
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (4)--- 架构
0x00 概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
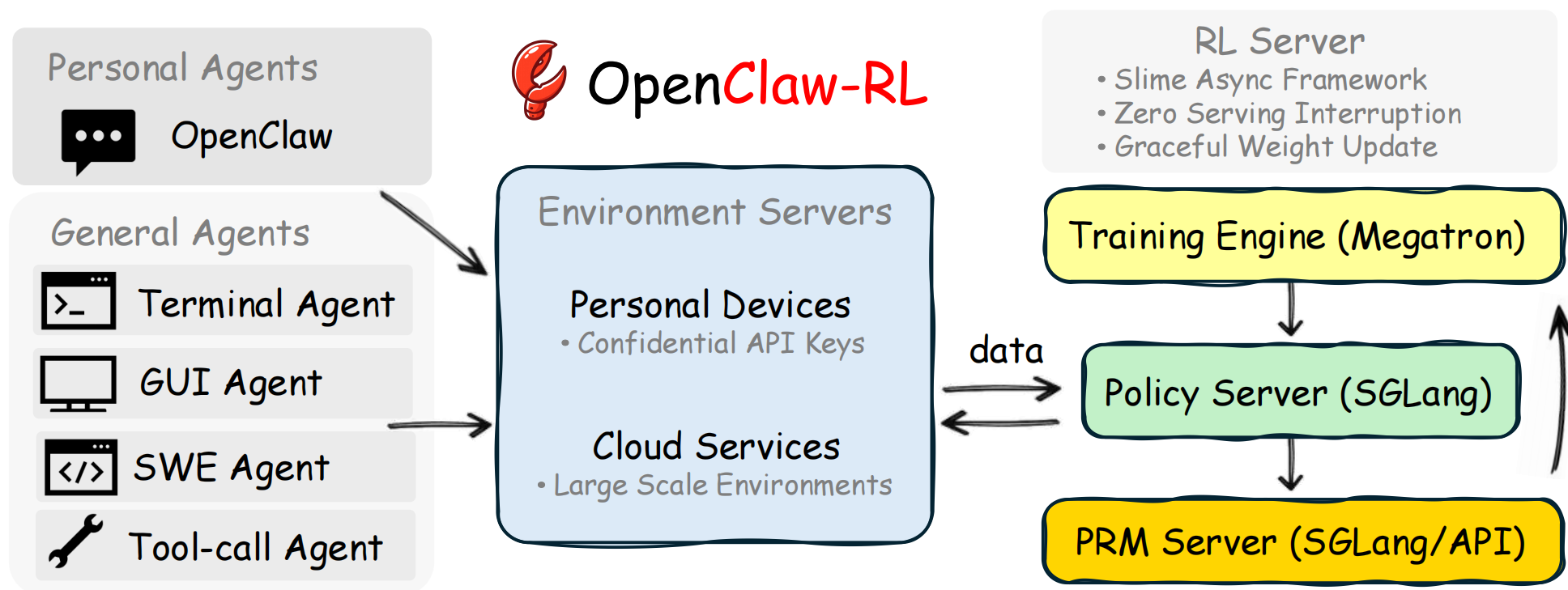
0x01 架构
OpenClaw 的 RL 训练 = 一套统一的 PPO 框架 + 三种不同的 advantage 注入方式
┌────────────┬──────────────────────────────┬─────────────────────────────────────┐
│ 方法 │ Advantage 来源 │ 适用场景 │
├────────────┼──────────────────────────────┼─────────────────────────────────────┤
│ Binary RL │ A = R (raw broadcast) │ 简单场景,只有 ±1 reward │
│ │ reward 标量广播到全序列 │ │
├────────────┼──────────────────────────────┼─────────────────────────────────────┤
│ OPD │ A_t = teacher_lp_t - old_lp_t│ 有 teacher model 提供 per-token 信号 │
│ │ teacher 的 per-token log-probs │ 需要精细引导,如 hint 机制 │
├────────────┼──────────────────────────────┼─────────────────────────────────────┤
│ Combine │ A_t = w_rl·R + w_opd·(teacher│ 同时需要 reward 和 teacher 信号 │
│ │ _lp_t - old_lp_t) │ 最灵活,可调权重 │
└────────────┴──────────────────────────────┴─────────────────────────────────────┘
关键设计原则:
- 统一 PPO clip 框架:三种方法共享同一套 ratio-based clipped loss
- 数据驱动分流:Combine 通过设置 teacher_lp=rollout_lp 或 reward=0 自动区分 OPD/RL 样本
- 无额外模型:GRPO 替代 Critic,teacher 只做 forward pass(不训练)
- 异步架构:Proxy 实时拦截用户对话,Trainer 后台持续更新
1.1 架构图
OpenClaw-RL 的系统架构图如下:
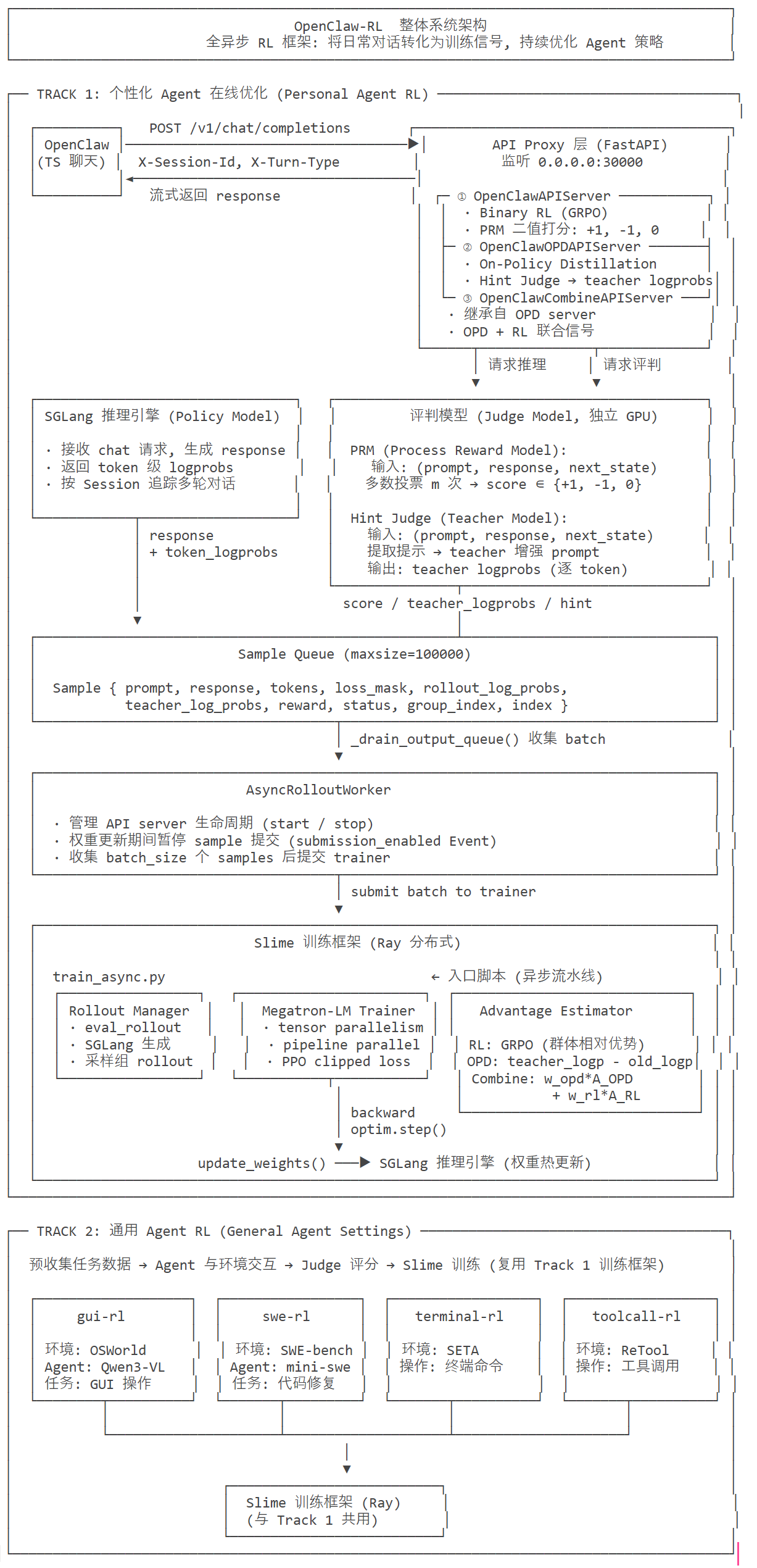
1.2 File Structure
OpenClaw-RL 的的文件结构如下。
OpenClaw-RL-main/
│
├── 🧠 核心 RL 框架
│ ├── slime/ # Ray + Megatron-LM 分布式训练
│ └── Megatron-LM/ # NVIDIA 模型并行后端
│
├── 🏠 个性化 Agent 优化 (Track 1)
│ ├── openclaw-rl/ # Binary RL (GRPO)
│ ├── openclaw-opd/ # On-Policy Distillation
│ ├── openclaw-combine/ # RL + OPD 联合方法
│ └── openclaw-tinker/ # Tinker 云端零 GPU 方案
│
├── 🌐 通用 Agent RL (Track 2)
│ ├── gui-rl/ # GUI Agent (OSWorld)
│ ├── swe-rl/ # SWE Agent (mini-swe-agent)
│ ├── terminal-rl/ # Terminal Agent (SETA)
│ └── toolcall-rl/ # Tool-Call Agent (ReTool)
│
├── 📊 评估
