
使用SpringAI完成 RAG 项目 —— 从零构建企业级知识库平台的完整历程
使用SpringAI完成 RAG 项目 —— 从零构建企业级知识库平台的完整历程
一个学习者的自白:我是如何通过阅读 Spring AI Alibaba 官方文档,从一行代码都没有,到最终交付一个融合 RAG + AI Agent 的完整知识库平台的。
项目地址:https://github.com/DevYangJC/Argus
写在前面
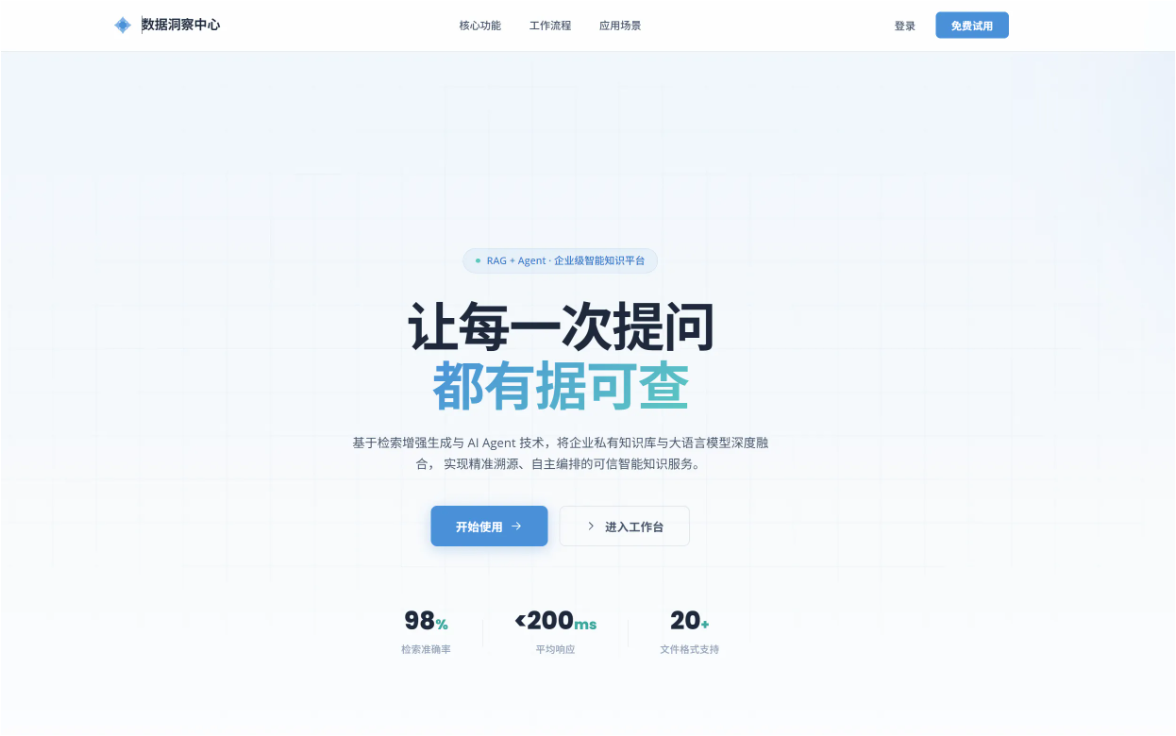
大家好。过去几个月,我利用业余时间完成了一个让我自己都感到惊喜的项目——Argus(百眼巨人),一个基于 Spring AI Alibaba 从零构建的 RAG 知识库平台。
说实话,在开始这个项目之前,我对 RAG 的理解还停留在"就是给 GPT 外挂一个向量数据库"的层面。但当我真正深入进去,才发现这条路上有太多值得探索的技术细节——从文档解析到向量索引,从混合检索到 Agent 工具编排,每一步都让我对 AI 应用开发有了全新的认识。
今天,我想把这段从 0 到 1 的完整历程分享出来,希望能给同样在 AI 应用开发道路上探索的朋友们一些启发。
一、为什么选择 RAG + Spring AI Alibaba?
1.1 一个真实的困惑
在 2025 年初,我开始思考一个问题:大语言模型确实很强大,但当一个企业想把自己的私有文档(产品手册、技术规范、运维指南)交给 AI 来回答问题时,会发生什么?
