换网络中的权重为量化整数值;
-
删除伪量化算子:在量化网络层前后分别插入量化和反量化算子
额外补充
大模型量化在实际应用时,往往还会加入adaptive softmax等缩小词表运算、STE等算法优化
结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)
友友们,自己的知乎账号为“快乐星球”,定期更新技术文章,敬请关注!
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)