
本周两个值得收藏的 GitHub AI 项目:社区热点调研助手与本地私有知识库
本周两个值得收藏的 GitHub AI 项目:社区热点调研助手与本地私有知识库
摘要:本周推荐两个更偏“实际工作流”的 GitHub Trending 项目:last30days-skill 适合把 Reddit、Hacker News、GitHub 等分散社区信号整理成可引用简报;open-notebook 则像一个可自部署的 NotebookLM,把 PDF、网页、音视频等资料变成可检索、可聊天、可生成播客的私有知识库。一个解决“外部世界最近在讨论什么”,一个解决“我手里的资料怎样持续复用”。

本周的两个项目都不是“再造一个聊天机器人”,而是把 AI 放进更具体的知识工作里:一个帮你追踪社区、项目和人物最近 30 天的讨论脉络;另一个帮你把私有资料沉淀成可对话的知识库。如果你经常做技术选型、竞品研究、课程整理或团队知识管理,这期值得看完。
1. last30days-skill:把分散社区信号变成一份可引用的研究简报
GitHub 地址:https://github.com/mvanhorn/last30days-skill
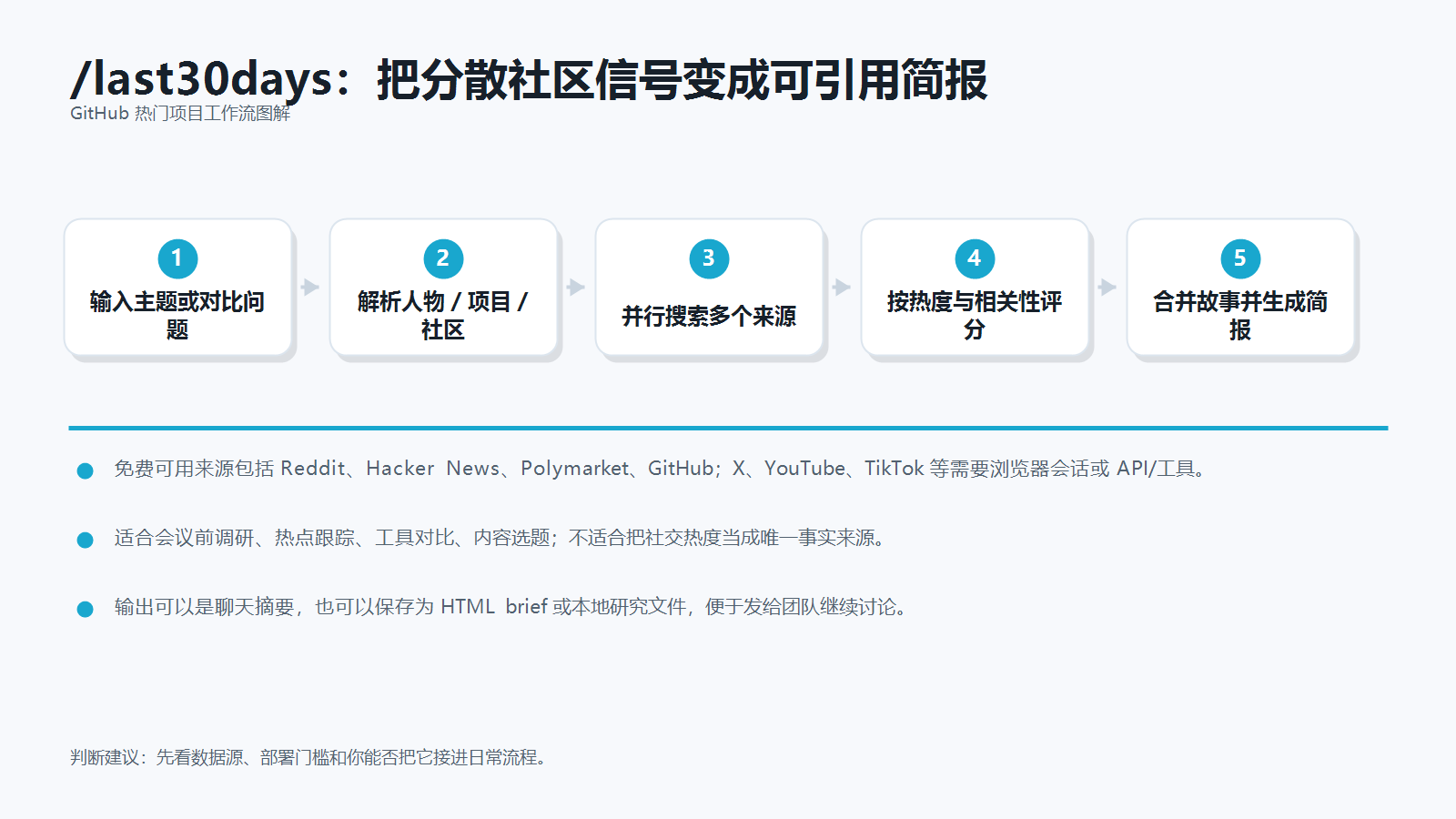
last30days-skill 是一个面向 Claude Code 的技能包。README 里的定位很直接:当你输入 /last30days,它会研究某个人、公司、项目、话题或趋势在最近 30 天的公开讨论,并把不同来源里的信号汇总成一份简报。
这类工具的价值不在于“替你搜索”,而在于把搜索动作拆成一个可重复流程:先理解研究对象,再去多个社区和内容平台找讨论,再按热度、相关性和情绪做初步判断,最后输出一份更适合人阅读的 brief。对经常写技术文章、做产品调研、开选型会的人来说,这比手动开十几个标签页更省心。
它解决什么问题
很多技术判断不是只看官方文档就够了。比如你想知道某个 Agent 框架最近有没有翻车案例,某个模型服务在开发者社区口碑如何,或者某个开源项目热度是不是只来自短期传播。手动查 Reddit、Hacker News、GitHub Issues、YouTube、X、TikTok,既费时间,也容易被单一平台带偏。
last30days-skill 的思路是:让 AI 先跑一轮“社区温度扫描”,帮你从不同渠道抓出高频讨论、正负反馈、常见使用场景和潜在争议。README 提到的免费来源包括 Reddit、Hacker News、Polymarket 和 GitHub;X、YouTube、TikTok 等来源则需要浏览器会话、API 或相应 MCP 工具配合。
核心功能与工作流
你可以把它理解成一个研究型 slash command。典型流程是:
- 在 Claude Code 里安装这个 skill。
- 输入类似