答案让人沮丧——LLM 会"编造"答案。它不知道你的文档里写了什么,只能基于训练数据中的通用知识来推测,结果往往是看起来很专业、实际上完全错误的内容。这就是 AI 领域著名的幻觉问题。
而 RAG(Retrieval-Augmented Generation,检索增强生成)正是解决这个问题的关键方案。它的核心思想非常简单:
在 LLM 回答之前,先从你的私有文档中检索出最相关的内容,然后让 LLM 基于这些真实文档来生成回答。
这样一来,AI 就不再是"凭空想象",而是"有据可查"。
1.2 为什么选择 Spring AI Alibaba?
确定了 RAG 的技术方向后,接下来面临的是技术选型问题。作为一个 Java 开发者,我自然希望能用 Spring Boot 生态来构建这个项目。当时我考察了几个方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| LangChain + Python | 生态最成熟,社区资源丰富 | 需要学习 Python 生态,与我现有的 Java 技术栈不兼容 |
| Spring AI + OpenAI | Java 原生,Spring 生态无缝集成 | 国内访问 OpenAI API 困难,延迟高 |
| Spring AI Alibaba | Java 原生 + 国内大模型深度集成 | 文档相对较新,社区尚在成长中 |
最终我选择了 Spring AI Alibaba,理由非常务实:
- DashScope 原生集成:通义千问在国内的访问速度和稳定性都非常好,API 延迟远低于海外服务
- Chat/Embedding 分离架构:Chat 走 DashScope 原生 API,Embedding 走 OpenAI 兼容模式——各取所长
- ReactAgent 图执行引擎:这是 Spring AI Alibaba Agent Framework 提供的核心能力,让我在后来的 V4.0 阶段能够构建出真正的 Agent 对话系统
- Spring Boot 生态兼容:MyBatis-Plus、Spring Security、Spring Retry 等成熟组件可以无缝接入
1.3 项目定位与命名
我给这个项目取名为 Argus——希腊神话中的百眼巨人。传说 Argus 即使睡着,身上的眼睛也始终保持警惕。这个名字完美契合了平台的愿景:
全面洞察你的私有知识资产,让每一次提问都有据可查。
项目采用渐进式迭代的开发方式,分四个版本逐步构建,每个版本聚焦一个核心主题:
二、V1.0:万丈高楼平地起 —— 用户认证与群组协作
2.1 为什么从认证开始?
说实话,刚开始我也犹豫过——是不是应该先从"炫酷"的 AI 对话功能开始?但仔细想想,一个企业级平台最基础的要求是什么?是安全和隔离。
如果不能让不同用户的数据相互隔离,不能让不同团队在各自的知识库空间中协作,那后面所有的 AI 能力都无从谈起。所以 V1.0 我选择从最基础的认证和群组系统开始。
2.2 JWT 双令牌认证机制
在认证方案上,我没有选择传统的 Session 模式,而是采用了 JWT 双令牌机制:
这个设计有几个关键考量:
Access Token 短期化(15 分钟):即使 Access Token 被泄露,攻击者也只有 15 分钟的操作窗口。相比某些系统动辄 24 小时的 Token 有效期,这是一个更加保守但更安全的选择。
