
AI Agent 的四大组成部分详解
从 LLM 到自主行动,拆解智能体的核心架构
目录
3.1 组成部分总览
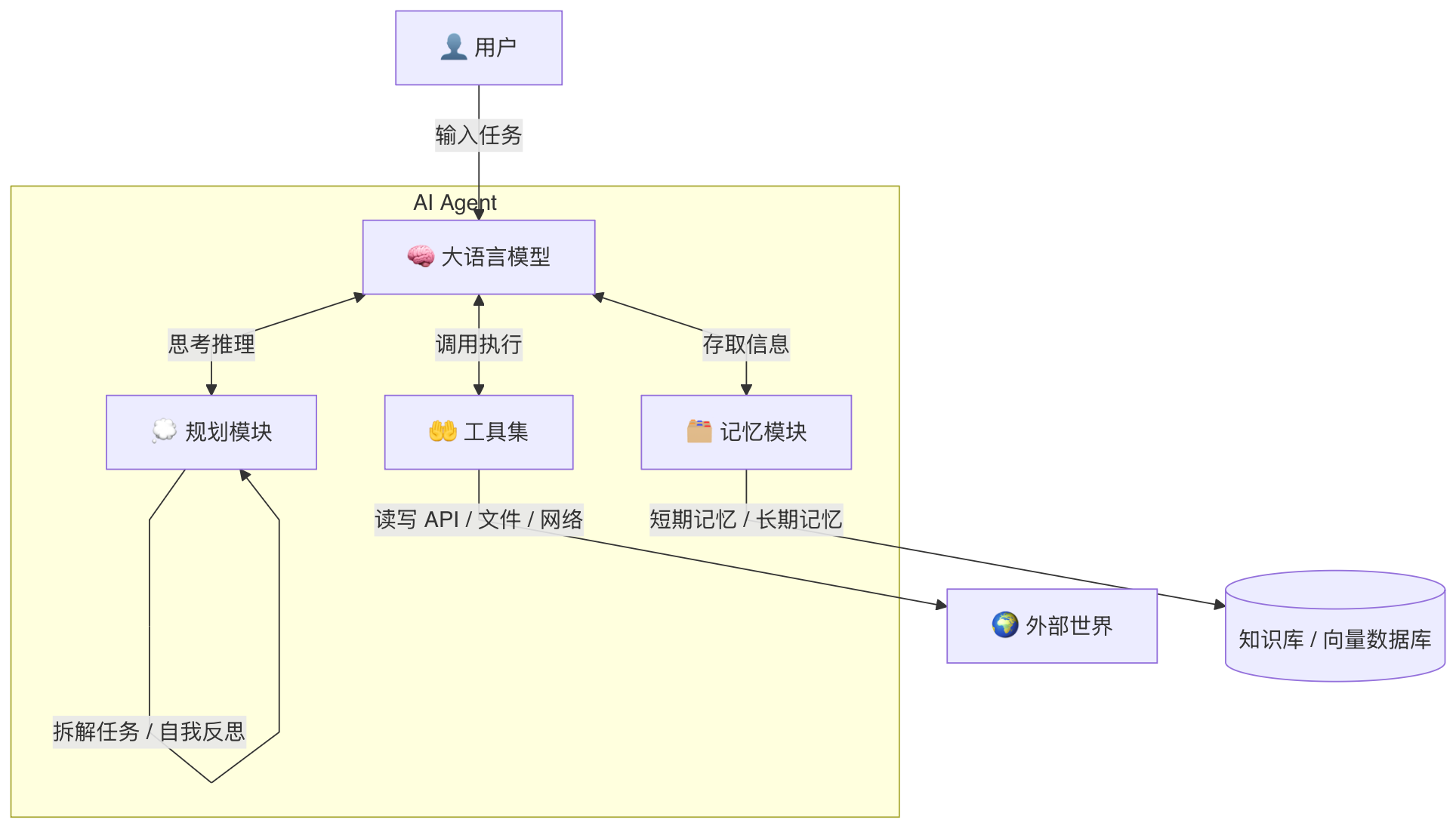
如果把一个 AI Agent 比作一个人,那么它的四大组成部分对应着人的四项核心能力:
| 组成部分 | 类比 | 核心职责 |
|---|---|---|
| 大语言模型(LLM) | 🧠 大脑 | 理解、推理、生成语言 |
| 规划模块(Planning) | 💭 思维 | 拆解任务、制定策略、反思调整 |
| 记忆模块(Memory) | 🗂️ 记忆 | 存储上下文、检索历史、积累经验 |
| 工具集(Tools) | 🤲 双手 | 与外部世界交互、执行具体操作 |
这四大模块协同工作,让 Agent 从"只会聊天"的模型,进化为"能自主完成复杂任务"的智能体。下面我们逐一深入。
3.2 组成部分一:大语言模型
作用与地位
大语言模型是 Agent 的核心引擎。它负责:
-
理解用户意图:将自然语言指令解析为可执行的任务目标。
-
推理与决策:基于上下文信息,判断下一步该做什么。
-
生成输出:产出文本、代码、计划、回复等。
一句话概括:没有 LLM,Agent 就失去了"智能"的来源。LLM 决定了 Agent 的智力上限,其他三个模块是让这份智力"落地"的放大器。
当前主流选择
截至 2026 年,构建 Agent 的主流 LLM 选型如下:
| 模型 | 提供商 | 特点 | 适用场景 |
|---|---|---|---|
| Claude (Opus / Sonnet) | Anthropic | 强推理、长上下文(200K)、工具使用出色、安全性高 | 复杂推理任务、代码生成、企业级 Agent |
| GPT-4o / GPT-5 | OpenAI | 多模态、生态成熟、插件丰富 | 通用 Agent、多模态任务 |
| Gemini 2.5 Pro | 原生多模态、超长上下文(1M+)、高性价比 | 大规模文档分析、多模态 Agent | |
| DeepSeek-V3 / R1 | DeepSeek | 开源、推理能力强、成本低 | 自部署 Agent、研究场景 |
| Qwen3 / Llama 4 | 阿里 / Meta | 开源可定制、本地部署 | 私有化部署、数据敏感场景 |
选型建议:
-
追求最强推理 + 工具使用:Claude Opus / Sonnet
-
需要多模态能力:GPT-5 或 Gemini
-
需要私有化部署 + 成本控制:DeepSeek 或 Qwen
实际代码示例
以下是一个使用 LLM 构建 Agent 的简单示例(以 Anthropic SDK 为例):
import anthropic
client = anthropic.Anthropic()
# 定义 Agent 的系统提示词
system_prompt = """你是一个智能助手 Agent。你有以下能力:
1. 分析用户需求
2. 制定执行计划
3. 调用工具完成任务
4. 根据结果调整策略
请始终先思考,再行动。"""
# Agent 主循环
def agent_run(user_task: str, tools: list[dict], max_steps: int = 10):
messages = [{"role": "user", "content": user_task}]
for step in range(max_steps):
response = client.messages.create(
model="claude-sonnet-4-6",
system=system_prompt,
messages=messages,
tools=tools,
max_tokens=4096,
)
# 处理工具调用
if response.stop_reason == "tool_use":
for block in response.content:
if block.type == "tool_use":
# 执行工具,将结果返回给 LLM
tool_result = execute_tool(block.name, block.input)
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": block.id,
"content": tool_result,
}]
})
else:
# 任务完成,返回最终结果
return response.content[0].text
return "达到最大步数限制"3.3 组成部分二:规划模块
为什么需要规划?
试想一下:你让 Agent "帮我做一个电商网站"。如果 Agent 没有规划能力,它可能会直接开始写 HTML 代码——结果大概率是一团糟。
规划模块让 Agent 能够:
-
拆解复杂任务:将宏大目标分解为可执行的子任务。
-
制定执行顺序:确定先做什么、后做什么、哪些可以并行。
-
动态调整:执行中遇到问题,能够重新规划。
-
自我反思:检查已完成的步骤,发现遗漏或错误。
规划是区分"初级 Agent"和"高级 Agent"的关键分水岭。
两种主流规划方法
方法一:ReAct(Reasoning + Acting)
核心思想:思考(Thought)→ 行动(Action)→ 观察(Observation),循环迭代。
Thought: 我需要先了解项目结构 Action: 执行 ls 命令 Observation: 看到 src/, tests/, README.md Thought: 项目有 src 目录,我先看看里面的文件 Action: 执行 ls src/ Observation: 看到 main.py, utils.py, config.py Thought: main.py 是入口,我先读它 Action: 读取 src/main.py ...