│ └── openclaw-test/ # GSM8K 多轮对话评估
│
├── 🎨 前端
│ └── openclaw/ # OpenClaw 聊天应用 (TS/Node)
│
└── 📄 配置
├── requirements.txt # 301 个 Python 依赖
└── instructions/ # 环境搭建指南
模块职责划分如下。
OpenClaw-RL/
├─ openclaw-rl/
│ ├─ openclaw_api_server.py ← FastAPI 代理 + PRM 评分 + 样本提交
│ └─ openclaw_rollout.py ← AsyncRolloutWorker: 桥接 API Server ↔ Slime
├─ openclaw-opd/ ← OPD 变体(hint 提取 + teacher log-probs)
├─ openclaw-combine/ ← Combined 变体(RL + OPD 并行)
├─ openclaw-tinker/ ← 无 GPU 云端版(Tinker API)
├─ slime/
│ └─ train_async.py ← 基础 RL 框架(Megatron + SGLang)
│ ← 入口:异步训练主循环
├─ terminal-rl/ gui-rl/
│ swe-rl/ toolcall-rl/ ← Track 2:通用智能体 RL
└─ openclaw/
└─ src/ ← OpenClaw TypeScript 应用
1.3 四大组件
OpenClaw-RL 的系统设计是四个异步解耦的循环——policy serving、environment hosting、reward judging、policy training 同时运行、互不阻塞,因此模型可以一边持续服务,一边从刚刚发生的真实交互中在线学习。
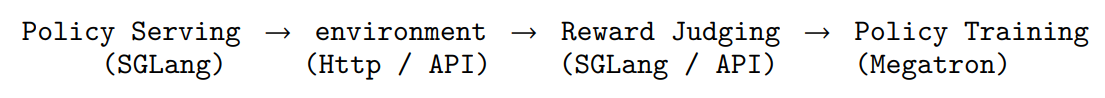
在这种模块化设计中,各组件既保持功能独立性又实现数据互通。
OpenClaw-RL四大组件 vs 标准RL的区别

四个阶段的模块归属
Policy Serving
定义:运行策略模型、生成response、提供推理能力。
功能定位
- 用户交互入口:接收外部环境的请求并返回响应
- 模型推理服务:转发请求至SGLang推理引擎获取模型响应
- 会话状态管理:维护多轮对话的上下文状态
技术实现
- Web 框架:基于 FastAPI 实现OpenAI 兼容的 /v1/chat/completions接口
- 核心文件:openclaw_api_server.py/ openclaw_opd_api_server.py
具体如下:
| 模块 | 角色 | 位置 |
|---|---|---|
| SGLang Rollout Engine | 真正的 Policy(LLM 推理,GPU 4-5) | Slime 启动,Ray PlacementGroup 管理 |
| OpenClawAPIServer._handle_request() | HTTP 转发代理 | openclaw_api_server.py |
| httpx.post(sglang_chat_url) | 向 SGLang 发送推理请求 | _handle_request() 内 |
| _extract_logprobs_from_chat_response() | 采集 rollout log-probs | openclaw_api_server.py |
| FastAPI /v1/chat/completions | 对外暴露的推理接口(PORT=30000) | _build_app() |
| Megatron Actor(GPU 0-3) | 保存最新策略权重,定期同步给 SGLang | Slime 内部 |
Environment
定义:产生观测(next_state)、定义任务边界。
环境托管模块(Environment Hosting Subsystem)构建智能体操作的真实/模拟环境:
- 个人智能体场景:集成用户终端设备(手机/电脑)的会话系统
- 通用智能体场景:支持云端并行终端、图形界面交互、软件工程开发环境及工具调用沙盒
