
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (6)--- Rollout
0x00 概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
可以把 RL 训练管道划分为如下5 个阶段(会有重叠,依据不同系统而不同),本篇介绍Rollout。
Stage 1 Stage 2 Stage 3 Stage 4 Stage 5
───────── ───────── ───────── ───────── ─────────
Prompt Rollout Reward Advantage Gradient
Selection Generation Scoring Computation Update
"问什么" "怎么答" "打几分" "好了多少" "往哪走"
0x01 Rollout基础
Rollout = 用策略在环境中执行并产生轨迹 τ = (s₀, a₀, r₀, ..., sₜ, aₜ, rₜ)。
1.1 概念
在 RL 框架中,"rollout" 这个词同时指代:
- 含义 1: 过程 (动词):"doing a rollout" = 用策略在环境中生成一条轨迹的过程
- 含义 2: 结果 (名词):"the rollout" = 生成出来的那条轨迹数据,包含: tokens, log_probs, reward, loss_mask 等。
在Slime代码中,generate_rollout_openclaw()函数名用的是含义 1(执行rollout过程),返回的 RolloutFnTrainOutput(samples=...)是含义2(rollout的结果数据)。
1.1.1 标准 RL
Rollout = 在环境中执行策略,产生一条完整的交互轨迹(trajectory)。
形式化:
给定策略 π 和环境 E
一次 rollout 产生一条轨迹 τ: τ = (s₀, a₀, r₀, s₁, a₁, r₁, ..., sₜ, aₜ, rₜ)
其中:
s₀ ~ ρ₀ (初始状态,从 prompt 分布采样)
aₜ ~ π(・|sₜ) (策略生成 action)
sₜ₊₁ ~ P (・|sₜ,aₜ) (环境转移)
rₜ = R (sₜ, aₜ) (环境给出奖励)
1.1.2 LLM RL
在 LLM RL 中,Rollout = 给定一个 prompt, 模型生成一个完整 response + 记录 log-probs + 打分。当然,也有人这么归纳:一次 rollout = 给定一个 prompt, 模型生成一个完整 response
s₀ = prompt (初始状态)
a₀, a₁, ..., aₜ = response 的每个 token (一系列 action)
r = 对整个 response 的打分 (terminal reward)
轨迹 τ = (prompt, token₁, token₂, ..., tokenₜ, reward)
注意: LLM 的 rollout 通常是 single-step episode (一轮就结束), 不像游戏有多步交互。
1.1.3 GPRO
一个 GRPO rollout batch:
- 采样 B 个 prompt
- 每个 prompt 生成 N 个 response
- 总共 B × N 条轨迹
每条轨迹包含:
- prompt (input)
- response tokens (actions)
- log π_old (a_t | s_t) (旧策略的 log-probs, 用于后续 PPO ratio 计算)
- reward (打分)
1.1.4 OpenClaw-RL
OpenClaw 的 "rollout"的特点:
- 不主动生成
- 等用户对话 → 从 queue 收集
- 凑够 rollout_batch_size 个样本 = 一次 "rollout"
每条轨迹包括:
- prompt = 用户消息 (s₀)
- response = 模型回复 (a₀...aₜ)
- rollout_log_probs = SGLang 生成时记录的 log π_old (用于 PPO ratio)
- reward = PRM 评分
- (OPD) teacher_log_probs = teacher 的 log-probs
主动和被动的对比如下。
标准 RL Rollout:
────────────────────────────────────────────────
dataset = load ("math_data.jsonl")
for prompt in dataset.sample (batch_size): ← 主动选题
responses = model.generate (prompt, n=4) ← 主动生成 N 个
for resp in responses:
score = reward_model (resp)
submit (prompt, resp, score)
OpenClaw Rollout:
────────────────────────────────────────────────
@openclaw_rollout.py
def generate_rollout_openclaw (...):
worker.resume_submission () ← 打开阀门
while len (data) < rollout_batch_size:
data += queue.get() ← 等!等用户发消息
await asyncio.sleep(0.05) ← 继续等...