优点:简单直观、易于实现、每个步骤可追踪。 缺点:缺乏全局规划,容易"走一步看一步"陷入局部最优。
代码示例:
def react_agent(task: str, tools: dict, max_steps: int = 10):
context = f"任务: {task}\n"
for step in range(max_steps):
# 1. 思考
thought = llm_think(context)
context += f"\nThought {step+1}: {thought}"
# 2. 行动
action = llm_decide_action(context, tools)
context += f"\nAction {step+1}: {action}"
# 3. 观察
observation = execute_action(action, tools)
context += f"\nObservation {step+1}: {observation}"
# 4. 判断是否完成
if llm_should_finish(context):
return llm_generate_answer(context)
return "未能在步数限制内完成任务"方法二:Plan-and-Solve(先规划再执行)
核心思想:先制定完整计划,再逐步执行,执行过程中可以修正。
Step 1: 生成整体计划 ├── 1.1 了解项目结构和依赖 ├── 1.2 设计数据库模型 ├── 1.3 实现 API 接口 ├── 1.4 编写前端页面 └── 1.5 集成测试 Step 2: 按计划执行 执行 1.1... 发现问题:缺少配置文件 → 修正计划:在 1.1 之后插入 "创建配置文件" Step 3: 执行过程中持续反思 检查点:每个子任务完成后验证结果
优点:全局视角、效率更高、减少无效探索。 缺点:初始计划可能不准确,需要较强的 LLM 推理能力。
代码示例:
def plan_and_solve_agent(task: str, tools: dict):
# 阶段一:制定计划
plan = llm_create_plan(task)
print(f"📋 初始计划:\n{plan}")
results = []
for i, step in enumerate(plan.steps):
# 阶段二:执行当前步骤
result = execute_step(step, tools)
results.append(result)
# 阶段三:反思与调整
if not result.success:
print(f"⚠️ 步骤 {i+1} 失败: {result.error}")
revised = llm_revise_plan(plan, results, i)
if revised.needs_change:
plan = revised.new_plan
print(f"🔄 计划已更新:\n{plan}")
# 阶段四:检查点验证
if step.has_checkpoint:
llm_verify_results(results[:i+1], task)
return llm_summarize(results, task)实际代码对比
| 维度 | ReAct | Plan-and-Solve |
|---|---|---|
| 规划方式 | 边想边做 | 先规划再执行 |
| 灵活性 | ⭐⭐⭐⭐⭐ 极高 | ⭐⭐⭐ 中等 |
| 效率 | ⭐⭐⭐ 可能绕路 | ⭐⭐⭐⭐ 路径更短 |
| 可解释性 | ⭐⭐⭐⭐ 每步可追踪 | ⭐⭐⭐⭐⭐ 计划清晰 |
| 适用场景 | 探索性任务、信息检索 | 工程实现、多步骤项目 |
| Token 消耗 | 较高(多轮思考) | 中等(计划可复用) |
选择建议
你的任务是探索性的、不确定的? └── 是 → 用 ReAct(灵活应变) └── 否 → 你的任务步骤清晰、目标明确? └── 是 → 用 Plan-and-Solve(高效执行) └── 否 → 混合使用:先制定粗略计划,执行中用 ReAct 调整
最佳实践:现代高级 Agent(如 Claude Code)通常采用混合模式——先用 Plan-and-Solve 制定总体方案,在具体执行每个子任务时切换到 ReAct 模式灵活应对。
3.4 组成部分三:记忆模块
为什么记忆很重要?
