
企业AI Agent生产环境架构:模型服务、任务编排、沙箱、AgentOps与算力规划
企业AI Agent从概念验证进入生产环境后,系统设计的重点会从“模型效果”转向“端到端任务能否稳定、受控地执行”。
普通LLM应用可以简化为请求进入推理服务、模型生成结果、应用返回答案。Agent系统则需要维护状态、动态选择工具、访问企业数据、执行外部动作,并对长时间、多步骤任务进行恢复和追踪。
2026年NVIDIA发布的Agent Toolkit将Nemotron开放模型、NemoClaw蓝图、OpenShell运行时和CUDA-X Agent Skills放在同一体系中。其官方描述明确指出,模型要转变为Agent,还需要一层harness,提供orchestration、context、memory、tool use和security。

这是一种值得参考的架构信号:生产级Agent不是一个框架或模型能够独立解决的问题,而是模型服务、应用控制面、安全执行面和AI基础设施的组合。
一、Agent系统与单轮推理系统的差异
Agent任务通常具有以下特征:
1. Stateful:需要保存任务状态、中间文件和历史决策。
2. Multi-step:一次请求可能触发多轮推理、检索和工具调用。
3. Tool-enabled:可以访问数据库、文件、API、命令和专业软件。
4. Long-running:任务可能持续数分钟至数小时,并需要断点恢复。
5. Non-deterministic:模型输出会影响后续路径,固定流程测试无法覆盖所有情况。
6. Bursty:主Agent并行触发子任务时,推理和数据处理请求会出现短时峰值。
因此,生产指标应从单模型延迟扩展到任务成功率、端到端时长、工具失败率、人工接管率、资源成本和执行可追溯性。

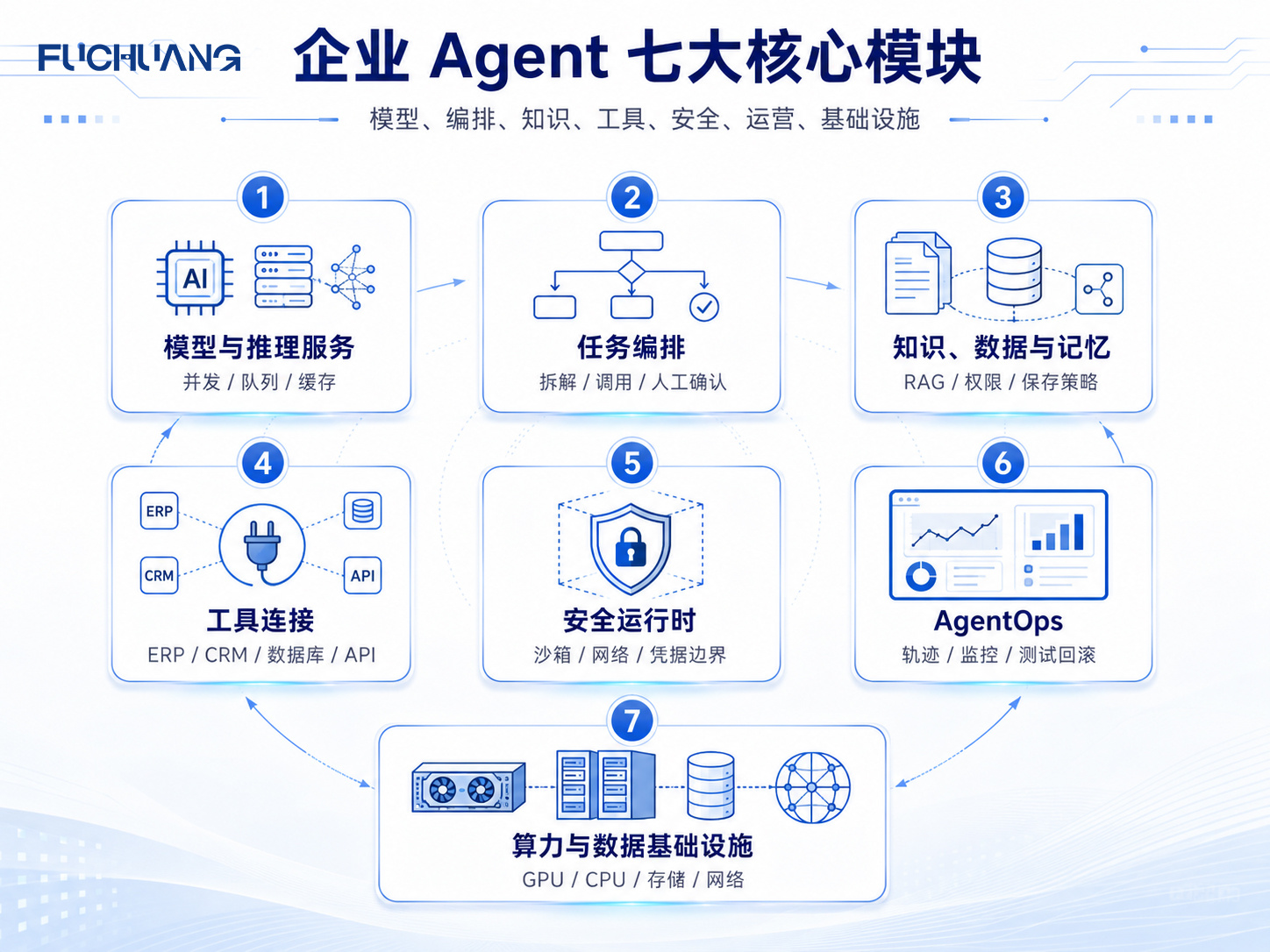
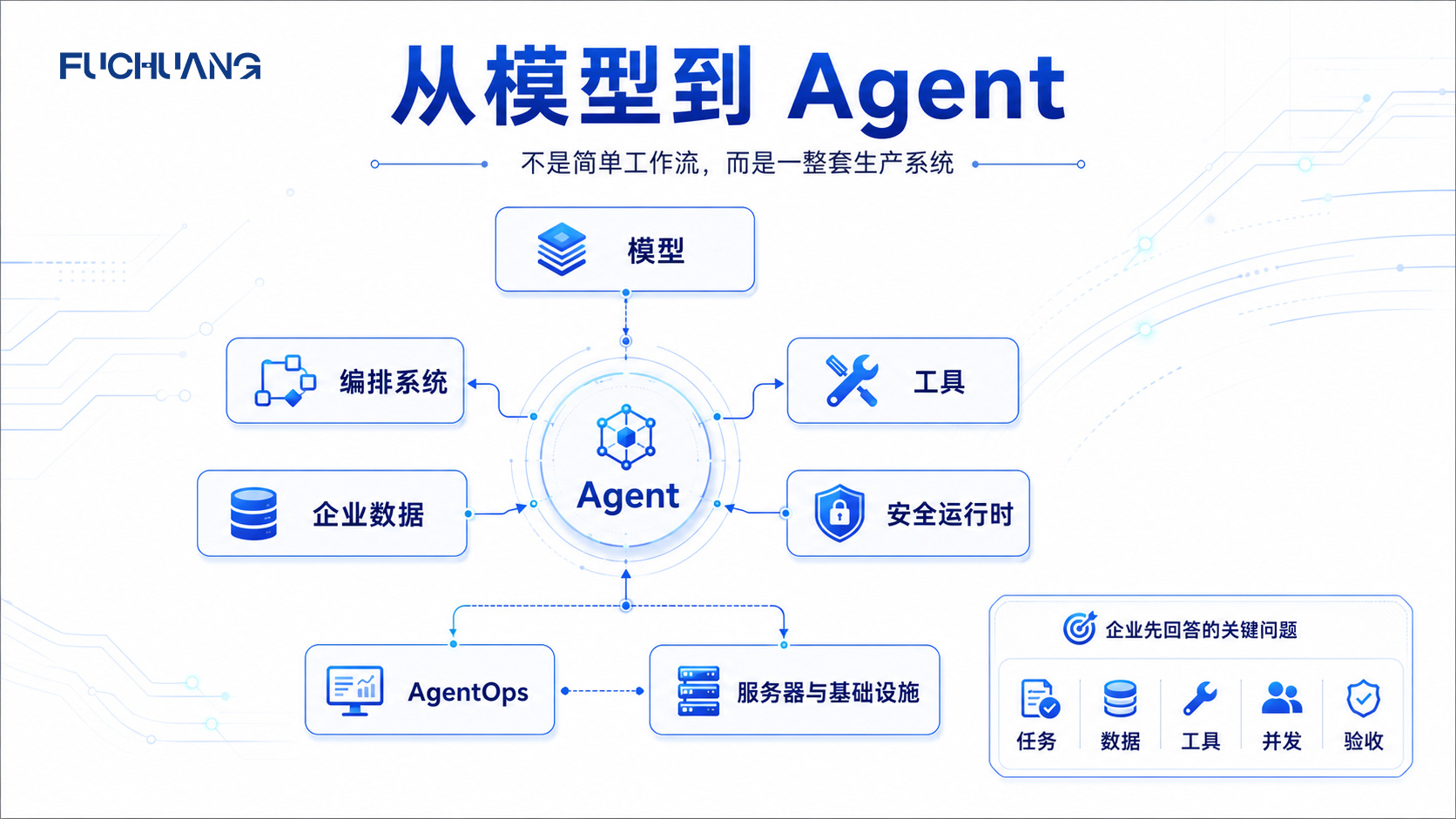
二、七层生产参考架构
1. Model and Inference Service
职责包括模型加载、批处理、KV Cache、请求队列、模型路由、限流、弹性扩缩、版本和故障恢复。
模型可以本地部署,也可以通过外部API使用。混合模式下应由网关统一处理认证、路由、成本和数据策略,避免Agent直接持有外部模型凭据。
2. Agent Orchestration and State
负责:
