
OpenClaw Dreaming 记忆流水线底层架构:状态分层、证据留痕与检索回流
一个能长期工作的 Agent,麻烦点不在“把对话存下来”。因为聊天记录本身太粗糙:里面有临时指令、工具失败、过程性解释、重复确认,也有少量会在未来反复有用的偏好、事实和工程判断。把这些内容原封不动塞进长期记忆,只会让上下文越来越脏。
OpenClaw Dreaming 机制处理的是一类问题:怎样让一次次对话先变成可追溯素材,再经过候选筛选、稳定归纳和索引构建,最后成为未来任务可以调用的长期上下文。
这套机制更像一条后台运行的记忆生产线。前台会话负责完成当前任务和保留原始事实;后台 Dreaming 再把这些事实加工成不同稳定程度的记忆,并通过 SQLite、全文索引和 memory_search 接回未来对话。
记忆不是一个文件:从日志、候选到索引的三层边界
OpenClaw 的记忆系统最容易被误解为“一个 Markdown 长期笔记”。实际情况更接近一套分层存储:原始会话、加工过程、长期正文、检索索引分别承担不同职责。
| 层级 | 典型位置 | 保存内容 | 核心职责 | 人工介入建议 |
|---|---|---|---|---|
| 原始输入层 | tech/sessions/*.jsonl |
用户消息、助手回复、工具事件、运行时元信息 | 留住当时发生了什么 | 不建议编辑,适合作为源日志 |
| 素材缓冲层 | memory/.dreams/session-corpus/YYYY-MM-DD.txt |
从 session 中抽取出的可读片段 | 给 Dreaming 提供当天素材 | 不建议编辑,适合排查抽取问题 |
| 运行审计层 | memory/.dreams/events.jsonl |
召回事件、阶段完成事件、写入路径 | 解释某次 Dreaming 是否运行、如何运行 | 只读排查 |
| 状态信号层 | daily-ingestion.json |
|||
、session-ingestion.json、short-term-recall.json、phase-signals.json |
游标、hash、召回次数、阶段命中 | 支持增量处理、去重和候选晋升判断 | 不建议手改 | |
| 长期正文层 | memory/YYYY-MM-DD.md |
|||
、DREAMS.md |
Light Sleep、REM Sleep、反思摘要和稳定上下文 | 供人和 Agent 阅读、审计、复用 | 可谨慎编辑,保留结构标记 | |
| 检索索引层 | ~/.openclaw/memory/tech.sqlite |
