
Claude Code Skills 推荐:2026年最值得安装的10个AI技能
1. 引言
2026年,AI编程助手已从“代码补全”进化到“自主执行复杂任务”的阶段。Claude Code 作为其中的佼佼者,其核心能力之一便是通过 Skills(技能) 来扩展和定制化工作流。这些 Skills 本质上是预定义的指令集或工具链,能让 Claude 在特定场景下表现出专家级的能力。
本文将为你精选 2026 年最值得安装的 10 个 Claude Code Skills,覆盖代码开发、项目管理、系统运维、创意写作等多个领域,帮助你大幅提升工作效率。
2. 什么是 Claude Code Skills?
在深入推荐列表之前,我们先简单理解一下 Skills 的概念。Claude Code 的 Skills 类似于 VS Code 的插件或浏览器的扩展,但它们不是独立的程序,而是一组高度结构化的 Prompt 指令 和 工具调用规则。
当你激活一个 Skill 时,Claude 会加载一套特定的行为模式:
- 角色设定:例如“你是一位资深的 Rust 安全审计专家”。
- 工作流约束:例如“在修改代码前,必须先运行测试套件”。
- 输出格式:例如“所有代码审查意见必须按严重等级分类”。
安装和管理 Skills 通常通过 claude.json 配置文件或命令行界面完成。
3. 十大必装 Skills 推荐
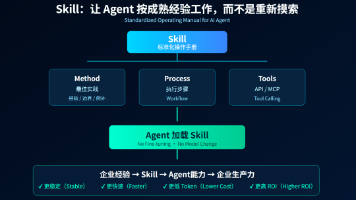
下面这张图展示了十大 Skills 的协作关系,它们共同构成了一个完整的 AI 开发工作流:
3.1. 全能代码审查官(Code Review Pro)
- 功能:对 Pull Request 或代码片段进行深度审查,不仅检查语法错误,还会分析架构设计、性能瓶颈、安全漏洞和可维护性。
- 适用场景:团队代码审查、开源项目贡献前自检。
- 推荐理由:2026年的代码审查已不再是"找茬",而是"协作优化"。这个 Skill 能自动生成结构化的审查报告,并附带修改建议。
代码示例:假设你提交了以下 Python 代码:
# 原始代码:用户管理模块
def get_users():
users = []
for i in range(1000):
user = db.query(f"SELECT * FROM users WHERE id = {i}")
if user:
users.append(user)
return users
激活 Code Review Pro 后,它会生成如下审查报告:
## 🔍 代码审查报告
### 严重等级:🔴 高危
1. **SQL 注入漏洞**(第3行)
- 问题:使用 f-string 拼接 SQL 查询,存在注入风险
- 建议:改用参数化查询
- 修复方案:
```python
user = db.query("SELECT * FROM users WHERE id = ?", (i,))
```
### 严重等级:🟡 中危
2. **N+1 查询问题**(第2-6行)
- 问题:循环内逐条查询数据库,1000次查询导致性能灾难
- 建议:改用批量查询
- 修复方案:
```python
def get_users():
ids = list(range(1000))
users = db.query("SELECT * FROM users WHERE id IN (?)", (ids,))
return users
```
### 严重等级:🟢 建议
3. **类型提示缺失**
- 建议:添加返回类型注解 `-> list[User]`
3.2. 自动化测试工程师(Test Architect)
- 功能:根据你的业务逻辑代码,自动生成单元测试、集成测试和端到端测试用例。支持 Jest、PyTest、JUnit 等主流框架。
- 适用场景:新项目初始化、遗留代码补全测试。
- 推荐理由:测试覆盖率是代码质量的基石。这个 Skill 能帮你从繁琐的测试编写中解放出来,专注于核心业务。
代码示例:对于以下订单服务代码:
# order_service.py
class OrderService:
def calculate_discount(self, total: float, user_level: str) -> float:
if user_level == "vip":
return total * 0.8
elif user_level == "member":
return total * 0.9
else:
return total
Test Architect 自动生成:
# test_order_service.py
import pytest
from order_service import OrderService
class TestOrderService:
@pytest.fixture
def service(self):
return OrderService()
def test_vip_discount(self, service):
"""VIP用户应享受8折优惠"""
result = service.calculate_discount(100.0, "vip")
assert result == 80.0
def test_member_discount(self, service):
"""会员用户应享受9折优惠"""
result = service.calculate_discount(100.0, "member")
assert result == 90.0
def test_regular_user_no_discount(self, service):
"""普通用户无折扣"""
result = service.calculate_discount(100.0, "normal")
assert result == 100.0
@pytest.mark.parametrize("total,level,expected", [
(0, "vip", 0),
(-50, "vip", -40),
(100.5, "member", 90.45),
])
def test_edge_cases(self, service, total, level, expected):
"""边界值测试"""
assert service.calculate_discount(total, level) == expected
3.3. 数据库架构师(DB Schema Designer)