/last30days <研究对象>的指令。 - 工具识别研究对象是人物、公司、项目还是话题。
- 按来源并行查找最近一个月的讨论。
- 把高热度链接、关键观点、情绪倾向和可信度提示整理成简报。
- 需要时保存为本地 HTML brief 或研究文件。
README 还给出了一些很贴近工作场景的例子:研究 Anthropic 最近 30 天的讨论,比较两个项目的社区反馈,或者针对某个话题生成一份趋势简报。它不是数据库,也不是舆情系统,更像一个可以嵌入 Claude Code 的“调研起手式”。
适合哪些人
如果你是技术博主、开发者关系、产品经理、投资研究、开源项目维护者,或者团队里负责技术选型的人,它会很顺手。尤其适合这些场景:
- 写文章前快速判断一个项目是否真的有讨论热度。
- 选型会前先看社区里真实用户在抱怨什么。
- 跟踪竞品、框架、模型服务或开发工具的最近变化。
- 做内容选题时找“最近一个月大家在吵什么”。
不适合哪些人
如果你需要的是严格审计、法律证据、学术引用或实时金融数据,它不能直接替代专业数据源。社交平台讨论天然有偏差:高赞不等于正确,争议大不等于项目差,少人讨论也不代表没人用。
另外,它依赖 Claude Code 的技能体系。对不用 Claude Code、没有配置浏览器会话或相关 API 的用户来说,上手前需要先补环境。
上手条件与采用门槛
采用难度:中等偏低。
低,是因为它本质是一个 skill,安装后就能通过命令触发;中等,是因为想覆盖更丰富的数据源,就要准备浏览器登录态、API key 或 MCP 服务。README 明确把数据源分成免费可用和需要额外接入的两类,这一点很实际。
局限与取舍
我的判断是,last30days-skill 最大的价值是“减少第一轮调研成本”,不是给你最终结论。它适合用来找线索、找讨论、找风险点,但最终仍需要人工回到原始链接核验。
它的另一个取舍是来源覆盖和配置复杂度之间的平衡。只用免费来源,上手快但视野有限;接入更多平台,洞察更丰富,但维护成本也会上来。
一句话判断:如果你经常要在开会、写稿、选型前快速摸清一个项目的社区温度,last30days-skill 值得先试;如果你要的是严肃数据分析系统,它只能算前置调研助手。
2. Open Notebook:自部署版“资料可对话化”工作台
GitHub 地址:https://github.com/lfnovo/open-notebook
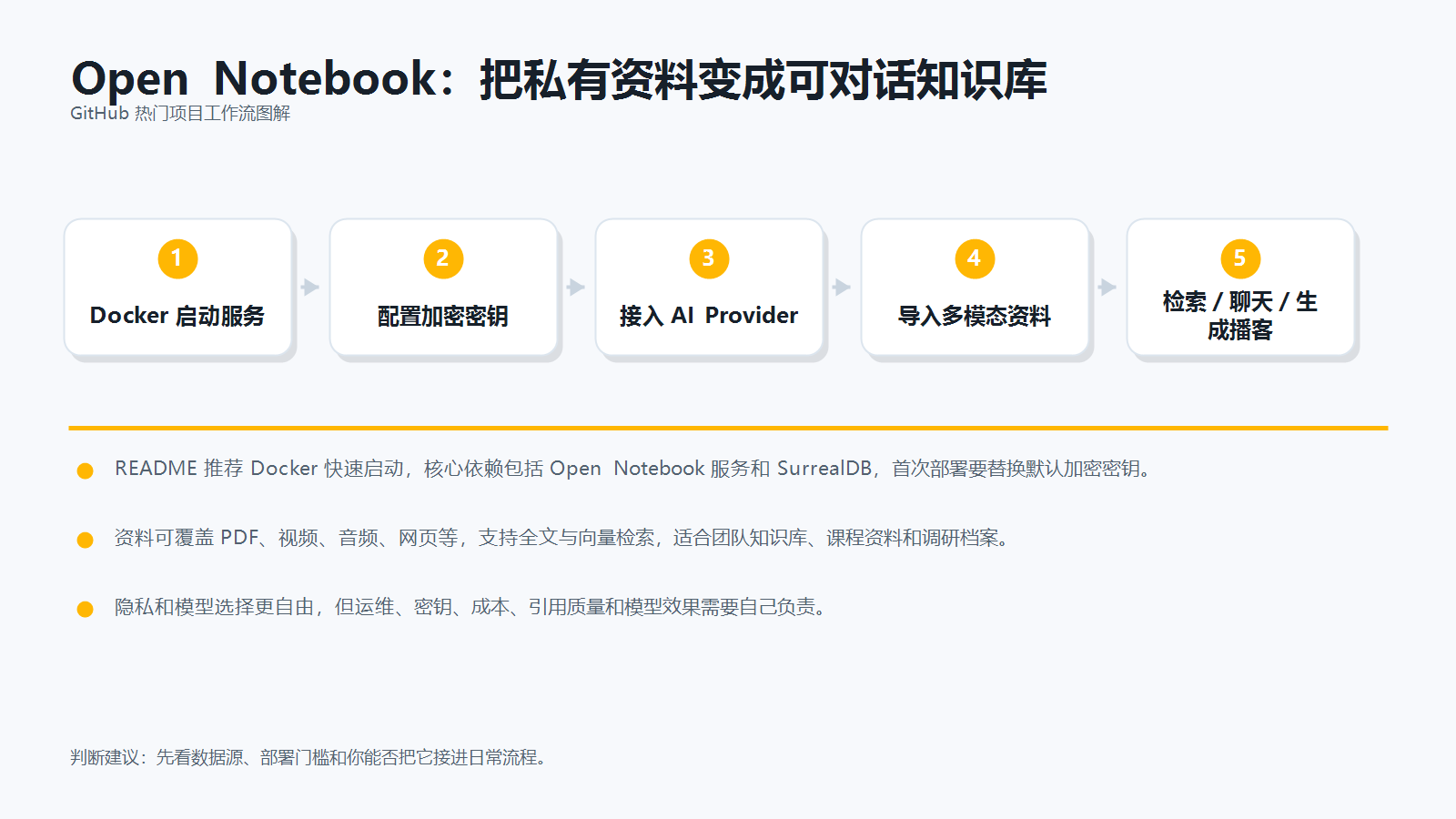
Open Notebook 的 README 把自己定位为开源、可自托管的 NotebookLM 替代方案。它的核心目标不是追热点,而是把你已有的资料变成一个可检索、可聊天、可生成内容的知识空间。
它支持把 PDF、网页、视频、音频等资料导入系统,再结合全文搜索、向量检索和 AI Provider 做问答、总结、引用与播客生成。对希望把课程资料、项目文档、客户调研、论文和内部知识放进同一个工作台的人来说,这个方向非常实用。