没有记忆的 Agent 就像"金鱼脑":
-
🚫 对话一长就忘记之前说过什么
-
🚫 每次都要从头理解用户背景
-
🚫 无法从过去的错误中学习
-
🚫 换个对话窗口就完全失忆
记忆模块让 Agent 能够跨越时间和对话,保持连贯的"认知"。
短期记忆(Short-term Memory)
定义:当前对话窗口内的上下文信息。
实现方式:
-
对话历史:将最近的用户消息和 Agent 回复拼接在 prompt 中
-
滑动窗口:当对话过长时,保留最近 N 轮,旧的被遗忘
-
上下文压缩:对历史对话做摘要,用摘要替代原文
class ShortTermMemory:
def __init__(self, max_tokens: int = 8000):
self.messages = []
self.max_tokens = max_tokens
def add(self, role: str, content: str):
self.messages.append({"role": role, "content": content})
# 超出限制时自动压缩
while self._estimate_tokens() > self.max_tokens:
self._summarize_oldest()
def _summarize_oldest(self):
"""将最早的几轮对话压缩为摘要"""
old_msgs = self.messages[:4]
summary = llm_summarize(old_msgs)
self.messages = [
{"role": "system", "content": f"[早期对话摘要] {summary}"}
] + self.messages[4:]
def get_context(self) -> list[dict]:
return self.messages长期记忆(Long-term Memory)
定义:跨对话、持久化的知识存储。
实现方式:
| 方式 | 原理 | 适用场景 |
|---|---|---|
| 向量数据库 | 将文本转为向量,按语义相似度检索 | 知识库、文档问答 |
| 知识图谱 | 用实体-关系-实体三元组存储 | 复杂关系推理 |
| 结构化存储 | 用户画像、偏好设置存数据库 | 个性化、配置管理 |
| 文件系统 | 将关键信息写入文件持久化 | 简单项目、个人助手 |
import chromadb
from chromadb.utils import embedding_functions
class LongTermMemory:
def __init__(self):
self.client = chromadb.PersistentClient(path="./agent_memory")
self.ef = embedding_functions.DefaultEmbeddingFunction()
self.collection = self.client.get_or_create_collection(
name="knowledge_base",
embedding_function=self.ef,
)
def remember(self, content: str, metadata: dict = None):
"""存入长期记忆"""
doc_id = f"mem_{hash(content)}"
self.collection.add(
documents=[content],
metadatas=[metadata or {}],
ids=[doc_id],
)
def recall(self, query: str, top_k: int = 5) -> list[str]:
"""检索相关记忆"""
results = self.collection.query(
query_texts=[query],
n_results=top_k,
)
return results["documents"][0] if results["documents"] else []
def forget(self, doc_id: str):
"""删除记忆"""
self.collection.delete(ids=[doc_id])记忆架构图
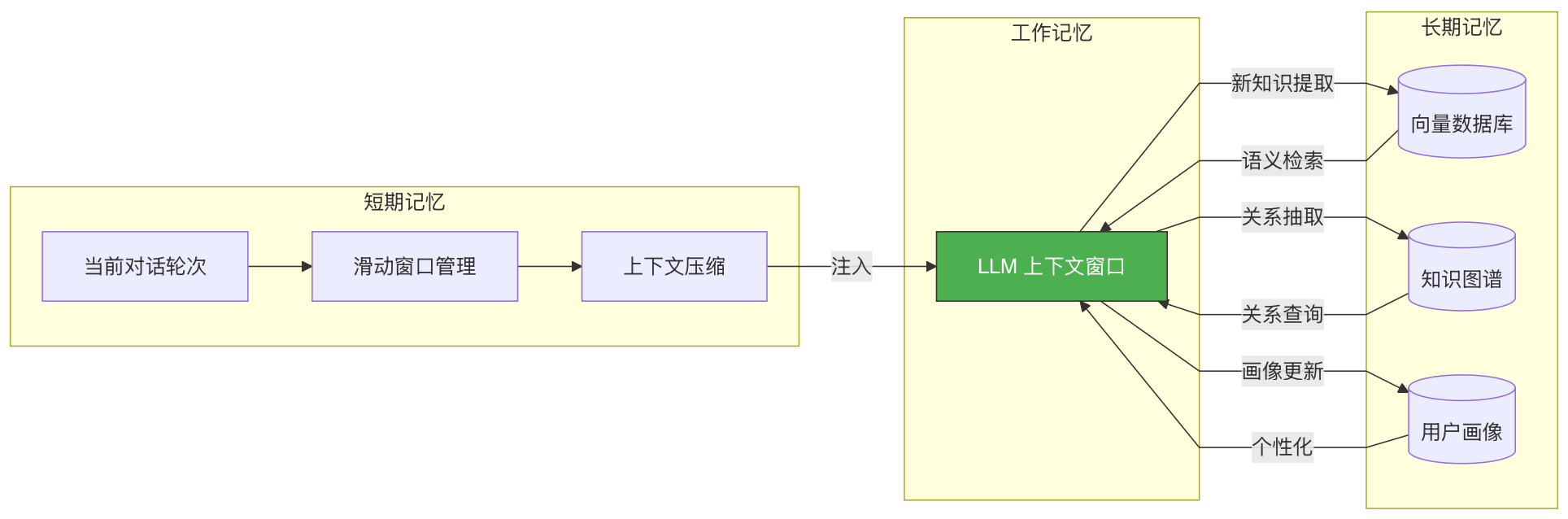
工作记忆是短期记忆和长期记忆的交汇点——它决定了 LLM 在当前推理中能"看到"什么信息。
记忆模块的高级技巧
1. 反思式记忆(Reflective Memory)
不只是存储事实,还存储"反思"——从经验中提炼的教训:
def reflective_memorize(experience: dict):
# 存储原始经历
memory.store("experience", experience)
# 让 LLM 反思并提炼教训
reflection = llm_reflect(f"""
经历:{experience}
请反思:
1. 做了什么?结果如何?