Refresh Token 存储于 httpOnly Cookie + 数据库:httpOnly 意味着 JavaScript 无法读取,XSS 攻击无法窃取。同时,Refresh Token 在数据库中也有记录,每次刷新时会进行 Rotation(旧 Token 删除、新 Token 生成),这样即使某个 Refresh Token 被盗用,使用一次后就会失效。
BCrypt 密码加密:用户密码在数据库中存储的是 BCrypt 哈希值,即使数据库被拖库,攻击者也无法还原明文密码。
2.3 三级角色权限体系
权限设计上,我实现了三个层级的角色控制:
| 角色 | 权限范围 |
|---|---|
| Admin | 系统管理员,可以管理所有用户、查看所有群组 |
| Group Owner | 群组所有者,可以邀请成员、审批申请、上传文档、删除文档 |
| Group Member | 群组成员,可以查看群组文档、在知识库中提问 |
权限校验的实现采用了"多层防御"策略——先经过 JWT 认证过滤器,再经过角色校验,最后在数据查询层面还会附加 groupId 过滤条件。这样即使某一层出现了漏洞,后续的防御层仍然能够保护数据安全。
2.4 群组协作机制
群组协作支持两种加入方式:
- 邀请制:群组 Owner 生成邀请码,被邀请者通过邀请码直接加入
- 申请制:用户主动申请加入群组,Owner 审批通过后成为成员
这两种机制覆盖了不同的协作场景——邀请制适合小团队,申请制适合开放的知识社区。
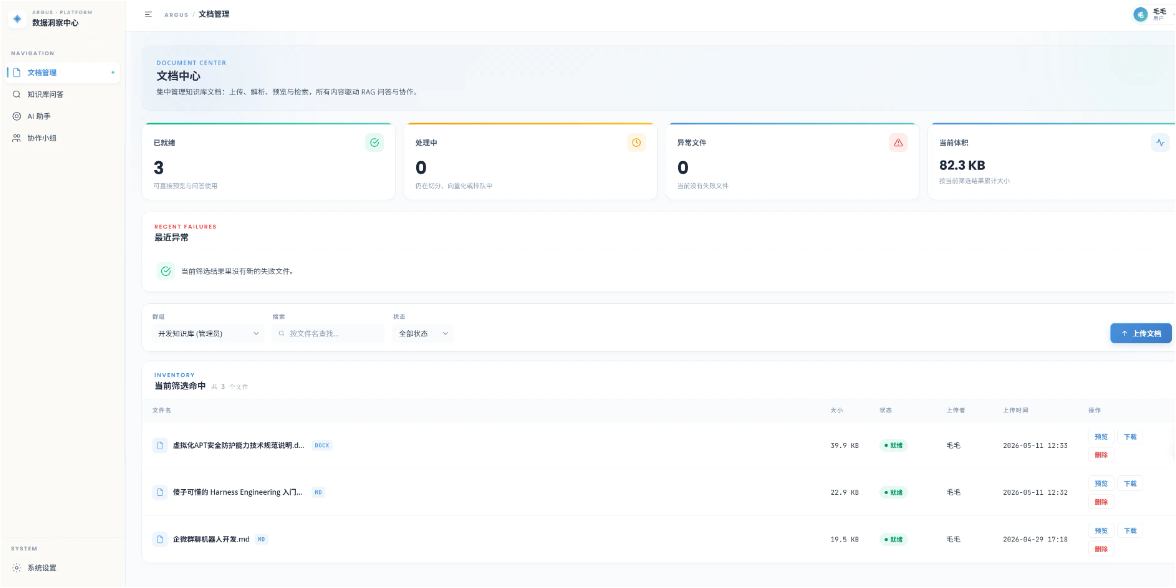
三、V2.0:打通数据链路 —— 文档管理与 ETL 流水线
3.1 挑战:大文件上传怎么搞?
V2.0 是整个项目中最"硬核"的一个版本。这个阶段要做的事情是:让用户能够上传文档,然后系统自动把文档解析、切片、向量化、建立索引,最终变成可检索的知识。
听起来简单?实际上光"上传"这一个环节就让我头疼了好几天。
在网络环境下上传大文件(比如几百 MB 的 PDF),最直接的问题是:如果网断了怎么办? 用户辛辛苦苦传了 95%,网络一抖,全部从头再来——这种体验简直是灾难。
3.2 三阶段分片上传协议
为了解决这个问题,我设计了一个三阶段分片上传协议:
这个协议解决了三个核心问题:
秒传(Instant Upload):如果同一个群组内已经存在相同 SHA-256 哈希的文档,系统直接返回已有文档的 ID,完全不占用带宽和存储空间。
断点续传:上传会话有 24 小时的有效期。如果上传中断,客户端重新初始化时会收到 uploadedChunks 列表(已上传的分片序号),只需要上传缺失的部分即可。
幂等安全:分片记录使用 PostgreSQL 的 ON CONFLICT ... DO UPDATE(upsert)语法,即使客户端重复上传同一个分片,也不会产生脏数据。
3.3 ETL 异步流水线
上传完成后,接下来是文档的"消化"过程——也就是 ETL(Extract-Transform-Load)流水线。我采用 Spring Event + @Async 的异步机制来驱动这个过程,这样上传接口可以立即返回,不会让用户等待:
这里有几个设计细节值得展开:
为什么用 Spring Event 而不是消息队列?
对于教学项目来说,引入 RabbitMQ 或 Kafka 会增加运维复杂度。Spring Event + @Async 的组合在单机部署场景下完全够用——事务提交后异步触发 ETL,不影响 HTTP 响应时间。而且 @TransactionalEventListener(AFTER_COMMIT) 保证了只有在数据库事务成功提交后才会触发处理,避免了"文档还没落库就开始处理"的竞态问题。
结构感知切片是什么?