worker.pause_submission () ← 关阀门
return data
# 数据从哪来?从 API Server 的请求处理流程来
# rollout 函数本身不生成任何数据!
具体可以参见下表
| 标准 | OpenClaw | |
|---|---|---|
| 谁控制prompt? | 训练系统 | 用户 |
| 谁控制N? | 训练系统(n=4~16) | 用户(永远n=1) |
| 数据到达时间 | 确定的(GPU生成速度) | 不确定的(等用户) |
| --disable-rollout-global-dataset | 不需要 | 必须(没有dataset) |
1.2 RL2 对比
我们用 RL2 这个框架来做对比,看看它是怎么做rollout的。
RL2 的本质架构为:在同一组 GPU 上交替做推理和训练。或者说,RL2 = 一个on-policy RL循环,把LLM当policy network,把推理服务器当采样器。
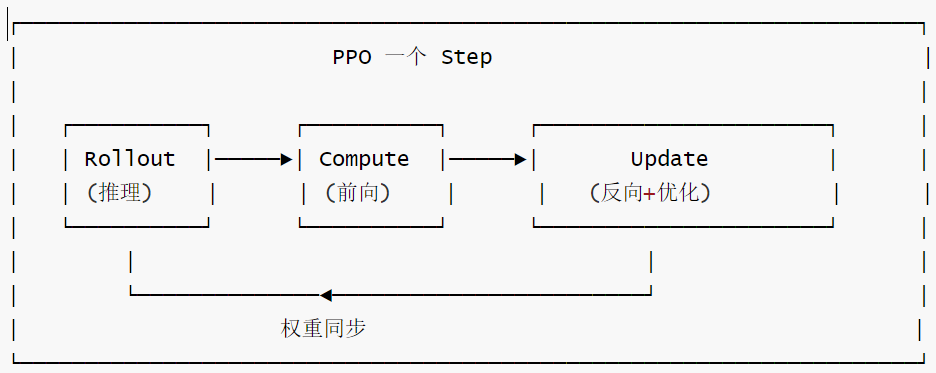
展开核心数据流如下:
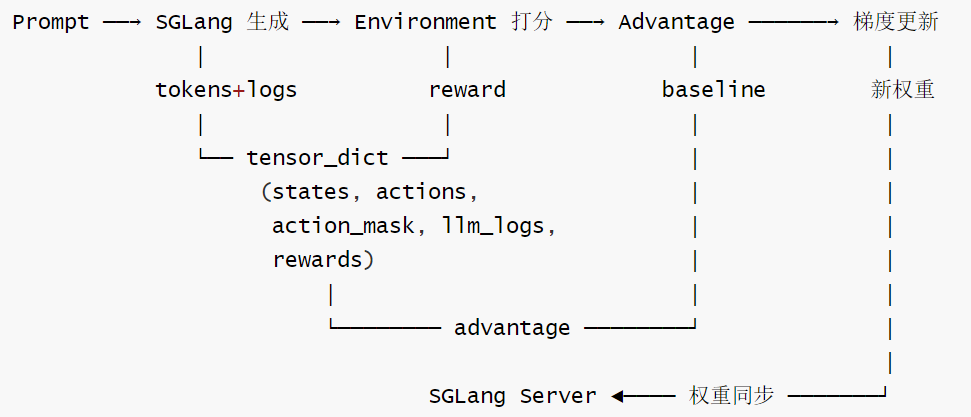
三个核心子系统及其职责:
- Rollout = SGLang推理 + 环境交互 → 产出(token序列,reward)
- Actor/Critic = FSDP分布式模型 → 计算logps/values → 反向传播
- Environment = env_step(action)→ reward(规则/外部API/LLM judge)
注意:
- Reward 不是独立模块—它集成在 env_step 内,实现方式完全灵活(规则/外部服务/LLM judge)
- PRM 可通过多轮环境实现—每个 step 返回中间 reward,累加到轨迹中
- 整个 Rollout 是异步的—SampleGroup 并发、env_step 可调外部网络、SGLang 请求并发
- 所有组件共享同一组 GPU—通过 offload + memory occupation 管理实现时分复用
0x02 OpenClaw-RL Rollout基础
在 OpenClaw-RL 中,Rollout 是Policy Serving + Environment 的交叉。
Rollout = 在环境中执行策略,生成完整轨迹的过程 = Policy的推理输出 × Environment的状态转移
Rollout的完整循环如下:
Environment 提供 State(t)(用户消息)
↓
Policy Serving 执行推理 → Action(t)(模型回复)
↓
Environment 接收 Action(t) → Environment 提供 State(t+1)(用户下一条消息)
↓