·任务图和步骤调度;
·模型、工具、子Agent调用;
·状态持久化;
·timeout、retry和circuit breaker;
·人工确认节点;
·任务暂停、恢复和取消。
长任务不应完全依赖模型上下文保存状态。中间文件、结构化状态和执行日志应落到独立存储中,以支持恢复和审计。
3. Enterprise Data, RAG and Memory
RAG解决企业知识检索,Memory解决跨步骤或跨会话状态,权限系统决定Agent在当前身份下可以访问什么。
这三者应分开设计。向量库中存在某个文档,不代表所有用户和Agent都可以检索。数据连接层需要传递用户、部门、任务和租户信息,并在检索前后执行权限过滤。
4. Tools and Business Connectors
工具可能包括数据库、文件系统、HTTP API、MCP Server、代码执行器、工单、监控、ERP/CRM以及EDA和仿真软件。
连接协议只解决发现和调用方式,不能替代身份认证、参数校验、最小权限和审计。读、写、删除、支付、外发等动作应采用不同策略,高风险操作需加入human-in-the-loop。
5. Secure Runtime and Sandbox
模型输出不能直接获得宿主机权限。执行层应通过容器、VM、MicroVM或沙箱隔离:
·进程:降低权限,禁止提权;
·文件:仅开放声明的只读或读写目录;
·网络:默认拒绝,按照目标、端口和方法开放;
·凭据:由控制面按需注入,不写入Agent上下文;
·推理:通过网关路由,隔离模型提供方凭据;
·资源:设置CPU、内存、GPU、时间和并发上限。
NVIDIA OpenShell采用Gateway和Sandbox分离:Gateway管理状态、策略、凭据和推理配置,Supervisor在沙箱内执行进程、文件、网络和凭据策略,并输出安全日志。
技术边界:OpenShell的GitHub仓库截至核验时标注为Alpha和single-player mode,尚不能把其当前开源状态直接视为成熟多租户生产平台。
6. AgentOps and Observability
AgentOps需要覆盖:
·Agent配置、提示、技能和依赖版本;
·模型与工具调用trace;
·输入、输出和中间状态;
·Token、时长、GPU利用率和成本;
·任务成功率、重试率、工具错误率;
·人工审核和修改记录;
·回归评估、灰度和回滚。