2. 哪里做得好?哪里可以改进?
3. 下次遇到类似情况,应该怎么做?
""")
# 存储反思(比原始数据更有价值)
memory.store("reflection", reflection, tags=["lesson", "improvement"])2. 重要性加权记忆
不是所有记忆都同等重要。给记忆打分,优先保留重要信息:
def importance_weighted_store(content: str):
# 让 LLM 评估这段信息的重要性(1-10)
score = llm_score_importance(content)
if score >= 8:
memory.store_detail(content) # 完整存储
elif score >= 5:
memory.store_summarized(content) # 摘要存储
else:
memory.maybe_store(content) # 概率性存储3. 记忆的遗忘曲线
模拟人脑的艾宾浩斯遗忘曲线,让 Agent 的记忆管理更"人性化":
def recall_with_decay(memory_id: str, current_time: float):
mem = memory.get(memory_id)
elapsed = current_time - mem.last_accessed
# 艾宾浩斯遗忘曲线近似
retention = math.exp(-elapsed / mem.halflife)
if retention < 0.1:
memory.archive(memory_id) # 归档,不再主动使用
return None
# 刷新最后访问时间
memory.touch(memory_id)
return mem.content3.5 组成部分四:工具集
工具是 Agent 的「超能力」
LLM 本身只能生成文本。它不能:
-
❌ 读取文件
-
❌ 执行代码
-
❌ 搜索互联网
-
❌ 调用 API
-
❌ 操作数据库
工具(Tools) 赋予了 Agent 与外部世界交互的能力,让它从"只能聊"进化为"能做事"。
工具的定义与实现
一个工具通常包含三个要素:
from typing import Any, Callable
from dataclasses import dataclass
@dataclass
class Tool:
"""Agent 工具的标准化定义"""
name: str # 工具名称(LLM 用它来识别)
description: str # 功能描述(帮助 LLM 判断何时使用)
parameters: dict # 参数 JSON Schema
function: Callable[..., Any] # 实际执行函数以 Anthropic SDK 的 tool use 格式为例:
tools = [
{
"name": "read_file",
"description": "读取指定路径的文件内容",
"input_schema": {
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "文件的绝对路径"
},
"encoding": {
"type": "string",
"default": "utf-8",