简单的文本切片按固定字符数切割,会破坏文档的语义结构(可能在段落中间切断)。我的实现会先识别 Markdown 标题层级和段落边界,优先在标题或段落边界处切割,确保每个切片都是一个相对完整的语义单元。切片过小的就合并到上一个,过大的则递归向下拆分。
PGvector HNSW 索引参数的选择
向量索引使用了 HNSW(Hierarchical Navigable Small World)算法,参数 m=16, ef_construction=200。这不是随便选的——m 控制每个节点的最大连接数,越大检索越快但构建越慢;ef_construction 控制构建时的候选集大小,越大索引质量越高但构建耗时越长。对于百万级以内的数据集,m=16, ef_construction=200 是质量和速度的平衡点。
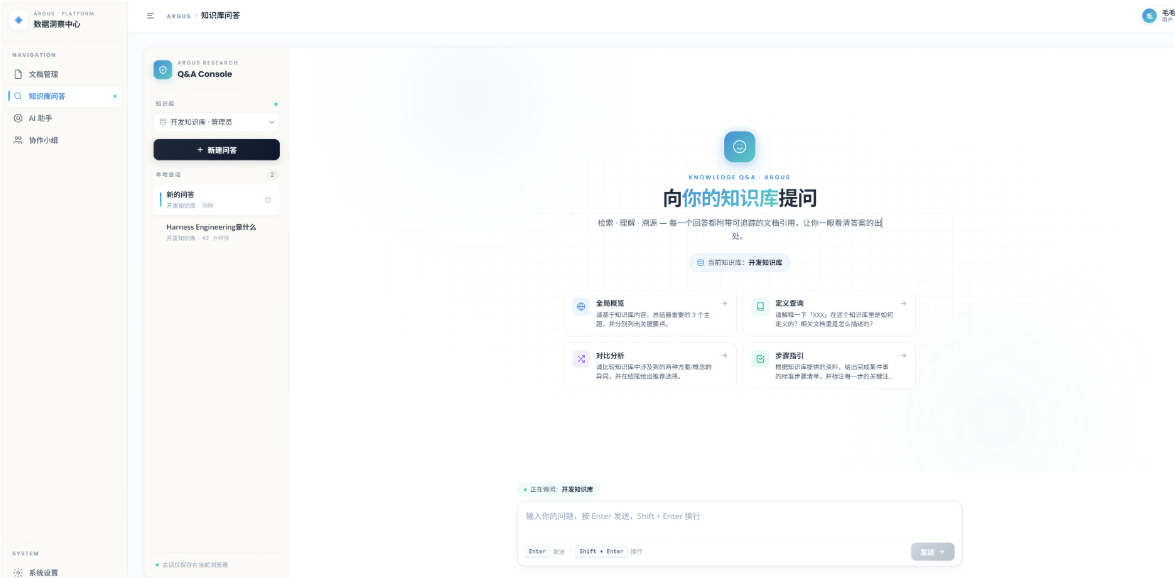
四、V3.0:让 AI 真正理解你的文档 —— RAG 问答系统
4.1 从检索到回答,中间还差什么?
V2.0 完成后,我已经有了两路检索能力:PGvector 的向量语义检索和 Elasticsearch 的关键词全文检索。理论上,拿到检索结果后喂给 LLM,就能生成回答了。
但实际试了一下,发现效果远不如预期。问题出在哪里?
问题一:用户的问题千奇百怪
用户问"这玩意儿怎么搞?“,直接拿去检索,向量相似度很低;但如果改写为"文档上传流程和操作方法”,检索效果就好很多。这就是**查询规划(Query Planning)**要解决的问题。
问题二:两路检索结果怎么融合?
向量检索返回的相似度分数是 0 到 1 的浮点数,ES 返回的 BM25 分数可能是 0 到几十——两种分数不在同一个尺度上,没法直接比较。这就是RRF 融合排序要解决的问题。
问题三:检索到的证据够不够?