重复,直到 session 结束
2.1 硬件架构
在 OpenClaw-RL 的硬件架构中,GPU 4-5 的名称是 "SGLang Rollout Engine"。但它实际负责的是 rollout 的 Policy Serving 侧:
- → 接收 HTTP 请求(用户消息)
- → 运行 LLM 推理,生成 token
- → 返回模型回复
rollout 的 Environment 侧(用户行为)在 GPU 之外:
- → 用户什么时候发消息? → 外部世界决定
- → 用户发什么内容? → 外部世界决定
- → 用户是否继续对话? → 外部世界决定
┌──────────────────────────────────────────────────────────────┐
│ Rollout(概念上) │
│ │
│ ┌─────────────────┐ ┌───────────────────────┐ │
│ │ Policy Serving │ │ Environment │ │
│ │ GPU 4-5 │ + │ 真实用户(外部) │ │
│ │ LLM 推理生成回复 │ │ 提供 state、接收 action │ │
│ └─────────────────┘ └───────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────┘
2.2 总体模块交互架构图
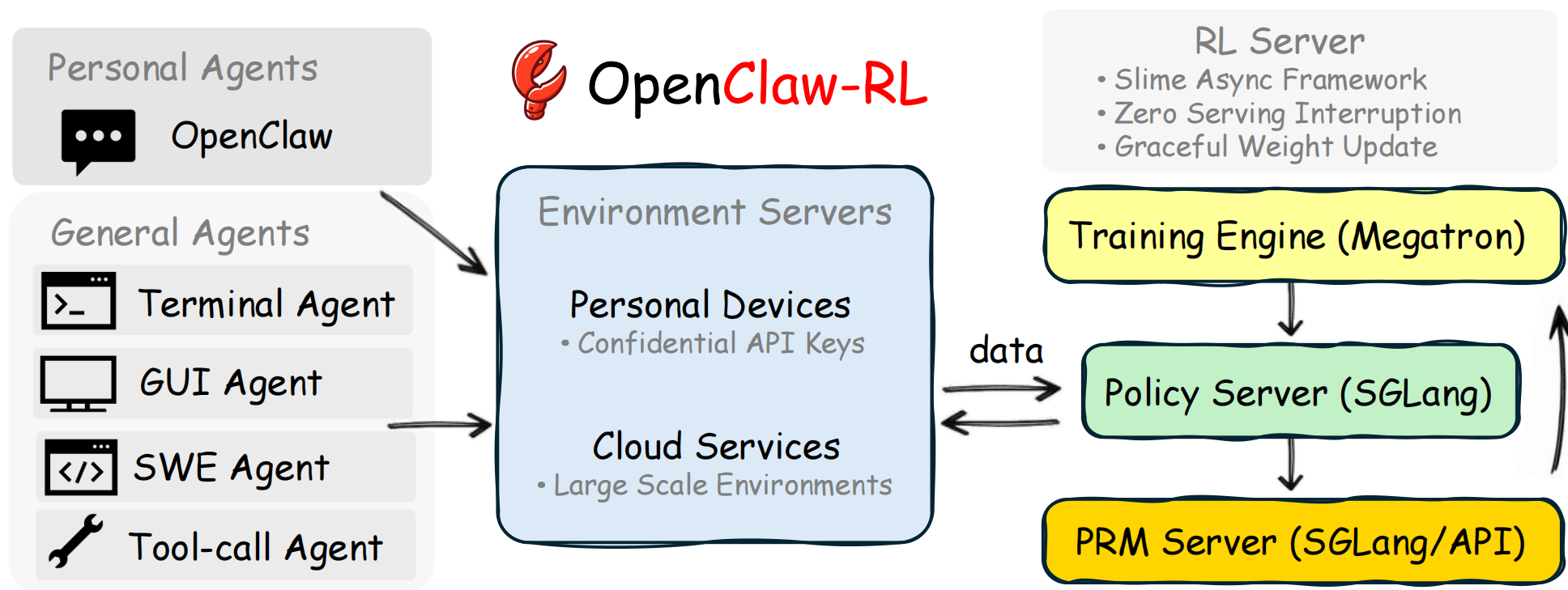
OpenClaw-RL 总体模块交互架构图 (Combine 方法) 如下,可以从中找到Rollout相关内容。

2.3 Slime 的 RolloutFunction 封装
在代码层面,Slime用一个函数封装了rollout的全部逻辑:
# openclaw-rl/openclaw_rollout.py
def generate_rollout_openclaw(args, rollout_id, data_buffer, evaluation=False):
"""
Slime 的 rollout function:
标准rollout(主动生成):
rollout_engine.generate(prompts) → 直接调LLM生成轨迹
= Policy Serving(GPU4-5)自己完成整个rollout
Environment是静态的(题目数据集)
OpenClaw的被动rollout:
等待_sample_queue.get()→ 从真实用户对话中取已完成的轨迹
= PolicyServing已经完成了(对话已结束)
= Environment已经交互过了(用户消息已收到)
这里只是“收集“已经发生的rollout
"""
while len(samples) < batch_size:
sample=_sample_queue.get(block=True)#被动等待
return samples
-disable-rollout-global-dataset的含义就是:
- 告诉Slime:“不需要你主动用LLM生成rollout"
- "我的rollout由真实用户+Policy Serving联合产生,你只管拿已完成的样本“
具体如下图。
Slime 训练框架调用: generate_rollout_openclaw(args, rollout_id, data_buffer)
|
| passive rollout:
| 不主动生成, 等待真实对话产生数据
▼
+---------------------------------------+
| worker.resume_submission() | <- 开启 submission_enabled Event
| _drain_output_queue() | <- 等待 rollout_batch_size=16 组
+---------------------------------------+
|
|
▼
(数据由异步 FastAPI handler 填入)
2.4 被动Rollout
OpenClaw-RL的rollout是被动rollout。generate_rollout_openclaw()等待真实用户发消息,而非主动从prompt池中选择问题生成回答。这意味着系统对rollout allocation(选什么问题训练)几乎没有控制权,由用户决定。
优势:
- 训练数据 = 真实用户对话,天然分布对齐,无train-deploy distribution gap
- 用户多样性天然提供entropy保障和batch内reward方差
- 无需维护prompt数据集
劣势:
- 无法做curriculum learning(由简到难)
- 无法增大group size G(每turn只有一条用户消息)
- 无法做dynamic sampling(不能要求用户“换个问题再问")
- Rollout allocation 几乎完全失控
2.5 小结
- 概念上:Rollout = PolicyServing + Environment 两者的交互过程,不专属任何一方
- 架构上:GPU 4-5标记为“Rollout Engine",但只承担了Policy Serving(推理)侧的工作
- 代码上:generate_rollout_openclaw是被动收集器,真正的rollout在FastAPI服务器处理用户请求时已经完成
0x03 OpenClaw-RL Rollout 实现
3.1 Rollout 完整流程


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)