NVIDIA企业AI工厂设计指南提出,长时间Agent应像微服务一样支持版本、测试、监控和回滚,同时还要处理行为和技能演进。
7. Compute, Storage and Network
容量规划不能只计算模型权重。建议至少建立以下变量:
·W:模型权重与运行时基础显存;
·C:单会话KV Cache平均占用;
·N:峰值并发会话或Agent数;
·L:单任务平均模型调用次数;
·P:并行子任务系数;
·S:文件、向量、数据库和中间产物的存储/IO需求;
·SLA:首Token延迟、端到端时长和可用性目标。
这里只能用于建立评估框架,不能直接得出固定GPU数量。不同模型、推理引擎、量化和上下文下,W和C差异很大,必须通过profiling获得。
三、Agent负载为什么更容易出现峰值
单轮问答中,用户请求与模型请求的比例相对直接。Agent系统中,一个用户任务可能触发多次模型调用;主Agent并行启动子Agent后,请求量会进一步放大。
可以用以下逻辑理解总请求压力:
用户任务数 × 单任务模型调用次数 × 并行系数
这不是精确性能公式,而是容量规划时需要纳入的放大关系。
NVIDIA Enterprise AI Factory Overview明确将Agentic workload描述为inherently bursty,建议围绕tokens/s、QPS和增长余量进行动态资源分配。