"description": "文件编码格式"
}
},
"required": ["file_path"]
}
},
{
"name": "web_search",
"description": "在互联网上搜索信息,返回相关结果列表",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
},
"num_results": {
"type": "integer",
"default": 5,
"description": "返回结果数量"
}
},
"required": ["query"]
}
}
]常用工具类型与实现
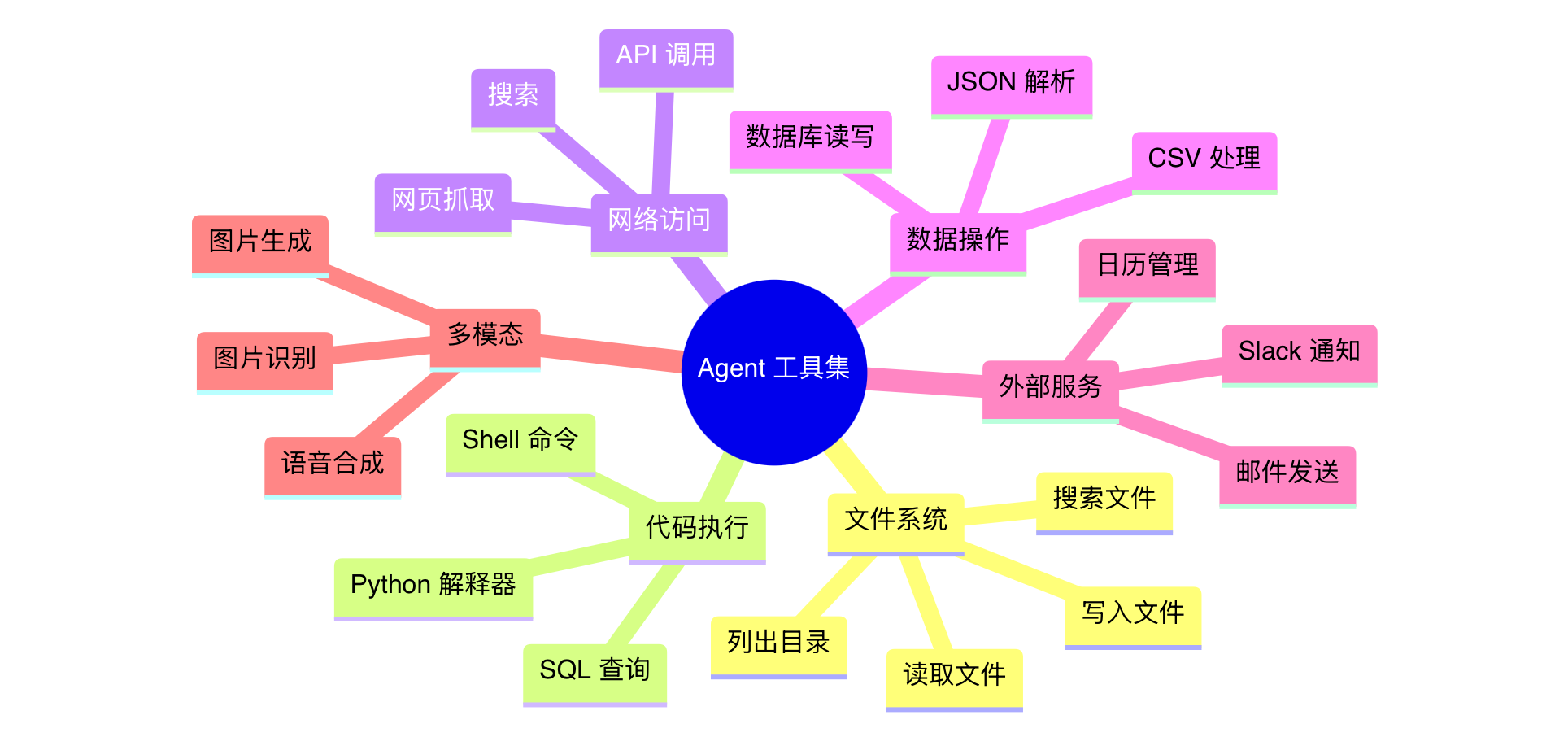
Agent 工具集文件系统代码执行网络访问数据操作外部服务多模态读取文件写入文件搜索文件列出目录Python 解释器Shell 命令SQL 查询网页抓取API 调用搜索数据库读写JSON 解析CSV 处理邮件发送日历管理Slack 通知图片生成图片识别语音合成
代码执行工具
import subprocess
import tempfile
def execute_python(code: str, timeout: int = 30) -> dict:
"""在沙箱中执行 Python 代码"""
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
tmp_path = f.name
try:
result = subprocess.run(
["python3", tmp_path],
capture_output=True,
text=True,
timeout=timeout,
)
return {
"stdout": result.stdout,
"stderr": result.stderr,
"exit_code": result.returncode,
}
except subprocess.TimeoutExpired:
return {"error": f"执行超时(>{timeout}秒)"}
finally:
os.unlink(tmp_path)API 调用工具
import subprocess
import tempfile
def execute_python(code: str, timeout: int = 30) -> dict:
"""在沙箱中执行 Python 代码"""
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
tmp_path = f.name
try:
result = subprocess.run(
["python3", tmp_path],
capture_output=True,
text=True,
timeout=timeout,
)
return {
"stdout": result.stdout,
"stderr": result.stderr,
"exit_code": result.returncode,
}
except subprocess.TimeoutExpired:
return {"error": f"执行超时(>{timeout}秒)"}
finally:
os.unlink(tmp_path)工具组合的实际案例
以下是一个研究助手 Agent 的工具组合示例——展示了多个工具如何协作完成一个复杂任务:
# 场景:用户问 "帮我调研一下 2025 年 AI Agent 框架的最新进展"
# Agent 自动组合多个工具完成任务:
research_flow = [
# Step 1: 搜索
ToolCall("web_search", {"query": "AI Agent framework 2025 top tools"}),
ToolCall("web_search", {"query": "LangGraph CrewAI AutoGen 2025 comparison"}),
# Step 2: 读取搜索结果,筛选高质量来源
ToolCall("web_fetch", {"url": "https://example.com/agent-comparison-2025"}),
ToolCall("web_fetch", {"url": "https://github.com/langchain-ai/langgraph"}),
# Step 3: 本地整理和分析
ToolCall("write_file", {"path": "/research/raw_notes.md", "content": "..."}),
ToolCall("execute_python", {"code": """
# 用代码分析 GitHub star 趋势
import requests
repos = ['langgraph', 'crewAI', 'AutoGen']
for repo in repos:
data = requests.get(f'https://api.github.com/repos/{repo}').json()
print(f"{repo}: {data['stargazers_count']} stars")
"""}),
# Step 4: 生成最终报告
ToolCall("write_file", {"path": "/research/report.md", "content": "..."}),
]工具使用的最佳实践
1. 工具描述要精确
# ❌ 糟糕的描述
"description": "搜索东西"
# ✅ 优秀的描述
"description": "在互联网上执行关键词搜索,返回标题、URL 和摘要列表。"
"当你需要查找最新信息、事实核查、或获取训练数据截止日期之后的"
"信息时使用此工具。不要用于数学计算或代码执行。"2. 错误处理要优雅
def safe_tool_execute(tool_name: str, params: dict) -> str:
"""统一的工具执行错误处理"""
try:
result = tool_registry[tool_name](**params)
return json.dumps({"success": True, "data": result})
except FileNotFoundError as e:
return json.dumps({"success": False, "error": f"文件不存在: {e}"})
except PermissionError as e:
return json.dumps({"success": False, "error": f"权限不足: {e}"})
except Exception as e:
return json.dumps({"success": False, "error": f"未知错误: {e}"})⚠️ 关键原则:即使工具执行失败,也要返回结构化的错误信息,而不是让 LLM 去"猜测"发生了什么。LLM 看到错误信息后可以自动调整策略,这是 Agent 鲁棒性的核心。
3. 控制工具权限范围
# 生产环境中应该限制工具的能力范围
tools_config = {
"read_file": {"allowed_paths": ["/project/"], "max_size_mb": 10},
"write_file": {"allowed_paths": ["/project/output/"], "require_confirm": True},
"execute_bash": {"allowed_commands": ["ls", "cat", "grep", "find"], "block_network": True},
"web_fetch": {"allowed_domains": ["github.com", "docs.python.org", "wikipedia.org"]},
}4. 避免工具循环
❌ 问题场景: LLM 调用 search → 结果不理想 → 再次 search → 还是不行 → 继续 search → ... ✅ 解决方案: 1. 设置单任务最大工具调用次数(如 25 次) 2. 检测重复调用:连续 3 次相同工具 + 相似参数 → 提示 LLM 换策略 3. 设置思考超时:如果 Agent 陷入循环,自动注入 "请总结当前已获得的信息,尝试新方法"
总结
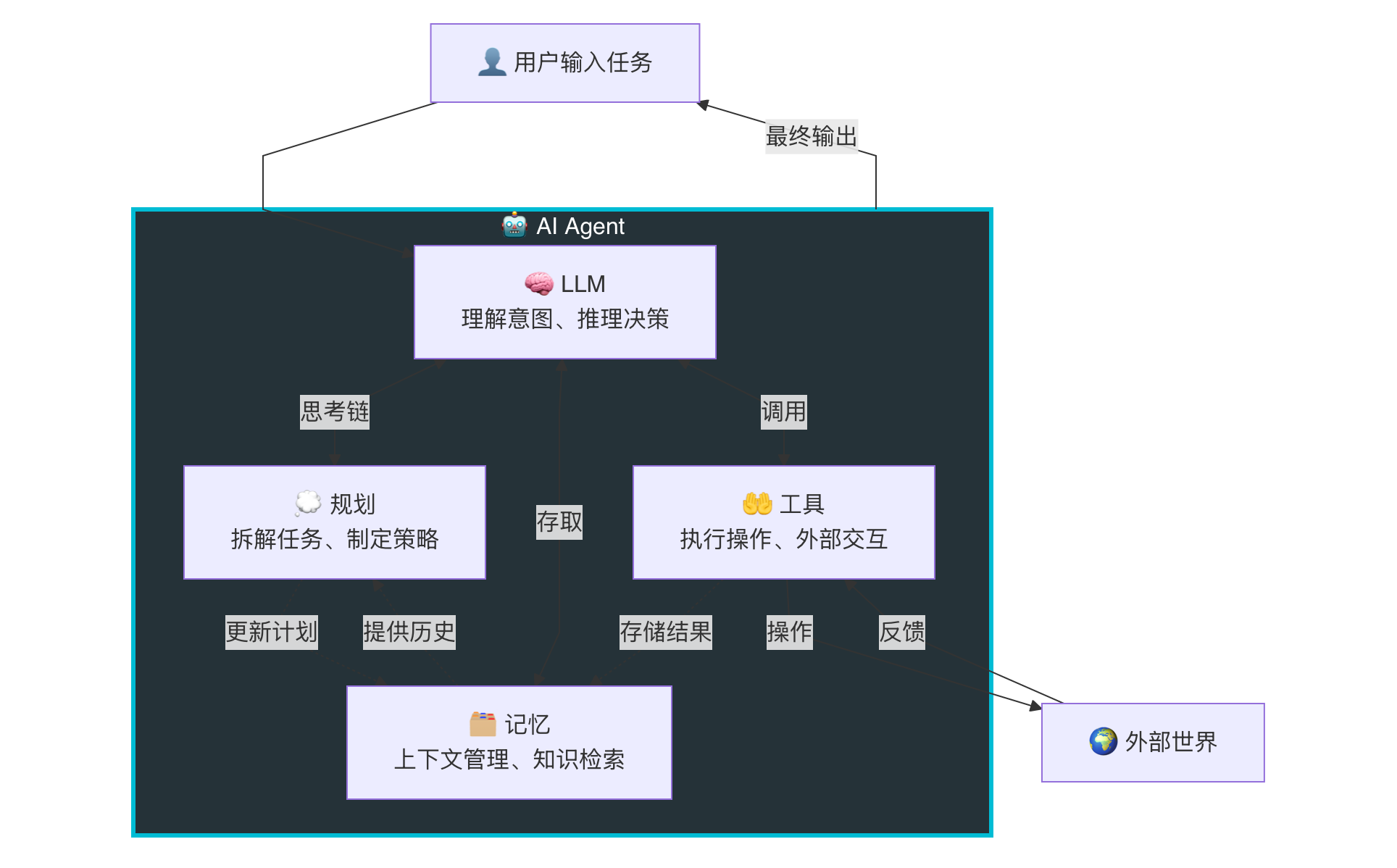
AI Agent 的四大组成部分相辅相成,构成了一个完整的智能体系:
| 组成部分 | 一句话总结 | 关键能力 |
|---|---|---|
| LLM | Agent 的"大脑" | 理解、推理、生成 |
| 规划 | Agent 的"思维" | 拆解、排序、反思、调整 |
| 记忆 | Agent 的"经验" | 短期上下文 + 长期知识库 |
| 工具 | Agent 的"双手" | 读写文件、执行代码、搜索、调用 API |
最后的建议:构建 Agent 时,不要试图一步到位。推荐的演进路径是:
-
起步:LLM + 1-2 个基础工具(读写文件)
-
增强:加入短期记忆,支持多轮对话
-
进阶:引入 ReAct 规划,支持复杂任务
-
成熟:添加长期记忆(向量数据库)+ Plan-and-Solve
-
卓越:反思机制 + 记忆优化 + 工具生态
每一层的加入都让 Agent 的能力产生质的飞跃。关键是根据你的场景选择合适的复杂度——过度设计一个简单场景的 Agent 和低配一个复杂场景的 Agent,都是资源的浪费。
本文适合对 AI Agent 有一定了解、希望深入理解其内部架构的开发者阅读。如果你正在构建自己的 Agent 系统,希望这篇文章能帮助你做出更清晰的架构决策。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)