有时检索回来的内容跟问题其实关系不大,如果强行让 LLM 回答,它还是会"编"。这就是证据评估要解决的问题。
4.2 RAG 问答的完整流程
4.3 RRF 融合排序:让向量和关键词"握手"
RRF(Reciprocal Rank Fusion)是一个优雅的算法。它的公式简单到只有一行:
R R F _ s c o r e ( d ) = ∑ c ∈ c h a n n e l s 1 k + r a n k c ( d ) RRF\_score(d) = \sum_{c \in channels} \frac{1}{k + rank_c(d)} RRF_score(d)=c∈channels∑k+rankc(d)1
其中 k=60 是一个平滑参数。这个公式的妙处在于:
- 它在两个通道的排名上做文章,而不是原始分数——这就完美解决了分数尺度不统一的问题
- 某个文档在向量检索中排第 1、在关键词检索中排第 10,它的 RRF 分数是
1/(60+1) + 1/(60+10) = 0.0164 + 0.0143 = 0.0307 - 另一个文档在向量检索中排第 3、在关键词检索中排第 3,它的 RRF 分数是
1/(60+3) + 1/(60+3) = 0.0317
可以看到,双通道都排名靠前的文档最终得分更高——这正是我们想要的:两个通道"交叉验证"过的结果更可信。
融合之后还有两步优化:
- 类簇聚合:同一个文档中连续的几个切片如果都命中了,就合并为一个"证据单元",提供更完整的上下文
- 邻居窗口扩展:每个命中的切片向前后各扩展 1 个切片,补充上下文避免碎片化
4.4 四级证据评估:AI 的"自知之明"
这是整个 RAG 系统中我最喜欢的设计。在传统的"搜索 + GPT"方案中,LLM 总是会尝试回答——即使检索到的内容完全不相关,它也会"编"一个听起来合理的答案。
我设计了一个四级证据评估机制:
| 等级 | 触发条件 | 回答策略 |
|---|---|---|
| NONE | 检索结果为空 | 直接拒答,不调用 LLM(省钱!) |
| WEAK | 仅单通道命中 + 文档数 < 2 | 生成回答但标注"依据有限,仅供参考" |
| PARTIAL | 双通道命中 OR 文档数 ≥ 2 | 正常回答,但标注覆盖不足的方面 |
| SUFFICIENT | 文档数 ≥ 2 AND (双通道命中 OR 最高分≥0.95) | 正常回答,禁止臆测 |
这个设计有两个关键考量:
文档数量门槛:单文档证据即使高相关也可能是文档本身的偏向性——比如一篇产品宣传文可能过度夸大某个功能。至少 2 个不同文档的切片命中,交叉验证的可信度才足够高。
NONE 级别直接拒答:这是成本控制的关键。在 NONE 的情况下,LLM 根本不会被调用,既节省了 API 费用,也避免了"一本正经胡说八道"的尴尬。
4.5 结构化输出与引用溯源
LLM 的输出格式不稳定是一个众所周知的痛点。我的解决方案是:通过精心设计的 System Prompt 要求 LLM 输出 JSON 格式:
{
"answered": true,
"answer": "文档上传流程分为三个阶段...",
"reasonCode": null,
"reasonMessage": null
}
同时准备了一个回退解析器——如果 LLM 输出的 JSON 解析失败(偶尔会发生),就用正则表达式从原始文本中尝试提取 answered 字段和 answer 内容。这确保了系统在 LLM 输出异常时也能优雅降级,而不是直接报错。
