
【OpenAI】GPT-5-Codex 企业级实战:代码生成优化指南获取OpenAI API KEY的两种方式,开发者必看全方面教程!
文章目录
GPT-5-Codex 实战优化指南:企业级代码生成性能与落地实践
一、模型定位与核心认知
- 定位:面向企业级、工程化、高复杂度代码场景,支持超长上下文(百万Token级别),覆盖全栈开发,具备量化性能优化能力。
- 应用:大规模代码生成、调试、重构、架构优化等高阶开发任务。
- 接入方式:目前通过 OpenAI Enterprise 限量开放,需企业认证。
二、核心能力对比(GPT-5-Codex vs GPT-4-Codex)
| 特性 | GPT-5-Codex | GPT-4-Codex |
|---|---|---|
| 上下文窗口 | 1M+ token | 128K token |
| 编程语言支持 | 100+(含 Rust/Go/Julia 等) | 70+ |
| 复杂逻辑推理 | 顶尖(分布式、高并发、算法设计) | 中高(简单逻辑为主) |
| 代码重构与优化 | 原生支持,含量化指标 | 基础支持,无量化建议 |
| 全栈开发能力 | 前端/后端/运维一体化生成 | 单模块为主 |
| 调试能力 | 动态分析 + 实时修复建议 | 静态分析为主 |
| 企业合规能力 | 版权检测、开源协议适配、安全审计 | 基础合规检查 |
三、企业级客户端示例代码
from openai import OpenAI