- 功能:根据自然语言描述的业务需求,自动设计数据库表结构、索引策略、外键关系,并生成对应的迁移脚本(如 Prisma、TypeORM、SQLAlchemy)。
- 适用场景:新功能开发、数据库重构。
- 推荐理由:它不仅能设计,还能分析现有查询的慢查询日志,给出索引优化建议。
代码示例:输入"设计一个电商订单系统,包含用户、商品、订单和支付记录",DB Schema Designer 输出:
-- 自动生成的 MySQL 建表脚本
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
nickname VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_email (email),
INDEX idx_created_at (created_at)
);
CREATE TABLE products (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(200) NOT NULL,
price DECIMAL(10,2) NOT NULL,
stock INT NOT NULL DEFAULT 0,
category_id INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_category (category_id),
INDEX idx_price (price)
);
CREATE TABLE orders (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
total_amount DECIMAL(12,2) NOT NULL,
status ENUM('pending','paid','shipped','completed','cancelled') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id),
INDEX idx_user_status (user_id, status),
INDEX idx_created_at (created_at)
);
CREATE TABLE payments (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
order_id BIGINT NOT NULL,
amount DECIMAL(12,2) NOT NULL,
method VARCHAR(20) NOT NULL,
paid_at TIMESTAMP NULL,
FOREIGN KEY (order_id) REFERENCES orders(id),
INDEX idx_order (order_id)
);
3.4. 系统调试侦探(Bug Hunter)
- 功能:当你遇到一个棘手的 Bug 时,激活此 Skill。它会引导你逐步提供错误日志、复现步骤和环境信息,然后进行根因分析,并给出修复方案。
- 适用场景:线上故障排查、复杂逻辑调试。
- 推荐理由:相比手动搜索 Stack Overflow,它能结合你的代码上下文进行精准定位,效率提升数倍。
代码示例:遇到以下并发 Bug:
# 有问题的代码:并发扣库存
class InventoryService:
def __init__(self):
self.stock = {"item_001": 10}
def deduct_stock(self, item_id: str, quantity: int) -> bool:
if self.stock.get(item_id, 0) >= quantity:
self.stock[item_id] -= quantity
return True
return False
Bug Hunter 分析后给出:
## 🐛 Bug 分析报告
### 根因分析
- **问题类型**:竞态条件(Race Condition)
- **触发条件**:高并发下多个请求同时调用 `deduct_stock`
- **复现步骤**:
1. 库存剩余 1 件
2. 请求 A 和 B 同时到达,都通过 `if` 判断
3. 两次都执行扣减,库存变为 -1
### 修复方案
```python
import threading
class InventoryService:
def __init__(self):
self.stock = {"item_001": 10}
self._lock = threading.Lock()
def deduct_stock(self, item_id: str, quantity: int) -> bool:
with self._lock:
if self.stock.get(item_id, 0) >= quantity:
self.stock[item_id] -= quantity
return True
return False
预防建议
- 生产环境建议使用 Redis 分布式锁或数据库行级锁
- 考虑使用乐观锁(版本号机制)提升并发性能
### 3.5. 文档生成器(Doc Weaver)
- **功能**:从代码注释、类型定义和函数签名中,自动生成格式优雅的 API 文档、README 文件或技术设计文档。
- **适用场景**:开源项目文档维护、内部 API 文档更新。
- **推荐理由**:2026年,文档即代码。这个 Skill 能确保文档与代码始终保持同步,告别"文档过期"的烦恼。
**代码示例**:对于以下带类型注解的代码:
```python
from datetime import datetime
from typing import Optional
class UserAPI:
def create_user(self, email: str, name: str, age: Optional[int] = None) -> dict:
"""创建新用户
Args:
email: 用户邮箱(必填)
name: 用户昵称(必填)
age: 用户年龄(可选)
Returns:
包含用户信息的字典
"""
pass
def get_user(self, user_id: int) -> Optional[dict]:
"""根据ID获取用户信息"""
pass
Doc Weaver 自动生成:
# UserAPI 接口文档
## POST /api/users
创建新用户