环境模块通过事件驱动机制实时反馈状态变化,包括用户追问、代码执行结果(stdout/stderr)或界面元素变更等信号。
具体如下:
| 模块 | 角色 | 位置 |
|---|---|---|
| 真实用户 | 发消息(动作) + 看 response(观测) | 外部,无代码 |
| HTTP 请求中的 messages | 用户发出的 observation sequence | FastAPI 请求体 |
| messages[-1](新消息) | next_state,上一轮 turn 的环境反馈 | _handle_request() 第 504 行 |
| X-Session-Id header | 标识同一个 environment episode(会话) | FastAPI header |
| X-Turn-Type: main/side | 区分训练轨迹与非训练交互 | FastAPI header |
| X-Session-Done header | episode 终止信号 | FastAPI header |
Environment在OpenClaw中没有代码实体,它就是“真实用户+HTTP协议“本身。
Reward Judging
定义:评估当前response的质量,产生reward 信号 Binary RL 的 Reward Judge。
效果评估模块(Reward Judging Component)采用双轨制评估机制:
- 量化评估层(PRM Judge):基于预设指标体系生成即时评分(+1/-1等)
- 质性指导层(OPD Hint Extractor):通过自然语言理解技术提取改进建议。
该模块将评估结果与指导信号整合为结构化反馈,构建"教师上下文"用于模型微调。评估过程采用异步批处理模式,支持每秒千级交互的评估吞吐量。
功能定位
- 质量评估:对代理响应进行质量评分
- 评估逻辑:基于下一状态判断助手响应质量
- 评分规则:+1(好)/-1(差)/0(中性)
- 多数投票:多次独立评估取多数结果
- 奖励信号生成:生成用于策略优化的奖励信号
- 过程监督:提供细粒度的过程反馈而非仅结果反馈
技术实现
- 过程奖励模型:通过下一状态评估当前响应质量
- 多数投票机制:执行多次独立评估取多数结果提高可靠性
- 异步评估:在后台线程中执行耗时的LLM评估
- 核心文件:集成在openclaw_api_server.py中的PRM相关逻辑
具体如下:
| 模块 | 角色 | 位置 |
|---|---|---|
| _fire_prm_scoring() | 触发 PRM 评分任务(异步) | openclaw_api_server.py |
| _prm_evaluate() | PRM 评估主逻辑(m=3 并行) | openclaw_api_server.py |
| _query_prm_once() | 单次调用 Judge LLM(GPU 6-7) | openclaw_api_server.py |
| _majority_vote() | 多数投票 → final score | openclaw_api_server.py |
| _build_prm_judge_prompt() | 构造 judge prompt | openclaw_api_server.py |
| SGLang PRM Engine(GPU 6-7) | 运行 Judge LLM 推理 | Slime 启动 |
OPD / Combine 额外的 Reward Judge如下:
| 模块 | 角色 | 位置 |
|---|---|---|
| _fire_opd_task() | 触发 OPD 评估任务(异步) | openclaw_opd_api_server.py |
| _opd_evaluate() | Hint Judge + Teacher LP + Eval | openclaw_opd_api_server.py |
| _query_judge_once() | Hint Judge 单次调用(GPU 6-7) | openclaw_opd_api_server.py |
| _select_best_hint() | 选最优 hint | openclaw_opd_api_server.py |