from tenacity import retry, stop_after_attempt, wait_exponential
import os
client = OpenAI(
api_key=os.getenv("OPENAI_ENTERPRISE_API_KEY"),
base_url="https://api.openai.com/v1/enterprise"
)
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def generate_code(prompt: str, language: str = "python", optimize_level: str = "performance"):
system_prompt = f"""
你是 GPT-5-Codex,企业级代码助手。
请生成符合工程规范的 {language} 代码,以 {optimize_level} 为优先目标。
输出包含:代码 + 注释 + 异常处理 + 测试示例 + 优化说明。
"""
completion = client.chat.completions.create(
model="gpt-5-codex-2026-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
],
temperature=0.2,
max_tokens=8192,
top_p=0.95,
frequency_penalty=0.1
)
return {
"code": completion.choices[0].message.content,
"usage": completion.usage
}
需求:实现用户认证模块
约束:Python 3.9,符合 PEP8,使用 JWT 认证
目标:安全、易维护
格式:包含异常处理和单元测试
1. 项目上下文注入
-
代码规范、架构文档、依赖清单写入系统提示
将项目的编码规范、架构设计文档、依赖库清单等关键信息注入到模型的系统提示中,确保生成的代码与项目环境高度兼容,减少后续修改成本。 -
分模块生成
对复杂系统进行拆分,分别生成接口层、业务层、数据层代码,避免一次性上下文过载,提高生成准确率和代码质量。 -
代码校验闭环
采用“生成 → 本地静态检查 → 模型二次校验 → 最终输出”的闭环流程,显著降低代码中的潜在 Bug,提升代码稳定性和可靠性。
2. 生成效率优化
-
长连接预热与复用
利用企业级 API 支持的 HTTP/2 长连接,减少每次请求的握手时间,提升接口响应速度。 -
批量请求合并
将多个小需求合并为一次请求,降低 API 调用频次,节省调用成本。 -
通用代码缓存
对工具类、基础函数等通用代码进行缓存,避免重复生成,提高整体效率。 -
精简输出范围
明确指令要求“只输出核心代码”,避免生成冗余内容,节省 Token 消耗。
3. 成本与稳定性优化
-
Token 精细化控制
通过设置max_tokens限制生成代码的最大长度,避免无效的 Token 消耗,控制成本。 -
模型分层使用
根据需求复杂度选择不同模型:- 简单需求使用 GPT-4-Codex