files |
||
、chunks、chunks_fts、embedding_cache |
支撑关键词检索、语义检索和增量索引 | 不应作为最终事实源 | ||
| 调用接口层 | memory_search |
|||
、memory_get |
查询和回读能力 | 让未来任务召回相关长期上下文 | 不涉及编辑 |
可以把这套结构拆成三条边界:
| 边界 | 关键判断 |
|---|---|
tech/sessions/*.jsonl |
|
| 记录事实,但不判断长期价值 | 它回答“当时发生过什么”,不回答“什么值得以后记住”。 |
.dreams/* |
|
| 记录生产过程,但不是最终知识库 | 它回答“为什么这条内容被召回或处理”,不适合直接当长期事实。 |
memory/*.md |
|
是可审计正文,tech.sqlite 是派生索引 |
排查时可以先从索引定位,再回到 Markdown 原文看上下文。 |

图:从会话日志到长期记忆检索回流的完整链路
这张图表达的重点是:记忆不会从当前对话直接跳到长期事实。它先经过素材化、候选化、稳定化,再进入可检索的长期上下文。
Session Ingestion:先保留原始上下文,再做延迟判断
每次用户发起请求时,系统首先要解决的是当前任务,而不是立刻“学习”。因此用户消息、助手回复、工具调用和运行元信息会先落到 session JSONL。这个阶段只保证一件事:原始上下文没有丢。
后续 Dreaming 会从这些持续追加的 session 文件里做增量抽取。session-ingestion.json 记录每个 session 文件的处理进度,例如文件大小、修改时间、内容 hash、行数以及最后处理到的内容行。这样后台任务不需要每次全量扫描,也能避免重复抽取同一段会话。
素材进入 session-corpus 后,会变成更适合阅读和回溯的行级文本:
[tech/sessions/...jsonl#L10] Assistant: 我先核对源码里的 dreaming / REM / DEEP 文件和规则,再把确认后的结论补进文档。
这一行看似普通,实际保留了三个关键信息:
| 字段 | 示例 | 作用 |
|---|---|---|
| 来源文件 | tech/sessions/...jsonl |
能定位到哪个 Agent 会话产生了素材 |
| 行号锚点 | #L10 |
支持回到原始日志查看上下文 |
| 角色与内容 | Assistant: ... |
|
、User: ... |
给后续候选判断提供语义输入 |