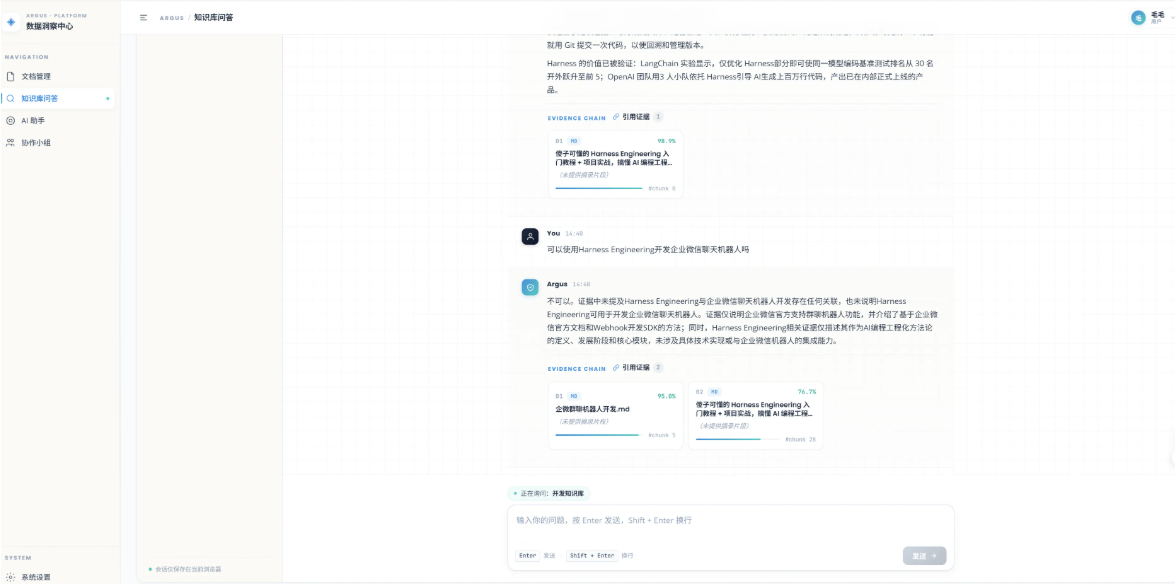
每条回答都会附带引用列表(Citations),包含来源文档名、切片序号、相关性评分。这让用户可以追溯到回答的依据——“这条信息来自哪个文档的哪一段”。
五、V4.0:让 AI 拥有"记忆" —— AI 助手 Agent
5.1 从"一次性问答"到"多轮对话"
V3.0 的 RAG 问答虽然强大,但有一个明显的局限:每次提问都是独立的。你问"什么是 RAG?“,AI 回答了;你再问"那它有什么优势?”,AI 不知道"它"指的是 RAG。这就像每次对话都在跟一个失忆的人聊天。
V4.0 的目标就是解决这个问题——让 AI 助手具备上下文感知的多轮对话能力。
5.2 ReactAgent:统一对话引擎
在技术选型上,我选择了 Spring AI Alibaba 的 ReactAgent 图执行引擎。这是一个基于图(Graph)的执行框架,支持"思考→行动→观察→再思考"的循环模式:
这里有一个有意思的设计决策:即使是纯对话模式(CHAT),我也让它走 ReactAgent 的图执行引擎,只是不装配任何工具。这样做的好处是:
- 两种模式共用同一套 Hook、流式处理、错误处理逻辑
- 代码复用度高,不需要维护两套对话处理流程
- 虽然 CHAT 模式走 Agent 图有一定的微小开销(图节点调度、MemorySaver checkpoint),但在 LLM 调用时延(数秒级)面前可以忽略不计
5.3 短期记忆三级压缩策略
多轮对话面临的核心矛盾是:LLM 的上下文窗口有限(即使是最新的模型也有上限),但对话历史会无限增长。
简单的"滑动窗口"方案(只保留最近 N 条消息)在长对话中会丢失早期的关键信息。比如用户在对话开始时说"我在做一个电力行业的项目",30 轮对话后如果你忘了这个背景,AI 的回答可能就完全跑偏了。
我设计了一个三级渐进压缩策略:
第一级:summary_text(会话摘要)
当会话消息数超过 20 条或 token 估算超过 8000 时触发。规则很简单:保留最近 N 条原始消息,将更早的消息压缩为"用户问了什么,助手回答了什么"的格式文本。摘要可复用——如果 7 天内没有新消息,直接使用已有的摘要。
第二级:session_memory(会话记忆)
这是最精妙的一级。每当新增 4 条消息或新增 token 超过 1200 时,调用 LLM 进行增量更新——不是重新摘要全部历史,而是把新消息"合并"到已有记忆中。Prompt 模板引导 LLM 保留关键事实、用户偏好和重要决策,丢弃临时性的寒暄和重复内容。
例如,用户可能在对话中多次提到"我在电力行业工作"、“我们的巡检手册要求…”——这些信息会被 session_memory 保留下来,而"好的"、“谢谢”、"明白了"之类的废话会被丢弃。
第三级:compact_summary(紧凑摘要)
当会话总 token 超过 6500 时触发。这是对 session_memory 的进一步压缩——基于"现有 compact_summary + session_memory + 待压缩消息"生成更精炼的版本。Prompt 引导 LLM 只保留最核心的信息。
运行时压缩(最后防线)
如果前面的压缩机制全部失效(理论上不应该发生),还有一个硬编码的 50000 token 阈值。超过时直接截断消息列表,只保留末尾 3 条。这是一个"逃生舱",确保系统永远不会因为上下文溢出而崩溃。
5.4 BEFORE_MODEL Hook:无侵入的上下文注入
你可能会问:这些摘要和记忆是怎么"喂"给模型的?