实际系统应结合队列、优先级、速率限制、最大任务深度、最大并行子Agent数和Token预算,避免单个任务消耗无限资源。OWASP也把Unbounded Consumption列为生成式AI应用风险之一。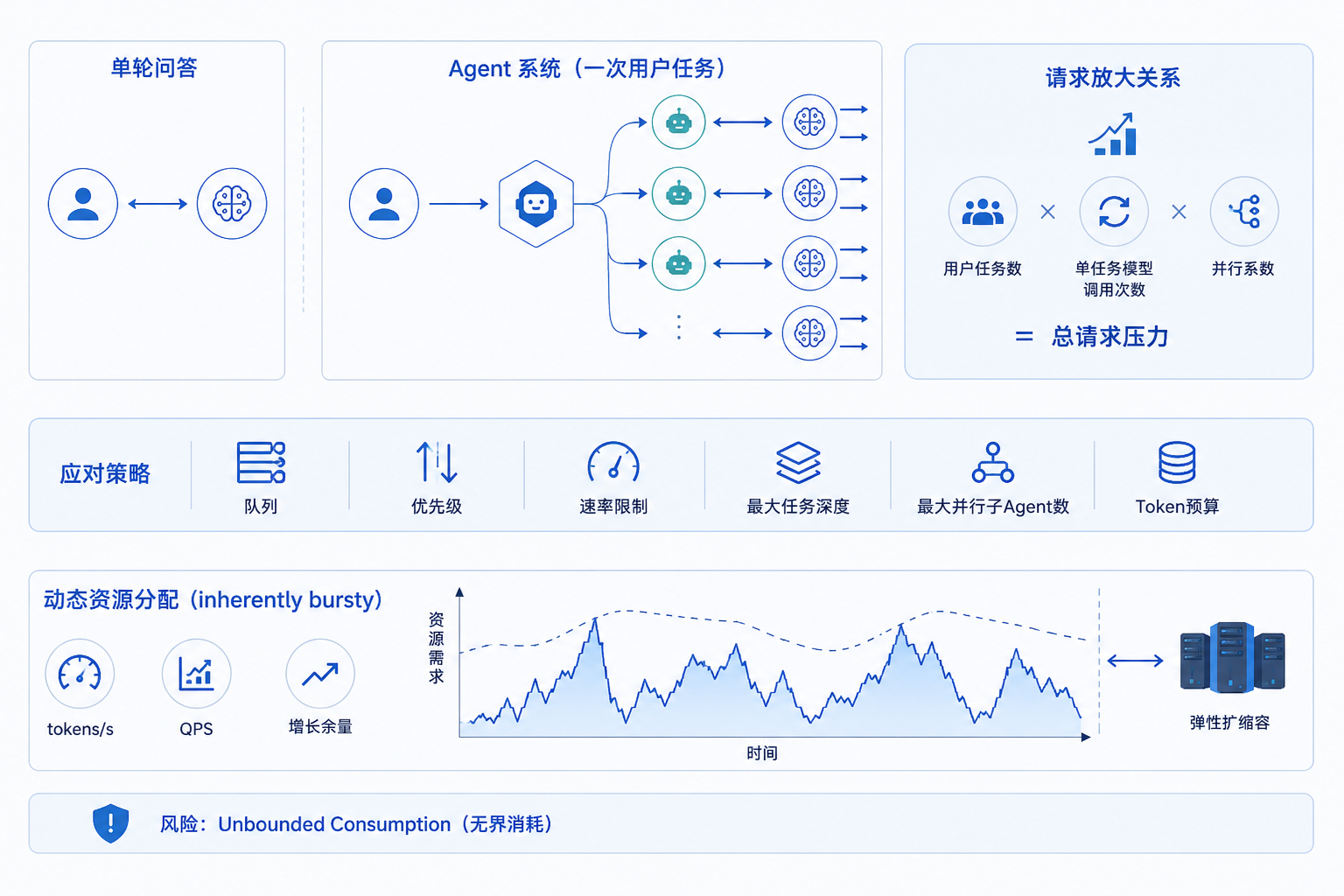
四、安全设计不能只依赖系统提示
Agent风险来自“模型输出”与“软件执行能力”的结合。
NIST在2026年AI Agent安全RFI中重点关注:
·间接提示注入;
·不安全或被污染的模型;
·错误目标和非预期动作;
·如何限制和监控Agent对部署环境的访问。
OWASP Agentic Applications框架则覆盖目标劫持、工具误用、身份和权限滥用等问题。
建议采用以下控制:
1. Agent独立身份,而不是共享管理员账号。
2. 最小权限和短期凭据。
3. 数据检索与工具调用都执行授权检查。
4. 网络default-deny,按目标和方法开放。
5. 外部网页、邮件和文档视为不可信输入。
6. 高风险动作采用双确认或人工审批。
7. 保留不可抵赖的执行与配置日志。