### 请求参数
| 参数名 | 类型 | 必填 | 说明 |
|--------|------|------|------|
| email | string | ✅ | 用户邮箱 |
| name | string | ✅ | 用户昵称 |
| age | integer | ❌ | 用户年龄 |
### 响应示例
```json
{
"id": 1,
"email": "user@example.com",
"name": "张三",
"age": 25,
"created_at": "2026-07-05T09:00:00Z"
}
GET /api/users/{id}
根据ID获取用户信息
路径参数
| 参数名 | 类型 | 说明 |
|---|---|---|
| id | integer | 用户ID |
响应码
200:成功404:用户不存在
### 3.6. 安全审计专家(Security Sentinel)
- **功能**:对代码库进行静态安全分析,检测 OWASP Top 10 漏洞、依赖库的已知 CVE、硬编码密钥等风险。
- **适用场景**:上线前安全检查、合规审计。
- **推荐理由**:安全左移是 DevOps 的核心实践。在编码阶段就发现并修复漏洞,成本远低于上线后。
**代码示例**:扫描以下代码:
```python
import os
import hashlib
# 危险:硬编码密钥
API_SECRET = "sk-1234567890abcdef"
def authenticate(request):
token = request.headers.get("Authorization")
# 危险:使用 MD5 哈希
hash = hashlib.md5(token.encode()).hexdigest()
# 危险:SQL 注入
query = f"SELECT * FROM users WHERE token = '{hash}'"
return db.execute(query)
Security Sentinel 报告:
## 🔒 安全审计报告
### 🔴 高危漏洞(3个)
1. **硬编码密钥**(第4行)
- CWE-798:使用硬编码凭据
- 建议:使用环境变量或密钥管理服务
- 修复:`API_SECRET = os.getenv("API_SECRET")`
2. **弱哈希算法**(第9行)
- CWE-327:使用已破解的加密算法
- 建议:改用 bcrypt 或 Argon2
- 修复:
```python
import bcrypt
hash = bcrypt.hashpw(token.encode(), bcrypt.gensalt())
```
3. **SQL 注入**(第11行)
- CWE-89:SQL 命令中使用了特殊元素
- 建议:使用 ORM 或参数化查询
- 修复:`db.execute("SELECT * FROM users WHERE token = ?", (hash,))`
### 🟡 中危建议
- 建议启用 HTTPS 强制跳转
- 建议添加请求频率限制
3.7. 项目规划师(Project Planner)
- 功能:将模糊的产品需求转化为结构化的开发任务、用户故事和验收标准。甚至可以生成甘特图或看板视图的 Markdown 描述。
- 适用场景:Sprint 规划、个人项目拆解。
- 推荐理由:它帮助你将"想法"转化为"可执行的任务列表",是敏捷开发者的得力助手。
代码示例:输入"开发一个在线笔记应用",Project Planner 输出:
# 📋 在线笔记应用 - 项目规划
## 用户故事
1. **作为** 用户,**我希望** 能注册账号,**以便** 安全地保存我的笔记
2. **作为** 用户,**我希望** 能创建富文本笔记,**以便** 记录格式丰富的内容
3. **作为** 用户,**我希望** 能按标签分类笔记,**以便** 快速查找
## Sprint 1:基础架构(2周)
| 任务 | 预估工时 | 优先级 |
|------|---------|--------|
| 用户认证模块(注册/登录) | 3天 | P0 |
| 数据库设计与搭建 | 2天 | P0 |
| 笔记 CRUD API | 4天 | P0 |
| 前端基础框架搭建 | 2天 | P1 |
## Sprint 2:核心功能(2周)
| 任务 | 预估工时 | 优先级 |
|------|---------|--------|
| 富文本编辑器集成 | 3天 | P0 |
| 标签系统实现 | 2天 | P1 |
| 搜索功能 | 3天 | P1 |
| 移动端适配 | 2天 | P2 |
## 技术选型
- **前端**:React + TypeScript + Tailwind CSS
- **后端**:FastAPI + SQLAlchemy
- **数据库**:PostgreSQL
- **部署**:Docker + GitHub Actions
3.8. 性能优化师(Performance Tuner)
- 功能:分析代码的时间复杂度和空间复杂度,识别热点函数,并给出具体的优化策略(如缓存、懒加载、算法替换)。
- 适用场景:高并发服务优化、前端渲染性能调优。
- 推荐理由:它不仅能告诉你"哪里慢",还能解释"为什么慢",并给出"如何改"的代码示例。
代码示例:分析以下低效代码:
# 低效实现:查找数组中的重复元素
def find_duplicates(arr):
duplicates = []
for i in range(len(arr)):
for j in range(i + 1, len(arr)):
if arr[i] == arr[j] and arr[i] not in duplicates:
duplicates.append(arr[i])
return duplicates
Performance Tuner 优化:
## ⚡ 性能分析报告
### 当前性能
- **时间复杂度**:O(n²) — 双重循环
- **空间复杂度**:O(n) — 存储结果
### 优化方案
```python
# 优化后:使用哈希表,时间复杂度 O(n)
def find_duplicates(arr):
seen = set()
duplicates = set()
for num in arr:
if num in seen:
duplicates.add(num)
else:
seen.add(num)
return list(duplicates)
