
最早的起点:对话式 AI 只能解决局部问题
最开始可用的 AI 主要是对话式工具。当时,一些代码补全类和对话式 AI 工具已经能够协助处理一些局部工作,比如转换一些代码片段,或者处理行数较少的文件。即便能力还比较有限,也已经和早期“刀耕火种”的方式有了明显区别。一个很直接的感受就是:用起来确实爽,而且效率和正确率都有了明显提升。
这个阶段的重点主要还是调提示词,尽量提高转换的准确率。但对我来说,更重要的收获其实是建立了信心:AI 的确有能力把“转代码”这件事做好。这也为后面的多轮优化打下了基础。
从 Prompt 到 Skill:AI 开始具备承接完整任务的能力
真正的转折点,出现在具备代码仓库读取、命令执行和任务承接能力的 AI 开发工具开始可用之后。
一方面,不再需要手动把代码片段贴给 AI;这类工具可以在 CLI 环境中自动读取代码、执行 Git 命令,并识别需要转换的范围。另一方面,基于 CLI 的这些能力,也为自动化带来了可能。最初的版本,就是把之前总结好的提示词封装成一个 Slash Command,用起来就更顺手了,只需要打开 CLI 并执行:
/code-converter <commit 信息>
到这里,AI 的角色已经不再只是“帮忙转换代码片段”,而是开始具备了承接整段转换流程的能力。
但我自己用着顺手还不够,关键是要让团队也能顺手用起来。代码转换是每位开发者都会遇到的事情,在验证出一定效果之后,我开始尝试推广。问题也随之出现:由于 Slash Command 没有纳入代码仓库管理,如何让大家始终使用同一份提示词,成了一个实际的落地障碍。
工具形态探索:如何普及代码转换工具
在这个阶段,主要探索的是:怎么让所有人都能顺畅地把这套流程用起来。
最早的一版自动化方案是这样的:
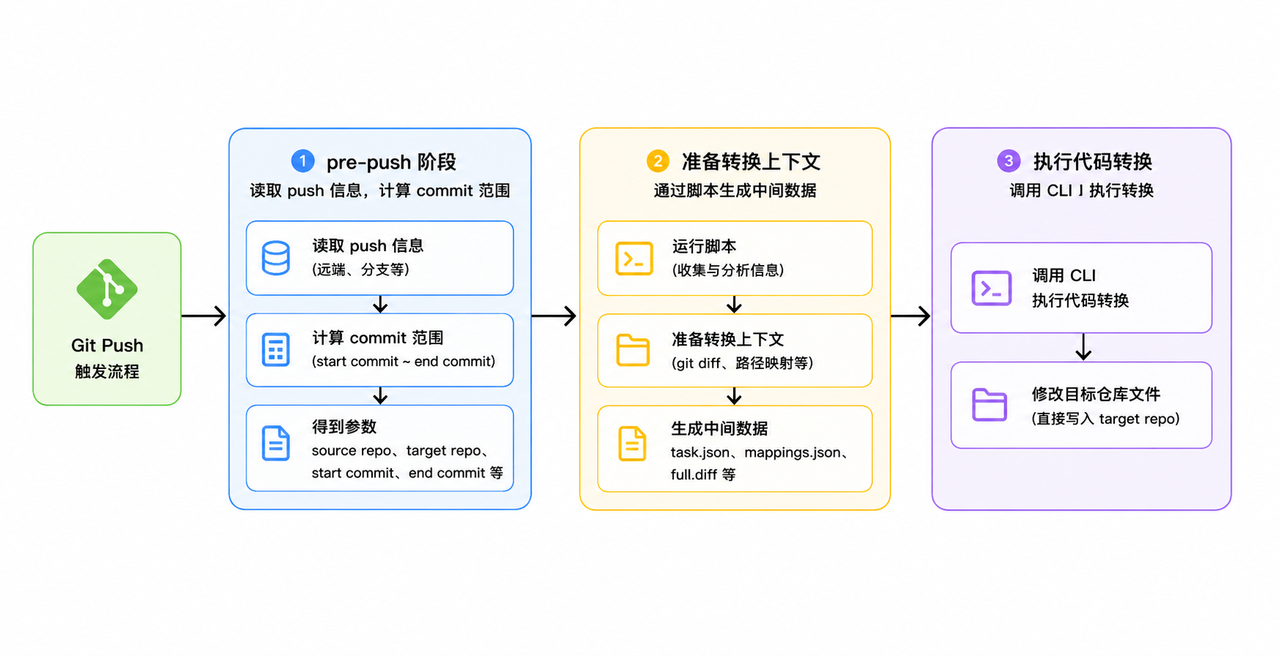
这版方案主要依赖 Git 的 pre-push hook,通过执行一些脚本来启动 CLI,完成自动化流程。