8. 对提示、模型、工具和依赖更新执行回归测试。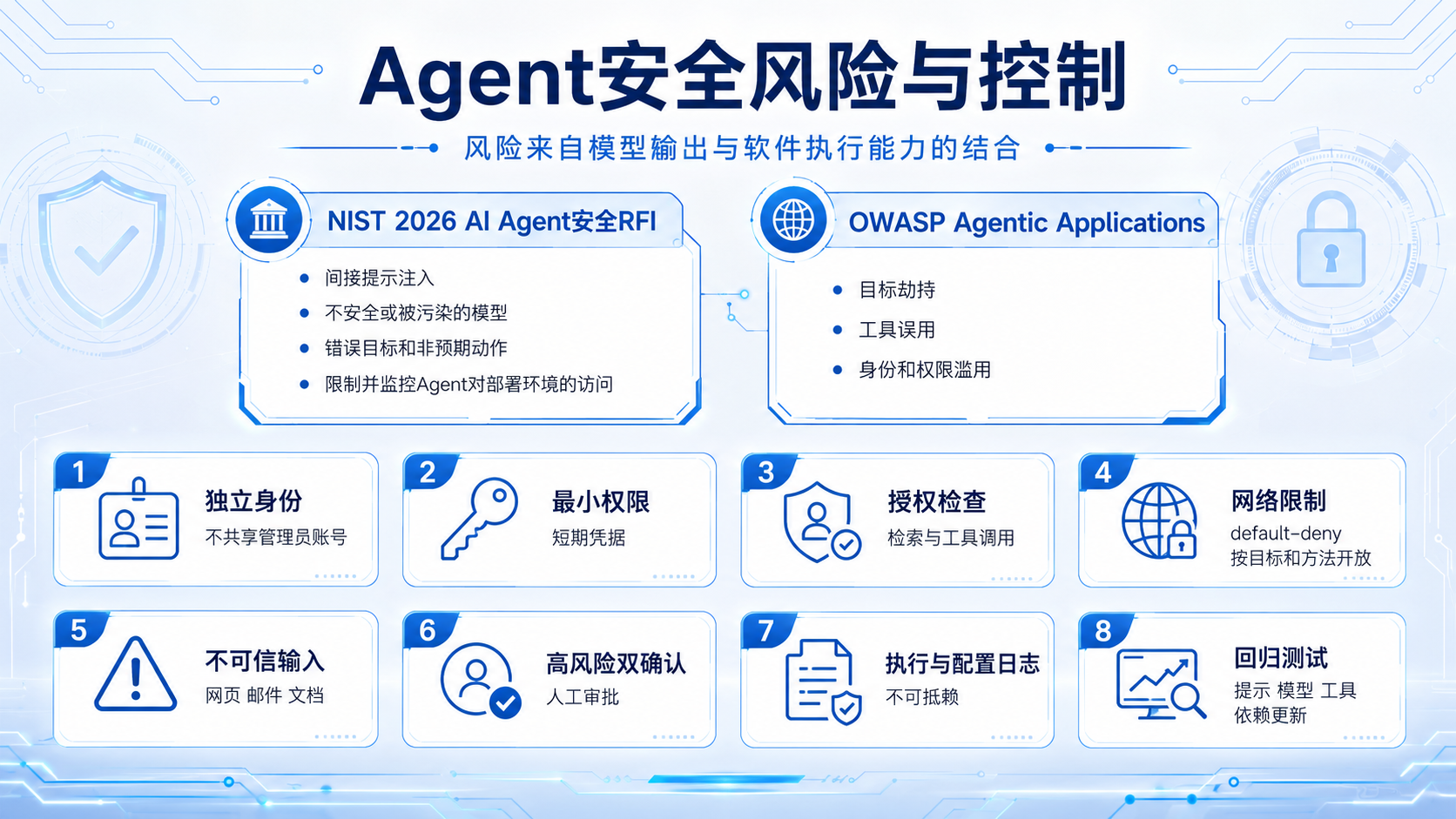
五、不同场景的资源关注点
知识问答Agent:RAG检索、数据权限、推理并发和引用质量。
运维Agent:长期运行、事件触发、日志吞吐、工具权限、异常恢复和高可用。
代码Agent:文件系统、代码执行、依赖下载、网络限制、CPU和NVMe性能。
数据分析Agent:数据库连接池、结构化输出、长任务状态和查询成本。
EDA/科研Agent:专业软件接口、许可、CPU/GPU混合计算、大内存、高速存储和调度系统。
多Agent平台:资源池化、任务队列、Agent身份、租户隔离、链路追踪和预算控制。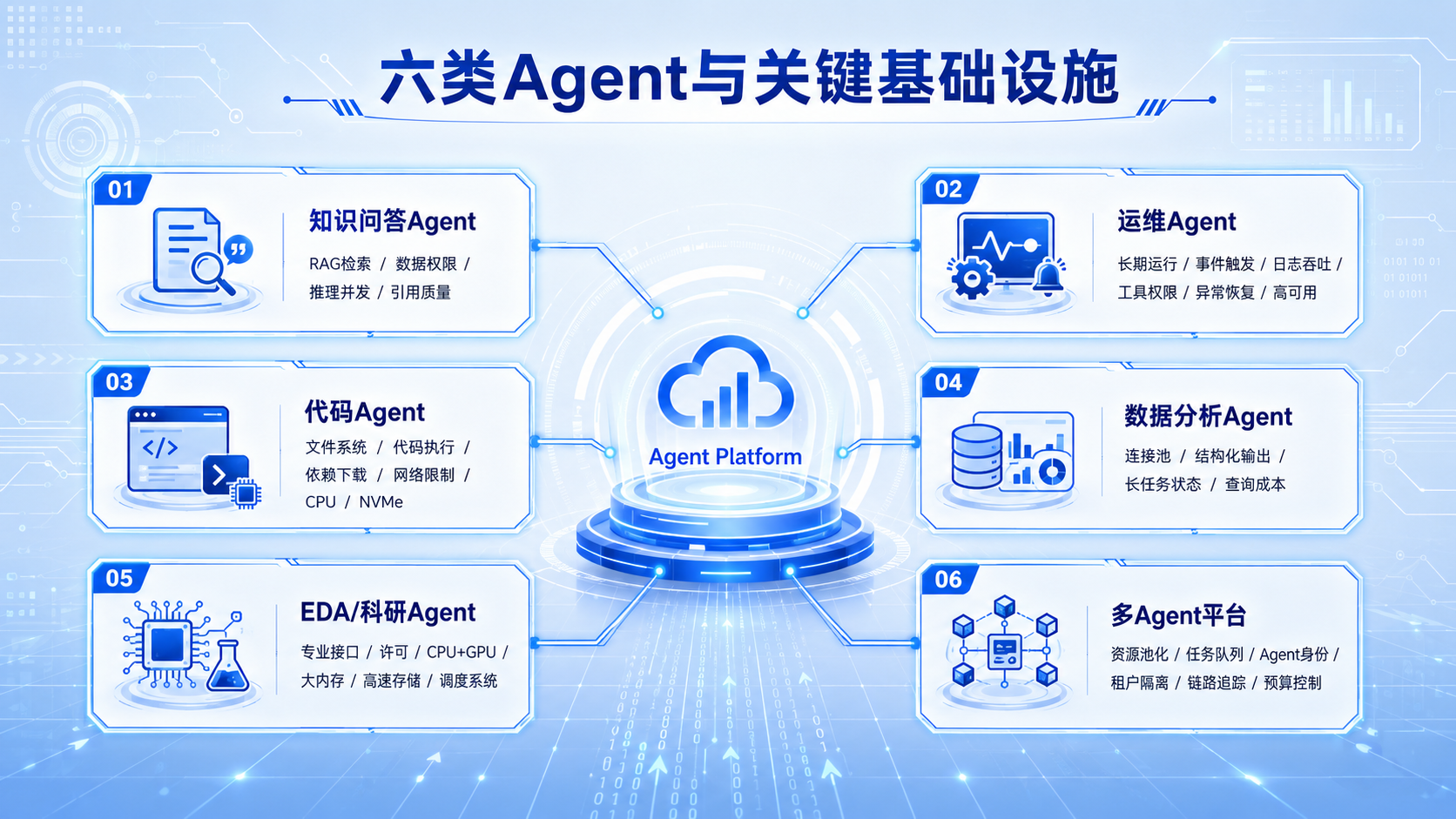
六、推荐的落地阶段
阶段1:PoC
使用单一、只读、结果可判断的任务,验证模型、RAG和工具调用。此阶段不应开放高风险权限。
阶段2:Controlled Pilot
在沙箱中连接少量真实系统,建立身份、权限、日志和人工确认机制,并开始收集端到端任务指标。
阶段3:Limited Production