性能对比
| 数据规模 | 优化前 | 优化后 | 提升倍数 |
|---|---|---|---|
| 100 | 0.01ms | 0.003ms | 3x |
| 1,000 | 1.2ms | 0.03ms | 40x |
| 10,000 | 120ms | 0.3ms | 400x |
| 100,000 | 12s | 3ms | 4000x |
### 3.9. 创意写作助手(Creative Muse)
- **功能**:跳出代码的范畴,专注于文案、博客、营销邮件、故事大纲的创作。支持多种语气和风格切换。
- **适用场景**:技术博客撰写、产品文案润色。
- **推荐理由**:对于技术人来说,写作往往比写代码更头疼。这个 Skill 能帮你把技术思想转化为通俗易懂的文字。
**代码示例**:输入"帮我写一篇介绍 Docker 的技术博客大纲",Creative Muse 输出:
```markdown
# 🎨 博客大纲:Docker 从入门到精通
## 标题方案
1. 《Docker 实战:从零搭建你的第一个容器化应用》
2. 《告别"在我电脑上能跑"——Docker 容器化指南》
## 文章结构
### 1. 引言:为什么需要 Docker?
- 环境不一致的痛点故事
- "在我电脑上能跑"的经典困境
### 2. Docker 核心概念(配图)
- 镜像 vs 容器 vs 仓库
- Dockerfile 编写技巧
### 3. 实战:容器化一个 Web 应用
- 编写 Dockerfile
- 使用 docker-compose 编排多服务
- 部署到云服务器
### 4. 最佳实践
- 镜像瘦身技巧
- 安全配置建议
- CI/CD 集成方案
### 5. 总结
- 学习路线图推荐
- 常见问题 FAQ
## 推荐语气
- 技术教程风格,适当加入幽默元素
- 每段控制在 3-5 句话,便于阅读
3.10. 多语言翻译官(Polyglot Bridge)
- 功能:将一段代码从一种编程语言精确翻译到另一种(如 Java 到 Go,Python 到 Rust),同时保持业务逻辑和代码风格的一致性。
- 适用场景:技术栈迁移、学习新语言时对照参考。
- 推荐理由:它不仅仅是逐行翻译,而是理解语言惯用法,生成"地道"的目标语言代码。
代码示例:将以下 Python 代码翻译为 Rust:
# Python 源文件:用户服务
from dataclasses import dataclass
from typing import Optional
@dataclass
class User:
id: int
name: str
email: str
age: Optional[int] = None
class UserService:
def __init__(self):
self.users: dict[int, User] = {}
def add_user(self, user: User) -> None:
self.users[user.id] = user
def find_by_age(self, min_age: int) -> list[User]:
return [u for u in self.users.values() if u.age and u.age >= min_age]
Polyglot Bridge 翻译为 Rust:
// Rust 翻译版本:用户服务
use std::collections::HashMap;
#[derive(Debug, Clone)]
struct User {
id: i32,
name: String,
email: String,
age: Option<i32>,
}
impl User {
fn new(id: i32, name: &str, email: &str, age: Option<i32>) -> Self {
User {
id,
name: name.to_string(),
email: email.to_string(),
age,
}
}
}
struct UserService {
users: HashMap<i32, User>,
}
impl UserService {
fn new() -> Self {
UserService {
users: HashMap::new(),
}
}
fn add_user(&mut self, user: User) {
self.users.insert(user.id, user);
}
fn find_by_age(&self, min_age: i32) -> Vec<&User> {
self.users
.values()
.filter(|u| u.age.map_or(false, |age| age >= min_age))
.collect()
}
}
4. 如何安装与配置 Skills?
安装 Skills 通常有两种方式:
-
通过命令行:
# 假设有一个官方或社区的 Skills 市场 claude skills install code-review-pro -
通过配置文件:
在你的项目根目录下的claude.json文件中添加:{ "skills": [ "code-review-pro", "test-architect", "bug-hunter" ] }
配置完成后,在对话中通过特定关键词(如 /review、/test)或自然语言指令即可激活对应的 Skill。
5. 总结与展望
2026年的 Claude Code Skills 生态已经相当成熟,它们不再是锦上添花的功能,而是现代开发者工具箱中不可或缺的一部分。通过合理组合这些 Skills,你可以构建一个属于自己的 AI 开发团队,让 Claude 在代码审查、测试、安全、文档等各个环节为你提供专家级的支持。
建议你从最痛点的领域开始尝试,比如代码审查或测试生成,逐步探索更多可能性。未来,随着 Skills 市场的繁荣,我们甚至可以看到社区贡献的、针对特定框架或业务领域的专用 Skills。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)