- 复杂需求使用 GPT-5-Codex
-
限流 + 指数退避重试
设计合理的限流策略和指数退避重试机制,防止触发 API 限流,保证服务稳定。 -
本地预校验
利用 pylint、eslint 或编译器进行本地代码预校验,提前过滤明显错误,减少无效 API 调用。
4. 企业级合规与安全优化
-
开源协议冲突检测
对生成代码进行版权和安全审计,检测潜在的 SQL 注入、XSS 攻击和内存泄漏等安全隐患,确保代码合规安全。 -
输出自动添加版权声明
支持私有化部署环境,自动在代码中添加版权声明,保障企业知识产权,确保数据不出域。
5. 最佳实践场景
-
企业级系统开发
适用于分布式服务、微服务架构、高并发系统及全栈项目的快速搭建。 -
遗留系统重构
支持老旧代码升级、性能瓶颈优化及技术栈迁移。 -
自动化开发平台
适配 IDE 插件、低代码平台、自动化测试及 CI/CD 脚本自动生成。 -
算法与高性能代码
机器学习工程化、数值计算及底层性能优化场景。 -
技术文档自动化
自动生成 API 文档、架构说明及运维手册。
6. 总结
GPT-5-Codex 作为面向企业级工程化开发的下一代代码生成模型,具备以下优势:
- 超大上下文支持,满足复杂系统开发需求
- 强逻辑推理能力,生成高质量、可维护代码
- 量化性能优化,提升代码执行效率
- 高合规性保障,确保企业安全与版权合规
结合结构化 Prompt、分块生成、缓存机制、重试策略及合规校验等工程化优化方案,企业能够实现:
代码质量提升 → 开发效率翻倍 → 成本可控 → 安全合规

第二种方式(国内):获取 能用AI API Key
要开始使用 能用AI 的服务,以下是获取 API Key 的详细步骤:
1. 点击 [能用AI 工具]
在浏览器中打开 能用AI 工具。
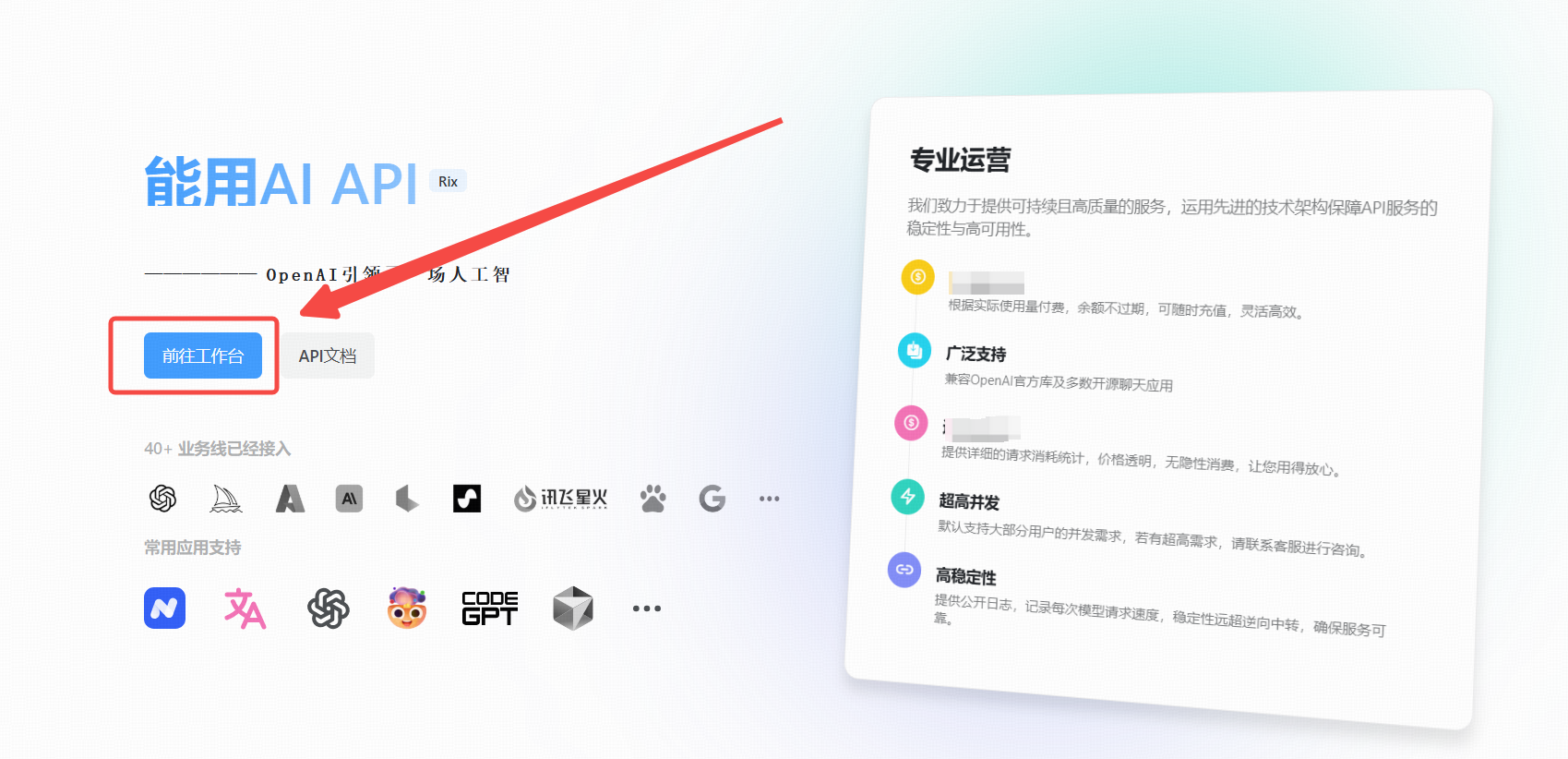
2. . 进入 API 管理界面
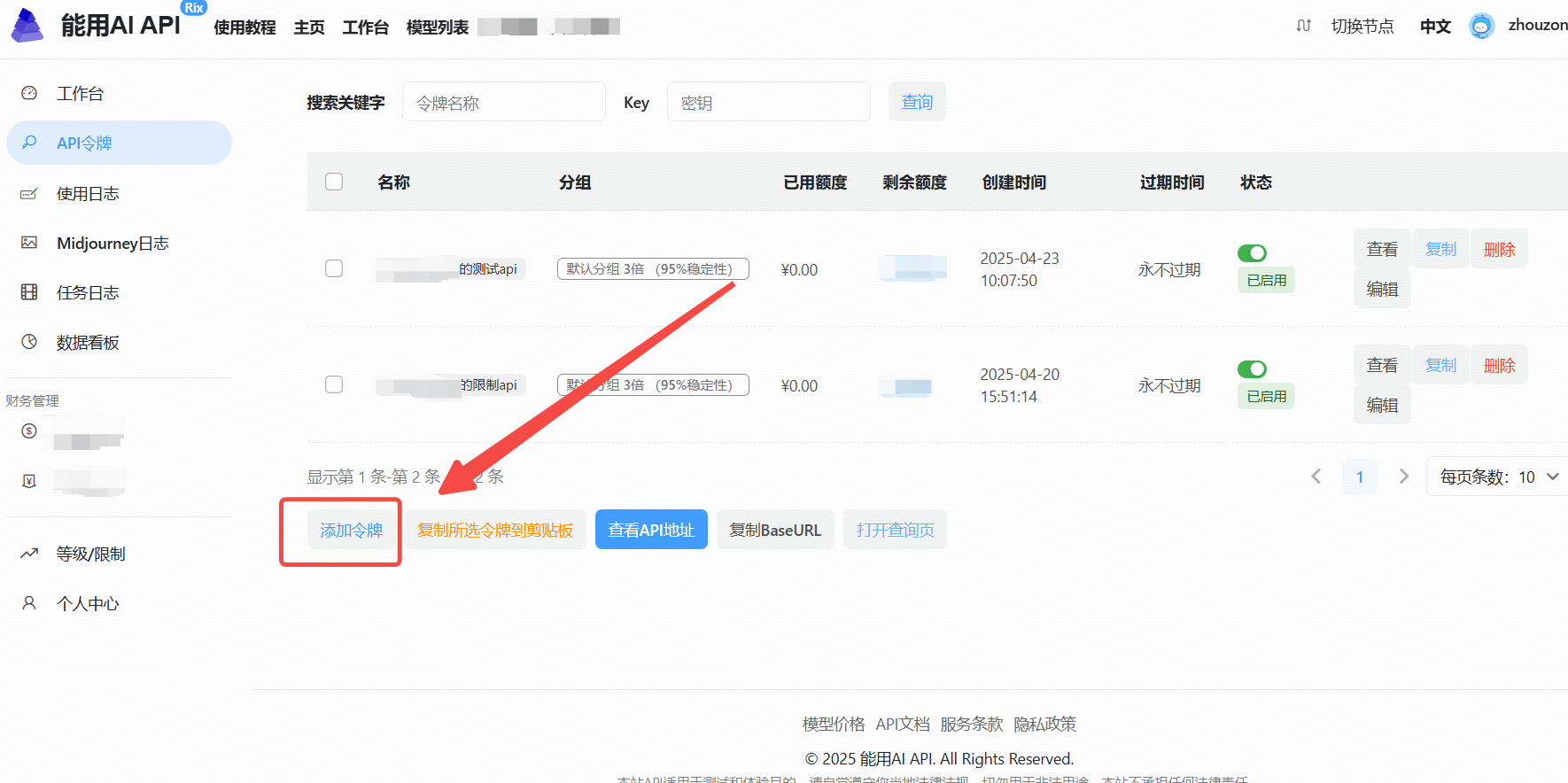
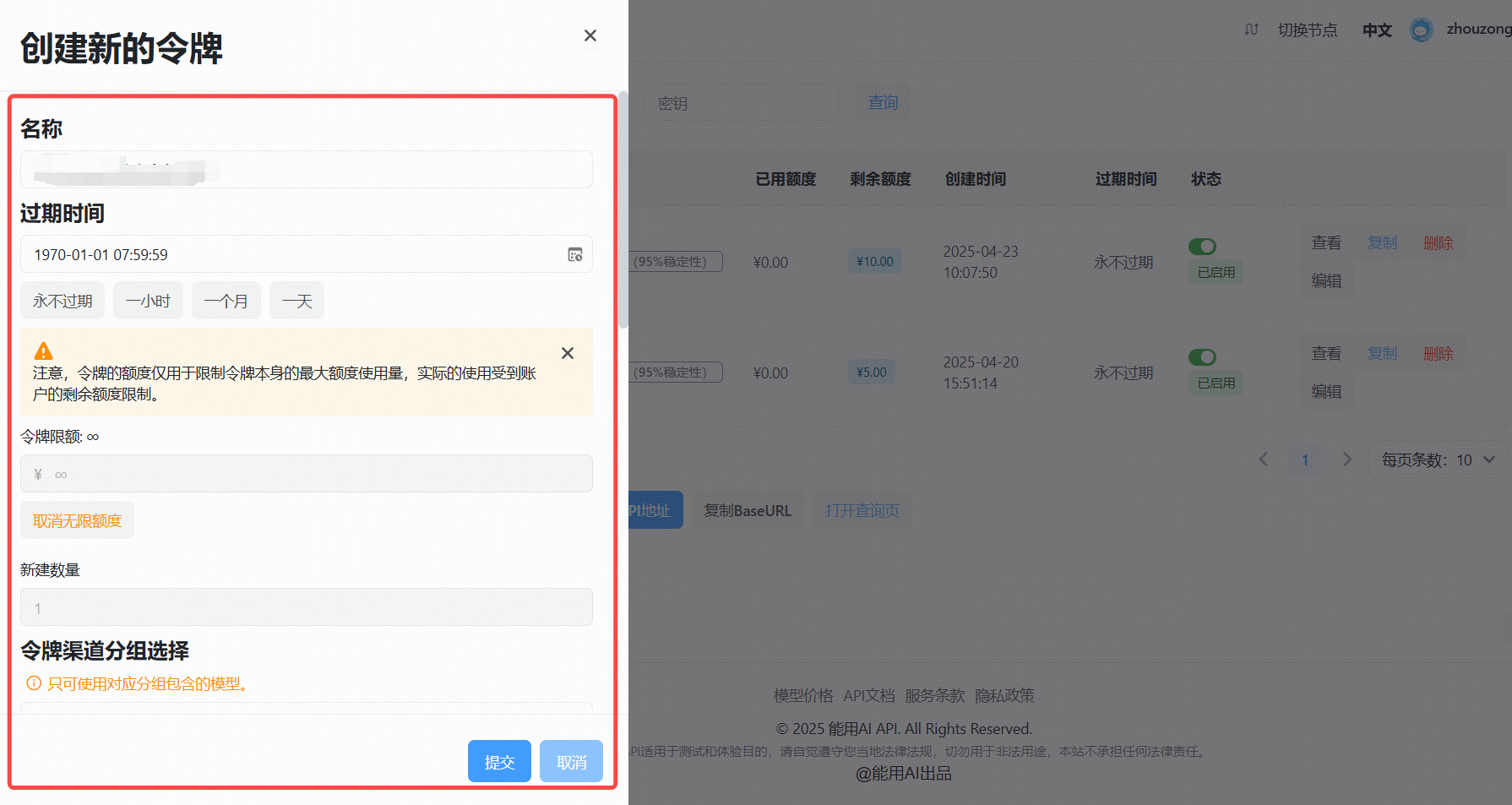
3. 生成新的 API Key
创建成功后点击“查看KEY”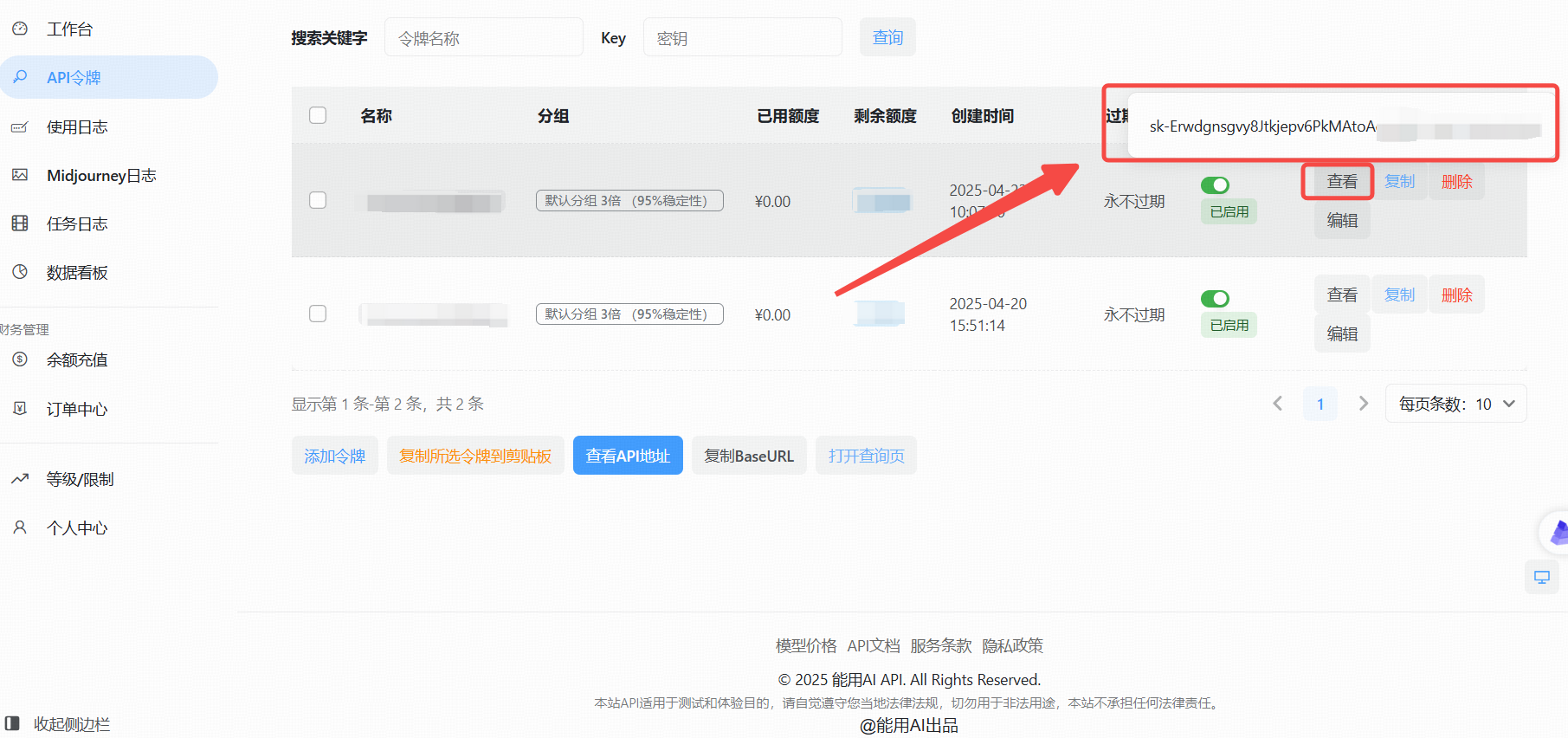
4. 调用代码使用 能用AI API
# [调用API:具体模型大全](https://flowus.cn/codemoss/share/42cfc0d9-b571-465d-8fe2-18eb4b6bc852)
from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4',
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
总结
通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!🌟

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)