它解决什么问题
资料越多,真正麻烦的往往不是“存在哪里”,而是“下次还能不能用起来”。一个团队可能有 PDF 方案、会议录音、竞品网页、内部文档、视频课程和零散笔记。文件都在,但检索、引用和复盘很碎。
Open Notebook 想解决的是这个断层:把不同格式资料放进统一知识库,让你可以围绕一个 notebook 进行检索、聊天、生成摘要,甚至把内容转成播客式音频。它的 README 还强调本地优先、自托管和多 AI Provider,这意味着你可以更灵活地选择模型与部署方式。
核心功能与工作流
README 推荐用 Docker 快速启动。典型流程大致是:
- 使用
docker compose启动 Open Notebook 和 SurrealDB。 - 首次部署时替换默认加密密钥。
- 配置 OpenAI、Gemini、Ollama 等 AI Provider。
- 导入 PDF、网页、视频、音频或文本资料。
- 在 Notebook 内做全文搜索、向量搜索、聊天问答和内容生成。
- 对重要资料生成摘要、引用回答或播客内容。
它更像一个“知识工作台”,而不是单次摘要工具。导入资料后,后续可以围绕同一批资料反复提问、检索和生成内容。
适合哪些人
Open Notebook 适合重视资料沉淀、又不想把所有内容都交给闭源在线服务的人。典型场景包括:
- 研发团队整理项目文档、RFC、会议记录和技术方案。
- 老师或学生把课程 PDF、录课、参考资料整理成可提问知识库。
- 技术写作者把调研链接、论文、播客文字稿统一管理。
- 企业或个人想要自托管 NotebookLM 类体验,并可自由选择模型供应商。
不适合哪些人
如果你只想偶尔总结一篇 PDF,或者完全不想碰 Docker、数据库、密钥和模型配置,它可能显得重。README 的快速启动很友好,但“自托管”永远意味着你要为环境、升级、数据备份和模型成本负责。
另外,私有化部署不自动等于“没有风险”。你仍然要确认导入资料的权限边界、模型 Provider 的数据处理方式、团队成员访问控制,以及生成内容中的引用是否准确。
上手条件与采用门槛
采用难度:中等。
有 Docker 基础的用户可以很快跑起来;没有部署经验的用户,需要理解容器、数据库、环境变量和 Provider API key。README 特别提醒要替换默认加密密钥,这说明项目不是只面向玩具 Demo,而是希望用户以真实部署的方式对待数据安全。
局限与取舍
Open Notebook 的优势是控制权:数据在哪里、接哪个模型、是否用本地模型,都有更大自由度。代价是你要自己运维,而且效果会受模型、向量检索配置、原始资料质量影响。
如果资料很乱、扫描件质量差、音视频转写不准,后面的问答也会受影响。它能帮你组织和激活资料,但不能替你保证每条回答天然可靠。