| _compute_teacher_log_probs() | 教师前向传播(max_new_tokens=0) | openclaw_opd_api_server.py |
| _query_prm_eval_once() | Eval Judge(仅 Combine) | openclaw_opd_api_server.py |
| _prm_eval_majority_vote() | Eval 多数投票(仅 Combine) | openclaw_opd_api_server.py |
Policy Training
定义:利用reward信号更新策略参数
策略训练模块(Policy Training Pipeline)基于Megatron等分布式训练框架构建,采用PPO等强化学习算法实现模型优化。其创新点在于:
- 独立数据队列机制:隔离在线服务与训练数据流
- 增量学习架构:支持动态权重更新而不中断服务
功能定位
- 模型优化:基于收集的样本和奖励信号更新策略模型
- 分布式训练:支持多GPU和多节点分布式训练
技术实现
- 训练框架:基于Slime和Megatron-LM实现
- 算法支持:GRPO、PPO、KL正则化等多种RL算法
- 核心文件:slime/train_async.py及相关训练脚本
具体如下:
| 模块 | 角色 | 位置 |
|---|---|---|
| _maybe_submit_ready_samples() | 等 PRM 完成后触发 sample 提交 | 各 api_server.py |
| _submit_turn_sample() | 构造 Sample 对象(loss_mask, reward) | 各 api_server.py |
| _submit_rl_turn_sample() | RL-only 样本(Combine) | openclaw_combine_api_server.py |
| output_queue.put(...) | 跨线程传递 Sample | 各 api_server.py |
Slime训练主循环:
| 模块 | 角色 | 位置 |
|---|---|---|
| generate_rollout_openclaw() | Slime rollout 入口(被动收集) | openclaw_rollout.py |
| _drain_output_queue() | 等待 N 个样本积累 | openclaw_rollout.py |
| AsyncRolloutWorker.pause/resume_submission() | 控制 API 开关(weight sync 期间暂停) | openclaw_rollout.py |
| compute_advantages_and_returns() | 计算 GRPO/OPD advantage | slime/.../loss.py |
| get_grpo_returns() | GRPO advantage(reward 标量广播) | ppo_utils.py |
| compute_policy_loss() | PPO clip 损失 | ppo_utils.py |
| combine_loss_function() | Combine 自定义损失(w_opd + w_rl) | combine_loss.py |
| Megatron Actor(GPU 0-3) | 执行梯度更新、weight sync | Slime / Megatron-LM |
| RolloutFnTrainOutput | rollout 输出格式(返回给 Slime) | openclaw_rollout.py |
GPU分配
4组件架构各自运行在哪些GPU上?具体如下:
| 组件 | GPU | 实际进程 | 核心代码 |
|---|---|---|---|
| Policy Training | GPU 0-3 | Megatron Actor,TP=4 | slime/ + openclaw_rollout.py |
| Policy Serving | GPU 4-5 | SGLang Rollout + FastAPI Proxy | openclaw_api_server.py |