但这个方案在推广时并不理想。首先,它需要额外配置 hook,而且 hook 一旦设置,所有 push 都会触发。在某些场景下,比如只是做原型设计时,其实并不希望执行代码转换,开发者如果想跳过,还需要额外指定 Git 参数,使用成本较高。其次,我们项目共有 6 个仓库,逐个配置也很麻烦。再者,skill 文件需要放在代码仓库中,如果有更新,还得再同步到用户目录并执行额外操作,维护起来也不方便。
简而言之,这个流程不够顺手,因此最终并没有真正推广开。
为了解决这些问题,让工具真正可用,第二版引入了一个可手动操作的 UI,流程如下:
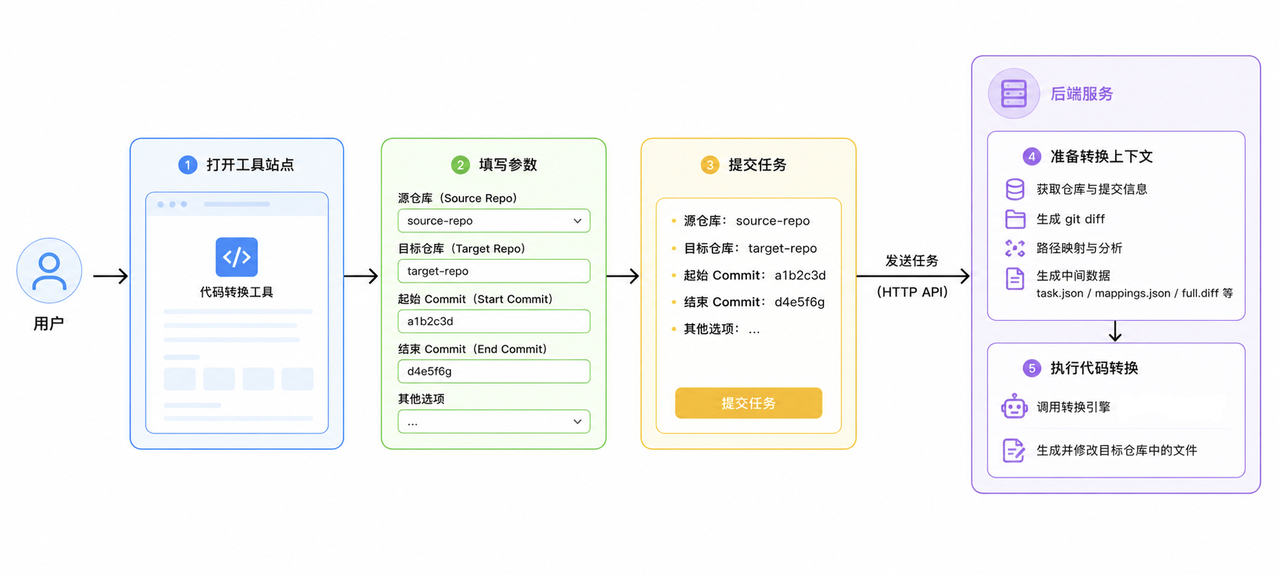
这一版大幅降低了使用门槛:双击 bat 即可启动;skill 直接放在工具仓库里,由工具统一管理;使用者只需要关注 UI 上要填写的参数即可。
真正的瓶颈:大任务为什么开始不稳定
到了这个阶段,工具在功能上已经基本可用,团队里的其他同事也开始把它真正用到代码转换场景中。随着使用次数增加,真正的问题才开始集中暴露出来。
小任务的效果通常不错,但一旦进入大批量代码转换,稳定性就会明显下降。结合实际使用情况回看,核心瓶颈主要有三个。
第一个问题,是上下文增长过快。
举个很典型的例子,某些存量代码里,C# 的属性定义可能是这样的:
public CalcType CalcType { get; set; }
Java 侧可能是这样的:
public CalcType CalcType = CalcType.Single;
从抽象规则上看,在 Java 侧,更合理的对应形式通常应该是 getter/setter,命名也应该转成小驼峰。但现实问题在于,存量代码本身未必完全规范。某些已有 Java 实现可能已经偏离了“标准映射”,比如直接保留为公开字段,甚至还带有特殊命名方式。
这就引出了第一个难点:为了确保转换准确,AI 往往需要多次到目标仓库里查代码。