这就用到了 ReactAgent 框架提供的 MessagesModelHook 机制。我实现了一个 BEFORE_MODEL Hook,在每次模型调用之前自动执行:
-
从
RunnableConfig的 metadata 中读取userId、sessionId、toolMode、groupId -
从数据库中加载该会话的
compactSummary、sessionMemory、最近消息 -
按顺序组装消息列表:
[compact summary 作为系统消息] → [session memory 作为系统消息] → [历史消息 1] → [历史消息 2] → ... → [工具调用结果(如果有)] → [当前用户问题] -
使用 REPLACE 模式完全替换 Agent 框架默认的消息列表
这整个过程中,Agent 的业务代码完全不需要关心上下文是怎么组装的——Hook 在框架层面自动完成了全部工作。这种"无侵入"的设计让代码保持了很高的内聚性。
5.5 SSE 流式输出与 Delta 去重
流式输出听起来简单——模型生成一个字就推送一个字——但实际上有一个坑:某些模型后端在流式模式下返回的不是增量 delta,而是截至当前的全文。如果直接透传给前端,用户会看到不断重复的前缀文字。
我的解决方案是用一个 StringBuilder 持续累积已推送的文本。每次收到新文本时,检查它是否以已累积的文本为前缀——如果是,就裁掉前缀,只把真正的增量推送给前端:
第 1 次收到: "RAG" → 推送 "RAG"
第 2 次收到: "RAG(检索增强" → 推送 "(检索增强"
第 3 次收到: "RAG(检索增强生成)是一种" → 推送 "生成)是一种"
同时还有一个 AGENT_MODEL_FINISHED 兜底路径——某些模型不走逐字流式通道,而是直接在 finished 节点返回全文。此时如果 finalReply 为空,就将完整文本作为一次性 delta 发送。
六、前后端分离与实时通信
6.1 前端技术选型
前端我选择了 Vue 3 + TypeScript + Element Plus 的组合。选择 Vue 3 的理由很简单:它的 Composition API 让组件逻辑的组织更加清晰,TypeScript 的类型系统能在编译期就发现大量潜在问题。
状态管理使用了 Pinia(Vue 3 官方推荐的状态管理库),相比 Vuex 更加轻量且 TypeScript 支持更好。Markdown 渲染使用了 marked 库,支持 GFM(GitHub Flavored Markdown)语法。
6.2 流式对话的前端实现
SSE 流式对话的前端实现使用 fetch API + ReadableStream:
const response = await fetch('/api/assistant/chat/stream', {
method: 'POST',
headers: { 'Content-Type': 'application/json', 'Authorization': `Bearer ${token}` },
body: JSON.stringify({ sessionId, message, toolMode, groupId })
})
const reader = response.body!.getReader()
const decoder = new TextDecoder()
while (true) {
const { done, value } = await reader.read()
if (done) break
// 解析 SSE 事件:event:delta\ndata:{"delta":"新文本"}\n\n
// 将增量文本追加到显示缓冲区,实现打字机效果
}
前端收到 delta 事件后,将文本增量追加到消息显示区域,实现逐字打印的打字机效果。done 事件到达后,将完整消息保存到 Pinia store 中。
七、未来发展规划
项目目前已经完成了 V4.0,但这只是开始。我计划在后续版本中逐步增加以下能力:
V4.1 — 体验优化
- 会话记忆可视化:在前端展示压缩摘要内容,让用户了解 AI “记住了什么”
- 消息分页加载:当前只支持加载最近 N 条消息,长会话需要分页支持
- 会话归档与恢复:将不活跃的会话归档,需要时再恢复
V4.2 — 工具扩展
- 更多 Agent 工具:文档管理工具(列出文档、搜索文档)、群组管理工具(查看成员、查看统计)
- 多工具协作:Agent 可以在同一轮对话中调用多个工具,处理更复杂的用户请求
- 工具调用可视化:在前端展示 Agent 的"思考过程"——它调用了哪些工具、得到了什么结果
V4.3 — 对话增强
- 对话分支:从任意消息节点创建分支对话,探索不同的回答方向
- 消息编辑与重新生成:编辑已发送的消息,让 AI 基于修改后的内容重新回答
- Prompt 版本管理:支持不同版本的 System Prompt,方便 A/B 测试