一句话判断:如果你有持续积累的私有资料,并愿意承担一点部署和维护成本,Open Notebook 很值得收藏;如果只是偶尔总结公开网页,轻量在线工具可能更省事。
两个项目怎么选
| 维度 | last30days-skill | Open Notebook |
|---|---|---|
| 主要目标 | 研究最近 30 天的外部社区讨论 | 管理并复用自己的私有资料 |
| 典型输入 | 人物、项目、公司、话题、趋势 | PDF、网页、视频、音频、文本资料 |
| 输出形态 | 社区研究简报、链接、观点脉络 | 检索结果、聊天回答、摘要、播客 |
| 更适合 | 技术选型、内容选题、竞品观察、会前调研 | 团队知识库、课程资料、论文笔记、项目文档 |
| 上手门槛 | Claude Code skill;高级来源需要登录态或 API | Docker、自托管、数据库、AI Provider 配置 |
| 最大优势 | 快速摸清外部社区温度 | 数据控制权更强,资料可长期沉淀 |
| 主要风险 | 社交热度不能直接等于事实 | 运维和模型效果需要自己负责 |
| 我的建议 | 先用来做第一轮线索扫描 | 适合长期知识资产,不适合一次性轻任务 |
使用建议:把它们接成一条调研链路
如果你同时做技术调研和知识管理,这两个项目其实可以串起来用。
第一步,用 last30days-skill 扫一遍外部世界:某个项目最近有没有踩坑贴、替代品讨论、版本争议、社区反馈。它帮你决定“这个东西值不值得深入看”。
第二步,把真正值得沉淀的资料放进 Open Notebook:官方 README、文档、论文、视频、会议纪要、自己的测试记录。后续团队讨论时,就不必重新翻浏览器历史。
第三步,人工做最终判断:社区信号只能提示风险,私有知识库只能提升复用效率。真正要落地到生产环境,还要看许可证、维护活跃度、安全边界、性能、成本和团队现有栈。
结论
本期可以这样取舍:
- 先看
last30days-skill:如果你的痛点是“最近大家到底在讨论什么”,它更快见效。 - 收藏
Open Notebook:如果你有长期资料沉淀需求,尤其是团队知识库、课程资料和技术调研档案,它的方向更有长期价值。 - 暂时跳过的情况:如果你既不使用 Claude Code,也不想自托管服务,这两个项目都需要先补一点环境基础。
我的总体判断是:last30days-skill 更像调研前的望远镜,帮你找到值得追的线索;Open Notebook 更像资料库的工作台,帮你把已经收集到的东西反复用起来。一个向外看,一个向内沉淀,正好覆盖了技术人每天最常见的两类知识工作。
推荐标签:GitHub、开源项目、AI工具、Claude Code、知识库、技术选型、Docker、RAG

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)