| Reward Judging | GPU 6-7 | SGLang PRM/Judge | 同一个 openclaw_api_server.py 中的评分逻辑 |
| Environment | 无GPU | OpenClawApp+用户 | openclaw/ (TS app) |
即:
GPU 分配 (8卡节点, run_qwen3_4b_openclaw_rl.sh):
GPU 0-3: Megatron Actor (ACTOR_GPUS=4, TP=4) <- Policy Training
GPU 4-5: SGLang Rollout (ROLLOUT_GPUS=2, TP=2) <- Policy Serving
GPU 6-7: SGLang PRM/Judge (PRM_GPUS=2, TP=2) <- Reward Judging
1.4 模型
OpenClaw-RL 优化的是 Qwen3-4B (Actor),它同时也是serve用户的模型(通过SGLang 推理引l擎的权重副本)。三个角色(Actor/Rollout/Judge)用的都是同一个模型,但只有 Actor 被训练更新。
模型详情
具体如下:
① Actor Model (GPU 0-3, Megatron TP=4)
= 被优化的 Student模型
= 做 forward/backward/optimizer step 的那个
→ 就是OpenClaw-RL 正在训练的模型
② Rollout Mode1. (GPU 4-5,SGLang TP=2)
= 为用户服务的推理引擎
= Actor的权重副本(定期同步)
→ 不直接训练,只是Actor 的“镜像“
③ PRM Judge / Teacher (GPU 6-7,·SGLang)
= 评分+生成hint+计算teacher_log_probs
= 可以是同一模型的另一个实例(OpenClawOPD)
→ 不被训练,只是工具
- 被优化的:只有 ① ActorModel
- ② 和 ① 是同一个模型的不同副本(权重周期性同步)
- ③ 是judge/teacher(固定不变)
具体配置
# run_qwen3_4b_openclaw_rl.sh 中:
MODEL_PATH=Qwen/Qwen3-4B #所有角色都用同—个模型
# Actor(训练):Qwen3-4B(Megatron格式,做梯度更新)
# Rollout(推理):Qwen3-4B(SGLang 格式,serve 用户)
# PRM/Teacher (评估):Qwen3-4B(SGLang 格式,评分/hint/teacher scoring)
训练循环
训练循环如下:
User → Rollout (Qwen3-4B) 生成 response
→ PRM Judge(Qwen3-4B)评分/生成hint
→ Teacher (Qwen3-4B+hint) 计算 teacher_log_probs
→ Actor(Qwen3-4B)做梯度更新 ◄─── 这一步优化模型
→ 权重同步回Rollout
→ 下次用户得到更好的response
0x02 Slime 的作用
Slime 在 OpenClaw-RL 中,是核心的 RL 后训练框架,负责高效地组织 rollout、trainer和data buffer等模块,实现异步、解耦的RL训练流程。它连接了模型推理(如SGLang)、训练(如 Megatron)和数据流转,支撑了 OpenClaw-RL 的所有 RL 训练范式(OPD,Binary RL,Combine)。
2.1 集成机制
Slime 通过以下机制与OpenClaw组件集成:
-
插件化架构:通过命令行参数注入自定义函数
-
异步数据流:OpenClawAPIServer异步生产数据,Slime异步消费
-
训练资源隔离:不同组件使用独立的GPU资源,避免相互干扰
-
统一接口:所有OpenClaw变体(RL/OPD/Combine)都遵循相同的集成模式
Slime 启动 SGLang 引擎
└── Slime 启动 SlimeRouter (分配动态端口)
└── Slime 将 ip/port 写入 args
└── OpenClawAPIServer 读取 args