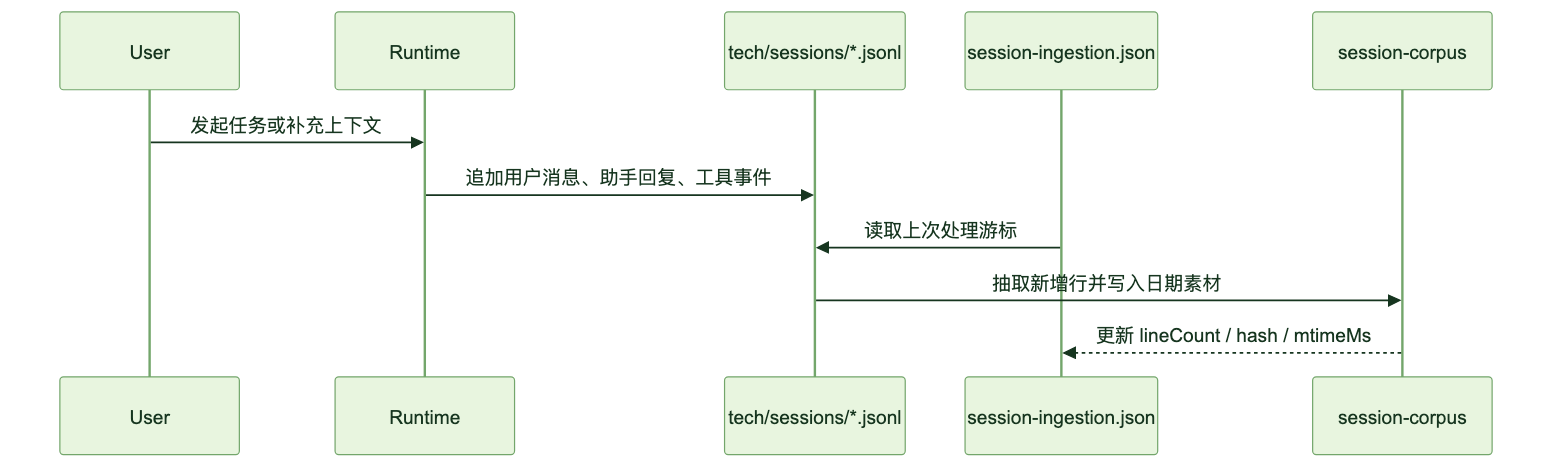
图:会话日志增量抽取为素材语料的过程
这一步的设计取舍很清楚:先完整留痕,再延迟判断。对话里的很多内容只对当前任务有用,过早写入长期记忆会制造噪声;但完全不留痕,又会丢掉后续可能需要归纳的证据。
Light 与 REM:用稳定性区分候选记忆和长期判断
memory/YYYY-MM-DD.md 是 Dreaming 输出最直观的位置。它不是单纯按时间堆内容,而是在文件内部用阶段标记区分不同稳定程度的信息。
| 区块 | 典型标记 | 内容形态 | 语义定位 | 使用方式 |
|---|---|---|---|---|
| Light Sleep | `` | |||
到 light:end |
Candidate、confidence、evidence、recalls、status | 候选记忆,表示“可能有用,但还要观察” | 适合近期续接、路径线索、任务偏好补全 | |
| REM Sleep | `` | |||
到 rem:end |
Reflections、Possible Lasting Truths | 更稳定的长期归纳 | 更适合影响后续回答、工具选择和写作规范 | |
| 会话补充 | 普通 Markdown 小节 | 文档链接、用户偏好、任务结果、实现锚点 | 人工或系统补写的稳定上下文 | 适合明确记录可复用事实 |
Light 和 REM 的差别不在格式,而在可信度和使用方式。
| 对比维度 | Light Sleep | REM Sleep |
|---|---|---|
| 目标 | 捕捉近期可能有价值的线索 | 提炼可长期复用的事实、偏好、模式和约束 |
| 粒度 | 较细,常带路径、原话、任务片段和证据位置 | 较粗,通常压缩成稳定判断 |
| 可信度表达 | 常见 confidence、status=staged、recalls |
通常来自多次 evidence 或更高置信归纳 |
| 行为影响 | 应谨慎使用,主要补全上下文 | 更容易影响后续回答和任务判断 |
| 典型用途 | 近期任务续接、排查线索保留 | 用户偏好、长期规则、重复问题模式 |
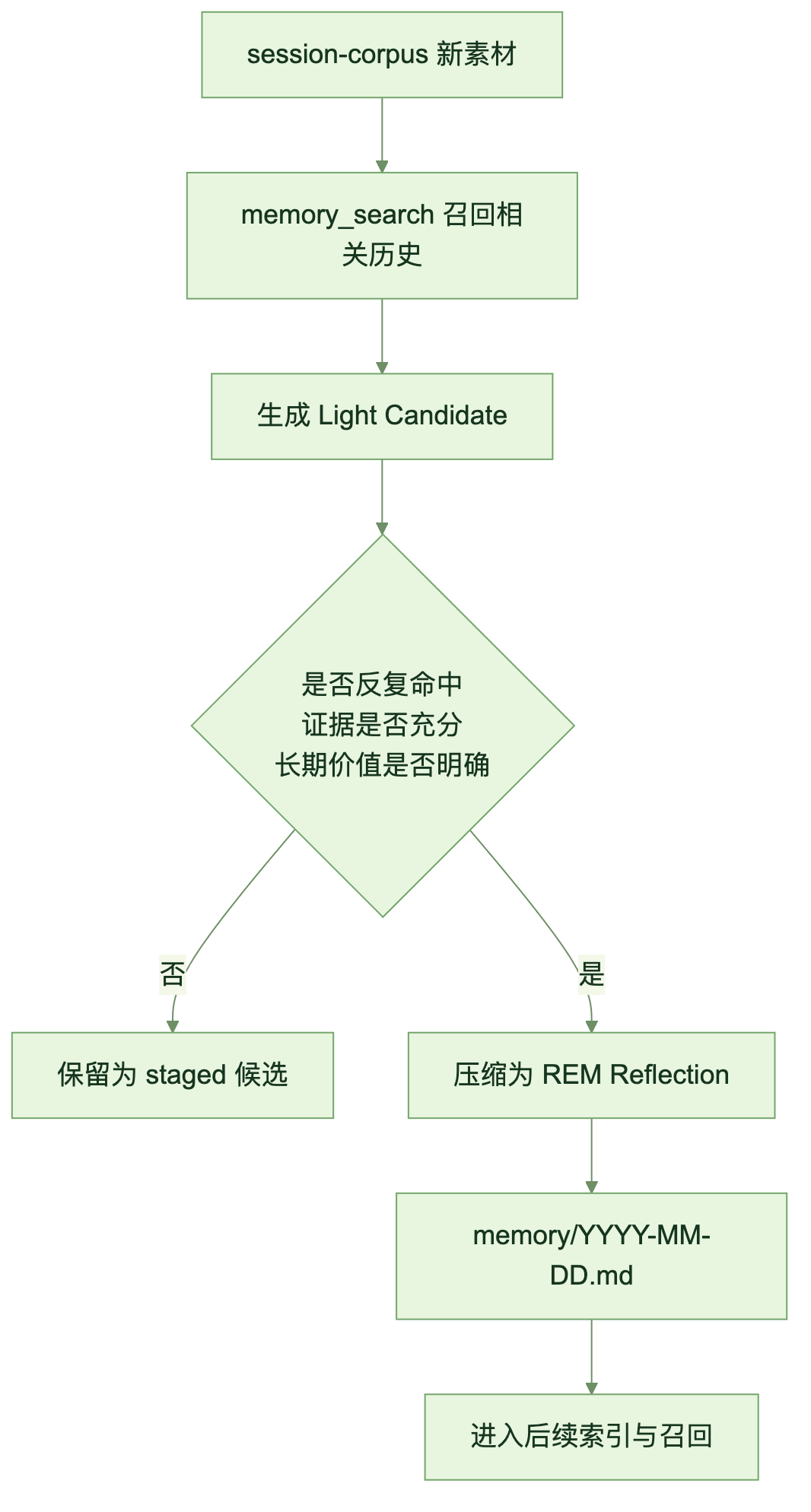
图:候选记忆如何经过证据判断沉淀为 REM 归纳
实际阅读日期记忆时,比较稳的顺序是:先看 REM 得到稳定判断,再回到 Light 看证据和来源。这样可以避免把候选层的低置信线索误当成长期事实。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)