固定部门和用户上线,引入高可用、资源队列、故障恢复、版本和回归评估。
阶段4:Platformization
将模型服务、数据连接、工具、策略、日志和评估能力组件化,支持多个Agent复用,而不是为每个Agent重复建设一套环境。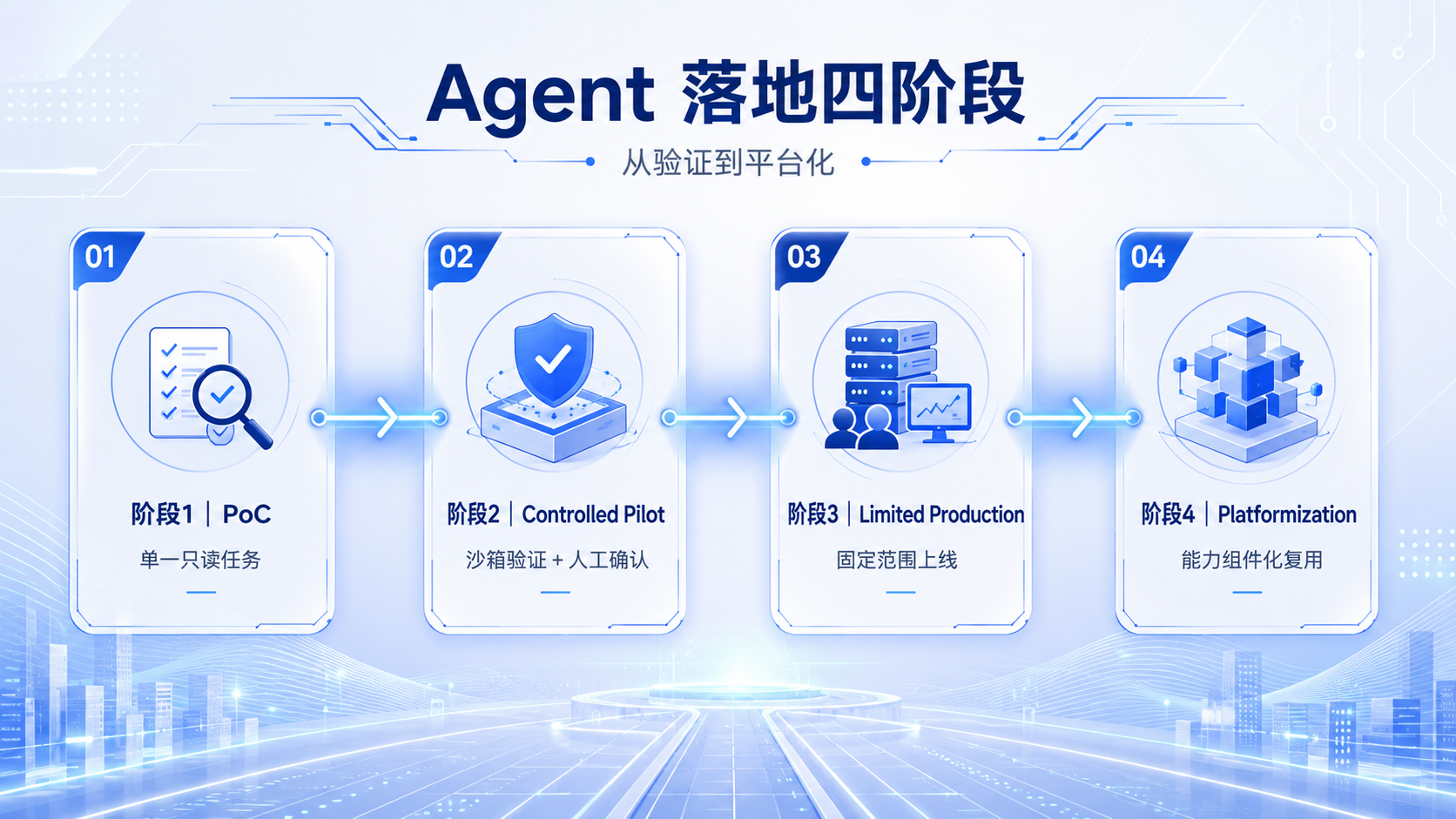
七、基础设施交付边界
企业Agent基础设施可以覆盖GPU服务器、推理服务、容器/Kubernetes环境、知识与数据连接底座、沙箱与权限策略、监控以及性能适配。
具体业务规则、工作流设计和应用系统开发通常仍需要客户或应用合作伙伴负责。基础设施与应用边界清晰,才能避免“底层能运行,但业务无法验收”或“应用功能完成,但生产环境不可维护”的问题。

结论
生产级AI Agent的核心不是模型能够回答问题,而是系统能够约束它如何访问数据、调用工具、消耗资源和处理失败。
在架构上,应把模型服务、编排状态、企业数据、工具连接、安全运行时、AgentOps和计算基础设施作为整体设计。配置上,应基于真实任务链profiling,而不是根据模型参数直接套用GPU数量。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)