这个要求本身很合理,但它会迅速推高上下文成本。一旦开始大量读取代码仓库,AI 的上下文就会快速膨胀。根据我的实际观察,任务规模一旦上到 1000 行左右,就很容易出现上下文耗尽;即使没有彻底耗尽,稳定性也往往会明显下降。
第二个问题是,大 diff 会让整个转换过程变得不流畅,甚至失控。
理想情况下,AI 会尝试自己拆分任务、逐步完成。但由于前面提到的“必须结合存量代码”这一点,即使任务被拆开,执行成本仍然很高。更糟的是,AI 有时会偏离当前目标,不再专注于完成转换,而是“另起炉灶”,试图再生成一个工具来解决问题。到了这个阶段,最大的风险已经不只是单次转换失败,而是整个流程开始失去稳定性和可预期性。
第三个问题是,AI 也会犯错。
从测试结果看,能够顺利完成的代码转换任务,正确率已经很高,基本能达到 95% 以上,但仍然无法完全避免零散错误。
增强工具
为了解决这些问题,我重新设计了一版流程:
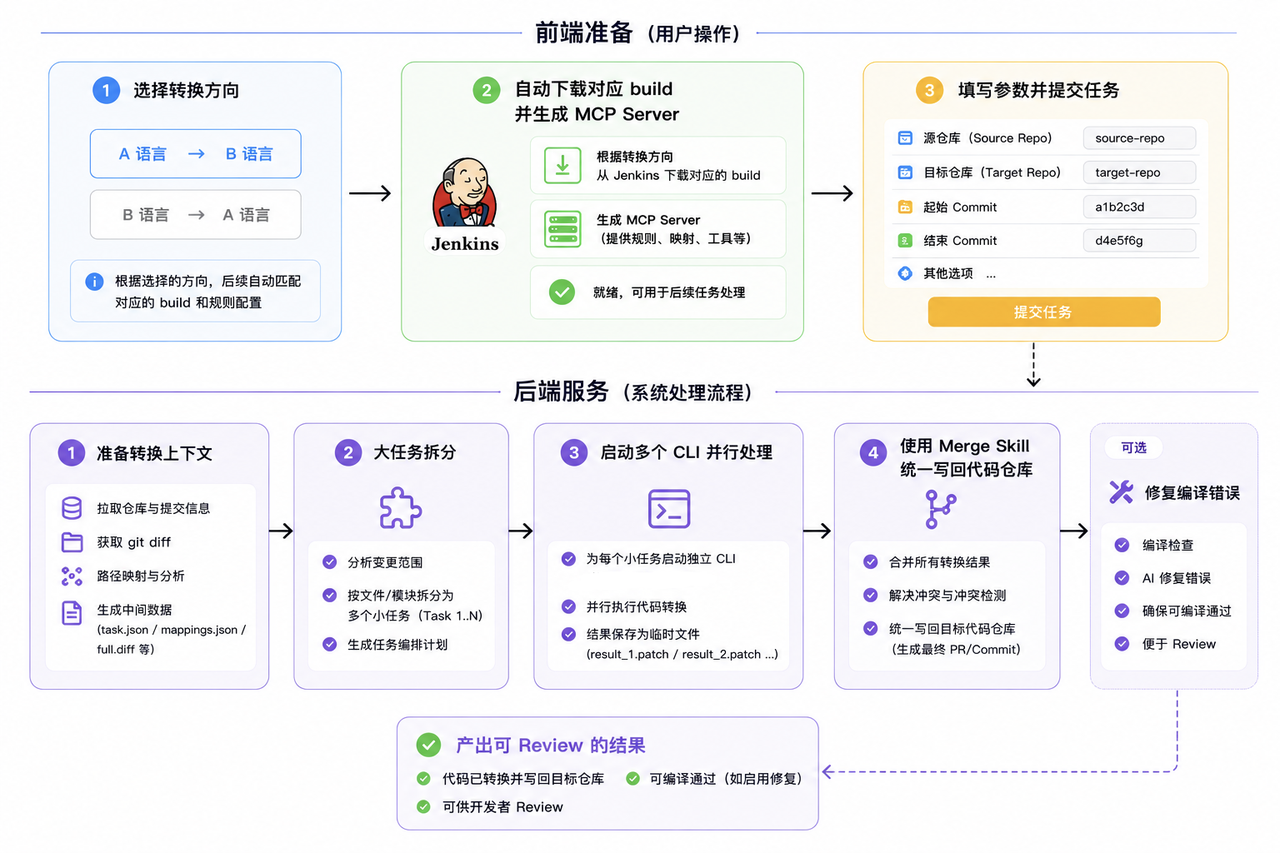
新流程主要有以下几个亮点:
MCP Server
原来那种“直接读取源码来判断如何转换”的方式,是一个很大的瓶颈。为了减少“读代码”带来的不确定性,我设计了一个 MCP Server:它会从 Jenkins 获取产品最新的非混淆包,再通过反射和遍历的方式,构建出一份完整的类型信息集合。
这份集合包含目标产物中的所有类型,以及每个类型下的方法、字段、属性等结构化信息。这样一来,AI 就不再需要直接查找源码,而是通过 MCP 查询目标平台实际暴露的 API 信息。
当然,中间也有一些失败的尝试。之前我试过用 knowledge.md 记录差异,但效果并不好。第一,项目太大,某次转换过程中记录下来的差异,下次未必真的能复用;第二,每次转换前还要额外读取这份

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)