V5.0 — 重大升级
- 多模态支持:除了文本文档,支持图片、表格等多模态内容的检索与问答
- WebSocket 升级:将 SSE 替换为 WebSocket,支持双向实时通信
- 前端管理控制台全面升级:文档管理、群组管理、问答历史、数据统计等功能的完整控制台
- 消息队列迁移:将 Spring Event 异步机制升级为 RabbitMQ/Kafka,支持分布式 Worker 调度
八、学习心得与经验总结
8.1 从文档出发,而不是从教程出发
整个开发过程中,我最大的感受是:官方文档是最好的学习资料。
Spring AI Alibaba 的官方文档写得很用心——不仅告诉你 API 怎么用,还解释了背后的设计理念。比如关于 Chat/Embedding 分离提供者的说明,让我理解了为什么 Embedding 要走 OpenAI 兼容模式而不是 DashScope 原生 API(因为 Spring AI 的 OpenAI embedding 客户端更成熟稳定)。
相比之下,网上的很多教程往往只给代码不给原理,看完之后知其然不知其所以然。遇到稍微复杂一点的需求,就束手无策了。
8.2 渐进式迭代的力量
这个项目分了四个版本,每个版本聚焦一个主题。这种方式让我在每个阶段都能保持专注,不会被过多未完成的功能分散注意力。
更重要的是,每个版本的交付物都是可用的——V1.0 有可用的认证系统,V2.0 有可用的文档上传和检索,V3.0 有可用的 RAG 问答,V4.0 有可用的 Agent 对话。这种"每一步都有交付"的开发节奏不仅给了我持续的正反馈,也让我在每个阶段都能进行完整的测试和验证。
8.3 遇到的技术挑战与解决思路
挑战一:Markdown 预览变成纯文本
在开发文档预览功能时,我发现 MD 文件预览只显示纯文本,没有任何格式。排查后发现,后端 MdDocumentParser.stripMarkdown() 方法会主动剥离所有 Markdown 语法(#、**、列表标记等),返回的是处理后的纯文本。修改方案是让 MD 文件绕过解析器,直接从 MinIO 读取原始内容返回给前端,由前端的 marked.js 完成渲染。
教训:调试时要沿着完整的数据链路排查——从前端请求到后端处理再到数据存储,任何一个环节都可能是问题所在。
挑战二:SSE 流式输出的 Delta 去重
前面提到过,某些模型后端返回的是全文而不是增量。这个问题花了我不少时间排查——一开始我以为是前端解析 SSE 事件的逻辑有 bug,后来才发现是后端推送的内容本身就是重复的。
教训:不要假设第三方组件的行为一定符合预期。即使文档上说"流式推送",实际行为也可能因模型后端的不同而有差异。
挑战三:短期记忆的并发写入冲突
在多轮对话中,用户发送消息后,BEFORE_MODEL Hook 和 AFTER_AGENT 回调都可能触发记忆更新。如果两个操作同时尝试更新 assistant_session_contexts 表,就会产生并发冲突。我的解决方案是使用乐观锁——在更新 SQL 的 WHERE 条件中加入 context_version = #{expectedVersion},更新失败(影响行数为 0)时抛出异常回滚事务。
教训:在涉及状态变更的系统中,并发控制是一个必须从一开始就考虑的问题。
8.4 给想入门 RAG 开发的建议
如果你也想从零开始构建一个 RAG 应用,我的建议是:
-
先理解原理,再动手写代码。搞清楚 Embedding 是什么、向量检索怎么工作、RAG 的完整链路是怎样的——这些基础知识会让你在遇到问题时更容易定位原因。
-
从最简单的实现开始。先用最直接的方式跑通"文档上传 → 向量检索 → LLM 回答"这个核心链路,然后再逐步优化检索质量、增加 Agent 能力、引入记忆管理。
-
Spring Boot + Spring AI Alibaba 是一个很好的起点。如果你有 Java 基础,这个组合让你可以在熟悉的生态中快速构建 AI 应用,不需要额外学习 Python 或 LangChain。
-
记录你的踩坑过程。我在开发过程中养成了记录遇到的问题和解决方案的习惯,这不仅帮助我自己理清思路,也让我在写这篇文章时能够回顾当时的思考过程。
写在最后
从一行代码都没有,到最终交付一个包含认证授权、文档管理、ETL 流水线、混合检索、RAG 问答、Agent 对话、短期记忆管理的完整平台,这段旅程让我深刻体会到:AI 应用开发不是"调 API"那么简单,它需要你对检索、存储、并发、架构等基础工程能力有扎实的理解。
但正是这种"全栈"的挑战,让整个过程充满了乐趣和成就感。
如果你对这个项目感兴趣,欢迎访问 GitHub 仓库 查看完整源码,也欢迎提 Issue 和 PR 一起讨论改进。
让每一次提问都有据可查 —— 这是 Argus 的初心,也是我对 AI 应用开发的信念。
本文同步发布于掘金、知乎、CSDN等平台。转载请联系作者。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)