└── 对外暴露 PORT=30000 给 OpenClaw App
(用户流量入口)
✓ SGLang 的启动、GPU 分配、端口分配、Router 注册 全部由 Slime 控制
① 分配 GPU (Ray Placement Group)
② 动态启动 SGLang 推理引擎 + SlimeRouter (port=动态分配 -> args.sglang_router_port)
③ 动态启动 PRM Engine + PRM Router (port=动态分配 -> args.prm_router_port)
④ 启动 Megatron Actor (GPU 0-3, TP=4)
✓ OpenClawAPIServer 只是"寄生"在 Slime 的基础设施上 ◄───────────────────── "此处是关键"
✓ PORT=30000 是外部可见端口, sglang_router_port 是 Slime 内部动态分配的
这种设计使得 OpenClaw-RL能够充分利用 Slime强大的分布式训练能力,同时保持 OpenClaw组件的灵活性和可扩展性。
2.2 Slime 扩展
我们来看看 Slime 扩展的机制。
Slime 设计了插件化的钩子系统,OpenClaw-RL 通过 shell 脚本中的参数注入,不修改 Slime 核心即可完整接管整个训练流程。
插件化架构
RolloutManager是Slime中负责管理rollout数据收集的核心类,它通过以下方式(扩展点)集成OpenClaw组件:
- 自定义生成函数:通过--custom-generate-function-path指定
- 自定义奖励函数:通过--custom-rm-path指定
- 自定义损失函数:通过--custom-loss-function-path指定
- 自定义 rollout 函数:通过 --rollout-function-path 指定
具体如下:
# run_qwen3_4b_openclaw_rl.sh 中的关键参数:
--rollout-function-path openclaw_rollout.generate_rollout_openclaw # 扩展点1
--custom-generate-function-path openclaw_api_server.generate # 扩展点2
--custom-rm-path openclaw_api_server.reward_func # 扩展点3
# 无需 --custom-loss-function-path (RL用标准GRPO)
# run_qwen3_4b_openclaw_combine.sh
--custom-loss-function-path combine_loss.combine_loss_function # 扩展点4
扩展点的职责
每个扩展点的职责如下:

2.3 OpenClaw-RL 做了哪些工作
OpenClaw-RL 的核心工作量集中在数据采集层 (openclaw_api_server.py),通过 4 个扩展点精准插入 Slime框架,完全不需要修改 Slime/Megatron 核心代码。
OpenClaw-RL 提供的工作量 Slime 框架提供的工作量
───────────────────────────────────── ─────────────────────────────────────
openclaw_api_server.py train_async.py (异步训练主循环)
- FastAPI 代理 + 会话管理 Megatron-LM (TP/PP/CP 训练)
- PRM 评分 (并发 m 次调用) SGLang (高效推理)
- next_state 检测 Ray (分布式任务调度)
- at-least-one guarantee GRPO 优势计算
- 样本提交到 output_queue PPO 损失函数
权重同步 (mbridge)
openclaw_rollout.py checkpoint 管理
- 被动等待模式 rollout WanDB 日志
小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)